
Notice:
This post is older than 5 years – the content might be outdated.
Automatic emotion recognition is an emerging area which leverages and combines knowledge from multiple fields such as machine learning, computer vision and signal processing. It has potential applications in many areas including healthcare, robotic assistance, education, market survey and advertising. Another usage of this information is to improve Human Computer Interaction with what can be described as Affective Computing, an interdisciplinary field that expands into otherwise unrelated fields like psychology and cognitive science. The concept of „affective robots“ refers to leveraging these emotional capabilities in humanoid robots to respond in the most appropriate way based on the user’s current mood and personality traits. In this article, we explore the emotion recognition capabilities of Pepper the robot and how they perform in contrast to other cutting-edge approaches.
Why emotion recognition in robots
Nowadays, we are accustomed to interacting with technology that helps us considerably in our daily routine. We rely on these devices for numerous tasks from early in the morning, when we use our smartphone to check the best route to work based on current traffic, at the ATM and even to pay at the supermarket. Technology reaches us continuously via notifications when a meeting is approaching, our flight has been delayed, a new album of our favourite artist has been released, and when it’s our friends‘ birthdays.
Amazon Echo and Google Home are recently released voice-enabled wireless speakers that make use of intelligent personal assistants, Amazon Alexa and Google Assistant, respectively, i.e. software agents that understand user requests in natural language and perform appropriate actions. People get used to the simplicity of these indeed helpful assistants. However, the kind of interaction we have with all these devices is utterly different from our experience with social interaction. An icon on a screen, a phone vibrating or an LED light blinking is definitely an absolutely impersonal way to interact with the devices that handle our most personal information and details about our lives.
Instead, benefitting from these services currently requires humans to behave more like machines instead of having them adapt to our needs. Humanoid robots, on the other side, that can also use intelligent assistants are equipped with numerous sensors, which offers the possibility to benefit from emotion recognition feedback during social interactions and use it to improve the quality of the service and thus make them emotionally intelligent machines.
How does automatic emotion recognition work
From all the ways humans can convey emotions, e.g. facial expression, body gestures, physiological signals, speech or even from written word as sentiment, we focused on the facial expression. This goal requires the following steps:
 How many and which emotions are there? And how can we identify them? Discrete emotion theory maintains for all human beings there is a set of basic emotions that are innate and expressed and recognized across cultures and which combined produce all others. A particularly extended research is Paul Ekman’s, an american psychologist pioneer in the study of emotions, whose most influential work concludes with the finding that facial expressions can be universally recognized. He officially put forth six basic emotions in 1971: anger, fear, disgust, surprise, happiness, and sadness [1].
How many and which emotions are there? And how can we identify them? Discrete emotion theory maintains for all human beings there is a set of basic emotions that are innate and expressed and recognized across cultures and which combined produce all others. A particularly extended research is Paul Ekman’s, an american psychologist pioneer in the study of emotions, whose most influential work concludes with the finding that facial expressions can be universally recognized. He officially put forth six basic emotions in 1971: anger, fear, disgust, surprise, happiness, and sadness [1].
Each of these need to be characterized by models that relate them to actually measurable cues, i.e. muscle positions. In computer vision and image processing, a feature is any piece of information relevant for solving the computational task. Features for facial expression recognition are e.g. the position of facial landmarks such as the eyes and eyebrows, or appearance features such as changes in skin texture, wrinkling and deepening of facial furrows. The widely used Facial Action Coding System (FACS) [2] published in 2002, tries to systematically categorize the expressions based upon these physical features.
The recognition process first detects the face in an image and then identifies the landmarks and the other mentioned features. To track a dense set of landmarks, the so-called active appearance models [3] (AAMs) are a widely used approach. An AAM is a computer vision algorithm for matching a statistical model of object shape and appearance to an image. It decouples the shape from the appearance of a face image. A set of images and the coordinates of landmarks are provided to the algorithm, which then uses the difference between the current estimate of appearance and the target image to drive an optimization process.
The algorithms
Underlined by literature, the most promising approach for facial expression recognition appears to be deep neural networks. The task of emotion recognition from facial expression is tackled as a classification problem for which supervised learning comes as a natural method, using labeled training data of the set of basic emotions.
In the last few years the field of machine learning has made an extraordinary progress on addressing these difficult image classification tasks. In particular, the model called deep convolutional neural network seems to be able to achieve very reasonable performance, able to match and sometimes even exceed human performance in some domains. Researchers have demonstrated steady progress in computer vision by validating their work against ImageNet, an academic benchmark for computer vision. Successive models continue to exhibit improvements, each time achieving a new state-of-the-art result: QuocNet, AlexNet, Inception (GoogLeNet), BN-Inception-v2 or the latest model, Inception-v3.
Other often used algorithms include variants of dynamic Bayesian networks e.g., Hidden Markov Models, Conditional Random Fields, support vector machine classifiers and rule-based systems.
The training data
Deep neural networks are known for their need for large amounts of training data. The development and validation of these algorithms requires access to large image and video databases. Normally curated databases compiled in academic environments are employed. Relevant variation in the data is needed, which includes having different poses, illumination, resolution, occlusion, facial expression, actions, and their intensity and timing, and individual differences in subjects. Some well-known and widely used with research purposes databases are: the extended Cohn-Kanade Dataset (CK+) [4], FER-2013 [5] or the Japanese Female Facial Expressions (JAFFE) [6].
Pepper Robot

Pepper is a 1.20 m tall autonomous humanoid programmable robot, developed by Softbank robotics and designed for interaction with humans. It communicates in a natural and intuitive way, through speech, body movements and a tablet. It is equipped with lots of sensors (infrared, sonars, laser and bumpers) that allow it to move around autonomously, as well as cameras and a 3D sensor to detect the environment, faces and recognize human emotions. It runs an unix-based OS called NaoQi OS and is fully programmable in several languages like C++ and Python, and therefore its capabilities can be extended by implementing new features. Because it is connected to the internet, it is also possible to integrate any online services.
Comparison of Pepper’s emotion recognition of the basic emotions with other cutting-edge approaches
To assess how the emotion recognition from Pepper performs compared to other state-of-the-art solutions, we carried out an evaluation, integrating and testing them on the robot.

Pepper’s ALMood Module
Pepper’s ALMood Module, part of the standard libraries for Pepper, returns the instantaneous emotion perception extracted from a combination of data sources: facial expression and smile, acoustic voice emotion analysis, head angles, touch sensors, semantic analysis from speech, sound level and energy level of noise and movement detection.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 |
Results from ALMood::currentPersonState() method : { "valence" : { value, confidence }, "attention" : { value, confidence }, "bodyLanguageState" : { "ease" : { level, confidence } }, "smile" : { value, confidence }, "expressions" :
{ "anger" : { value, confidence }, "joy" : { value, confidence }, "sorrow" : { value, confidence }, "calm" : { value, confidence }, "surprise" : { value, confidence }, "laughter" : { value, confidence }, "excitement" : { value, confidence }, } } |
Some of these cues rely on Real-Time Facial Expression Estimation Technology services from OMRON. This technology combines the company’s proprietary 3D model-fitting technology and an statistical classification method, based on a massive database of facial images.
Facial expression values are represented as real values in the range (0, 1) normalized, i.e. so that add up to 1, same as the output from a soft-max function, often used in the final layer of neural networks applied to classification problems. This function is commonly used to highlight the largest values suppressing those which are significantly below the maximum value. In this condition, they are particularly easy to compare with one another and the final result is simply the maximum value of the array.
Deep Convolutional Neural Network, using Tensorflow
Convolutional Neural Networks, likewise referred to as ConvNets or CNNs, are a kind of neural networks that have proven highly effective in image recognition and classification tasks, such as identifying faces or objects in images.
The implementation is programmed making use of the TFLearn library on top of TensorFlow. CV2 is also used, to extract the contents of the image and reshape it to the correct format that is passed to the model’s prediction method.
The model employed has been used by several research studies and is based on a slight variation of the Alexnet model: the network starts with an input layer of 48 by 48, matching the size of the input data. This layer is followed by one convolutional layer, a local contrast normalization layer, and a max-pooling layer respectively. The network is finished with two more convolutional layers and one fully connected layer, connected to a soft-max output layer. Dropout was applied to the fully connected layer and all layers contain ReLu units. Also a second maxpooling layer is applied to reduce the number of parameters.
The DCNN network model needs to be trained in order to learn, which is a step that may require many hours or several days depending on the resources. The training data used is the FER2013 dataset [5].
The trained network returns the likelihood for each expression to be depicted by the user, the biggest appearing face, in a range from 0 to 1. The output with the highest value is assumed to be the current emotion from the basic emotions: happiness, sadness, anger, surprise, disgust, fear and neutral.
Google’s Machine Learning Cloud Vision API
The neural net-based Machine Learning Platform provides machine learning services with pre-trained models that can be used through APIs with a JSON REST interface, either by making direct HTTP requests to the server or with the client libraries, offered in several programming languages.
The Cloud Vision API exposes a method „images.annotate“ that runs the image detection and annotation for configurable features in one or more images and returns the requested annotation information. The image data is to be sent base64-encoded or providing a Google Cloud Storage URI. The available annotations are: FACE_DETECTION, LANDMARK_DETECTION LOGO_DETECTION LABEL_DETECTION TEXT_DETECTION SAFE_SEARCH_DETECTION, IMAGE_PROPERTIES
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
Results from HTTP POST to https://cloud.google.com/vision/docs/reference/rest/v1/images/annotate
for face detection annotations :
{
”joyLikelihood": enum(Likelihood),
"sorrowLikelihood": enum(Likelihood),
"angerLikelihood": enum(Likelihood),
"surpriseLikelihood": enum(Likelihood), } |
The values indicate the likelihood of each of the emotions in the range: UNKNOWN, VERY_UNLIKELY, UNLIKELY, POSSIBLE, LIKELY, VERY_LIKELY.
Microsoft’s Cognitive Services Emotion Cloud API
Microsoft Cognitive Services, formerly known as Project Oxford, are a set of APIs, SDKs and services of Microsoft’s machine learning based features.
The Face API takes as input an image and returns information related to the faces found in it such as emotion scores among many other face attributes represented as real values normalized, in the range from 0 to 1. Images can be supplied in two ways: via a URL or as image data sent within the request.
|
1 2 3 4 5 6 7 8 9 10 11 12 |
Results from HTTP POST to https://northeurope.api.cognitive.microsoft.com/face/v1.0/detect?returnFaceAttributes=emotion: { "anger": number, "contempt": number, "disgust": number, "fear": number, "happiness": number, "neutral": number, "sadness": number, "surprise": number } |
Kairos’ Emotion Analysis Cloud API
According to the documentation, Kairos’ Emotion Analysis software measures total attention time, number of glances, blink detection, and attention span, can understand positive, negative and neutral sentiments and detect facial expressions including smiles, frowns, anger, and surprise. It can be integrated using their APIs and SDKs.
The media uploaded can be an image or a video but the engine appears to be tuned to perform best on video to learn the baseline expressions of the person over time and adjust to compensate for a person’s natural resting expression, which makes the emotion recognition from a single image not as accurate.
The process involves an HTTP POST request to the API to create a new media object to be processed, to which the response includes the ID of the media uploaded. We need this ID for the second HTTP GET request which, in turn will return the results of the uploaded piece of media, the confidence for the set of emotions, not normalized, in the range from 0 to 100.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
Results :
{
"anger": number,
"disgust": number,
"fear": number,
"joy": number,
"sadness": number,
"surprise": number
} |
Evaluation

We’ve evaluated the performance of each of the solutions capturing images with Pepper’s cameras using a) emotion-tagged photos from the Cohn-Kanade (CK+) database and b) real subjects in both cases for the emotions: happy, sad, neutral, surprised, and angry and extracted the predominant emotion detected by each algorithm from the results.
In order to ensure some variation in the participants, among the 19 subjects there were people from different nationalities, females and males in the age range from 25 to 49 (mean=35, stdev=6). Also, in order to be able to make fair comparisons in every test the conditions were the same in terms of light, position, orientation and distance to the robot.
The emotion recognition has been tested with posed expressions i.e. in absence of an underlying emotional state as well as with spontaneous reactions, i.e. congruent with an underlying emotional state by means of emotion elicitation techniques. These have been evaluated separately due to recent research that asserts the potential importance of dynamic aspects, such as speed of onset and offset of the expression as well as the degree of irregularity of facial movement for the encoding of spontaneous versus deliberate emotional facial expressions.
The image shows the predominant emotion detected by each algorithm as a demo.
Results and conclusion
As well as in other research studies, not all emotions were recognized with the same accuracy. In general, the most easily detected emotion across all of the algortihms is a happy expression, with an extremely accurate detection rate that goes up to 100% in some cases while angry and sad expressions appear to be the hardest to identify. For both of those concrete cases, Pepper’s recognition as well as the self-trained convolutional neural network performed a little bit better than the rest.
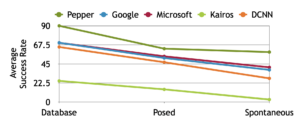
The average results graph illustrates the same tendency for each of the solutions: database images could be correctly interpreted without major problems. The reason these expressions are recognized so accurately may lie in the fact that these expressions are „pure“ according to experts, who characterized them as forms of the standard. It is notably more difficult to identify the posed expressions by the subjects and the rates are even lower for spontaneous reactions. However, Pepper’s algorithm seems to be trained well enough to maintain a compelling success rate of almost 60% even with these more subtle or confusing movements.
Still, Google’s and Microsoft’s services return values which can definitely be relied on, especially when it comes to distinguish a neutral look from an expression and spotting those images where a smile can be seen, which definitely seems to be their strength. An assumption is that these numbers would be even better if the images used had a higher resolution. To match the resolution of Pepper’s algorithm the pictures taken had a resolution of 640 x 480px, which depending on the position and distance to the face might in some cases not be enough to precisely differentiate an emotion and chances are the scores for two of them are too close.
As it can be appreciated, Kairos’s algorithm performance using still images as media input can not reach such rates at all, not even by far. The way it seems, this has been tuned for best performance using video rather than static images, where some knowledge about the personal characteristics of the individuals can be learned over time. However, the expectations for the execution with still images was definitely higher. It is intriguing to note that the results obtained with the DCNN implementation do not differ that much from others, in all situations. In this case, the images it was trained on were certainly different from those obtained in the laboratory. This leads to the assumption that these kind of algorithms could perform surprisingly well when they are trained with the same specific data they will be later used with.
To improve these results in automated emotion recognition, a possibility is to go for a multi-modal approach, i.e. that relies on several signals in addition to the facial expression. These relate to different aspects of the subject’s communication, such as vocal expressions, which among others includes words, utterances and pauses, or physiological cues like heart rate and skin temperature or gestures. The combination of several sources would result in a more reliable output, decreasing the probability of misinterpreting signals.
Being able to recognize human emotions is just the first step towards emotionally intelligent machines. This can be used to adapt the robot’s behavior and thus improve the quality of human-machine interaction.
References
- [1] P. Ekman, Universals and Cultural Differences in Facial Expressions of Emotion. University of Nebraska Press,1971.
- [2] P.Ekman,W.V.Friesen,andJ.C.Hager,“Thefacialactioncodingsystem,“inResearchNexus eBook, 2002.
- [3] T. F. Cootes, G. J. Edwards, and C. J. Taylor, “Active appearance models,“ IEEE Trans. Pattern Analysis and Machine Intelligence, vol. 23, pp. 681–685, June 2001.
- [4] P. Lucey, J. F. Cohn, T. Kanade, J. M. Saragih, Z. Ambadar, and I. A. Matthews, “The extended cohn-kanade dataset (CK+): A complete dataset for action unit and emotion-specified expres- sion,“ in IEEE Conference on Computer Vision and Pattern Recognition, CVPR Workshops 2010, San Francisco, CA, USA, 13-18 June, 2010, pp. 94–101, 2010.
- [5] “Challenges in representation learning: Facial expression recognition challenge.“ http://www.kaggle.com/c/ challengesin-representation-learning-facial-expression-recognitionchallenge. Accessed: 2017-01-23.
- [6] M. J. Lyons, S. Akamatsu, M. Kamachi, and J. Gyoba, “Coding facial expressions with gabor wavelets,“ in 3rd International Conference on Face & Gesture Recognition (FG’98), April 14- 16, 1998, Nara, Japan, pp. 200–205, 1998.



2 Kommentare