
Notice:
This post is older than 5 years – the content might be outdated.
In the last years, artificial neural networks (ANN) have successfully been applied across a number of tasks, such as image classification, speech recognition and natural language understanding. Two main drivers, firstly a large amount of (labelled) data, and secondly growing compute resources, allowed to use technology that dates back to the 1960s and break records on many benchmarks. However, designing well-performing ANNs requires expert knowledge and experience. Neuroevolution aims at solving this difficult and often time-consuming process by applying evolutionary techniques.
This article aims to provide an introduction to the re-emerging field of neuroevolution by supplying a definition, differentiating between other fields and areas and giving an overview by summarising a number of recent research papers.
Motivation
Inspired by biological neural networks, ANNs consist of many artificial neurons that are connected to each other. In a process, mostly referred to as training or learning, ANNs are optimised to solve specific, predefined tasks such as detecting faces. Learning is usually realised by employing a form of stochastic gradient descent (SGD) in order to change the network parameters in such a way that a future prediction for the same input is closer to the desired output.
The architecture of a network, i.e. how the neurons are connected to each other, plays a very important role in whether or not an ANN can be trained to successfully learn a task. Over the years, human experts carefully designed complex architectures such as the VGGNet, AlexNet, GoogleNet, ResNet and many more to achieve and often surpass human-level performance on many different tasks. However, there is no single architecture that is sufficient for all tasks, and therefore manually designing well performing ANNs is a very challenging, time consuming and complex task that requires knowledge and experience. A typical ten layer network, for example, can have ~10^10 candidate networks. This makes it impractical to evaluate all combinations and select the best performing one.
Consequently, a lot of effort is currently put into automating the process of finding good ANN architectures. Solving this requires answering many questions, such as i) how to design the components of the architecture, ii) how to put them together, and iii) how to set the hyperparameters. There are two different paradigms that caught people’s attention in approaching this problems, namely a) using artificial intelligence (AI) based search methods, and b) using evolutionary techniques to generate networks. The latter is referred to as neuroevolution and, similar to machine learning, is “… yet another example that old algorithms combined with modern amounts of computing can work surprisingly well“ (Uber AI Labs team).
Definition
Let’s begin by looking at a few definitions:
„Neuroevolution, or neuro-evolution, is a form of artificial intelligence that uses evolutionary algorithms to generate artificial neural networks (ANN), parameters, topology and rules.“ Wikipedia
“Neuroevolution is a machine learning technique that applies evolutionary algorithms to construct artificial neural networks, taking inspiration from the evolution of biological nervous systems in nature.“ Scholarpedia
“The class of methods for training artificial neural networks with genetic algorithms.“ Wiktionary
As can be seen, neuroevolution is a technique that applies biologically inspired methods to evolve artificial neural networks. Here, biologically inspired methods refer to evolutionary algorithms which use a population-based metaheuristic and mechanisms such as selection, reproduction, recombination and mutation to generate solutions. First methods using neuroevolution can be traced back to the 1980s and 1990s, where direct genetic algorithms were used to evolve the weights of fixed ANNs.
Related fields and areas
Neuroevolution vs AI
Since neuroevolution aims at evolving ANNs, what is the relation between neuroevolution, artificial intelligence (AI) and machine/deep learning? AI research, in its broad definition, aims at computing intelligence, i.e. developing machines that can demonstrate human- and/or animal-like intelligence by perceiving its environment and taking actions in order to achieve its goals.
Neuroevolution vs ML
Machine learning (ML), similarly to deep learning, is a field that utilises statistical techniques in order to learn a specific task with data (in contrast to being explicitly programmed). Therefore, ANNs are considered one of the many approaches to machine learning. Furthermore, neuroevolution measures performance in terms of a fitness metric and hence works with sparse feedback (such as winning a game) in contrast to conventional machine/deep learning techniques which often rely on gradient descent to guide optimisation. Neuroevolution, therefore, can be applied more broadly because it does not require a large set of correct input-output pairs. Instead, it only requires that a) the performance can somehow be measured over time, and b) the behaviour of the networks can be modified through evolution.
Neuroevolution vs AutoML
Automated machine learning (AutoML) has the goal of having an AI based solution to fully automate the end-to-end process of applying machine learning to problems. In practice, one or many human experts have to apply pre-processing, feature engineering, feature extraction and feature selection before a dataset is ready. Afterwards, one has to select proper algorithms and tune hyperparameters in order to maximise a models performance. Depending on the specific AI based solution, AutoML can be seen as neuroevolution. Google AI, for example, presented both a reinforcement learning approach as well as an evolutionary approach to find, i.e. generate, ANNs and refer to both of them as AutoML.
Neuroevolution vs EAs
Evolutionary algorithms (EAs), which are a subset of evolutionary computation, use biologically inspired evolution mechanisms. A population of individuals (often referred to as genotypes or genomes) represent candidate solutions (referred to as phenotypes) to an optimisation problem. The performance of individuals, i.e. quality or fitness of the solutions, is measured over time and determines which individuals are selected for reproduction. Once parents are selected, offspring is generated by recombination/crossover mechanisms and mutation. Evolution takes place by repeating this process. The process can be terminated if, for example, an individual achieves a certain fitness, an absolute number of generations is reached, or there has been no improvement over a certain number of generations.
There are many different types and techniques of evolutionary computation, for example, EAs, genetic algorithms (GAs), particle swarm optimisation, swarm intelligence, ant colony optimisation, etc. Most EAs work very similarly and only differ in the specific implementation details of the mechanisms responsible for evolution. GAs, for example, usually seek solutions to a problem in the form of strings.
One very important aspect in EAs is the specific implementation of encoding individuals (ANNs in our case). There are two different kinds of encoding, namely a) direct encoding, and b) indirect encoding. The former refers to encoding every neuron and connection directly in the genome. In the latter, schemes of the genotype indirectly specify how the individual (i.e. network) should be generated/constructed. Choosing a proper encoding mechanism is important because it affects the size and expressiveness of genotypes, search space, modularity, compression and mapping to the problem domain.
State-of-the-art
Evolving artificial neural networks
Employing neuroevolution techniques to evolve ANNs dates back many years. In „Evolving Artificial Neural Networks“ published in 1999, author Xin Yao reviews and discusses different methods to combine EAs with ANNs. Evolutionary artificial neural networks (EANNs), as they are called in the paper, refer to a class of ANNs which, additionally to learning, employ evolution as another key form of adaptation.
Originally, a GA was used to evolve the weights of a fixed ANN. In 2002, Stanley and Miikkulainen showed that simultaneously evolving the architecture using the NEAT (NeuroEvolution of Augmenting Topologies) algorithm is advantageous. Since then, a lot of effort is put into finding new and better methods to evolve well performing ANNs.
NEAT evolves both the parameters and architecture of ANNs and thus is an example of TWEANN (Topology and Weight Evolving Artificial Neural Network). NEAT employs a set of three different mutations: i) modify a weight, ii) add a connection between nodes, and iii) insert a node while splitting an existing connection.
Moreover, NEAT offers a mechanism to recombine two different models into one, and a strategy known as fitness sharing to promote diversity. NEAT uses a direct encoding scheme to encode the full network (each neuron and connection is represented explicitly). Consequently, there is no need to define rules for network construction and the representation is less compact. An evolution usually starts with very simple networks such as a perceptron and grows as evolution progresses.
Over the years, many extensions have been developed. One of them is HyperNEAT, which addresses the encoding issue when evolving large-scale ANNs. Instead of representing each parameter explicitly, it uses an indirect encoding mechanism to encode a large amount of parameters in the genes.
Novelty search is another invention that abandons the goal to maximise a fitness function. Instead, it rewards individuals that behave differently. This change often leads to much better solutions in the end because novel solutions perform badly in the beginning and need time to fully manifest their potential.
Large-scale evolution of image classifiers
In 2017, Google published „Large-Scale Evolution of Image Classifiers“ in which they try to minimise human participation from discovering ANNs. More specifically, they use EAs and present novel mutation operators that are able to navigate large search spaces.
A fully-trained model (no post-processing required) that achieves state-of-the-art performance is obtained from trivial initial conditions. Additionally, the transition of the CIFAR-10 to the CIFAR-100 dataset did not require any modifications. The algorithm must evolve complex neural networks and structures such as convolutional neural networks (CNN) on its own.
A large search space is enabled by allowing to insert and remove whole layers and not restricting the possible values to choose from (yielding a “dense“ search space). Backpropagation is used to optimise the weights. The schema of the used EA is an example of tournament selection: a worker selects two individuals from the population at each evolutionary step and compares their fitness. The worst of the pair is immediately removed, while the best pair is selected to be a parent. A parent undergoes reproduction by producing a copy of itself and applying mutation. The modified copy (a child) is trained and put back into the population. The worker picks a mutation at random from a predetermined set (altering learning rate, reset weights, insert and remove convolutions, add and skip connections, etc.).
A massively-parallel, lock-free infrastructure is employed to realise this strategy. Many workers operate asynchronously on different computers, do not communicate with each other and only share the population (of size 1000) which is stored on a file system.
Every individual of a starting population consists of just a single-layer model with no convolutions. This choice of initial poor performers forces evolution to discover better architectures. The combination of poor initial conditions and a large search space, which is only limited by the defined mutation set, restricts the experimenter’s impact.
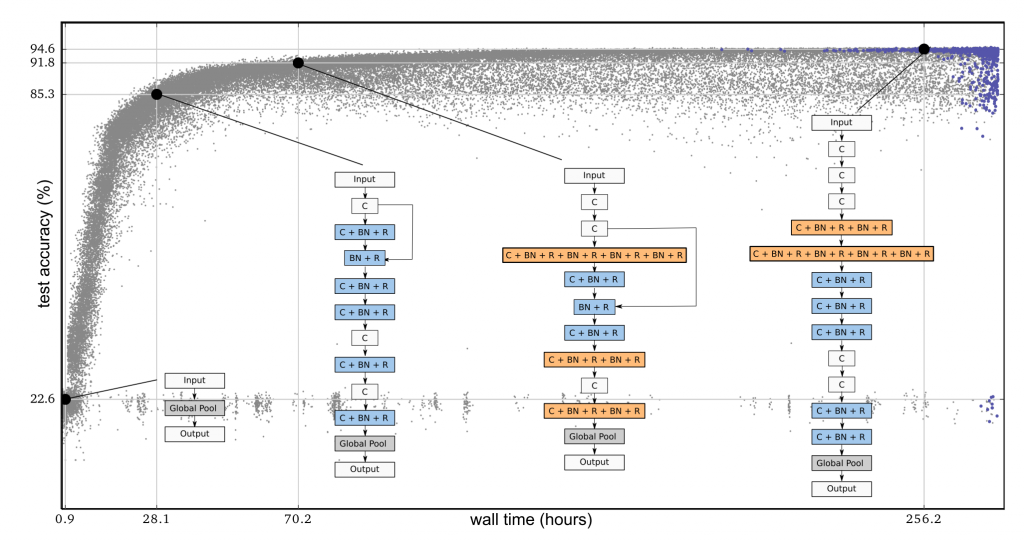
The conclusion of the paper reads as follows:
„In this paper we have shown that (i) neuro-evolution is capable of constructing large, accurate networks for two challenging and popular image classification benchmarks; (ii) neuro-evolution can do this starting from trivial initial conditions while searching a very large space; (iii) the process, once started, needs no experimenter participation; and (iv) the process yields fully trained models.“
Evolving deep neural networks
At about the same time, members of the university of Texas proposed an automated method called CoDeepNEAT (Coevolution DeepNEAT) for optimising deep learning architectures through evolution. It extends existing neuroevolution methods to topology, components, and hyperparameters. Based on NEAT, which has been successful in evolving topologies and weights of relatively small networks, CoDeepNEAT is extended to evolve components, topologies and hyperparameters.
First, NEAT is extended to DeepNEAT in order to evolve deep neural networks. The fundamental process is the same: a population of chromosomes (represented by a graph) is created and structure (nodes and edges) is added over generations through mutation. Whereas in NEAT each node represents a neuron, each node in DeepNEAT represents a layer. Each node in DeepNEAT contains a table of real and binary valued hyperparameters such as the type of layer and the properties of that layer. The edges simply indicate how the nodes (e.g. layers) are connected. Constructing a deep network is done by traversing the chromosome graph and replacing each node with the corresponding layer. Additionally, the chromosome contains a set of global hyperparameters such as the learning rate. A merging layer is applied where necessary to allow arbitrary connectivity between layers to ensure same sizes. During fitness evaluation, each chromosome is converted into a network and trained for a fixed number of epochs. After the training is complete, a metric is returned to DeepNEAT that indicates the network’s performance, and a fitness value is assigned to the corresponding chromosome in the population. Although DeepNEAT can evolve well performing deep neural networks, the structures are often complex and unprincipled because the allowed search space is too large. Therefore, it is extended to evolve modules and blueprints instead.
Motivated by the fact that most successful networks, such as GoogleNet and ResNet are composed of modules that are repeated multiple times, CoDeepNEAT is proposed. Two populations of modules and blueprints are evolved separately using the same methods as in DeepNEAT. The blueprint chromosome is a graph where each node contains a pointer to a specific module species. Each module chromosome is a graph that represents a small network. As shown in the figure, modules and blueprints are combined during fitness evaluation to create a larger network. For every node in the blueprint, a module is randomly chosen from the species to which that node points. The same module is used if multiple blueprint nodes point to the same module species. The fitnesses of the assembled networks are attributed back to the blueprints and the modules as the average fitness of all assembled networks containing that blueprint.
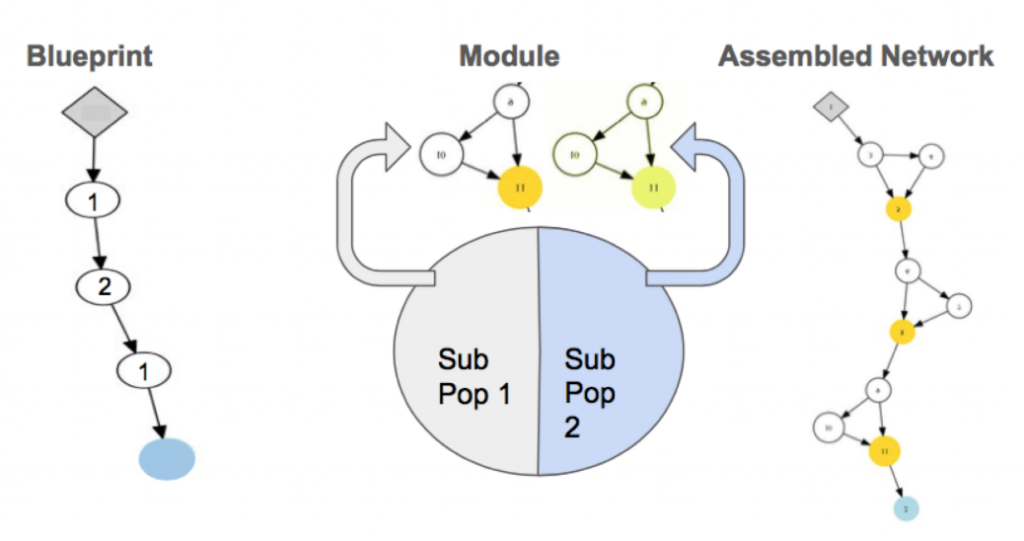
For the CIFAR-10 image classification benchmark, CoDeepNEAT is initialised with populations of 25 blueprints and 45 modules. 100 CNNs are assembled from these two populations for fitness evaluation every generation. Each node in the module chromosome represents a convolutional layer. Each network is trained for eight epochs and evaluated on the validation set to determine the classification accuracy. The best network after 72 generations is returned and trained for 300 epochs. A very interesting side effect of allowing limited training during evolution is that the best network evolved by CoDeepNEAT trains very fast.
In another series of experiments, CoDeepNEAT is extended with mutations in order to allow recurrent connections with the main goal to evolve LSTM architectures. Two types of mutations are added: one that enables a connection between LSTM layers, and the other adds or removes skip connections. The Penn Treebank (PTB) benchmark is used to evolve and evaluate the networks for language modelling (e.g. predicting the next word). A starting population of 50 LSTM networks is initialised with uniformly random initial connection weights. Each network consists of two recurrent layers with each having 650 hidden nodes. For fitness evaluation, each network is trained for 39 epochs. After 25 generations, the best network outperformed vanilla LSTM by 5% test-perplexity. The best LSTM variant consists of a feedback skip connection between the memory cells of two LSTM layers; a very interesting finding because it is similar to a recent hand-designed architecture. This demonstrates that improved LSTM variants can automatically be discovered by CoDeepNEAT with just two LSTM-specific mutations.
The conclusion of the paper reads as follows:
“Evolutionary optimisation makes it possible to construct more complex deep learning architectures than can be done by hand. The topology, components, and hyperparameters of the architecture can all be optimised simultaneously to fit the requirements of the task, resulting in superior performance“.
Evolving deep convolutional neural networks for image classification
In October 2017, a team from the university of Wellington proposed EvoCNN, a new method to use GAs to evolve architectures and connection weight initialisation values for deep convolutional neural networks. They argue that albeit evolutionary computation has been successfully applied to neural networks it does not scale well enough to evolve complicated architectures and large quantities of connection weights. They propose a variable-length gene encoding strategy to represent different building blocks and the unpredictable optimal depth of CNNs. Furthermore, a new scheme is developed to effectively initialise connection weights and a novel fitness evaluation which speeds up the heuristic search while using less computational resources.
They argue that the main issue of previous approaches is the high computational complexity due to a) the employed fitness evaluation (each individual in each generation must be trained to a certain degree in order to evaluate its performance), and b) large population size.
The main goal of weight initialisation is to allow for a good signal flow through the many layers of a network. If the weights are not properly initialised (too large or too small) the signal (and hence the weights) get stuck in the saturated or dead regions and thus do not contribute/learn during training. The commonly used Xavier method employs prior knowledge of the architecture. In particular, the Xavier method determines the range of initialisation based on the number of neurons in the input and output layer such that the weights follow a zero-mean distribution and a specific variance. Their argument is that the Xavier method only works well for optimal network architectures. Anyways, there has not been an existing evolutionary algorithm to search for connection weight initialisation for deep networks, including CNNs, due to the large number of weights and difficulty to encode such information into the chromosomes before.
Because it is not possible to explicitly declare hundreds of thousands of weights in chromosomes, EvoCNN uses two statistical real numbers, the standard deviation and mean value, to represent the numerous parameters. Once the best configuration is found, the weight values are sampled from the corresponding Gaussian distribution.
The individuals of a population are initialised in two steps. Firstly, a convolutional layer is added. Then, a convolutional layer or pooling layer is chosen via coin flip and repeated until a predefined length is met. Secondly, fully-connected layers are chosen and added. After these two steps are finished the respective parts are combined and returned.
Since image classification tasks are investigated, the classification error is used as a measure of fitness. Additionally, the number of weights is used as an indicator of the networks quality. Training each individual in each generation until convergence is impractical because of the sheer computational complexity. Instead, each individual is trained for a small number of epochs (e.g. 5-10). Then the mean value and standard deviation of classification errors are calculated on each batch of the evaluation dataset. Both values are employed as a measure of fitness for one individual. This means, three values are employed in total to report the fitness of one individual: standard deviation and mean value of classification error, and number of parameters. This is motivated by the fact, that it is sufficient to only investigate the statistical tendency of performance.
A standard binary tournament selection is employed to select parent solutions for the crossover operations. The mean values are used in a first step (together with a certain threshold). Afterwards, the number of parameters (together with a certain threshold) are considered. If the parent solution cannot be selected from this comparisons, the individual with the smaller standard deviation is chosen.
The offspring generation follows a general GA procedure. First, two parent solutions are selected from the mating pool. Then, the crossover operator is used to generate an offspring and apply the mutation operator on the generated offspring. Store the offspring and remove the parent solutions from the mating pool. This is repeated until the mating pool is empty.
The crossover process is divided into three phases, namely a) unit collection, b) unit alignment and crossover, and finally c) unit restore.
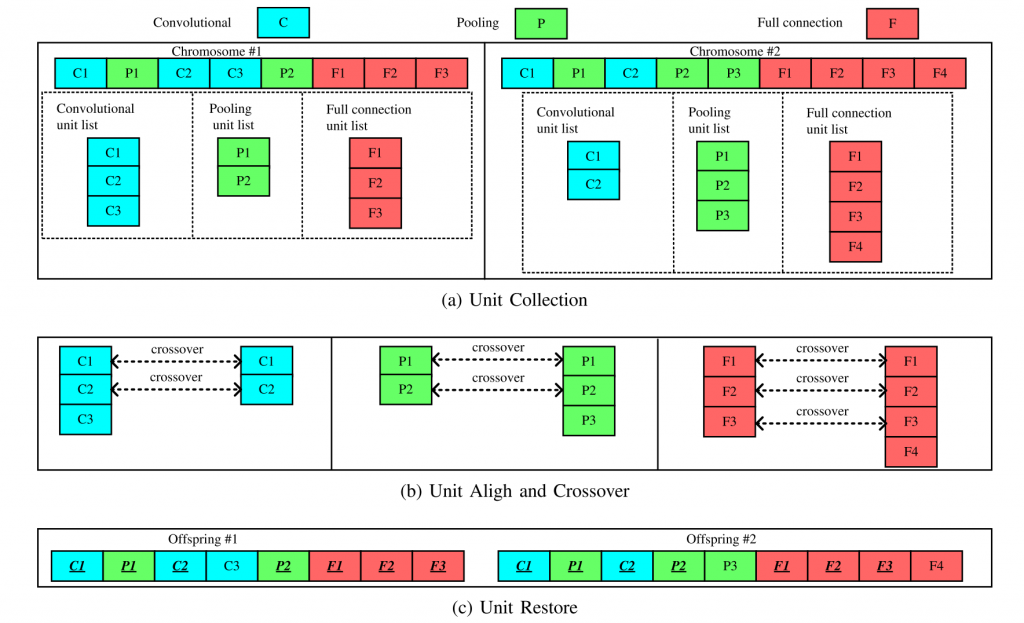
Mutations can be performed on each position of the units. Three different mutations are allowed, namely, a) unit added, b) unit removed, and c) unit modified. Each mutation operation has a probability of ⅓ to be selected. The modify mutation depends on the unit type, and if chosen, all information encoded in this unit is changed.
Environmental selection is implemented by selecting a fraction of the best performing individuals first and then the remaining individuals are selected by the modified tournament selection algorithm described above. Considering elitism and diversity simultaneously is expected to improve the performance of the proposed method. After evolution is complete, the best candidate is chosen by a set of parameters (e.g. fitness, accuracy, number of parameters), trained until convergence and finally evaluated.
The full evolution was run multiple times (30 independent runs) in order to investigate an average performance and differences between best and mean. In summary, the proposed method outperforms all other reported models which do not use data augmentation on multiple benchmarks.
Additionally, they initialise the evolved architectures with Xavier, compare them with their own and show that in fact the evolved weight initialisation further improves the classification error. Quite impressive results, in particular because they only trained on 2 GPUs for a couple of days.
Regularized evolution for image classifier architecture search
This past March, Google published a blog post in which they wonder if they can utilise their huge computational resources to evolve networks with minimal to no expert knowledge and participation. In „Large-Scale Evolution of Image Classifiers“, which we already covered, the idea was to start with trivial conditions and simple building blocks, and sit back and wait for the evolutionary process to evolve well-performing networks. In the more recent paper „Regularized Evolution for Image Classifier Architecture Search“, Google provides much more sophisticated building blocks and good initial conditions. In combination with modern hardware (Google’s then-new TPUv2 chips), the proposed evolution process produces state-of-the-art models on CIFAR-10 and ImageNet benchmarks.
Motivated by the fact, that earlier evolution could build upon very important inventions (i.e. building blocks) such as convolutions, ReLUs and batch-normalization, the idea is now to minimise the search space by removing/reducing large-scale errors in the architectures. Building upon a fixed stack of repeated cells as presented by Zoph. et al. (2017), evolution is tasked to develop the individual cells.
Although the allowed mutations within a cell are still simple, the fixed architecture is not as it was carefully designed by an expert. This drastically reduces the search space and makes it easier to achieve high-quality models because the models do not start from trivial conditions.
By comparing to other methods that exists in literature like neural architecture search with reinforcement learning by Zoph & Le (2016) (covered in the next chapter) and random search, they show that evolution is in fact faster to find well performing models, as well as producing models which use fewer floating-point operations.
The produced networks are called AmoebaNets. All experiments used a lot of computational resources by using hundreds of GPUs/TPUs for days. With these experiments Google aimed to provide a case study and glimpse into what can be achieved by throwing a huge amount of computational resources onto a problem and motivate that these experiments will become common in the future.
One important note is in regards to regularisation. Instead of removing the worst performing individual, they remove the oldest individual. Since each network is fully trained (no weight inheritance), this method guarantees that networks that keep a high accuracy when retrained are kept alive. Therefore, robustness is improved (only networks that remain accurate over generations survive) and the final models are able to achieve a higher accuracy.
Neural architecture search
Although neural architecture search (NAS) is not strictly neuroevolution by definition (because it does not use an EA to find solutions), it is worth mentioning in the context of generating ANNs.
In May 2017 Google published a blog post which presents first results of applying reinforcement learning to automate the design of machine learning models (the blog refers to the approach as AutoML, whereas in the paper it is called NAS).
The main motivation for NAS is the fact that designing well working architectures is difficult, time consuming and requires expert knowledge and experience. Feature engineering shifted to architecture design. The method presented in the paper can design networks from scratch thereby achieving state-of-the-art performance.
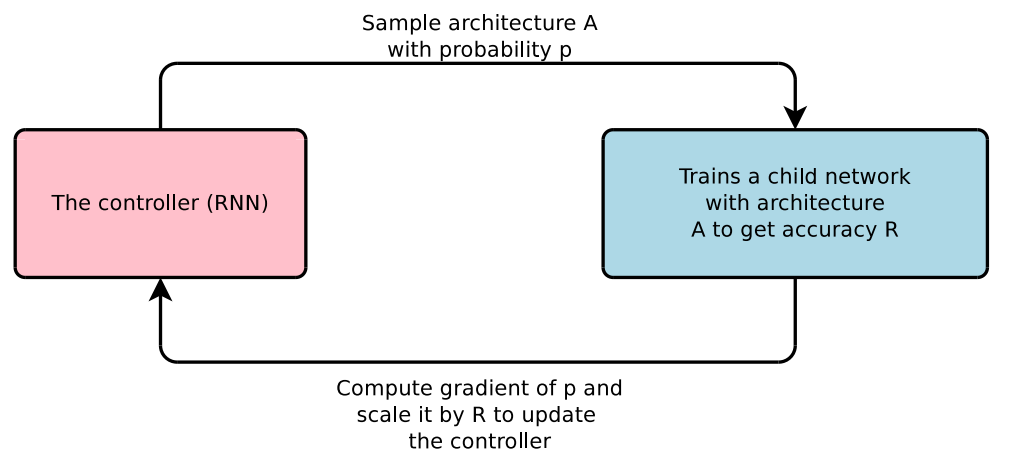
This work is based on the observation that the structure and connectivity (i.e. the architecture) can be specified by a variable-length string. The controller network is a recurrent neural network (RNN) and is well suited to produce such a string.
A controller network proposes child network architectures which are then trained and evaluated for a particular task. The feedback is used to inform the controller on how to improve the proposals on the next turn. Eventually, the controller learns to assign high probabilities to areas of architecture space that achieve better accuracy.
Efficient neural architecture search
Very recently (February 2018), a new approach named ENAS (Efficient Neural Architecture Search) was presented. It addressed one of the main issues of standard NAS which is computational complexity by enabling sharing of parameters among child models. Specifically, it is 1000x less expensive than NAS while achieving a state-of-the-art performance on CIFAR-10 and established a new state-of-the-art for the Penn Treebank benchmark.
While NAS takes 3-4 days on 450 GPUs, ENAS uses a single GPU for about 16 hours. The main contribution is forcing all child models to share weights. Thus, it is not necessary to retrain all models from scratch until convergence in each iteration to measure the accuracy and then throw the trained weights away. The apparent complications that arise from sharing weights, such as models utilising their weights differently, are addressed by previous work on transfer and multitask learning specifically for weights.
ENAS consists of a recurrent controller network that discovers networks by searching for an optimal subgraph within a large computational graph. The controller is trained with policy gradient to select a subgraph that maximises the expected reward. This is based on the observation that all the graphs that NAS ends up iterating over can be viewed as subgraphs of a larger graph. In particular, the NAS’s search space can be expressed as a single directed acyclic graph (DAG). This makes ENAS’s DAG a superposition of all possible child models in a search space of NAS.

Conclusion
Neuroevolution and AutoML attract a lot of interest in the AI community. Recent results suggest that the methods can be applied more broadly and are feasible in terms of computational complexity while achieving state-of-the-art performance.
Nevertheless, there is also a lot of possible future work. Many methods lack open-source implementations, let alone result reproductions. The available computational resources, albeit growing, set a limit to the search space that can be covered and measuring the speed of convergence is not consistent. Furthermore, research on combining parent neural networks to generate offspring is ongoing. Additionally, understanding and finding sophisticated methods to encode a large amount of parameters remains an open challenge.
Final words
Congratulations if you have made it this far! This article introduced neuroevolution, a field that uses evolutionary algorithms to automatically evolve artificial neural networks that achieve state-of-the-art performance, on par with architectures designed by human experts. We have learned very much by covering a lot of material, a number of definitions, related research areas and latest research results.
Read on
- Neuroevolution Scaling Artificial Neural Networks
- Generative Adversarial Networks explained
- Text Spotting using semi-supervised Generative Adversarial Networks
If you are curious about technology, have a look at our portfolio or head over to the current job openings!



2 Kommentare