Notice:
This post is older than 5 years – the content might be outdated.
In my past articles we learned a lot about Redis basics, high availability, CLI and performance. Today we take a look at Redis as a distributed keyspace for huge datasets.
Why Redis Partitioning is Useful: the Basics
Using Redis partitioning serves two main goals:
- Much larger databases using the sum of the memory of all Redis servers and
- scaling the compute power and network bandwidth to multiple cores/servers and network adapters.
As an example, let’s suppose we have four Redis instances R0, R1, R2, R3 and lots of keys representing users (user:1, user:2, …, user:n). There are many ways to perform partitioning, so here are just two to give you an idea.
The simplest way is range partitioning, mapping ranges of objects into specific Redis instances. For example ID 0 to ID 10000 are held by instance R0 while users with ID 10001 to ID 20000 are held by instance R1 and so forth. This system works and is used in practice. Its biggest disadvantage is that you need a table that maps ranges to instances. The table needs to be managed and you need a separate table for for every type of object.
An alternative to range partitioning is hash partitioning which works with any kind of key. Use a hash function (e.g. crc32) on the key name and you get a number, e.g. 93024922. Now use a modulo operation on this number to turn it into a number between 0 and 3. This number can then be mapped to one of the four Redis instances. In our case 93024922 modulo 4 equals 2, so I know my key foobar should be stored in the R2 instance.
Different implementations of partitioning
- Client side partitioning: The client selects the right node where to write and read a given key.
- Proxy assisted partitioning: The client sends requests to a proxy that is able to speak the Redis protocol. The proxy sends the request to the right Redis instances and the reply to the client (Twemproxy implements proxy assisted partitioning)
- Query routing: The client queries a random instance, and the instance will make sure to forward the query to the right node. Redis Cluster is a hybrid form of query routing. The client gets a redirected to message from the cluster node and connects to the correct instance.
Some features of Redis don’t play very well with partitioning, so here’s a list of disadvantages:
- Operations involving multiple keys are usually not supported.
- Redis transactions involving multiple keys can not be used.
- A huge key such as a very big sorted set can not be sharded
- Handling persistence is more complex, because you have to handle multiple RDB/AOF files. Those files need to be aggregated to create a backup of your databases.
- Rebalancing of data, adding and removing nodes, is possible during runtime.
Redis Cluster in practice
So that’s a lot of theory, but what about practice? Redis Cluster is available and production-ready since April 1st, 2015, requiring Redis 3.0 or higher. It uses a mix of query routing and client side partitioning. The Redis Cluster will distribute your dataset among multiple nodes and will add availability by using a master-slave model. Refer to figure 1 for an example.
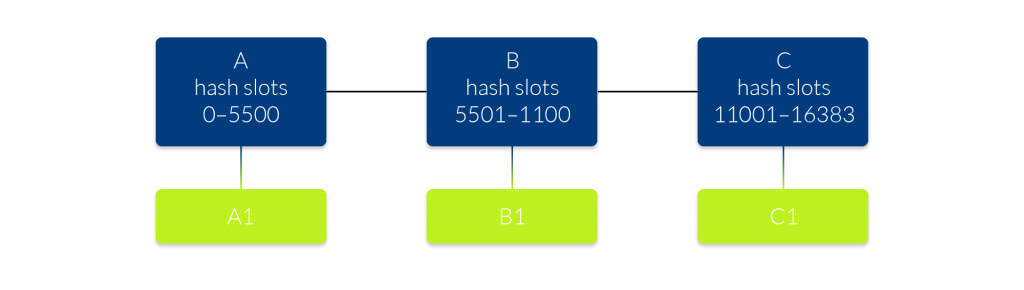
In the figure above we have three master nodes and the 16384 hash slots are divided between those instances (crc16 of key modulo 16384). Each of the master nodes has a slave for availability purposes. Node A1 replicates node A, and if A fails, A1 will become the new master of the hash slots 0 to 5500. If both nodes of a hash slot fail, e.g. A and A1, the cluster will not be able to continue to operate. For more availability you can add more slaves per hash slot. Redis Cluster is not able to guarantee strong consistency, because the replication is still asynchronous. During writes the following happens:
- Client writes to master B.
- Master B replies OK to the client.
- Master B propagates the writes to its slave B1.
There is now acknowledgement from B1, before master B gives its OK to the client. In the worst case the following happens:
- B accepts a write from the client and gives its OK.
- B crashes before the write is replicated to the slave B1.
In this case the write is lost forever. This is very similar to what happens with most databases that flush data to disk every second.
Building the Redis cluster
A setup that works as expected requires at least 6 empty Redis instances running in cluster mode. All nodes should be reachable in the same private network. Protected mode hast to be off, because we have no password protection and Redis is listening on all interfaces. Per node the Redis configuration ( redis.conf) looks as follows:
|
1 2 3 4 5 6 7 8 9 10 11 |
port 7000 cluster-enabled yes cluster-config-file /etc/redis/nodes.conf cluster-node-timeout 5000 appendonly yes protected-mode no |
This defines the port for the Redis instance to listen to, , the path to the global config file, the persistence AOF File and other parameters. The instance uses redis.conf to store the Cluster members, roles and node IDs. After starting the Redis instances, you will see the following message at the logfile:
|
1 |
No cluster configuration found, I'm 97a3a64667477371c4479320d683e4c8db5858b1 |
This ID is unique and serves as an identifier for this instance within the cluster. To initiate the cluster we use the redis-trib utility. This ruby file can be found at the src directory of the Redis source code distribution. It requires the redis gem:
|
1 |
gem install redis |
After installing ruby and the Redis gem you can create the cluster with the following command:
|
1 |
./redis-trib.rb create –replicas 1 192.168.67.100:7000 192.168.67.101:7000 192.168.67.102:7000 192.168.67.103:7000 192.168.67.104:7000 192.168.67.105:7000 |
The replicas option means that we want a slave for every master node. Redis-trib will offer you a configuration, and you can accept it by typing yes. When the setup is complete finally you’ll see a message like this:
|
1 |
[OK] All 16384 slots covered |
At this point the cluster is up and running. Now we can use it for some tests with the redis-cli:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 |
redis-cli -h 192.168.67.101 -c -p 7000 redis 192.168.67.101:7000> set foo bar -> Redirected to slot [12182] located at 192.168.67.102:7000 OK redis 192.168.67.102:7000> set hello world -> Redirected to slot [866] located at 192.168.67.101:7000 OK redis 192.168.67.101:7000> get foo -> Redirected to slot [12182] located at 192.168.67.102:7000 "bar" redis 192.168.67.102:7000> get hello -> Redirected to slot [866] located at 192.168.67.101:7000 "world" |
Managing the cluster
Here are some useful commands to manage your cluster using a mix of the redis-cli commands and the redis-trib utility.
| Command | Description |
|---|---|
| redis-cli -h $host -p $port cluster nodes | Get all nodes, roles and IDs of your cluster |
| ./redis-trib.rb check $host:$port | Check cluster status and health |
| ./redis-trib.rb add-node $host:$port $host:$port | Add a new node (first argument) to the cluster. Second argument is a node of the existing cluster |
| ./redis-trib.rb reshard $host:$port | Reshard a number of hash slots to a new node (via node-ID) |
| ./redis-trib.rb add-node –slave (--master-id xxxxxxx) $host:$port $host:$port | Add a new node (first argument) as a slave of a random master among the masters with less replicas. With the --master-id option you can add the slave to exactly the master you wish. |
| ./redis-trib del-node $host:$port ` | Remove a slave node from the cluster. To remove a master, use the same command, but the master must be empty (hold no keys). |
That concludes our short overview of Redis Cluster and how to manage it with different tools. To get more interesting stuff and details about Redis Cluster, visit the official site https://redis.io.
Thanks for your patience, see you next time.



One thought on “Redis Cluster and Partitioning”