This article sheds light on the question of why machine learning products mostly do not get into production even though they are enjoying an ongoing boom. Additionally, it shows how MLOps can help to tackle these challenges in the machine learning life cycle.
There is bad news for all companies planning to include machine learning (ML) products into their current systems: Most ML projects never get into production. Too often ML products reach their dead end once the experimentation phase is completed. While machine learning and artificial intelligence experience an ongoing boom, this fact seems to be disillusioning. In the remainder of this article, we will shed light on the question of where this obvious discrepancy comes from. Once we understand why it is so difficult to get the application into production, we have the chance to take action to overcome these difficulties. We then provide the reader with a high-level overview of how to design an ML application to assure a robust shift from PoC to production with a high degree of maintainability.
Change anything changes everything
At first glance, shipping machine learning applications to production should be straightforward – simply combine data science with traditional DevOps principles such as CI/CD, and off we go. In the short term, this may work but in the long term, such a naive approach is deadly. While maintenance costs (efforts) of traditional software products are already high, maintaining ML products is even more complex. Sculley et al. (2015) argue that for the former “strong abstraction boundaries using encapsulation and modular design help create maintainable code in which it is easy to make isolated changes and improvements.“ By contrast, distinct modularization within ML software products is effectively impossible, as the dynamic nature of data and models entangle the respective components of an ML product. To better carry the message of this, Sculley et al. (2015) introduced the CACE “Change Anything Changes Everything“ principle.
MLOps
Both research and industry are aware of this problem, and as a result, the field of MLOps has been established in recent years. The idea of MLOps is to ship ML models that were trained in a static and stable environment to a dynamic and therefore unstable production environment while ensuring reliable and efficient maintenance. To achieve this, MLOps adheres to the principles of DevOps but additionally recognizes ML-specific peculiarities – the interconnectivity of the components as well as the dynamic nature of the product induced by data and model. To apply best practice MLOps, it is critical to gain a conceptual understanding of the entanglement between the components. Only then can we understand how pitfalls propagate through the ML system which enables us to react appropriately.
To consider an ML product from a holistic perspective, one is best advised to think in terms of a machine learning life cycle (see figure 1). The diagram is adopted from Kaminwar et al. (2021). A machine learning life cycle is characterized by two main properties: First, all components are interconnected. Second, the ML workflow is represented as a cycle: following the argument of Amershi et al. (2019) due to the dynamic nature of an ML product the process never ends and therefore requires continuous reiterations through all components simultaneously. In general, the machine learning life cycle can be subdivided into 5 stages/phases/components – the Business Understanding phase, the Data Acquisition, the Modeling, the Deployment and Monitoring phase.
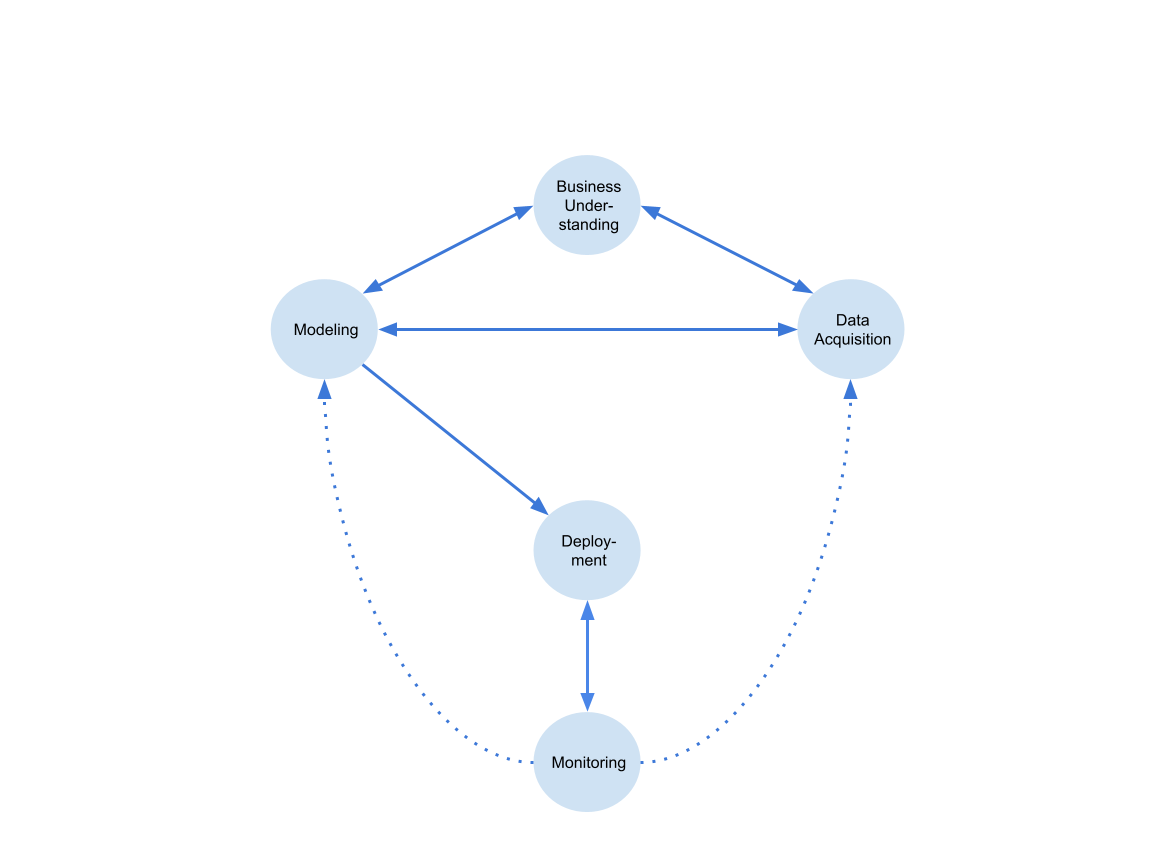
Business Understanding represents arguably the most crucial phase for any ML project. In this phase, data scientists communicate with domain experts to determine several key factors. The actual business problem is defined and translated into a machine learning problem. Evaluation metrics and validation strategies are determined in a way that they represent actual business metrics. Furthermore, success criteria must be defined as well as meaningful PoCs must be conducted to be able to assess the feasibility of the project. If this phase is not given sufficient importance, a considerable amount of technical debt is already introduced which results in heavy re-iterations at later stages or even in the abrupt end of the project. For instance, if evaluation metrics and validation strategies are wrongly specified, the ML model is not optimized for solving the business problem, and therefore, the whole application becomes useless.
Data Acquisition represents the phase at which a lot of time is traditionally spent. Without going into exhaustive detail, this phase is concerned with three aspects. Which data represents the business problem the best and how can it be preprocessed to be valuable. How can we assure that the training data is representative of the data during deployment, which is essential for a successful transition from the static training/experimentation phase to the dynamic production phase. Lastly, it is important to introduce a data versioning system to ensure reproducibility. This becomes crucial when several reiterations within the life cycle have been triggered. A successful data acquisition phase is highly dependent on an elaborate business understanding and elementary for the following modeling phase.
Modeling represents the phase where the preprocessed and cleaned data is taken, features are engineered, models are trained, validated, and selected and hyperparameters are tuned. Within this phase two aspects are important: We require model tracking and versioning for reproducibility. Similarly, to data versioning, we not only want to version code but also models – again this becomes elementary once reiterations are triggered. Further, oftentimes the design decision is made by a data scientist which is heavily influenced by a previous project experience and also prone to errors in terms of not all design options can be taken into account. To mitigate this risk at least to some extent, it is favorable to consider AutoML for the modeling phase. In the best case, the different phases are automatized and the data scientist must only be concerned with setting up the pipeline.
Deployment represents the “heart“ of the machine learning life cycle. In this phase, the provisioned ML pipeline meets the live data. The model output is generated and provided for a specific endpoint which can be another software product or a human. This component is also concerned with provisioning astable infrastructure which allows for easy down and up-scaling of resources. It orchestrates the single components and allows them to communicate with each other in an efficient and effective manner.
Monitoring can be considered as the “end“ or the “beginning“ of the life cycle. In traditional software products, monitoring refers to infrastructure monitoring. With respect to ML products, we additionally monitor data drifts and model degradation. When irregular behavior of the model is observed, monitoring (infrastructure) can trigger model retraining or initiate new data collection. To avoid considerable downtime, we require effective connections between the components. Due to the fact that the data during training only represents a snapshot of the “reality“ and is also dynamically changing due to a dynamic real-world environment, data drift and therefore model degradation represents a likely event and therefore, sophisticated monitoring is paramount for the maintainability of an ML product.
Within this blog post, we shed light on the complexity of deploying and maintaining a machine learning product. As discussed in the beginning, not being aware of the complexity is the fundamental reason why most machine learning projects fail. Yet, with the emergence of MLOps as an own discipline in software engineering, the occurring challenges are tackled. Still, most tools are solving one problem in isolation while disregarding the others. Note again, however, that the respective components cannot be considered isolatedly, and therefore, it remains challenging to define a holistic system that allows all frameworks to interact with each other in a seamless manner. Only if this is guaranteed, reiterations can be carried out quickly and without additional effort. We argue that to pursue this, a team of experienced data scientists, machine learning, and MLOps engineers is required to identify the common pitfalls at the beginning of the project and to build a solution that takes all the above considerations into account.
From Theory to Practice
This blog post is by no means the first that discusses the complexity of the machine learning life cycle and the need for sophisticated MLOps. Yet, there seem to be only limited resources that represent a mapping from theoretical considerations of the ML life cycle to practical implementations. There are in fact platforms that claim to provide a full end-to-end MLOps solution, however, it is doubtful to what extent these claims hold their promises. To evaluate open source frameworks such as kubeflow (Google) or metaflow (Netflix) or paid providers such as valohai would be beyond the scope of this post, although it would be very interesting to further investigate. We proceeded to build our own solutions with the help of open source components to be able to really understand the internal complexities of a matured MLOps platform.
To implement a holistic solution, we need to map the elaborated components of the ML life cycle to actual software tools. To pursue this, we have to deduce a tech stack that fully covers the machine learning life cycle: At the heart of the application is the compute platform where the application is deployed. To allow for incremental iterations we require a CI/CD pipeline and proper model, data, and code versioning tools. Beyond that, we need a monitoring tool that oversees the ML application during production. To open the black box, we need to visualize the predictions and the live data by means of a dashboard tool. Lastly, to persist a high degree of automation, we require to have an automated training pipeline that is triggered once the monitoring issues an alert.
Microservices as a proper design choice
The most fundamental design decision was to follow the principles of a microservice architecture. By doing so, we can consider each component of the ML life cycle as an independently deployable service where each service solves an isolated problem. Martin Fowler describes the characteristics of a microservice in his post “Microservices“ which prove to be suitable for designing an ML application. The first key characteristic is the “Componentization via Services“. This allows that changes in one component do not require changes in the whole application and therefore, reiterations, adjustments, or continued development can be carried out and redeployed quickly. Secondly, we consider the characteristic of “Smart endpoints and dumb pipes“ as crucial. This means that each service has its own domain logic and only receives requests and produces responses via lightweight messaging. Another interesting characteristic of a microservice architecture is summarized by Martin Fowler with “Products not Projects“. The idea behind this is that the development team takes full responsibility for the application in production. Following the argument of Martin Fowler this might be theoretically possible with a monolithic application, yet having fine granular microservices simplifies taking ownership. This is also well-aligned with the principle of organizing applications around business capabilities. The last aspect is very important to consider once we try to solve MLOps problems not only for one project but for multiple projects. To scale the applicability, different teams should build domain-agnostic solutions that can be put together in one platform. Introducing platform thinking to MLOps increases productivity and speed w.r.t. bringing ML models to production.
To implement the ML life cycle in the style of a microservice architecture, we build upon the following tech stack which serves as a foundation:
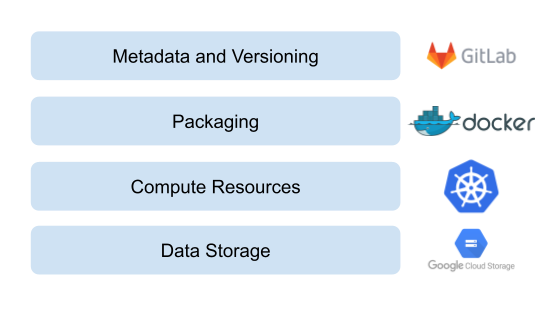
For data storage and compute resources we use the Google Cloud Storage and Google Kubernetes Engine (GKE). With Kubernetes we can conveniently implement the idea of the microservice architecture. The components are defined as containerized applications that are orchestrated via Kubernetes. The full ML application lives within the Kubernetes Cluster while, again, the respective components are deployed separately. By doing so, we can flexibly scale and schedule the respective components and thereby better respond to the respective requirements. The communication between components within the Cluster is ensured via exposed Services while UIs are exposed to the outside world via Ingresses. To manage the Kubernetes application we use Helm and to provide the infrastructure we use terraform. We use Gitlab for metadata and code versioning as well as Gitlab CI for continuous integration and deployment (CI/CD).
Once this framework is set up, we can continue with building the ML-specific components as independent microservices. For data and model versioning we rely on DVC and MLflow, respectively. MLflow is not only used for experiment tracking but also for serving the trained models. For automated model training, we leveraged H2O and for automated feature engineering, we use tsfresh (only suitable for time series data). Beyond that, we customize our own monitoring tool by building upon the framework provided by evidently AI. To store and persist the predictions and the features during deployment, we use InfluxDB, and to visualize the results, we use Grafana for Dashboarding. For lightweight messaging between the microservices we either leverage built-in APIs, APIs, or Apache Kafka.


