
This blog post gives an overview of an example data lake architecture implemented on the Google Cloud Platform, which is capable of operating on petabyte data scenarios while being compliant with GDPR and still able to derive business insights – even though data is anonymized! Also, we will demonstrate how restricted data access management is possible in such a setup.
In 2018 the General Data Protection Regulation (GDPR) went into effect. Just two years later the US state California followed with its California Consumer Privacy Act – and many more might follow.
All these privacy regulations have in common that they enforce legally binding guidelines on storing and processing user related data.
Since nowadays almost every modern company uses data for their business – and penalties for not following these regulations are enormous –, many of our customers are facing the challenge of adapting their architectures to these regulations.
GDPR, what is it all about?
While the GDPR covers many topics – some of them rather vaguely expressed – we want to focus on two main aspects relevant to keep your data lake compliant:
1. Retention: Personal identifiable information (PII) data must be either dropped or anonymized after a defined time period (defined by your legal department)
2. Data Deletion Requests (DDR): individuals have the right to have their personal data erased by inquiring a request
For both DDR and retention there are two ways to go: Either drop the data completely or anonymize it. While dropping data is easier, it might have an impact on your business since you cannot derive insights from your customer data anymore. Anonymizing the data on the other hand is more complex, but your business is still able to get insights from it (see Pic 1). For example, after the user’s name (and all other relevant PII attributes), “Alexander“ has been fully anonymized (hashed with a random seed) to “fsdfsdfwef“, analyzing on that data is valid.
On that end, the technical solution for DDR and retention are very similar: Either certain user requests (DDR) or a moving time window (retention) lead to the anonymization of data.

Data Lake Architecture
To fulfill the requirements mentioned before, we need an architecture that is capable of implementing these requirements.
Before we discuss the architecture as a whole, let’s have a closer look at the core components: What is their purpose and how do they interact with each other to eventually meet GDPR compliance?
Storage Layer
Delta & Google Cloud Storage


In the past it was tedious to modify already stored data in big data engineering architectures (e.g. Hadoop with Hive and HDFS). While possible, this is something the underlying system was not designed to do, resulting in high resource consumption and frustration.
From this pain, the motivation grew to change and hence many projects arose with the focus to bring ACID-like capabilities to big data storage. Some of the most prominent technologies are Apache Iceberg, Apache Hudi and Delta Lake.
Since Apache Spark & Delta Lake are both projects developed by Databricks it is a good fit, if your ETL workloads are already written in Spark because they have a seamless integration. Also GCP DataProc (see next section) offers native Delta Lake support.
While Delta has many more features, the most important one in regards to GDPR is the atomicity of transactions. Imagine if you would only anonymize part of your data while other parts are still sensitive in clear text because a transaction failed.
This aspect of modifying your data in a transactionally consistent manner is crucial to a data architecture that should meet the above-stated GDPR requirements.
To avoid accessing PII data by using Delta Lakes time travel, which allows you to access old versions of the data, the VACUUM operation should be executed frequently.
Delta relies on the Apache Parquet format, the resulting delta tables/parquet files will be stored on the Google Cloud Storage (GCS).
Application Layer
DataProc

Having identified sensible data for your use case the next step is to take care of it to be compliant. This can be done by either completely dropping the data or anonymizing it, so it can not be related to a certain user. The latter requires a way to modify the data for your needs. For example different PII fields need different anonymization strategies – while a ZIP code needs to be truncated the customer should be hashed.
Apache Spark is prominent for being a general purpose programming framework on big data which makes it a perfect fit to implement custom anonymization strategies on large datasets.
As a general data processing framework it allows us to leverage general programming capacities & language features of Scala, which helps scaling to a generic solution in code, instead of having very specific non-reusable SQL scripts for particular domain events.
GCP offers a managed service to run your Apache Spark workloads and for provisioning/sizing clusters respectively which is called Dataproc.
Besides Spark Dataproc additionally offers some other known projects from the big data space for example Presto and Druid. For the scope of this articles architecture we focus on Dataproc Spark though.
Dataproc also ships with a tight integration for the Delta .
Hence the choice for Dataproc with Spark application is a very natural choice in such a big data setup with batch/streaming workloads.
Composer

Cloud Composer is GCPs commercial managed service implementation of Apache Airflow. While it is technically not needed to make your data lake compliant, it can assist you in orchestrating the different steps needed for that (apply retention, DDR, …) in one central place.
Furthermore you can easily schedule ressource creation and deletion of DataProc clusters by natice Airflow-Operators, which is in general a good pattern when using cloud resources, as this will decrease your cloud bill.
Also it comes in very handy since you can easily execute the workloads based on a time schedule – exactly what you need to fulfill re-running retention in a moving window fashion.
Access Layer
BigQuery

Having proper data pipelines for your GDPR in place is half of the battle. You want to make your data easily available throughout your company, to enable your data driven business.
These requirements lead to one of the most prominent services on Google Cloud: BigQuery.
BigQuery is Google Cloud’s Data Warehouse that offers petabyte analytical capacities. More importantly, it integrates seamlessly with GCPs IAM which makes it easy to share datasets and manage (PII) permissions within your company.
So while Delta Lake provides handy technical features as a storage system and a close integration with Spark, it is not the best interface for end customers on the Google Cloud. Here, BigQuery shines with blazing speed and interconnectivity to BI tools like Looker. Additionally it integrates seamlessly with other GCP services – most importantly, IAM & Data Catalogue (see next section) which makes it very easy to manage access and permissions for datasets & tables.
These features make BigQuery the central interface for data consumption in our architecture. While the very access-restricted Delta Lake storage layer is used only by service accounts to transform raw data, BigQuery is used to serve the GDPR compliant data for product teams.
Data Catalog

Having sensible data in your access layer requires a regulated way of managing who is allowed to interact with that data. GCPs Data Catalog allows you to create so called policy tags. Policy tags are a great way to indicate sensible PII data in your table schemes and manage the access to that data respectively.
Concretely, one could create a policy tag called „pii_user_name“ and apply that policy tag to various BigQuery columns by editing the corresponding schema. By doing that, only IAM entities with the required permissions to this policy tag „pii_user_name“ are allowed to query that column which holds the name of the user. This is a very easy way of granting access to sensible data since you probably have a properly defined IAM concept in place already.
Most often it is convenient to group several policy tags together into a hierarchy – for example in a „highly-sensitive“ (e.g. consisting of policy tags „pii_credit_card_number“, …) and „low-sensitive“ group („pii_timestamp“, „pii_location“, …). Data catalog allows this grouping with so-called taxonomies. This furthermore facilitates the process of granting access to columns since now you only need to grant access to the root node/group, e.g. „highly-sensitive“ and the user will have access to all policy tags defined within that group (see Pic 2).
Furthermore, Data Catalog offers features for data discovery. Once a table is registered (for BQ this happens automatically), it is known to Data Catalog, yielding results if a search is executed for a column name or a description string (https://cloud.google.com/data-catalog/docs/how-to/search-reference).
It is possible to specify the search query in detail, e.g. searching for specific Tags (for example PII).

Architecture assemblement/discussion
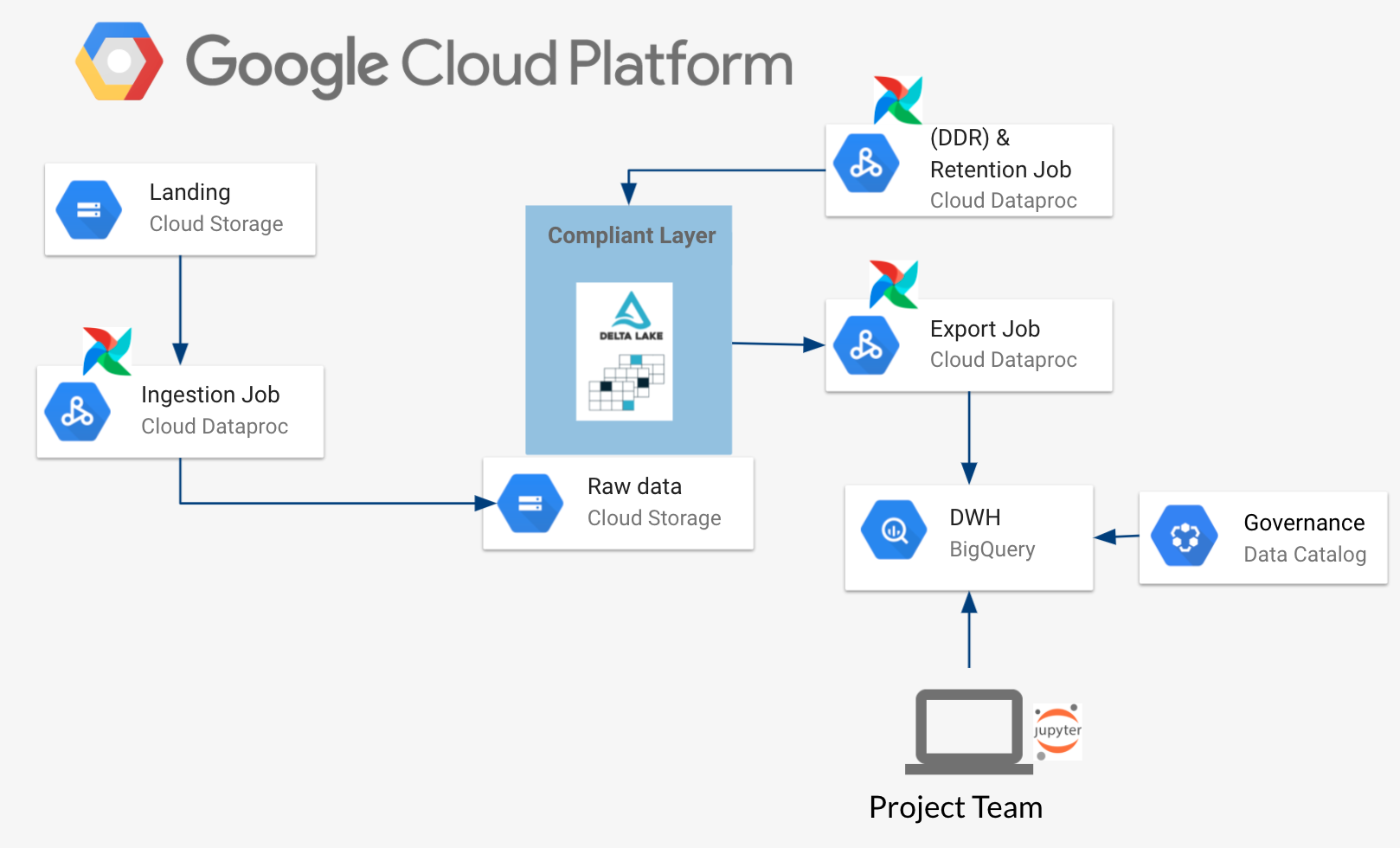
After having a look at the different components, let’s now review the architecture on a higher level.
In this architecture, Delta is used as a storage layer with ACID capabilities to transform data with different anonymization strategies to meet GDPR requirements. This storage layer is very restricted in access and only usable for service accounts, since it holds sensitive data. This design choice was made because BigQuery provides many features in giving access via IAM and integrates well with solutions like data catalog.
Furthermore, having Delta as a storage layer gives you more flexibility for downstream data applications – imagine that you want to have your data in a rather I/O-intense use case instead of an analytical intense use case. Data could easily be shifted from the same storage location (Delta) to some specific database optimized for that usecase (e.g. BigTable). This also offers more flexibility in case of moving to another cloud or even to an on-premise architecture since Delta has wide support across all these platforms.
In this architecture, Delta serves as a single source of truth: When a retention or DDR triggers the anonymization jobs (Spark on Dataproc), the corresponding data is anonymized and afterwards provisioned to BigQuery in the GDPR compliant form, ready for consumption.
On the one hand, this separation of storage and access layer (Delta & BigQuery) might result in more work and a higher cloud bill (since both systems hold the data). On the other hand, it makes your architecture more flexible and robust since data can be always re-provisioned from the access restricted storage layer, if something fails on the access layer.
Summary & Lookout
This article gives an overview on how to be compliant in the sense of DDR and retention and what services on the Google Cloud fit.
This is one approach to how a GDPR-compliant data lake architecture could look like. A thorough analysis of your use cases should be taken into account beforehand. If your use case does not need to access data older than a few days or does not make use of PII data the easiest way to be GDPR-compliant is just dropping data or not ingesting sensitive fields. If you on the other hand need to make sense of your data, e.g. by joining anonymized data in a consistent way, a sophisticated approach & architecture like the one described in this article is needed.


