
This article takes a look at a security proof of concept for multifarious data and describes best practices as well as limitations when handling data in different formats that are not initially known.
Data connects everything in information technology. User accounts at your workplace, shipping information of packages, sensor data in a manufacturing factory – in all of those examples huge amounts of data are being saved and processed. From a security standpoint, we need sufficient protection for all types of non-public data and adequate access control. In an environment where all data types are known in advance, access control can be implemented using widespread access control models, such as role-based Access Control (RBAC). The use of common access control models is supported by most Identity and Access Management (IAM) solutions, such as Keycloak, Auth0 and Okta, and must not be implemented from scratch. However, in some cases the underlying data is multifarious, i.e. having different formats that might not be known in advance. In the following article, I will take a look at a concrete use case with such multifarious data and present the general security proof of concept that was developed for it. I will also describe the best practices and limitations I encountered while dealing with multifarious data, as well as some ideas to make the development of a security concept easier.
Use case
In this article, I will take a look at a security system that is built upon multifarious data. It is a use case of energy informatics where multiple data sources such as power plants, weather stations, batteries and energy consumers are queried, the data is combined and displayed to the user on a dashboard. The data can come from different organizations, and some of it can be confidential or private. For instance, the energy consumption of a building can be used to extrapolate personal data of its inhabitants, e.g. when they are coming and leaving, or even what electrical devices are being used. Otherwise, some organizations might choose not to publish their research data, or not to make some unfinished dashboards visible to the general public.
Goals
The main goal of this work was to establish a system that can accommodate different levels of data protection, i.e. granularities. We divide different granularities into the following three levels, using an abstract collection of weather data as an example:
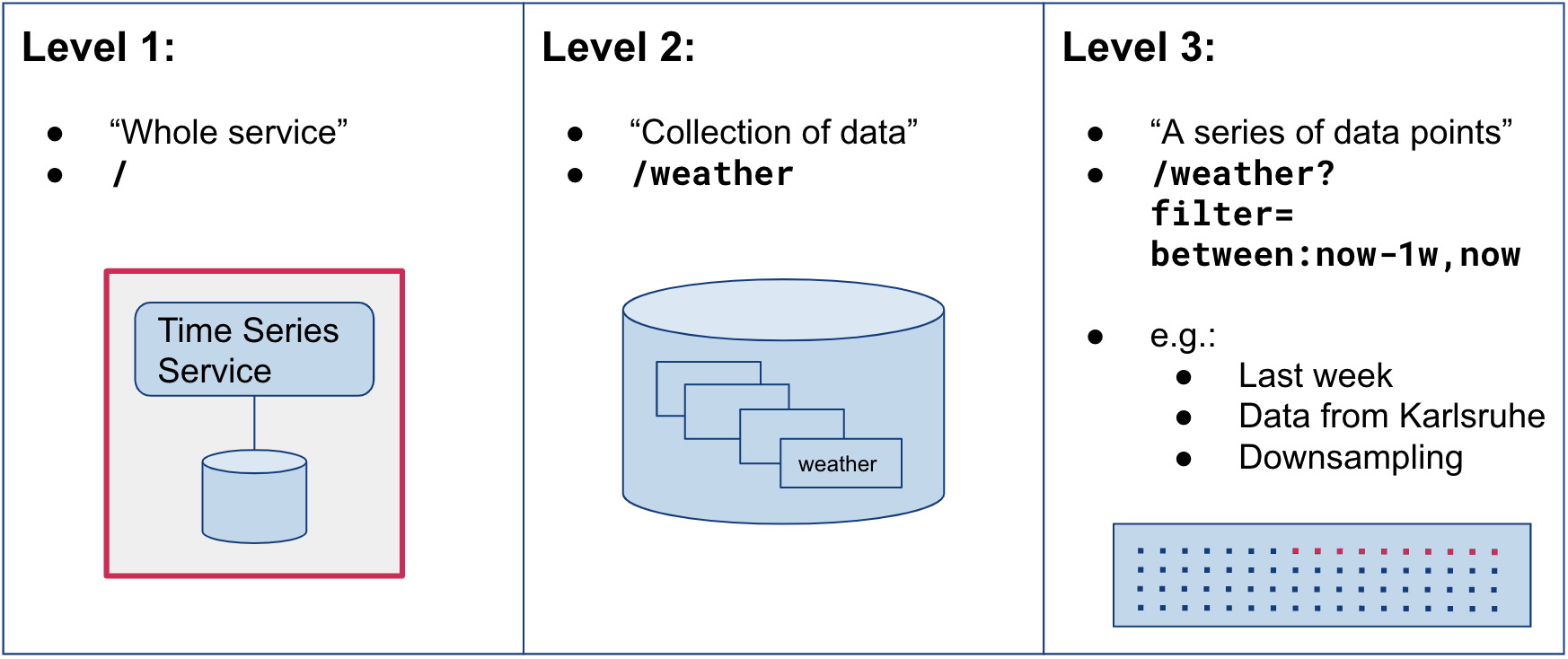
At level one, an access control decision would be to allow or deny a user access to the whole time series service. This would only be useful if all data contained in it would be confidential – an unlikely scenario. The second level concerns the collection of weather data within the service, while the third level works with various filters, e.g. only allowing access to the data from last week, or to aggregated data. The latter can be useful for the energy consumption use case to obfuscate real data. For example, if only one value per two hours is sampled, as opposed to a frequency of half an hour or even less, no imminent conclusions about the inhabitants’ behavior can be made.
Another goal of the security design was to implement the concept of data ownership for groups instead of individual users, as there are potentially different groups collaborating in one system. There should be a way to limit access to the data belonging to one group, as well as to share and revoke read access to members of other groups. The latter requirement calls for a flexible IAM concept, meaning that the users can share some of the accesses independently to reduce the administrative overhead. The concepts of data ownership and flexible IAM are illustrated in the following graphic:
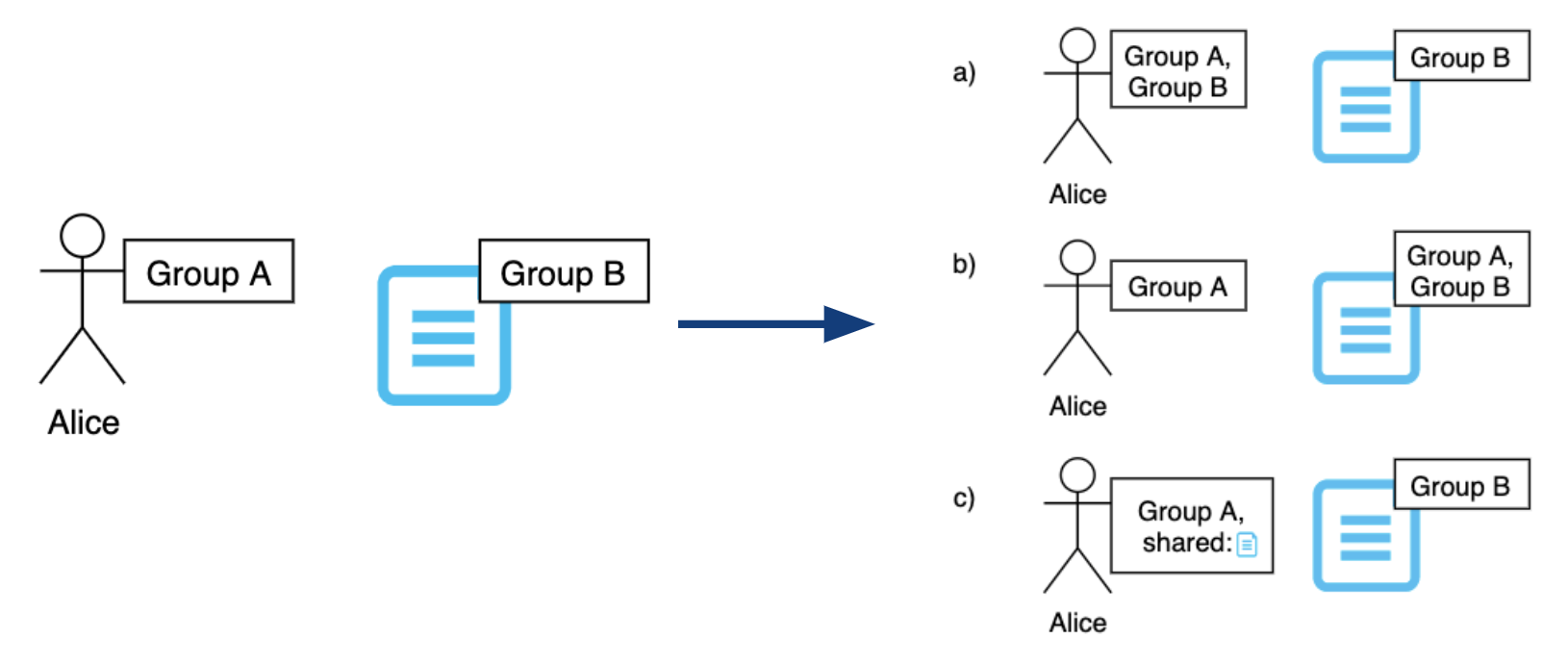
Flexible IAM
As seen in the picture, it is possible to assign both users and objects to different groups. In the example, Alice belongs to a different group than the document, and therefore cannot access it. There are several ways of granting Alice the right to see this document in such a model. Firstly, Alice can be invited to Group B, which grants her the right to access all objects of the group. This poses a security threat, as Group B might have joint projects with other groups that Alice should not be authorized to see. Moreover, the security administrator will have to remove Alice from the group once the project ends, which might be forgotten. The second way to grant Alice the required access would be to temporarily assign the document to Group A. This poses an additional security threat, as now all other members from Group A can read the data, and the admins of Group A can modify or delete it. Thus, both of those approaches violate the principle of Least Privilege.
Now, the sharing concept (c) enables a more flexible way to share necessary permissions to Alice. To share the document, a user from Group B would grant Alice permission to read only this document, which will be recorded for her user and can be evaluated on the next system access. Thus, no other objects belonging to Group B are shared with Alice and the principle of Least Privilege is retained. However, the disadvantage of this method is that it is not immediately visible what users have access to the file, as opposed to option (b). In this case, the central point would have to be requested to determine which users have the specific capability.
Security Design
As seen in the requirements, a fine-grained sharing concept would generate a significant number of attributes that need to be recorded for the user (e.g. Alice belongs to Group A and has access to documents x, y, z). This number can be kept as low as possible under the assumption that the users can always access the documents from their group, and that the sharing attributes would be generated and saved on demand, e.g. the first time an object is shared. Nevertheless, the question of where and how those attributes are saved remains open.
To answer this question, we will take a closer look at the underlying software architecture. Here, the data is retrieved from numerous data services through their Application Programming Interfaces (APIs) and is then prepared by the Application Service, which functions as a backend for the frontend. Then, those dashboards are displayed in the frontend and can be configured by the users. The configurations need to be stored as data objects, therefore the Dashboard Backend provides an API for storing and changing the dashboards. The following scheme describes the abstract view of the system architecture:
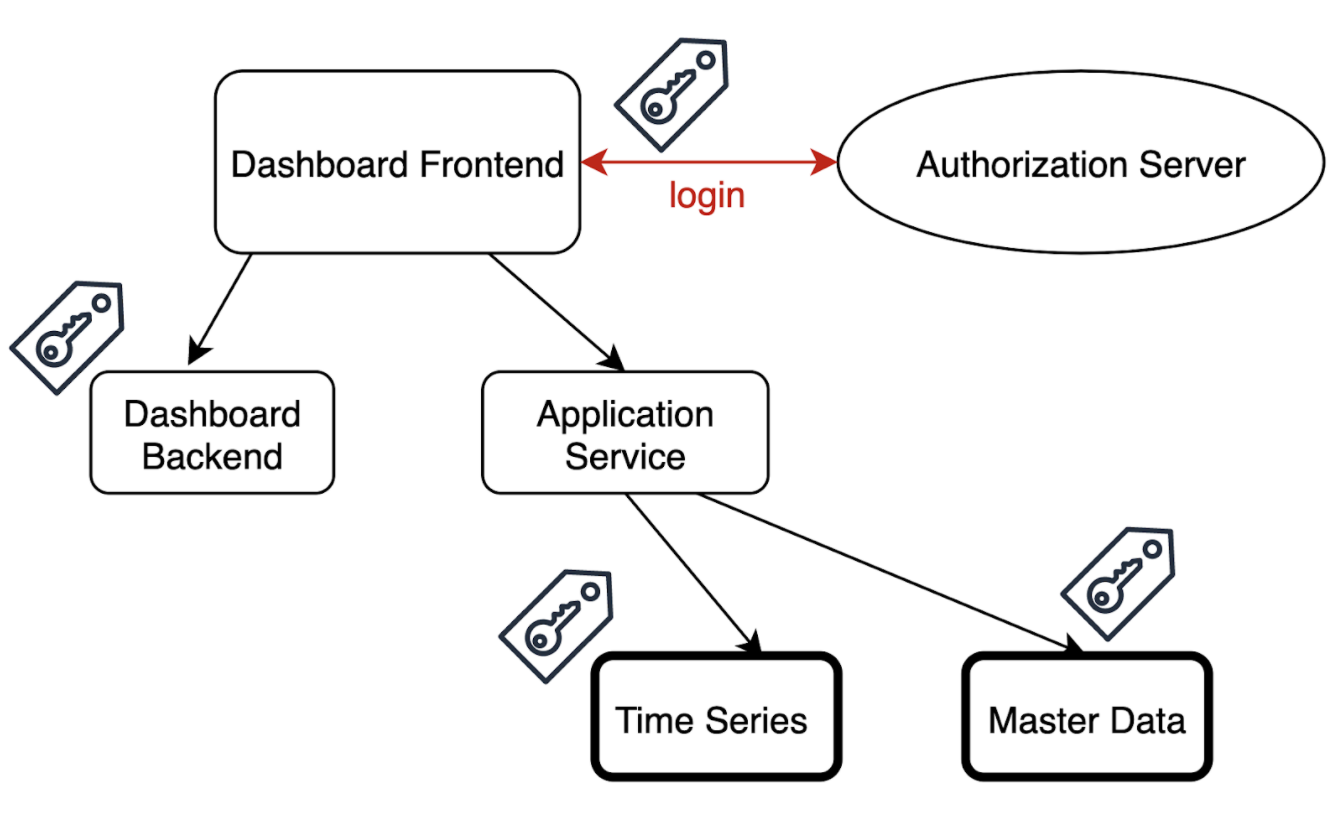
As seen in the picture, authentication happens via the central authorization server that supports the OAuth 2.0 + OpenID Connect flow. For our proof of concept, we chose Keycloak as an out-of-box IAM solution, as it is open-source and supports all the necessary authentication and authorization flows. It is also used to store and manage user data and handle the log-in and sign-in flows. All communication to underlying services is secured with security tokens which can be validated by underlying services and contain some information about the user. This information should be sufficient for the services to make security decisions, however, this information can have different forms. Those forms can determine the security architecture – in particular, whether the permissions are stored in a centralized or decentralized way.
Implementation: Centralised or Decentralised?
On the one hand, the token can contain all permissions that the user has in the system, e.g. “can access data from power plant N“ or “can access data from last month“. In this case, all user permissions are saved in the authorization service, and the services can check the token and immediately decide whether to accept or deny the request. However, such a security token can become very long, as it contains fine-grained security information of all services. This also is a violation of the Separation of Concerns (SoC) Principle, as all permissions are stored in the token and can be read by other services that do not need to know this information.
On the other hand, the token could only contain the user’s id and other general attributes, such as what user group they belong to. This means, that the backend services should analyze this information locally and manage their access databases. Of course, this approach results in very short tokens and the observance of SoC. But, remembering the goals of the security system, we may encounter some problems if we implement more complex mechanisms, such as flexible IAM or granularity level 2-3. In case of permission needs to be shared with another user or another group, decentralized information management provides a significant disadvantage, as all affected services need to be notified about the change. The same should be done in case a user is deleted or changed.
Hybrid Architecture
In our implementation, we decided to combine those two approaches in a so-called hybrid architecture. The following image represents the security architecture and the contents of the token:
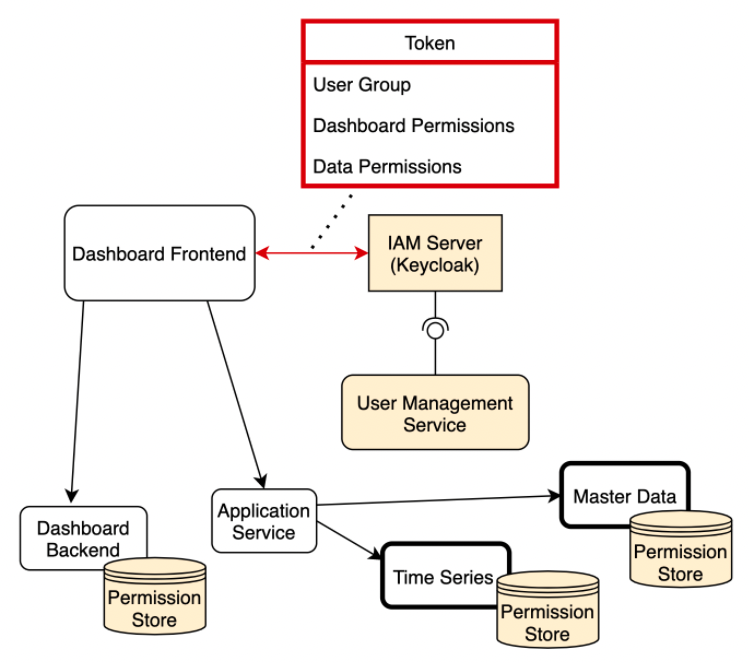
The token that is attached to every request only describes the group affiliation and permissions that were dynamically shared with the user. It does not contain the security properties of accessed data, for example, what objects belong to which user groups. This is realized by the Permission Store module that is attached to every backend service that persists objects. This module contains an overview of private data and the group it belongs to but otherwise contains no information about the users, which can be read from the access token. Therefore, the overall security design can be classified as extended RBAC, where roles are represented by groups, and single permissions can be shared by saving them in the IAM server and writing them into the security token.
Lessons Learned
In the implementation, only granularity level 2 could be reached, as only the data collection names can be saved in the token. The reason for this is the multitude of ways to group multifarious data and a need for standardization. Currently, we can easily save the group affiliation of single metrics, e.g. all data from solar panels belongs to Group X, all weather data belongs to Group Y. In the same way, we can define shared accesses in the token: user A belongs to Group X and additionally has access to weather data. However, such simplicity is not achievable on higher granularity (“user A has access to data from last month“). To reach level 3 of granularity, a whole standard of encoding that fine-grained permission is required, a central point needs to enforce this standard and an efficient way of saving those permissions with the user needs to be developed. This can delimit the endless combinations of attributes but would mean a huge development overhead.
Moreover, somewhat fine-grained access control can also be achieved by sensibly labeling the data. For example, if all data from Germany is labeled accordingly, the access control by country would be much easier to implement. However, in this case, it would be wise to limit the attributes only to the most essential ones, and/or make them non-shareable.
Overall, I recognized that implementing such complex features in an IAM context is not a trivial task, as every increase in flexibility or granularity introduces a significant development overhead. Therefore, every new feature should be first evaluated from a cost-benefit perspective and the prediction should be communicated to the stakeholders. Moreover, adherence to best practices of secure software development is still a requirement, such as checking the OWASP Top Ten list, implementing encapsulation and using reputable frameworks and standards.


