
One of the largest cost factors for modern machine learning is the annotation process. Reducing these costs enables machine learning-based use cases to ease model development and find greater acceptance. Active learning is an approach for the intelligent selection of training data to reduce the required amount of data to train models. This blog post focuses on the application of active learning for the complex task of object detection (computer vision). It was carried out as part of a maritime research project.
Introduction
In recent years, representation learning has been shown to outperform previous machine learning techniques in several tasks such as computer vision by the use of deep neural networks. However, to enable the development of such quality visual prediction models by supervised training techniques, a sufficiently high amount of quality annotated data is mandatory.
The problem of data selection
The acquisition of the annotation remains an intensive task, as human expertise is required for these complex use cases. With the ever-increasing processing of new data, the need for annotation of this data to train supervised prediction models is increasing as well. This led to two problems:
- Annotation of all available data very quickly becomes uneconomical.
- The data relevant to the model changes during model development.
The former may be solved by automatization based on the current model to reduce the human-based process as efficiently and effectively as possible. The latter falls prey to the assumption that all samples in a dataset are equally relevant over the entire training period. At the beginning of training, priorities are to teach a model the diverse similarities of data, less the unusual cases. However, during the lifecycle of a model, the priorities begin to shift and edge cases begin to receive attention. But as more new data has been seen, these edge cases will still be the minority while redundancies will still be the major part of incoming data.
Another aspect is the enormous amount of incoming data which may serve as training data. Manual inspection of all data may become infeasible, hence an automatised selection function is a welcome utility for data engineering.
To qualify as a valid approach, models trained on data selected by the selection function must exceed a random selection-based function with the same amount of training samples.
Goal
Active learning is an approach to iteratively improve models. This is done by selecting an information-rich data set from the entire set of unannotated data based on a model trained on the already labeled data. Such an approach might be able to solve the problems above:
- By filtering information-poor data, the number of annotations (i.e. annotation costs) can be reduced and
- the focus of data selection is enabled to shift.
The goal of this work was to investigate whether active learning can be considered as a method to automatically propose images for new annotations in the domain of underwater species detection. Since a real execution by manual annotation is too costly, this was simulated based on an existing dataset of the UFOTriNet project (more in the next section). The annotations were withheld and the associated data was considered unlabelled for the time being. An additional gain from a successful simulation was the extraction of a smaller but more informative dataset to accelerate future training procedures.
Context
In 2015, the United Nations adopted the agenda for the next 15 years to develop a sustainable future for mankind, oriented on 17 goals. The 14th of these goals, Conserve and sustainably use the oceans, seas, and marine resources for sustainable development, describes the plans for the next years regarding oceanic health. The second paragraph of this 14th goal states: “By 2020, sustainably manage and protect marine and coastal ecosystems to avoid significant adverse impacts, including by strengthening their resilience, and take action for their restoration in order to achieve healthy and productive oceans.“ This declaration of global relevance in marine health pushes the investment of continuous developments in interdisciplinary domains to support this goal for the year 2020 and beyond.
In the context of this initiative, the Federal Ministry of Food and Agriculture in Germany financially supports the development of an autonomous fish observatory UFOTriNet: Development of a mobile and portable underwater fish monitoring observatory (UFO) and establishment of a fish monitoring network for the evaluation of fish stocks by coupling with a stationary UFO to analyze fish stocks by species, weight, and size by non-invasive techniques [1]. Part of this project is researching and developing pattern recognition algorithms for monitoring underwater images in the area of computer vision. Annotated data that has been accumulated over the last years during the runtime of the project were the basis for training and evaluation of models.
Active learning
Our colleague Matthias Richter already explained the idea and most important components in a previous blog post [2]. Please take a look if you are unfamiliar with active learning or need a fresh up. In general, active learning supports the learning system (i.e. the model) to sample data samples it is most uncertain about. There are two methods to sample existing data for annotation: Selective and pool-based sampling. In the case of selective sampling, an incoming stream of data is inferred and a binary sampling decision is made directly afterward (flagged for annotation or not). In contrast, the pool-based approach injects a pool of data and selects a subset. The decisive advantage is a weighing of the data samples against each other, which enables the filtering of redundancies. In addition, the size of the selected subset can be determined within the pool-based sampling and the focus on information-rich data can be concentrated.
Incremental improvement by efficient queries
We decided to use the pool-based sampling approach to rank and filter the most promising samples and to increase labeling efficiency. After an information-rich set of parts has been selected, annotated, and used to train a new model, this procedure can be repeated. This creates a cycle that incrementally annotates more and more information-rich data and improves the model. To enter the cycle, an initial model is required, trained on a small initial seed set as training data with balanced classes.
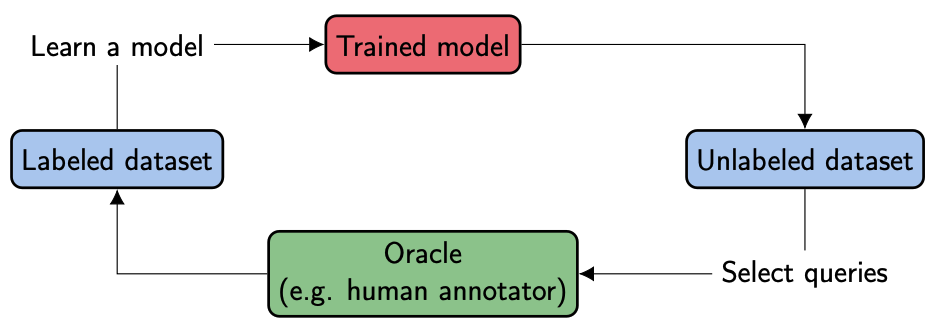
This selection process in the cycle is called a query and is made out of three steps: Pooling, informativeness calculation, and sampling (see below). The pooling step is an efficiency layer in which a subset \(P\) of the unannotated data is randomly sampled (for very large datasets), although the complete subset could be used as well (small to medium-sized datasets). Afterwards in the informativeness step, each data sample is assigned an information score based on a given model, the so-called informativeness. This value describes the potential gain of the sample for the model if it would be part of the training.
Finally, another subset is created during the sampling step which contains the final queried batch \(Q’\) for annotation. The most straightforward approach is to select the top N samples based on the ranked informativeness score. After annotation, this batch \(Q\) is then added to the existing data for re-training.

As Matthias already explained in his blog post, there exist multiple approaches to calculate the informativeness for each sample. As most models predict a class probability vector, this vector can be used to calculate the informativeness using different uncertainty metrics (least confidence, smallest margin, and entropy) called uncertainty score. Using the posterior model probabilities, this approach is called uncertainty sampling.
Object detection
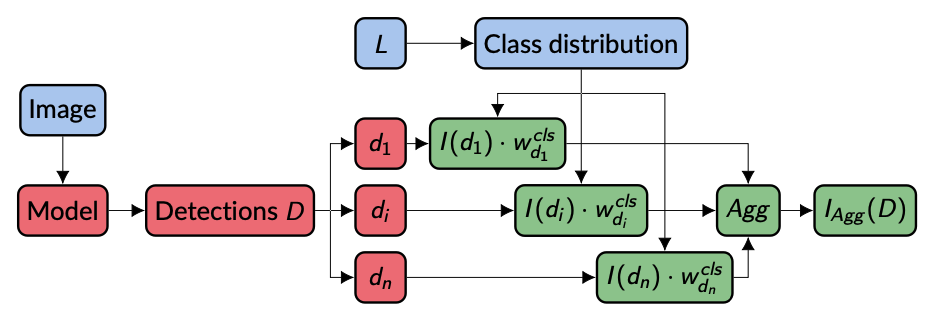
Most applications of active learning are done in classification tasks. Object detection, however, is a more complex task as a single sample (image) can contain zero, one, or multiple detections, each with its own classification vector and uncertainty score.
While the uncertainty score of an image with zero detections can be defined as zero, multiple detections \(D = \{d_1, …, d_n\}\) require an aggregation \(Agg\) to reduce the uncertainty scores \(I(d_1),…,I(d_n)\) to a single value \(I_{Agg}(D)\) for the whole sample to enable image ranking for the sampling step. Typical aggregations can be used here such as \(\Sigma\), maximum, or average. (For more information see: Brust, Clemens-Alexander et al. Active Learning for Deep Object Detection)

Experiments
As mentioned in the introduction, a selection algorithm such as active learning must exceed in model performance compared to a random approach. Another boundary can be set due to the simulated nature of these experiments: As all labels are withheld for the selection algorithm, a baseline model can be trained using all available data. This defines an upper boundary of the potential performance.
YOLOv5 is a state-of-the-art object detector. It is one of the most famous representatives of the YOLO (You Only Look Once) family of object detectors. YOLOv5 integrates the latest advancements of the computer vision community and is actively maintained. It is known for its fast inference time, easy deployment, and ease of use for ML engineers. It served as a model architecture throughout all experiments.
Uncertainty
The choice of aggregation method directly influences the annotation focus. We chose the sum aggregation to emphasize more detections per image and reduce the total amount of images. This results in more information-rich images while efficiently shrinking the training set, resulting in faster training. A drawback of this aggregation method is that it requires a more intense annotation phase due to the existence of multiple objects.
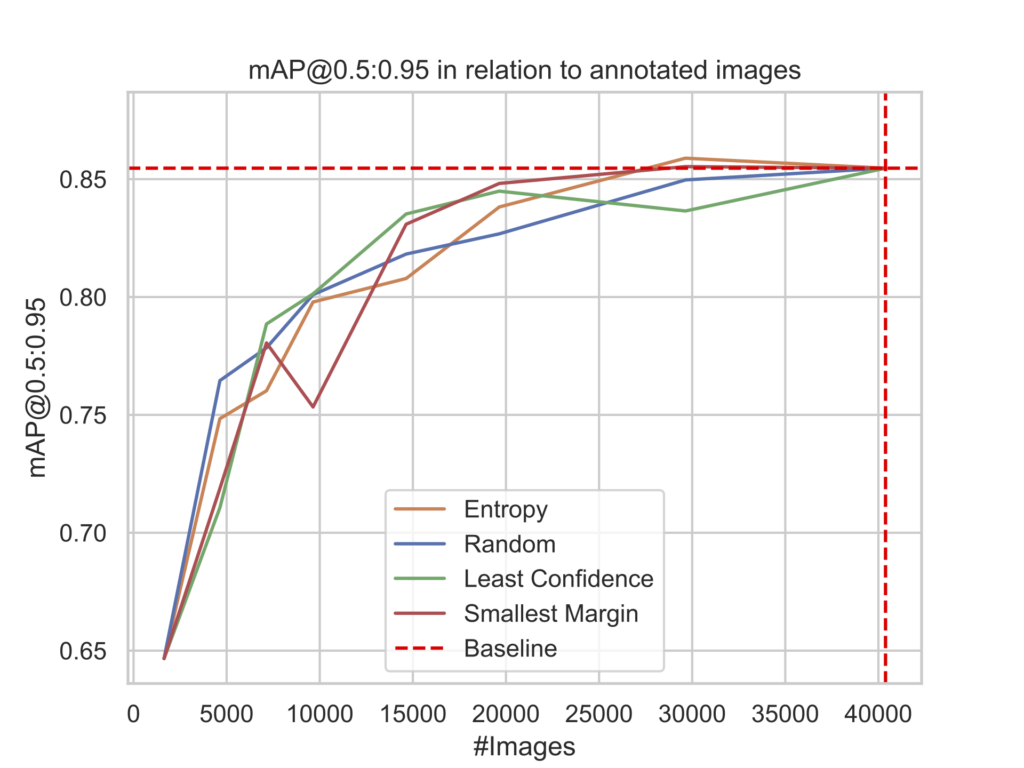
The experiment has been run for each of the three uncertainty metrics (least confidence, smallest margin, and entropy). Starting with a similar rise in the early phase, the active learning methods show a performance gain compared to the random sampling. This indicates an advantage for maturing models by selecting edge cases instead of redundancies. As the runs continue, each run’s training set converges to the same data, minimizing the performance differences.
Weighted Uncertainty
Relying solely on informativeness has the potential to create imbalance inside the training set and therefore a prior bias towards high-frequent classes. This aspect is extremely relevant in environments such as this marine environment in which classes occur with large differences in frequency. As a countermeasure, a class weight can be assigned to increase the informativeness for low frequent classes. During each query step, the distribution of ground truth labels of the training dataset is used to create a weight for each class. For each detection’s most likely class, the corresponding class weight is multiplied by the detection’s uncertainty score before aggregation.
Adding the class weight, all active learning methods show an improved performance compared to random sampling. The high similarity between the methods indicates a reduced prior bias when neglecting class imbalances compared to the unweighted uncertainty experiments.

The class weights are the same during the first iteration due to the balanced dataset of the initially trained model. Therefore, no class is preferred and objects are selected based only on their uncertainty, leading to a drastic class imbalance. This imbalance is successfully countered during the next iterations.
Revisiting the active learning cycle
Setting the sampling size (i.e. how many samples are queried during each loop iteration) is one of the most important parameters for pool-based active learning. A rather small value enables cherry-picking of the most information-rich samples, maximizing the labeling efficiency.
However, the smaller the sampling size, the more cycle iterations to reach the same amount of queried samples. Consequently, this will also lead to an increased amount of training from scratch. In the days of deep learning, a too-small increase in training data size might show a too-small increase to justify the training effort. Hence a deeper understanding of the problem case and data insight is required during model development.
One possible solution is the integration of continuous learning. Re-using a trained model and updating it sequentially with new data realizes an efficient way to integrate new knowledge in complex networks while keeping already existing knowledge to prevent forgetting.
Summary
Active learning could successfully be applied to the domain of object detection. By using uncertainty aggregation, the aggregation framework is not limited to YOLOv5 but to other object detectors as well. With the addition of class weights, it was possible to re-establish class imbalance to a reasonable degree and increase performance. The amount of required training data for a well-performing deep learning model had been successfully reduced, showing its usefulness for real-world applications.


