
Notice:
This post is older than 5 years – the content might be outdated.
One of the biggest challenges in data centers is to maintain multiple clusters for different workloads. Say you want to run Hadoop, Kafka and Storm which means that you have to maintain 3 different clusters. These different clusters are hardly utilized most of the time so for example when you run Hadoop you need many resources to get the job done but the rest of the day these resources stay idle. With a very simple calculation you can see how much time your resources are idle and only waste space and money (and we didn’t talk about hardware replacements at this point!). Read on for the nitty gritty details in this first article in our Mesos mini series.
Say a Hadoop cluster runs a 3 hour job, this means the cluster is idle 21 hours a day. Looking at the whole year we have a cluster which is idle for 7665 hours (!). And this calculation does not even take into account that we usually want to overprovision our cluster so that we can handle load peaks.
In 2009 Benjamin Hindman and his team at UC Berkley had the same problem with multiple Hadoop clusters. So they created Apache Mesos which is a distributed system kernel and works as a cluster scheduler. Mesos abstracts the resources (CPU, memory, I/O, network) of a cluster for end users. So Mesos abstracts the whole cluster resources into one big computer and allows the user to have OS functionalities on a cluster-level. Mesos provides a Web UI as well as an API for resource and scheduling management. One of the first and biggest Mesos adopters is Twitter.

Apache Mesos runs on any POSIX oriented operating system (e.g. Linux and OSX) and allows you to share resources between multiple frameworks, which are handled kind of like an application. With Mesos you are able to combine all these resources into one big cluster and run different workloads on it. When we introduce an intelligent time scheduling for example Hadoop runs only at a specific time and we can reduce the size of the cluster. Another approach is to run best effort jobs which run when some resources are idle and can be killed if a high priority job comes in. This oversubscription approach for Mesos is in development by Mesosphere, Intel and some other big companies.

It’s pretty helpful to be able to run different frameworks on your cluster without the need to provision new resources. So for example when you have some Tasks which can be better done with a special framework, e.g. Storm, you can simply run it on your cluster.
Mesos vs. regular OSes
When we compare Mesos to a regular OS we see that Mesos provides all the abstraction layers on a cluster-level which are provided by an OS on a single computer. One of the first things an operation system provides is process isolation, this means every process gets its own file descriptors, memory space etc. Mesos does the same by providing isolation with the help of cgroups, Docker or LXC.
In the next step an OS provides you resource sharing: Generally you don’t want to worry about resources – you just want to have the resources and let a scheduler assign them. This also allows you to share resources between different processes. Mesos does this using the DRF-algorithm (Dominant Resource Fairness). We will have a more detailed look at the scheduling part of Mesos later.
One of the last important things an OS provides (I know this is not a complete list by far) is a common infrastructure for the user. For example as developer you want to use functions like Read(), Write(), Open()… and (most of the time) you don’t really care about details of this functions‘ implementation. For Mesos the common infrastructure are functions like LaunchTask(), KillTask(), … which allow the framework to interact with Mesos.
Mesos – Architecture

There are 4 important components to run Mesos:
- Master: Coordinates the work and decides which framework gets how many resources
- Zookeeper: Used as distributed storage, enables the coordination of the masters
- Slave: A worker node which provides its resources to run tasks of a framework
- Framework: Has a scheduler component which decides where a task gets launched and an executor which executes one or more tasks at the Slave.
Obviously we need resources to run our workload on a Mesos cluster:
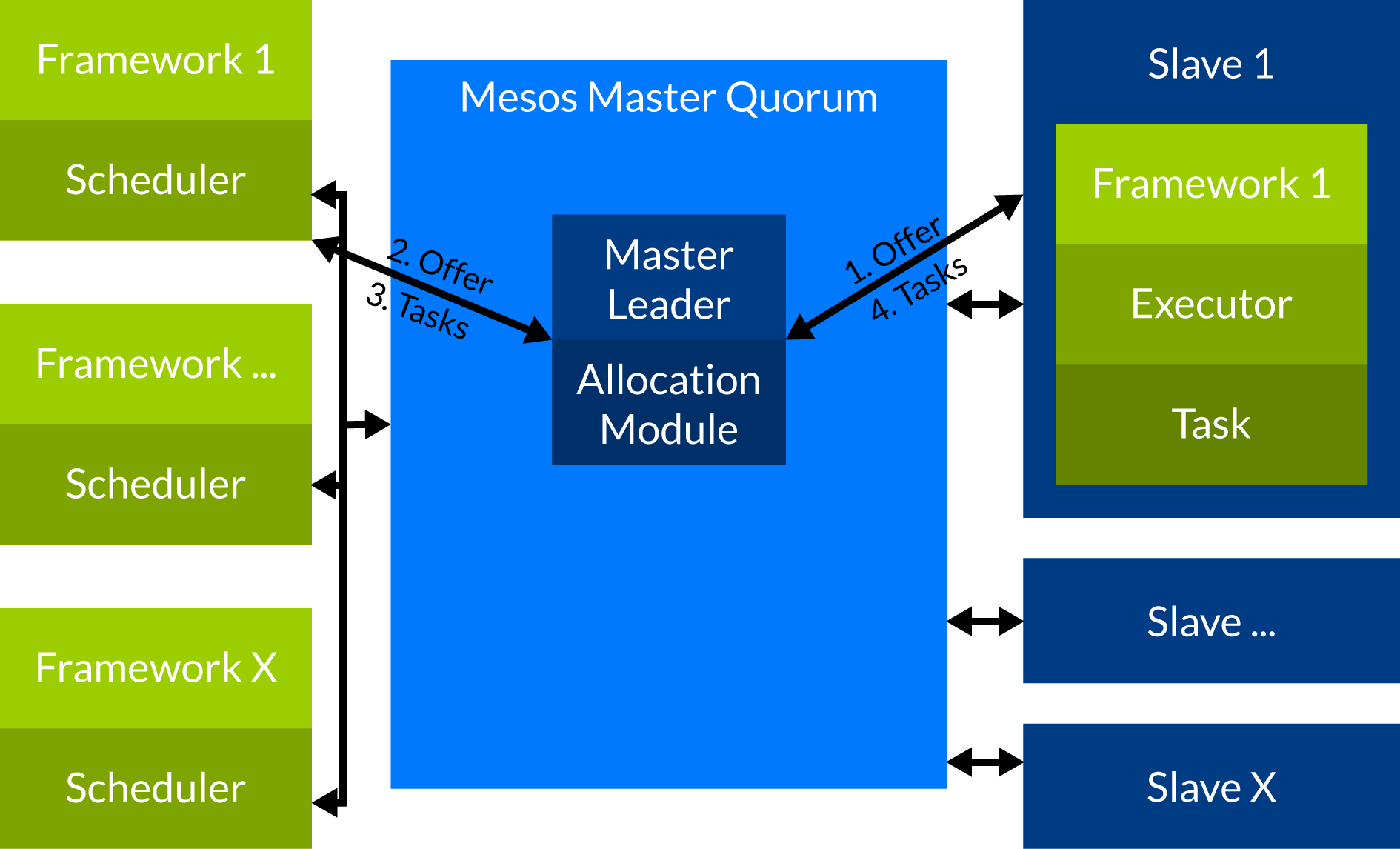
And this is how it works: When a Slave notices that it has free resources it sends an offer to the Mesos master which includes its Slave ID and the free resources. The allocation module inside the master decides which framework will get the offer. When a framework receives an offer it can decide how many of the resources it will take. For example the framework may only take the CPUs of an offer to start its tasks. When the framework has decided which resources it will take and how many tasks it will start it sends a message to the master. The message contains the number of tasks and the resources that it will allocate for each task. In a last step the master passes this information on to the slave that reads these taskinfos (taskname, slave id, ressources) and starts the tasks. When the tasks have finished and the resources are free again all these steps will be repeated.
Run tasks on Mesos
When we have a Mesos cluster we also want to run our jobs on it. The simplest way to run your tasks on Mesos is to use an existing framework (this is not a complete list of all Mesos frameworks). If you have some exotic workload or no framework fits your needs you can also build your own framework – But I would only recommend this step if you really know what you are doing or if you want to get some insights into Mesos.
Getting started
To get started right away you can use Vagrant to spin up a mini cluster to play around with
- https://github.com/everpeace/vagrant-mesos
- https://github.com/mesosphere/playa-mesos
- Or install you own cluster with the Mesosphere prebuilt packages https://mesosphere.com/downloads
Read on
In the next part of this series we will show you how to use Marathon (an init system for Mesos) to run your tasks on Mesos.
Get in touch
For all your data center needs visit our website (now available in English, too!), drop us an Email at list-blog@inovex.de or call +49 721 619 021-0.
We’re hiring!
Looking for a change? We’re hiring Big Data Systems Engineers skilled in Hadoop (Hortonworks), Flume, Spark, Flink, Hive and Cloudera. Apply now!
3 Kommentare