
Notice:
This post is older than 5 years – the content might be outdated.
In this final blog post of our 3 part series we will have a look at how you can build your own Apache Mesos framework. If you’re new to Mesos have a look at our introduction first and learn how to run tasks and applications using Marathon – otherwise jump right in.
How Mesos frameworks work
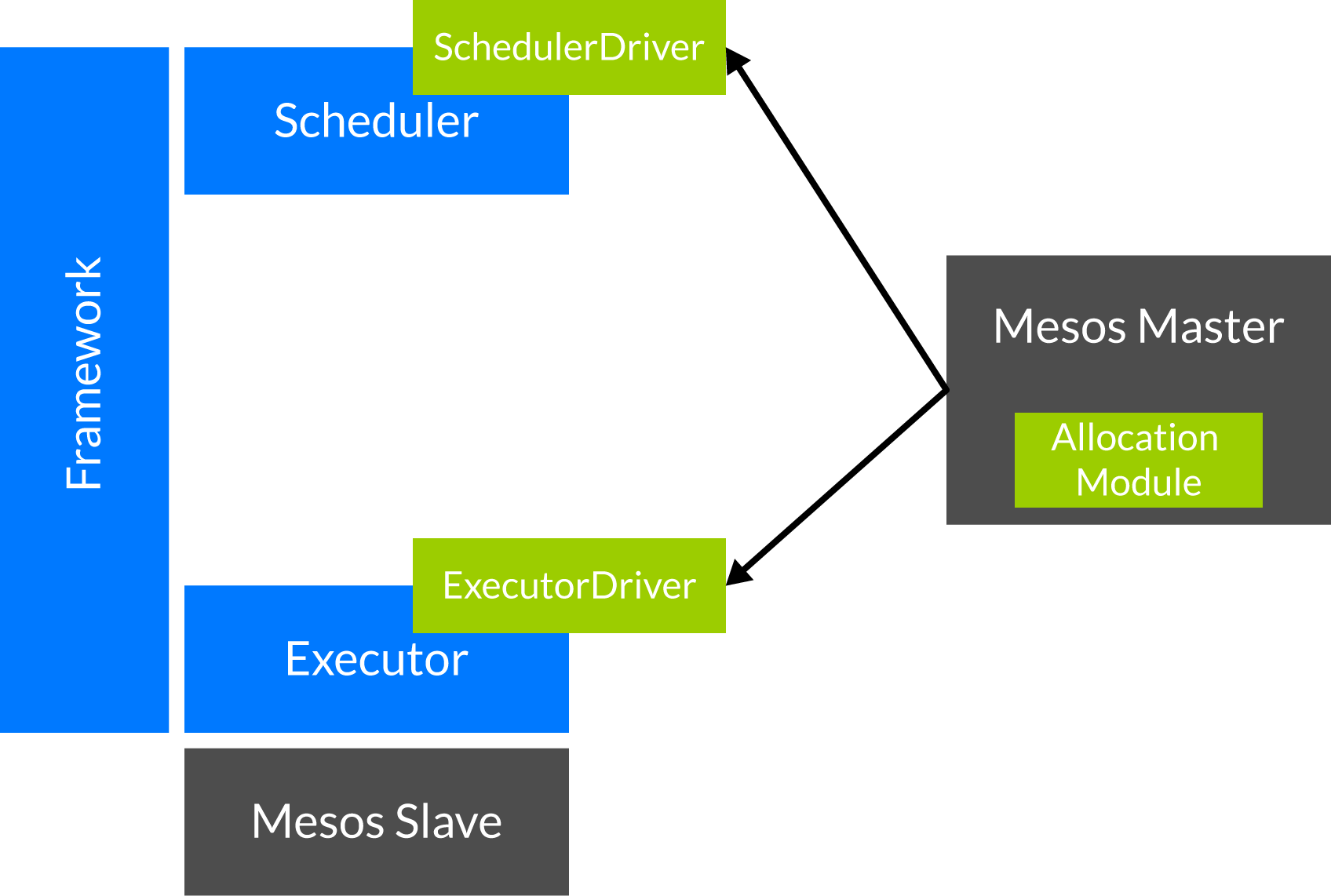
A Mesos framework has a scheduler and an executor. Normally the scheduler is be started manually by yourself or by Marathon. The scheduler takes offers from the Mesos master and decides how it will distribute the tasks to the offers it gets. The SchedulerDriver is needed to communicate with the Mesos master so basically the driver is a kind of a translator.
When the scheduler takes an offer and sends a taskinfo (which is the description of a task) to a slave (over the Mesos master) the Mesos slave will create an executor. The executor can start one or more tasks and can communicate with the Mesos master over the ExecutorDriver. The executor can send status updates that contain information about the status of the tasks like staging, running and finished.
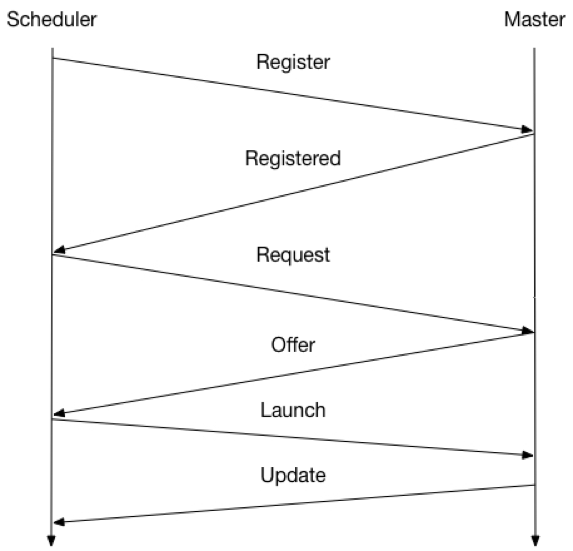
In a first step the Scheduler registers itself with the Mesos master. The scheduler gets the registered message from the Mesos master to see if everything worked Fine. In the next step the scheduler can request resources for his tasks after which the Mesos master will send offers from the Slaves to the Scheduler. When the scheduler has decided how it will start the tasks and which resources it will use the scheduler sends a launch message. Finally the Mesos master will send status updates about the tasks to the scheduler.
Getting started
When you want to start to write your own framework you have a very wide choice of programming languages:

We programmed the example framework with Python. To start with Python and Mesos you need to install the Mesos python egg. You can simply fetch the Python eggs from Mesosphere. The example is available on github. Also, there are some more examples, feel free to test these examples and have a look how they work.
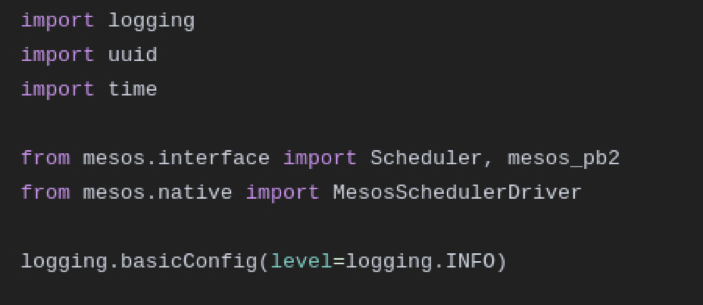
We import the standard scheduler to override the API functions we need. We also import the Mesos protobuf to access or create information and finally the MesosSchedulerDriver which allows us to talk to the Mesos master.
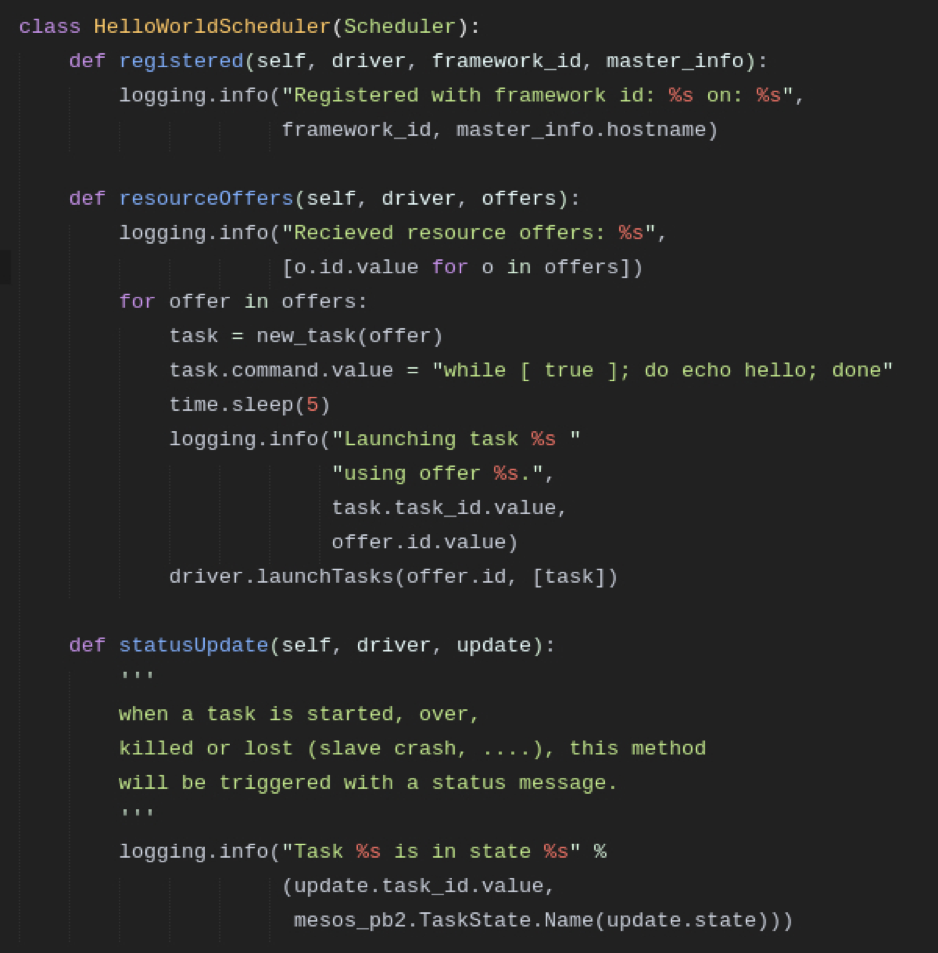
Next we create the HelloWorldScheduler which inherits from the Scheduler. Now we can override the functions we want to use–if we don’t override a function the Scheduler will use the default function. We define a registered() method which will be called when the framework has registered at the Mesos master. The method simply prints out the framework id and the hostname of the Mesos master.
The method resourceOffers() will be called when the framework receives an offer from the Mesos master. In this case we simply take all offers and create new tasks which say ‚hello‘‘. With the last statement we send a list of tasks (acutally the list only contains one task but we have to send a list) to the Mesos master via the driver so they can be started. In the statusUpdate() method we simply print the status of each task–there are 8 different TaskStates that indicate the state of a task.
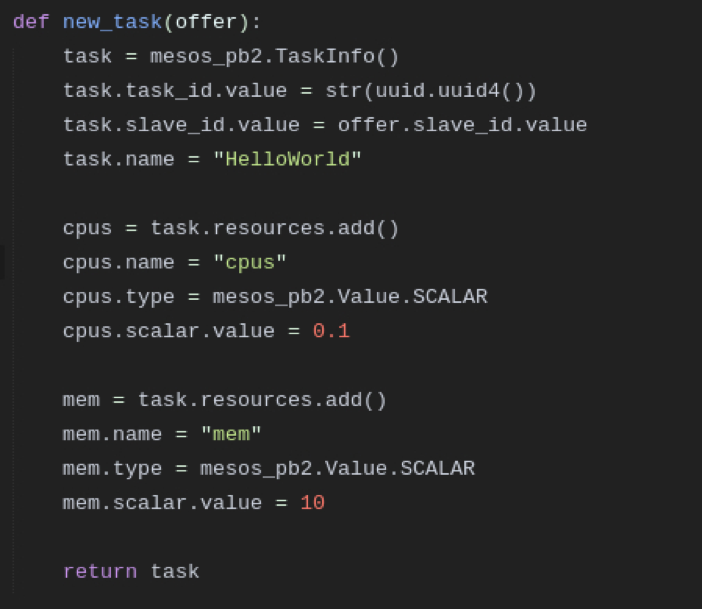
To create a new task we need to create a TaskInfo. Now we can assign a unique task id and a slave id which we get from the offer. We can also assign the task a human readable name to identify it.
In the next steps we assign the task resource 0.1 CPU and 10 MB RAM. If you need to specify some other resources just have a look at the Mesos protobuf. Finally we want to launch our Frameowork:
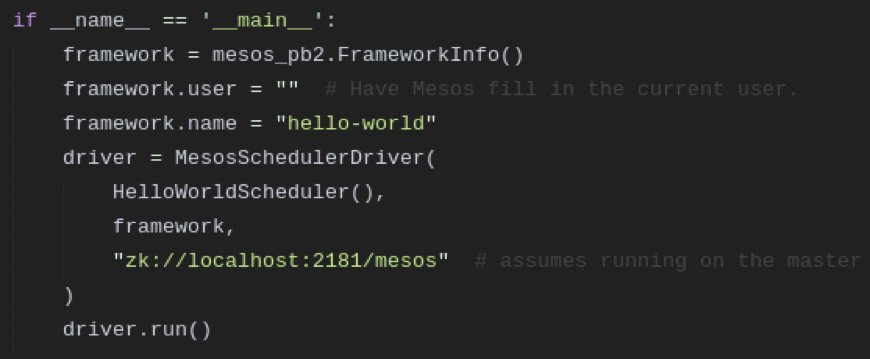
We create a FrameworkInfo and assign the framework name “hello-world“. The framework assumes that it’s running on the master. Now you can start the framework with python hello_framework.py . When you go to the Mesos web UI and look inside the framework tab you will see that our framework appears there. Of course you can also see the tasks which are started by the framework.
Get in touch
For all your data center needs visit our website, drop us an Email at list-blog@inovex.de or call +49 721 619 021-0. Any suggestions? Feel free to leave a comment below!
We’re hiring!
Looking for a change? We’re hiring BigData Systems Engineers skilled in Hadoop (Hortonworks), Flume, Spark, Flink, Hive and Cloudera. Apply now!
5 Kommentare