
Notice:
This post is older than 5 years – the content might be outdated.
In the hope of excellent features, without requiring domain experts spending days engineering them, lies this review of automated feature engineering with TPOT, auto-sklearn and autofeat.
In this blogpost, we will examine the automated feature engineering of the three libraries mentioned for four datasets. We will take a look at the following questions: How do the automated feature engineering frameworks differ conceptionally and in result? What are the gains by using them depending on the expressiveness of the predictive model at hand? How do these automated features compare to those engineered manually?
Why (Automated) Feature Engineering?
Feature engineering is often described as the extraction and accentuation of implicit information from data [1], to construct features best amenable to learning [2]. Feature engineering is heavily domain-specific while machine learning models can be general-purpose [2]. Whether or not feature engineering includes data exploration and cleaning tasks—also sometimes referred to as feature preprocessing—, such as missing values imputation or outlier treatment, is not formally defined but considered in this blogpost.
The main motivation for feature engineering itself is interesting for two reasons, the improvement of prediction metrics like accuracy, as well as allowing simpler models to be a viable alternative to complex ones. As the prominent figure of the data science community, Andrew Ng, puts it: „Coming up with features is difficult, time-consuming, requires expert knowledge. ’Applied machine learning’ is basically feature engineering“ [3]. There are at least four reasons for automating this process:
- Domain experts may not be readily available or biased, in which case new useful feature transformations are desired.
- Scalability: Automation has the ability to scale in producing and testing more novel features faster (which in itself does not mean that the features are better).
- Feature engineering is a trial and error heavy process: the influence of a feature on the quality of a machine learning model needs to be evaluated. According to Forbes, data scientists spend most of their time on such tasks, although it is ranked as the least enjoyable [4].
- In the strive for complete automated machine learning, every step of the pipeline needs to be automated.
Just for clarification, the differences between deep learning and automated feature engineering are sometimes confused. Feature engineering is much more general-purpose than deep learning, depending on the available feature engineering strategies. Feature engineering can include the mentioned feature pre-processing transformations and the input data can even be discrete or sparse. Moreover, feature engineering is also done on deep learning tasks, architectural decisions that transform the input features could be considered feature engineering by the provided definition. These transformations of the input data are chosen by design and are not the result of model training.
How do These Libraries Work?
In a nutshell, TPOT designs machine learning pipelines with genetic programming. Genetic programming is a subcategory of evolutionary algorithms used to build programs automatically and independent of their domain. Looking at Figure 1, one can see an exemplary TPOT optimized pipeline. The default possible feature operators—here represented in circles—include mainly preprocessors, transformers and feature selection algorithms implemented in Scikit-learn. The available operators can easily be extended. The model and hyperparameter selection of a machine learning pipeline is also part of TPOT but deactivated in the following examples. Ultimately, the optimization goal in TPOT is to find a pipeline with a minimal number of operators but with the best-possible prediction accuracy given some error measure.

Auto-sklearn also constructs complete machine learning pipelines that maximize a chosen error measure. The pipelines of auto-sklearn are not as flexible and consist of up to four feature operators in front of the machine learning model. The optimization of pipelines in auto-sklearn is done using Bayesian optimization. In a nutshell, Bayesian optimization is a strategy for efficiently finding global extrema. It prooved to be especially useful for non-convex objective functions. The sampled evidence is captured in a probabilistic model to represent the relationship between data points and measured performance, which is then used to select the next values to test.
Autofeat is intended for generating linear features in a two-step process. First, it generates tens of thousands of features with non-linear feature transformations and combinations. In a second step it selects the most useful subset of features by the correlation of features with the target residual and importance of features for a linear model. Both steps can be done for a different amount of iterations, resulting in more complex and more stable features respectively.
Evaluation Setup
A blueprint of the setup to generate data for an evaluation can be seen in Figure 2.

The experiments conducted for our comarison used four different regression datasets. The first two are synthetic, noiseless and constructed artificially while the true target function is known. The first corresponds to a simple XOR problem (the „Hello World“ of feature engineering) impossible to be solved by a linear model. The second synthetic dataset corresponds to the target function \(target = 2 + 15 * x_1 + 3 / (x_2 – 1 / x_3) + 5 * (x_2 + log(x_1))^2- x_4^4 \), with \(x1, x3 \) sampled from a uniform distribution sampled from 1 to 100 and \(x2, x4 \) sampled from a standard distribution with mean 0 and standard deviation of 100.
Complementary to these, two more datasets have been taken from Kaggle. One is the Rossmann Store Sales dataset – from now on referred to as “Rossmann“, where the goal is to forecast daily sales for each store using store, promotion and competitor data. The other is about predicting the taxi trip duration in the New York City Taxi Trip Duration dataset—from now on referred to as “TaxiTrip“. We took a subset of 100.000 data samples for each of those datasets to speed up the training process. Also, we removed outliers in the TaxiTrip dataset with the interquartile range because there are few examples where a taxi trip took around 24 days—while the average trips takes 11 minutes—which has too big of an impact on the chosen accuracy metric.
Before initialising the frameworks, the data must be pre-processed according to the requirements of each framework. For example, TPOT only needs typecasting to numerical values, auto-sklearn and autofeat need an additional index list for categorical features, TPOT and auto-sklearn do work with data imputations while autofeat does not.
The pre-processed data is used for automated feature engineering. TPOT and auto-sklearn are used with cross-validation with four folds for every pipeline evaluation and TPOT’s population size is set to 50, autofeat’s generation steps are set to 3 with 5 selection iterations. With TPOT and auto-sklearn the user may decide which operators can be utilized in a pipeline. For both we use the default operators but restrict the pipeline to only use a fixed machine learning model. Note that the versions of the frameworks are 1.1.2 for autofeat, 0.11.1 for TPOT, and 0.6.0 for auto-sklearn at the time of testing. In addition to the libraries, we will compare feature engineering and performance of top Kaggle solutions (Rossmann, TaxiTrip) for the real-life datasets. We will also once do no feature engineering for a naive baseline.
Based on the results, I trained and evaluated four models on holdout sets. The models used are a linear regressor, lasso lars CV, decision tree regressor, and random forest regressor. In the end, the performance of all models is measured by the RMSE error. The whole process is repeated 20 times for each configuration, as the initialization of libraries produces different results, with 12 hours of CPU time per run.
Results
Optimization of Features Over Time
Let’s look at how the pipeline error gets improved over time: The x-axis of Figure 3 shows the evaluated generation number, each of which is comprised of 50 individuals with their associated performance. The corresponding y-axis shows the RMSE error score of the best individual of the generation. In cases where the next generation did not exceed the best performance so far, the most recent best performance is plotted.
To illustrate what median performing optimization history can be expected, the median of the 20 runs per model is highlighted in a stronger color than the individual runs that are presented with a lower alpha value. Additionally, visible in the models’ color are filled intervals showing the performance range from first to the third quartile. The intervals and medians are plotted until there are at least five runs left. When a run is terminated, because the allocated time has run out, it is marked by a red line on the median.


The more expressive models start with better performance, especially the random forest. The convergence of performance is foreseeable after around 20 generations for most models, with the exception of the linear models. In cases where TPOT is able to construct good linear features, an improvement over time is consistently high until termination. For the more expressive models, that did well without feature engineering—being able to already model more of the underlying data structure—TPOT showed to be less effective in improving performance. In those cases, more computational resources should not make a difference in performance.
There is a noticeable difference in the number of evaluated generations before termination, which is not only due to the different complexity of pipelines. We specified that each generation should have 50 individuals, however, most have around 10 individuals. They seem to get homogenous and no new combinations of operators are found. There are enough operator combinations and a pipeline can always have more operators, but few operators make up most hyperparameter configurations and pipeline growth is heavily restricted. The issue with pipeline growth is that the first generation gets initialized with only up to 3 operators and growth is limited by design. As a pipeline’s fitness is measured by both error and the number of operators, a pipeline with an additional operator is always also worse than its predecessor on at least one fitness criterion. That also favors complex operators that do much at once as only the number of operators count, because the complexity of operators arguably differs. For example, the default configuration contains both an operator that counts the occurrence of zeros in a sample and a radial basis function sampler that produces a hundred new features at once. The mutation of a pipeline, a procedure to overcome local minima or maxima in evolutionary algorithms, does change, prune or add one operator at a time, which is possibly not enough change at once to skip local minima. The effect of this is that while 80 percent of the best pipelines had at least 4 operators, only 20 percent of evaluated had more than 4. Altering the optimization process to be more growth-friendly, initializing deeper pipelines, and redefining complexity could potentially lead to a greater variety and better pipelines.
The observations for the optimization history for auto-sklearn in Figure 5 are similar to TPOT, the only difference is a more stable convergence for all datasets. This is quite possibly due to the fixed pipeline structure.


Autofeat’s plot in Figure 7 looks different than the others as there is no improvement over time that could be analyzed but only the final performance for a varying number of generation and selection steps. Note that the feature generation is independent of the final prediction model, the number of selected features is represented in the bins of the heatmap and the color intensity shows the performance gain against not doing feature engineering. Generally, the most important performance factor was the complexity of generated features on the y-axis, which is bottlenecked by the memory limitation. Scenarios with large datasets, especially true with many categorical features one-hot encoded, get very memory intensive and would need a different evaluation setup with large memory allocation to inspect the effect of more generation steps. The simpler feature transformations in the first two feature generation steps were not complex enough to produce new selected features. Linear models profit more from feature engineering; unsurprisingly, as the focus of this library is to produce linear features and features are partially selected based on the coefficients of a linear model.

Output of Libraries and Comparison to Manual Feature Engineering
Let’s explore the output of libraries for the simple XOR feature engineering problem, but only for the linear regression model. The default RMSE error is 0.5001, but every framework solves this simple problem almost immediately within machine precision, but with very different features.
Beginning with TPOT’s output, the following code snippets show two solutions. This generated output is a short representation of TPOT’s produced pipeline. It lists the operators of the pipeline from last to the first operator with the operators’ parameter settings. For example, the first pipeline uses an operator called RBFSampler with the original feature matrix as input and the gamma hyperparameter set to 0.1, whose output is then the input for the linear regression model.
|
1 2 3 4 5 6 7 |
# Pipeline 1 LinearRegression(RBFSampler(input_matrix, gamma=0.1)) # Pipeline 2 LinearRegression(ZeroCount(ZeroCount(input_matrix))) |
The output shows a simple and overly complex example. Minimalistic feature construction can be examined for Pipeline 2, where two features are added sequentially by the „ZeroCount“ operator. Pipeline 1, with the default settings for the RBFSampler (i.e., radial basis function sampler), computes an additional 100 features, resulting in a total of 102 features for this simple case. This is a great example of one of the downsides of the current definition of complexity in TPOT, the construction of 100 new features with the RBFSampler is considered less complex than counting the occurrences of zeroes twice per sample in pipeline two.
Auto-sklearn’s outputs look different but contain the same information as before. The library does also sometimes use overly complex operators as in Pipeline 1, but because the pipeline can only have so many operators, very simple operators like the “ZeroCount“ operator is not part of auto-sklearn per default. Pipeline 2 with the polynomial feature operator shows a more minimalistic approach. Note that sometimes additional scaling or imputation strategies are applied that do nothing, but since this library does enforce the fewest possible operators by design, they are still part of the pipeline.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
# Pipeline 1 imputation:strategy, Value: 'median' preprocessor:random_trees_embedding: bootstrap= True, max_depth=5, max_leaf_nodes=None, min_samples_leaf=1, min_samples_split=2, min_weight_fraction_leaf=1.0, n_estimators=10 regressor:__choice__, Value: 'OwnLinearReg' # Pipeline 2 categorical_encoding:one_hot_encoding: use_minimum_fraction=False imputation:strategy, Value: 'most_frequent' preprocessor:polynomial: degree=2, include_bias=True, interaction_only=False regressor:__choice__, Value: 'OwnLinearReg' rescaling:__choice__, Value: 'minmax' |
Autofeat solves the XOR dataset consistently with a minimal set of features. With every hyperparameter configuration it adds a single additional feature like \(x1 ∗ x2 \) or \(|x1 − x2|\).
We will not go into detail about the constructed features for both TPOT and auto-sklearn as they show only the feature operators, without consideration about the exact features created. As of now, the output features are not labeled, and especially in TPOT’s potentially big pipelines features are mixed up in many transformations and their meaning is lost in complex operators. While autofeat’s feature construction is clearly labeled, the complex non-linear transformations are just not interpretable in the tested real-life scenarios. One interesting observation I want to highlight is the complex synthetic function \(target = 2 + 15 * x_1 + 3 / (x_2 – 1 / x_3) + 5 * (x_2 + log(x_1))^2- x_4^4 \). The terms \(5 * (x_2 + log(x_1))^2\) and \(x_4^4 \) of the target function are the exact output of autofeat and thereby produce an almost perfect error score. To see how long autofeat is able to produce these exact features I introduced a variety of complications; the exact terms could only be consistently engineered with duplicate, random features or little noise on the target function. Especially new categorical values that affected part of the other features could not be reconstructed. Even though all complications could be engineered in the feature generation, they were just not selected.
The Kaggle feature engineering shows some similarities. Sometimes the exact operators of the pipeline-generating libraries are used, in other cases, the operators are simply not implemented. Especially a time-and-date-conversion operator is not available in either libraries. On the other hand, lots of features produced by combinations of features are only generated in autofeat but the ones from Kaggle were not selected. An overview of what feature engineering techniques are used in the Kaggle contributions and whether the frameworks can reproduce them you can find in Figure 8. Note that a framework is considered as being able to make use of a technique if it implements at least one sub-technique. For all listed feature engineering techniques there are multiple potential approaches.

The most important takeaway is that current automated solutions show that domain knowledge is not replaceable as the feature transformations can be anything depending on the domain. TPOT and auto-sklearn can not have every operator, and introducing new external data is a feature completely unthinkable as of now, but often a part of Kaggle solutions.
Performance of Libraries
The overall median performance for all datasets but the XOR problem can be seen in Figure 9. The best-performing library for the more expressive models is TPOT, followed by autofeat and lastly auto-sklearn. For simple models, the frameworks are performing equally well. In simpler scenarios where data can be made complete linear, as in the Synthetic examples, autofeat dominated performance by constructing parts of the exact target function.
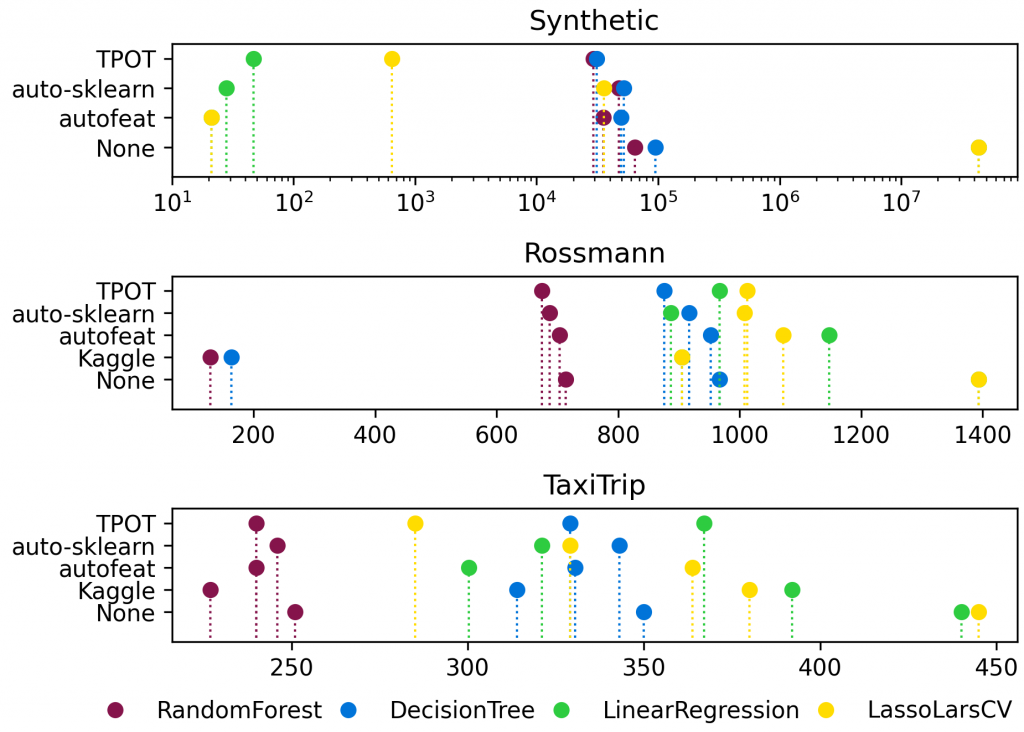
Overall, the best human feature engineering solutions outperform the frameworks for all real-life datasets by as much as five times for the Rossmann example. The Kaggle performances for the linear models have to be taken with a grain of salt as they were not intended for a linear model. For the real-life datasets the model’s complexity was more important for the performance than the feature engineering, although all models benefit from automated feature engineering.
Conclusion—tl;dr
- TPOT’s variably sized pipelines and complex operators outperformed on the real-life datasets. Linear models could potentially improve with more resources.
- Autofeat is best for small datasets with underlying data possibly being linearly separable.
- Automated feature engineering is more effective for simpler models, however, model complexity was more important than feature engineering.
- The automated solutions are clearly inferior to the best Kaggle solutions.
- Automated feature engineering is not fully automated yet as there are limitless feature engineering possibilities, highly dependent on the problem domain.
Automated feature engineering can be another tool for a data scientist’s workflow, especially with limited domain knowledge or available human resources, but certainly does not replace the need for human feature engineering.
Sources
[1] Ray, Sunil: A Comprehensive Guide to Data Exploration. https://www.analyticsvidhya.com/blog/2016/01/guide-data-exploration/, Retrieved: June 09. 2020
[2] Domingos, Pedro: A Few Useful Things to Know about Machine Learning. In: Communications of the ACM 55 (2012), Nr. 10, S. 78–87. – ISSN 0001-0782, 1557-7317
[3] Ng, Andrew: Machine Learning and AI via Brain Simulations. https://helper.ipam.ucla.edu/publications/gss2012/gss2012_10595.pdf, Retrieved: January 21. 2020
[4] Rencberoglu, Emre: Fundamental Techniques of Feature Engineering for Machine Learning. https://towardsdatascience.com/feature-engineering-for- machine-learning-3a5e293a5114, Retrieved: January 07. 2020



Very nice work. It would be very nice if you could provide the link to the implemented codes as well.
Hi Paribartan, glad you like it. The code can be found under https://github.com/inovex/automated-feature-engineering/