
Hinweis:
Dieser Blogartikel ist älter als 5 Jahre – die genannten Inhalte sind eventuell überholt.
Ich beschäftige mich bereits seit einiger Zeit mit der Azure Data Factory, habe neben Real-World Kunden, Projekten und Vorträgen auch schon Hands-On Workshops dafür konzipiert und durchgeführt. Ich habe mir die jüngste Weiterentwicklung, den „Copy Wizard“ in Vorbereitung eines Vortrags bei der SQL PASS Community schon mal etwas genauer angesehen und möchte meine Erfahrungen in diesem Blog-Eintrag gerne teilen.
Der Platform-as-a-service Dienst ist seit Mitte 2015 produktiv nutzbar für Data-Management-Aufgaben in der Microsoft Cloud. Die Azure Data Factory (ADF) ermöglicht die zentrale Orchestrierung von vielen der zahlreichen Datenspeicher und Verarbeitungsdienste auf Azure und in On-Premise-Rechenzentren. Sie beinhaltet aber neben dem Management und Monitoring von Datenverarbeitungsschritten auch Kopierfunktionen.
Bislang bestand das große Manko bei der Entwicklung der Factories nach einhelliger Meinung der Nutzer:innen in der komplizierten Zusammenstellung der Verarbeitungslogiken über JSON-basierte Templates. Die Unterstützung durch Visual Studio bestand lediglich aus der Bereitstellung von JSON-Code-Fragmenten und einigen Syntax-Checks. Oft kam es beim manuellen Eintragen der Datenverbindungen und der Parametrisierung für das korrekte „Slicing“ zu Fehlern.
Am 18.3.2016 hat Microsoft den ADF den „Copy Wizard“ spendiert. Dieser Assistent soll es einfach machen Daten zwischen den Diensten zu kopieren, ohne dabei mit dem JSON-Quellcode in Berührung zu kommen.
Copy Wizard starten
Im Azure-Portal findet man den Copy Wizard als Preview Feature in bestehenden Data Factories im ersten Blade:

Das Erstellen einer Kopieraktivität erfolgt in 3 logischen Schritten: Quelle festlegen, Ziel auswählen und ein paar optionale Parameter wie z.B. Wiederholbarkeit festlegen. Im Bild unten sind beispielhaft als Quelle eine Datei im Azure Blob Store und als Ziel eine Tabelle in einer Azure-SQL-Datenbank ausgewählt. Dieses Beispiel werde ich im Folgenden auch durchspielen.

Walk-Through
Nach dem Starten des Assistenten, der ein neues Fenster im Browser öffnet, werden zunächst der Name der Pipeline und der Zeitplan für die Ausführung festgelegt.

Die Intervalleinstellungen sind auf verschiedenen Zeitebenen wählbar (siehe Recurring pattern im nächsten Bild). Außerdem wird über Start- und Endzeit festgelegt, wann mit dem Laden begonnen werden soll. Die im obigen Bild ausgewählten Optionen würden am 21.03.2016 mit dem Laden von Slices auf Tagesebene beginnen und das bis zum 30.12.2099 fortführen.

Quellen und Ziele
Die Auswahl des Quellentyps erfolgt über den folgenden Dialog per Mausklick:

Es können auch die bereits in der Data Factory vorhandenen Datenquellen genutzt werden, inklusive der hinterlegten Credentials – sicherlich ein sinnvolles Feature, um das Duplizieren von Code zu vermeiden. Die momentan zur Auswahl stehenden Quellen und Ziele sind im Übrigen nicht das Ende der Fahnenstange, im Laufe der nächsten Wochen sollen 20 weitere integriert werden.
Nach der ersten Auswahl erfolgt die Verfeinerung in weiteren Dialogen:
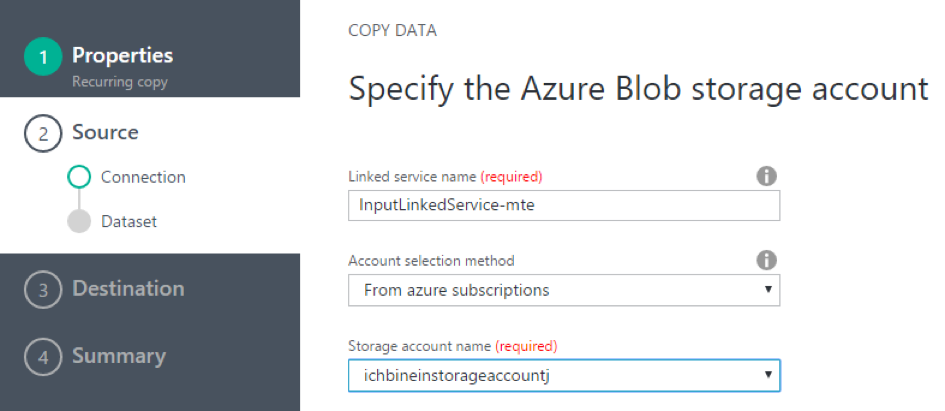
Eine Referenzierung auf Resourcen, die nicht in der eigenen Subscription liegen, ist über die bekannten Mechanismen wie z.B. Shared Access Keys auch möglich. Es wird nach der Authentifikation interaktiv eine Verbindung zu den Datenspeichern aufgebaut die eine direkte Auswahl einzelner Ressourcen (z.B. eine Datei) oder auch ein Quell-Pattern ermöglicht (Pfad mit rekursiven Unterverzeichnissen).

Kleiner Tipp an der Stelle: Zur Fortsetzung des Assistenten muss je nach Bildschirmauflösung nach rechts unten gescrollt und zunächst „Choose“/“Auswahl“ angeklickt werden, bevor man links unten mit „Next“ in den folgenden Dialog kommt.

Im nächsten Dialog können weitere Optionen festgelegt werden. Im Bild sieht man die typischen Unterscheidungen wie die Zeichen für Spaltentrenner oder das Zeilenende.
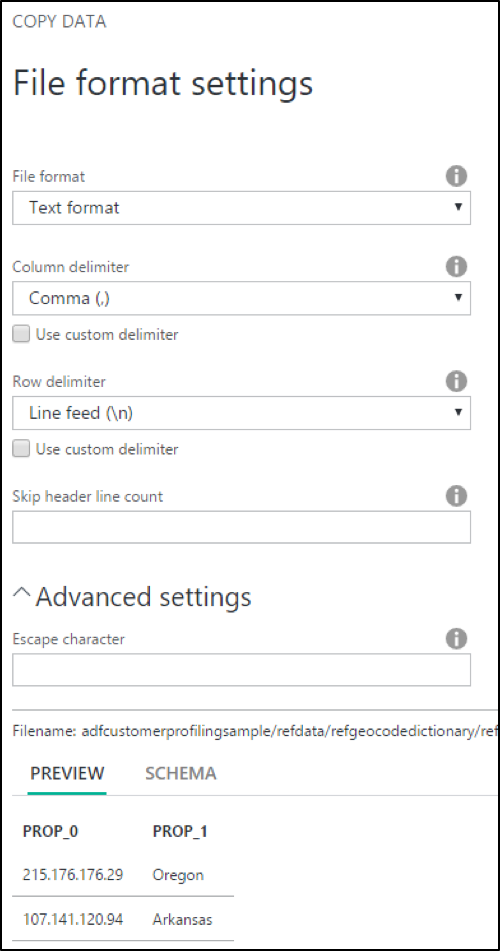
Es wird auch gleich eine Preview der Daten in der Quelldatei angezeigt. Neben dem Preview stehen unter „Schema“ die Datentypen, die der Assistent aufgrund der Daten in den Spalten vermutet.
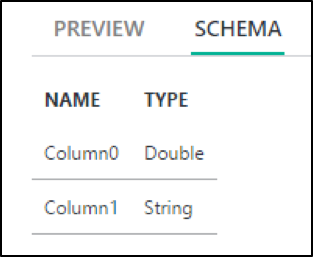
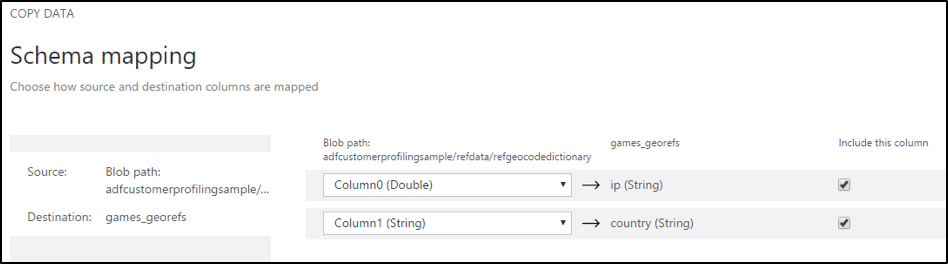
Dem aufmerksamen Betrachter wird dabei auch bereits auffallen, dass der Datentyp Double im Falle der IP-Adressen in Column0 nicht so ganz passt. Leider lässt sich das Schema an der Stelle weder bearbeiten noch beeinflussen.
Die Auswahl der Ziele entspricht der der Quellen. Im nächsten Bild sind beispielhaft die bereits in der Data Factory existierenden und konfigurierten Datenspeicher abgebildet. Die Symbole zeigen den Typ der Verbindung an.
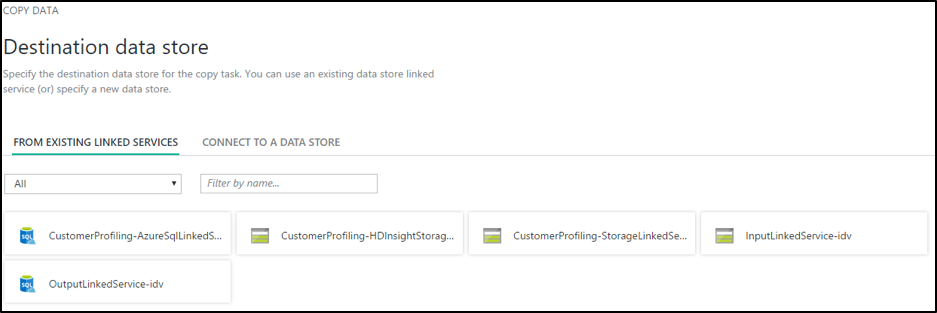
Bei der Auswahl einer Datenbank als Ziel muss die Zieltabelle mit den passenden Datenstrukturen bereits vorhanden sein, sie lässt sich leider nicht über den Assistenten anlegen.
Einstellungen
Im nächsten Dialog werden die Quell- auf die Zielspalten gemappt. Hier offenbart sich das Problem der nicht übereinstimmenden Datentypen. Die Konvertierung der IP-Adressen in Column0 beim Auslesen aus der CSV Datei in den Datentyp Double wird später beim Ausführen der Pipeline/Activity fehlschlagen. Tipp dazu: Man kann die Datentypen dann im JSON im Portal korrigieren … naja, immerhin.
Ebenfalls in diesem Dialog können optional Repeatability Settings (Einstellungen zur Wiederholbarkeit) gesetzt werden.
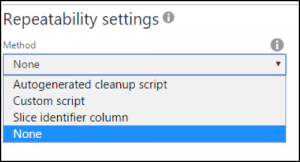
Der Default ist „None“, bei dem die Daten einfach ins Ziel geschrieben werden. Das kann für einen einmaligen Ladevorgang durchaus sinnvoll aus, beim wiederholten Laden der gleichen Daten muss das Ziel i.d.R. darauf vorbereitet werden, um Dubletten zu vermeiden. Die Optionen sind folgendermaßen:
Autogenerated cleanup script
Cleaning der Zieltabelle über ein Script über eine Datenbankspalte vom Typ datetime. Hier werden die Parameter des aktuell behandelten Data Slices über die ADF-Mechanismen übergeben. Z.B. Lösche in der Tabelle vom 21.03.2016 00:00:00 bis 22.03.2016 00:00:00.

Custom script
Das Script kann frei editiert werden, z.B. kann man auch einfach vor jedem Ladelauf die Zieltabelle löschen: $$Text.Format(‚delete FROM mytable‘)

Slide identifier column
ADF verwaltet die Zieltabelle selbst anhand einer Spalte vom Typ binary in der Zieltabelle. Vermutlich wird der Inhalt der Spalten gehashed, um Veränderungen erkennen zu können. Leider funktionierte diese Option in meinen Tests nicht, sondern lief immer wieder auf Fehler.

Deployment
Nach der Konfiguration sind alle Einstellungen vorgenommen und es wird noch einmal eine Übersichtseite dazu anzeigt, bevor mit einem Klick auf „Finish“ ein Deployment der neuen Pipeline/Activity in die Data Factory vorgenommen wird.

Es werden die Verbindungen, Datasets und Pipelines im Ziel angelegt und der Status in einem Abschlussbericht angezeigt.

Von hier aus kann man direkt in das seit Februar verfügbare Monitoring und Management Tool für die Data Factory springen, um sich die Zeitpläne und Ausführungsergebnisse anzuschauen. Wie man im nächsten Bild sehen kann, wurde eine neue Pipeline mit der definierten Activity angelegt.

Fazit
Soweit so bunt! Ich finde, dass diese Entwicklung eindeutig in die richtige Richtung geht. Einige Dinge funktionieren noch nicht so richtig wie (z.B. die Datentyperkennung) bei CSVs. Bei einer Preview ist das auch in Ordnung und diese Punkte werden mit Sicherheit noch überarbeitet.
Was im Sinne des Application Lifecycle Management leider noch nicht ins Bild passt, ist die Tatsache, dass der Copy Wizard lediglich im Portal verfügbar ist. Nur die Entwicklung von ADF-Artefakten in Visual Studio ermöglicht die ordentliche Integration in Quellcodeverwaltungs- und Build-Systeme. Es bleibt zu hoffen, dass auch dieser Weg in der Roadmap vorgesehen ist.
Als Ad-hoc-Tool, vergleichbar mit dem SQL Server Import/Export Assistent und ggf. als „Schreibhilfe“ für JSON kann sich der Copy Wizard aber bereits heute als äußerst nützlich erweisen.
Weiterlesen
Mehr Infos zu Microsoft Azure und unserem kompletten Analytics-Angebot gibt es auf unserer Website oder telefonisch unter +49 721 619 021-0.



2 Kommentare