
Hinweis:
Dieser Blogartikel ist älter als 5 Jahre – die genannten Inhalte sind eventuell überholt.
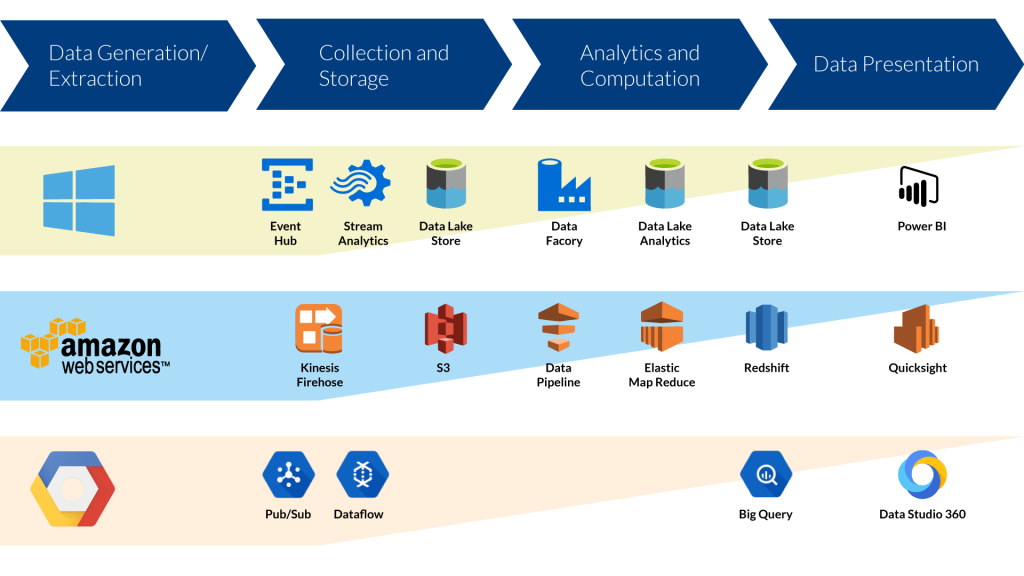
Um aus gesammelten Daten nützliche Informationen und einen Mehrwert zu gewinnen, ist in der Regel eine Aufbereitung notwendig. Die Methoden zur Verarbeitung lassen sich in Realtime und Batch Processing unterteilen. Erstere beziehen sich nur auf einen sehr aktuellen Ausschnitt der Daten und wurden bereits im Teil Collection and Storage bei den Streaming-Diensten vorgestellt. Die Batch-Verarbeitung bezieht meist einen größeren Datenausschnitt mit ein, also auch historische Daten, um neue Erkenntnisse oder Analysemodelle zu erhalten. Zur Verarbeitung großer Datenmengen stellen die Cloud Provider meist Tools aus dem Hadoop Big Data Ecosystem zur Verfügung.
Um die Daten zur späteren Analyse in ein geeignetes System und Format zu bringen, werden im DWH-Umfeld seit vielen Jahren Extraction-Transformation-Load-Prozesse (ETL) eingesetzt. Im Cloud-Umfeld werden neben klassischen Tools mit entsprechenden Erweiterungen (z.B. SSIS mit HDInsight-Komponenten) für das Data Management auch Orchestrierungsdienste angeboten.
Diese haben ihren Schwerpunkt weniger bei komplexen Transformationskomponenten als bei komplexen Schedules. Außerdem werden Abhängigkeiten zwischen zahlreichen oft Web-basierten Datenquellen berücksichtigt und hochskalierende Cloud-Resourcen möglichst effizient genutzt. Die notwendigen Transformationsschritte selbst werden auf Compute-Ressourcen verlagert, etwa Hive auf Hadoop oder Stored Procedures in SQL-Datenbanken.
Orchestrierungsdienste können auch genutzt werden, um Ressourcen zeitgerecht zur Verfügung zu stellen und dann wieder abzuschalten wie z.B. On-Demand Hadoop Cluster.
Datenverarbeitung bei AWS



WS Elastic MapReduce: „Processing big data with fully managed Hadoop Framework.“
AWS Data Pipeline: „automate the movement and transformation of data.“
Mit Elastic MapReduce (EMR) bietet AWS ein von Amazon betriebenes Hadoop Framework (PaaS). Die Anwender:innen können bei der Erstellung eines Hadoop-Clusters Vorgaben aus der Hardwarepalette von AWS in nahezu beliebiger Anzahl und Größenordnung wählen. Die Anwender :innen müssen sich nicht mit der Komplexität des Betriebs von Big-Data-Technologie beschäftigen sondern können sich auf ihren Business Case konzentrieren.
Sollen EMR Jobs wiederholt ausgeführt werden, kommt der AWS-Orchestrierungsdienst Data Pipeline zum Einsatz. Typischerweise werden dazu Vorbedingungen konfiguriert („Daten des letzten Tages sind verfügbar“) bevor das Cluster hochgefahren und Verarbeitungen gestartet wird. Der AWS-Orchestrierungsdienst Data Pipeline wird mittels eines Web-basierten Designers bedient. Dabei können Activities, Data Nodes und Ressourcen mittels Drop-Down-Menüs und Freitextfeldern konfiguriert werden.
Auf diese Weise werden auch kosten gespart, da die Rechnerknoten nur zu benötigten Zeit online sind.
Einsatz im Use Case
Die von Kinesis verarbeiteten Daten sind in einem Bucket (so heißt der Cloud-Speicher bei AWS) als CSV persistiert. Mittels Data Pipeline werden die Daten täglich auf Stundenbasis aggregiert und in das Data Warehouse geschrieben. Für die eigentliche Berechnung wird in der Pipeline Hive unter EMR verwendet. Ein hinterlegtes Hive Script wird dazu auf einem EMR Cluster ausgeführt. Sobald der Job ausgeführt wurde, wird das Cluster wieder heruntergefahren.
Gezeigt wird im folgenden Video eine bestehende Amazon Data Pipeline in der AWS Web Console. Auf der linken Seite ist der Workflow mit den verbundenen Items zu sehen wie z.B. dem Schedule, den Datensenken oder Verarbeitungsskripten. Rechts sieht man jeweils die Details zu den links angeklickten Tasks wie z.b. die Parameter für eine Hive Query, die extern in einem Pfad auf einem S3 Bucket hinterlegt ist.
Datenverarbeitung bei Azure



Azure Data Lake Analytics: „Analyse any kind of data of any size.“
Azure Data Factory: „Compose and orchestrate data services at scale.“
Für die Verarbeitung von großen Datenmengen in der Cloud bietet Microsoft neben gemanagten Hadoop Clustern Namens HDInsight seit kurzem einen Dienst namens Data Lake Analytics an. Dabei handelt es sich um eine eigene Implementierung des MapReduce-Paradigmas, welche die Komplexität der verteilten Infrastruktur und deren Programmierung gänzlich reduziert.
Durch den SQL-Dialekt U-SQL erlaubt es Microsoft nun, sehr einfach und ohne das aufwändigere Programmieren von MapReduce Jobs große Datenmengen zu verarbeiten. Entwickler aus dem Microsoft-Stack, die über Kenntnisse in C# und T-SQL verfügen, können nun mit geringerem Einarbeitungsaufwand loslegen, da spezifische MapReduce-Kenntnisse und Java-Implementierungen entfallen. In U-SQL können die deklarativen SQL Querries mittels C# kombiniert werden.
Die verteilte Analyse benötigt ein verteiltes Dateisystem. Microsoft stellt dafür einen Data Analytics Store bereit. Die U-SQL Skripte können in Visual Studio programmiert werden. Zur Ausführung wird der Code in der Azure Cloud deployed und kommt verteilt zu Ausführung. Abgerechnet wird nach der Verarbeitungsdauer aller Maschinen.
Azures Orchestrierungsdienst heißt Data Factory. Data-Factory-Aufträge können sowohl im Web-Portal als auch in Visual Studio angelegt werden. Für das Erstellen der Verarbeitungsschritte stehen Json Templates zu Verfügung. Sehr einfache Anwendungsfälle werden von einem Assistenten unterstützt. Ansonsten findet das Design in einem Json-Dokument mittels Copy und Paste statt. Dabei können über Datasets Ein- und Ausgaben wie Tabellen definiert werden.
Der Dienst übernimmt das starten und stoppen von Jobs sowie von Ressourcen wie HDInsight-Clustern. Im Factory Dashboard können der Zustand der Ausführungen überwacht und wenn notwendig Verarbeitungsketten neu gestartet werden.
Einsatz im Use Case
Mittels Azure Data Factory werden die Daten täglich auf Stundenbasis aggregiert und in das Data Warehouse oder in eine Datenbank gespeichert. Dazu verwendet die Factory als Linked Service die Data Lake Analytics, welche die Daten gemäß dem U-SQL Skript aggregieren.
Im Video unten zeigen wir eine bestehende, ins „neue“ Azure Portal deployte Data Factory. Zunächst werden die verknüpften Datenspeicher und die darin definierten Datasets gezeigt, wie z.B. eine csv-Datei im Azure Data Lake. Darauf basieren die in Pipelines zusammengefassten Activities wie zum Beispiel ein U-SQL-Script, das die Wetterdaten voraggregiert. Schließlich folgt der Absprung zur Monitoring-Umgebung, die sich in einem separaten Fenster öffnet.
Datenverarbeitung bei Google



Google Dataproc: „Managed Hadoop & Spark.“
Google Dataflow: „Real Time Data Processing for batch and stream data processing.“
Auch Google hat mit Cloud Dataproc eine Managend-Hadoop-Lösung im Angebot. Selbstverständlich lassen sich auch hier Spark, Hive oder Pig nutzen. Da hier allerdings ein entsprechendes Orchestrierungstool fehlt, wurde Cloud Dataproc im Use Case nicht verwendet. Google selbst empfiehlt Anwender:innen von Dataproc beim Einsatz von Pig oder Hive gegebenenfalls auf Big Query umzusteigen. Wird Dataproc für Datentransformationen eingesetzt, so empfiehlt Google hier Dataflow.
Einsatz im Use Case
Gemäß der Empfehlung von Google haben wir im Use Case auf Dataflow gesetzt. Dies ist aufgrund des Einsatzes als Streaming Anwendung allerdings im vorherigen Artikel zu finden.
Tipp: Im Batch Mode kann Dataflow durchaus wie ein Orchestrierungsdienst verwendet werden. Im Programmcode können andere Dienste von Google aufgerufen und abgefragt werden. So ist es möglich, Daten aus verschiedensten Quellen zu lesen, zu verarbeiten und zu schreiben. Im Vergleich zu den Mittbewerbern fehlt allerdings die Funktion für Scheduling und Monitoring. Bei Bedarf lässt sich ein Scheduling mit CronJobs lösen.
Da hier wieder nur programmatische Zugriffe erfolgen, gibt es kein Video für Dataproc und Dataflow.
Bewertung der Dienste für Orchestrierung und Datenverarbeitung
Der Funktionsumfang der Orchestrierungsdienste ist deutlich eingeschränkter als bei typischen ETL-Tools. Abgesehen von copy sind Transformationen derzeit nur innerhalb der Compute-Knoten und mit deren Möglichkeiten (Hive, Stored Procs usw.) umsetzbar.
AWS Data Pipeline hat einen selbsterklärenden Designer, mit dem sich Pipelines bestehend aus Datenknoten, Aktivitäten und Ressourcen modellieren lassen. Die detaillierte Konfiguration erfolgt in Drop-Down-Menüs und Freitextfeldern, die leider keine Code Completion, Syntax Highlighting oder Validierung bieten. Das Lifecycle Management ist ebenfalls nicht ideal, weil keine IDE-Integration verfügbar ist. Die Konfiguration kann lediglich als Json heruntergeladen und versioniert werden.
Azure Data Factory funktioniert sehr ähnlich. Eine Pipeline wird aus Aktivitäten, Data Sets und Linked Services aufgebaut. Eine Data Factory lässt sich sowohl im Web als auch in Visual Studio erstellen. Es werden zwar Basis-Templates zur Verfügung gestellt, aber ein Designer wie in den Standard ETL-Tools fehlt. Stattdessen werden Json-Dokumente per Copy & Paste zusammenkonfiguriert. Gut gelungen ist das Management und Monitoring der Data Factory. Der Copy Assistent kann den Einstieg vereinfachen.
| AWS Data Pipeline | Azure Data Factory | Google Cloud Dataflow |
| Bedienung: ☆☆
Lifecycle Management: ☆ Möglichkeiten: ☆☆ |
Bedienung: ☆+
Lifecycle Management: ☆☆ Möglichkeiten: ☆☆ |
Dataflow nicht separat
für ETL Aufgaben getestet. |
Weiterlesen
Im nächsten Artikel widmen wir uns dem Thema Analytical Data Store mit den hochskalierenden Technologien AWS Redshift, Azure Data Lake sowie Google Big Query.
Bis dahin lohnt sich ein Blick auf unsere Website, wo wir unser komplettes Dienstleistungsportfolio rund um den Themenbereich Analytics vorstellen. Bei Fragen freuen wir uns auch über direkten Kontakt in den Kommentaren, per Mail an info@inovex.de oder telefonisch unter +49 721 619 021-0.
Die Blog-Serie im Überblick:
- Einleitung, Vergleich des Look & Feel sowie Vorstellung von Use Case & Architekturen
- Collection und Storage
- Computation (dieser Artikel)
- Analytical Data Stores
- Data Presentation und Fazit
Join us!
Wir suchen Verstärkung für unser Analytics-Team! Wir freuen uns auf Bewerbungen!



One thought on “Cloud Wars: Computation [Teil 3]”