
Hinweis:
Dieser Blogartikel ist älter als 5 Jahre – die genannten Inhalte sind eventuell überholt.
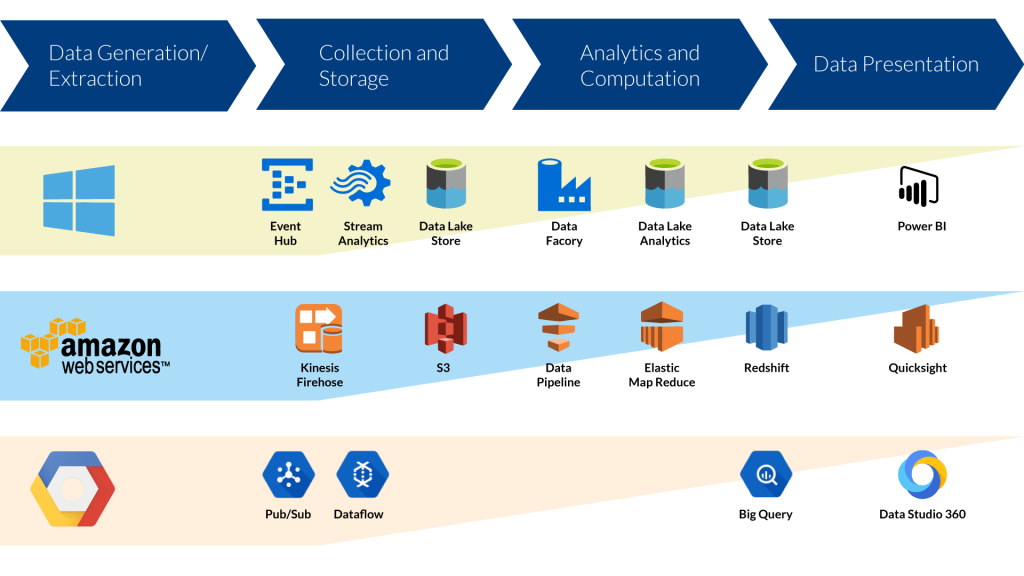
Die großen Public-Cloud-Anbieter locken inzwischen mit Platform-as-a-Service-Angeboten, die versprechen, Daten jeglicher Art performant und kosteneffizient zu speichern und zu verarbeiten. Neben unterschiedlichen Datenbanken gibt es dazu Dienste für Batch- und Realtime-Processing, die wir in diesem Artikel vergleichen.
Analytical Data Stores
Alle drei betrachteten Cloud-Anbieter bieten Data-Warehouse-Lösungen, die nach der Massively-Parallel-Processing-Architektur aufgebaut sind. Durch eine Aufteilung der Berechnungen auf mehrere Rechner in einem Cluster, also die horizontale Skalierung, kann ein deutlicher Performance-Gewinn erzielt werden. Weitere Geschwindigkeitsoptimierungen werden bei den Herstellern durch spaltenorientierte Datenbanken, Komprimierung und In-Memory Caching erzielt.
Die Data-Warehouse-Lösungen bieten in der Regel eigene ODBC/JDBC-Treiber an, sodass auch gängige ETL Tools zur Beladung verwendet werden können. Auch Analyse-Tools und Visualisierungen lassen sich durch die standardisierte Schnittstelle verbinden. Aufgaben wie Einrichten, Betreiben und Skalieren werden vom Cloud Provider übernommen und sind so stark vereinfacht.


Redshift: fully managed, petabyte-scale data warehouse service in the cloud.
Analytische Datenspeicher bei AWS
Für die Analyse von strukturierten Daten bietet AWS mit Redshift ein skalierbares Data Warehouse für SQL-basierte Abfragen und BI Tools. Redshift ist eine auf einem Postgres Fork basierende, horizontal skalierende Data-Warehouse-Lösung. AWS Redshift wird lediglich serverseitig provisioniert, eine Entwicklungsunterstützung im Web Interface sowie eine Entwicklungsumgebung fehlen.
SQL Tools wie SQLWorkbench/J oder Squirrel Sql Client können den bereitgestellten Treiber nutzen und über JDBC/ODBC Querys absetzen. Die Abarbeitung der Anfragen wird auf die konfigurierten Nodes verteilt und parallel ausgeführt. Durch die spaltenbasierte Speicherung sind Analysen in Redshift sehr schnell und benötigen keine Indices. Regelmäßige automatisierte Backups erhöhen die Datensicherheit.
Redshift ist ein Postgres Fork – und diese Verwandtschaft merkt man ihm an einigen Stellen an. Eine unabhängige Skalierung von Speicher und Compute-Ressourcen wie beim Azure DWH ist nicht möglich, da darunterliegende Instanzen gewählt werden müssen
Einsatz im Use Case
Für die Wetterdaten wurde eine Zieltabelle in Redshift angelegt, die von Kinesis Firehose kontinuierlich mit den aktuellsten Daten befüllt wird. Außerdem werden durch die regelmäßigen Ausführungen eines Hive Jobs voraggregierte Daten erstellt und vom Hadoop Cluster in eine Tabelle in Redshift übertragen.
Zunächst zeigen wir das Anlegen und Konfigurieren eines Redshift Clusters in der Amazon Web Console:
Dann demonstrieren wir das Anlegen von Tabellenstrukturen und nach dem Befüllen über Kinesis Firehose das Abfragen der Daten in einem SQL Query Tool:



Azure Data Lake Analytics: Analyse any kind of data of any size.
Azure SQL Data Warehouse: „An elastic data warehouse as a service with enterprise-class features.“
Analytische Datenspeicher bei Azure
Um Analysen auf große Datenmengen auszuführen, eignet sich das bereits im letzten Abschnitt vorgestellte Data Lake Analytics. Mit USQL als Abfragesprache und der Integration in Azure Data Factory und Power BI stellt es aber insbesondere für semi-strukturierte Daten eine gute Alternative zu rein relationalen Datenspeichern dar. Die Kombination von TSQL und C# erhöht zusätzlich die Flexibilität und ermöglicht auch das Einbringen von komplexen Kontrollstrukturen. Die Unterstützung in Visual Studio erleichtert das Arbeiten und verbessert den Application Lifecycle.
Die direkte Konkurrenz zu Amazon Redshift und Googles Big Query ist Microsofts SQL Data Warehouse. Hier sind auch ODBC/JDBC-Treiber verfügbar, sodass sich das DWH gut in die Systemlandschaft integriert. Das DWH sollte vor allem dann verwendet werden, wenn Informationen dauerhaft verfügbar sein müssen oder häufig von Nutzern oder interaktiven Report-Querys abgefragt werden.
Das SQL DWH basiert auf dem relationalen Datenbankmodul von SQL Server, ist aber durch die verteilte Ausführung auf mehreren Knoten und (optional) spaltenbasierte Speicherung auf Analysen ausgerichtet. Die Skalierung von Speicher und Computerressourcen erfolgt sehr schnell und unabhängig voneinander. Microsoft verspricht den annähernd vollen T-SQL Umfang. Hinsichtlich Skalierung und Funktionalität ist Azures SQL DWH gegenüber Redshift überlegen.
Einsatz im Use Case
Die von Azure Stream Analytics in den Data Lake Analytics Store gespeicherten Daten können nun mittels Data Lake Analytics mit U-SQL verarbeitet werden. Für die Verarbeitung der Daten mit Azure Data Factory und die Visualisierung der Daten in Power BI gibt es direkte Schnittstellen. Azure SQL DWH wurde für den Anwendungsfall nicht getestet.
Nachfolgend zeigen wir das Ausführen einer Query auf dem geladenen csv File über die Abfragesprache U-SQL in der Entwicklungsumgebung Visual Studio 2015. Dateien können in Visual Studio wie Tabellen in einer Preview betrachtet werden. Das USQL Script besteht aus dem bereits typisierten Input im oberen Teil des Scripts, der Query für die Aggregation der Wetterdaten sowie dem Pfad für die Zieldatei. Beim Start der Abfrage (Submit) kann der Grad der Parallelisierung über einen Schieberegler angegeben werden, was sich natürlich auf die Performance auswirkt. Es folgt eine Statusübersicht der Verarbeitungsschritte und eine Art Ausführungsplan, der je nach Komplexität des Statements auch ausführlicher aussieht kann als in dem Beispiel:


Analytische Datenspeicher bei GCP
Zur Verarbeitung von Daten bietet Google Big Query eine zum SQL-Standard konforme Lösung. Wie auch bei der Konkurrenz handelt es sich dabei um eine massiv parallele spaltenbasierte Lösung, die sich gut für Data Warehouse Workloads eignet. Google verbirgt allerdings jegliche Umsetzungdetails und Hardware vor dem Kunden, auch die Skalierbarkeit. Bezahlt wird nach der Menge der Daten, die von Big Query verarbeitet werden. Für Kunden ist das finanziell dann interessant, wenn nur sporadisch Querys abgesetzt werden. JDBC/ODBC-Treiber sind verfügbar. Praktisch ist zudem der Zugriff über das Web Interface, in dem sich Tabellen als Vorschau anzeigen oder ganze Querys ausführen lassen.
Einsatz im Use Case
Für die Wetterdaten wurden geeignete BigQuery Tables angelegt, die von dem Dataflow Programm gefüllt werden.
Im folgenden Video zeigen wir die Weboberfläche für Google Big Query, in der zunächst in einem Projekt die gewünschte Tabelle mit ihren Metadaten dargestellt wird. Auch hier gibt es eine praktische Preview-Funktion für einen ersten Einblick in die Daten. Die Abfrage erfolgt dann unter „Query Data“ inklusive Syntax Highlighting.
Bewertung der Dienste für Analytical Data Stores
Mit ihren horizontal skalierenden Lösungen haben die Anbieter ähnliche Anwendungsfälle etwas unterschiedlich gelöst. Redshift und Azure DWH sind klassische DWH-Lösungen die mit ihren eigenen ODBC/JDBC-Treibern in gängige Tools integriert werden können. Beim IaaS-Marktführer AWS läuft die Bezahlung strikt nach Hardware, wohingegen bei Big Query und Data Lake Analytics Kosten entsprechend der Query anfallen.
| Amazon Redshift | Azure Data Lake | Big Query |
| Bedienung: ☆+
Lifecycle Management: ☆☆ Möglichkeiten: ☆☆ |
Bedienung: ☆☆☆
Lifecycle Management: ☆☆☆ Möglichkeiten: ☆☆☆ |
Bedienung: ☆☆+
Lifecycle Management: ☆☆ Möglichkeiten: ☆☆ |
Weiterlesen
Im nächsten Artikel widmen wir uns dem Thema Data Presentation mit den Cloud-basierten Visualisierungs-Tools Amazon Quicksight, Microsoft Power BI und Google Data Studio 360. Außerdem präsentieren wie unser Gesamtfazit zur Studie der drei großen Cloud Provider!
Bis dahin lohnt sich ein Blick auf unsere Website, wo wir unser komplettes Dienstleistungsportfolio rund um den Themenbereich Analytics vorstellen. Bei Fragen freuen uns auch über direkten Kontakt in den Kommentaren, per Mail an info@inovex.de oder telefonisch unter +49 721 619 021-0.
Die Blog-Serie im Überblick:
- Einleitung, Vergleich des Look & Feel sowie Vorstellung von Use Case & Architekturen
- Collection und Storage
- Computation
- Analytical Data Stores (dieser Artikel)
- Data Presentation und Fazit
Join us!
Wir suchen Verstärkung für unser Analytics-Team! Egal ob Business Intelligence Entwickler (m/w/d) oder Werkstudent (m/w/d) im Bereich Data Management & Analytics oder Software Entwickler (m/w/d) mit Schwerpunkt Big-Data-Technologien: Wir freuen uns auf Bewerbungen!



One thought on “Cloud Wars: Data Storage und Analytics [Teil 4]”