
Data observability is key to today’s business world when it comes to digitizing and automating processes and being a data-driven company. Data catalogs are the foundation when focusing on establishing and improving data observability in a company. In the following, we will compare three data catalog tools that are available as open source extensively. Thereby, we will not compare them via their shining feature descriptions on their homepage. Instead, we got our hands dirty and dug into them deeply. We actually used the tools, ingested data from sources, and discovered the functions ourselves.
What is a Data Catalog?
But as a first step, let’s shed some light on: What is a data catalog? What can I expect? What are the advantages of starting to use such a tool?
A data catalog can be seen as a digital equivalent of a library. As a single source of truth, it contains all information about the company’s data stock. Moreover, it helps to find the data already available for usage. A catalog provides an entry point and supports people interested in consuming new data in their selection, by including additional metadata about all data assets. Metadata here can be, for example, the storage location, data owners, if data is considered as personal identifiable information (PII), or information on data quality. In addition, additional features like a search interface or entity tagging can increase the usability for non-technical users. In either case, a data catalog serves as the first stop to find all data assets in your company. Assets can be of various types like tables, files, processes, metrics, etc.
With all the features the whole company benefits from a unified overview of all data supporting the management of their data infrastructure like Data Lakes or Data Meshes. It addresses or supports the following topics:
- Data Freshness: How up-to-date is the data we want to use?
- Data Security/Governance: Who do I need to contact to get access to the data? Does the data contain sensitive information?
- Data Redundancy: Is the data we are looking for already provided by another team in the company and already available?
- Data Discrepancy: How can we integrate all of the data across our organization? How can we ensure that the same standards are consistently applied across the organization?
- Data Documentation: What does an attribute mean? What’s the purpose of a dataset?
- Data Quality: Does the data have good quality? Which checks are carried out and according to which schedule? How does the data quality develop over time?
- Data Lineage: Who uses which data and will be affected by schema changes?
As the above arguments already make clear, it makes sense for many companies to start building their own catalog. But before we continue with our comparison, let’s take a quick look at the current trend of Data Mesh.
One of the core principles of Data Mesh is to move the responsibility away from dedicated data teams to domain or product teams. This means more decentralization and democratization of data ownership. To achieve this, it is essential to have an overview of what data is available and maintained by which team in order to coordinate data sharing, etc. Furthermore, this reduces the risk of duplicating efforts or slowing down processes. So the catalog as a major center piece allows everybody to scroll through the data which is available (probably limited by governance rules) without the need of technical access and possible governance violations. Without this, the Data Mesh would become a collection of data silos instead.
Comparison Setup
Before we introduce the tools we chose for this comparison, we would like to shed some light on the deployment setup for our comparison. In order to have a „production-like“ environment, we decided not to use the local Docker-based quick-start setup. This is provided by many tools for demo and quick trial-and-error purposes. Instead, we want to deploy the catalog on Kubernetes. This is a setup we often see with our customers. To make things a little easier, we deploy the required backend databases as deployments with persistent volumes. However, this is not an option for a true production deployment. Instead, we should rather rely on a full database instance or managed databases from the cloud provider to simplify availability and backup.
In this comparison, we use Google’s Kubernetes Engine (GKE) on Google Cloud Platform (GCP) and BigQuery as an example of ingestion sources.
Catalog Candidates
There are many commercially licensed catalogs, but we like the idea of open source tools. In particular, the flexibility in how you can integrate the tools into your existing environment. By using an open source data catalog, you can easily adapt it to your own needs (if required). In addition, being able to delve into the codebase can help you a lot during the initial deployment in case it does not work straight out of the box. Therefore, we limit this comparison to three open source catalogs which we see the most potential in.
After some research, we selected the following:
-
- DataHub, most prominent open source catalog, originally developed by LinkedIn
- OpenMetadata, an up-and-coming catalog with a slightly different approach
- Amundsen, a somewhat older and stable catalog solution originally developed by Lyft
In the following, we will introduce the three catalog tools in detail, talking specifically about their components, and how we decided to set them up.
Amundsen
![]()
Amundsen went open source in 2019 and was born out of a desire to master data discovery and data governance at Lyft. It is a well known and established data catalog tool that one should consider when investigating data catalogs. In terms of required components, Amundsen is the most simple tool in our comparison. It only requires two prerequisite services to be available: Elasticsearch as search engine and Neo4J as graph index. As an alternative, one can also use Apache Atlas instead of Neo4j.
Within the scope of this evaluation, we decided to go with Neo4J. In the medium term, this setup may become simpler as Elasticsearch can also act as a graph index, but this is speculative at this stage. We are not aware of Amundsen considering this change.

Building on this foundation, the backend of Amundsen consists of two services: the metadata and the search service. In contrast, the frontend consists only of one service. It communicates via REST APIs with the search service to provide features such as full-text search to end users. For this, the required technical metadata and information are retrieved from the metadata service, which uses the state stored in Neo4j. To ingest metadata, Amundsen provides the databuilder library which allows users to extract metadata from various source systems and send it to Amundsen in the expected format.
Amundsen sounded really interesting at first sight. Unfortunately, as we got deeper into the research, without finding more recent resources or articles, it started to feel a bit old and stale. Nevertheless, we tried to deploy an instance in our Kubernetes cluster to play around and evaluate the system. Sadly, the public helm chart could not be used because there are a lot of outdated sources. It uses an older Neo4J version than the databuilder library expects, so it is not really usable. We tried to update the sources, but stopped after a while because the documentation was sparse. Furthermore, we did not want to invest too much time in one catalog when we have promising other catalogs in the pipeline.
In their Slack, we found a statement from one of the maintainers that Amundsen is more in a maintenance and stability mode. In addition, the maintainers (of Lyft) do not actively develop features for the OSS system and only support community contributions. With this in mind, we have decided not to consider Amundsen further (or without practical experience) in this comparison for the time being.
OpenMetadata
![]() OpenMetadata started open source in mid 2021 and wants to address the following topics: Discovery, Collaboration, Governance, Data Quality, and Data Insights. It defines itself as an active metadata platform rather than a simple data catalog. And that brings real benefits to the entire organization. Collate, which also offers a SaaS solution of OpenMetadata, is the primary developer and maintainer of OpenMetadata.
OpenMetadata started open source in mid 2021 and wants to address the following topics: Discovery, Collaboration, Governance, Data Quality, and Data Insights. It defines itself as an active metadata platform rather than a simple data catalog. And that brings real benefits to the entire organization. Collate, which also offers a SaaS solution of OpenMetadata, is the primary developer and maintainer of OpenMetadata.
One special feature OpenMetadata offers is the ability to interact with other catalog users directly. The change feed on the starting page shows the latest changes made by whom. One can start conversions on changes/metadata, request tags and terms to entities, and assign the task to other people in the company which are able/allowed to verify it (see the figure below). Sloppy speaking, one could say that OpenMetadata is the social network among data catalog tools.
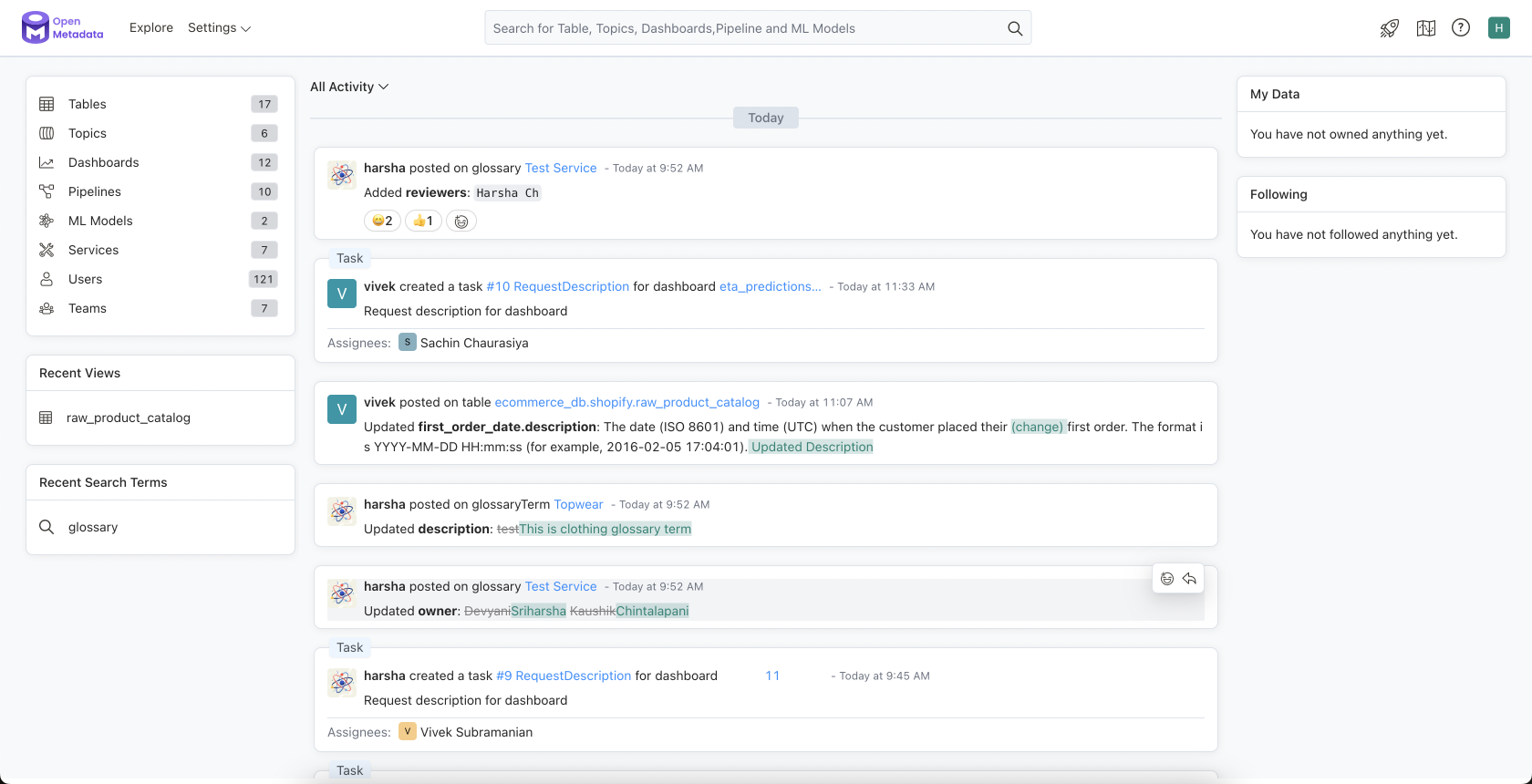
In terms of required components, OpenMetadata is slightly more demanding than Amundsen. However, it has a very simple and lean architecture itself. In addition to an instance of Elasticsearch (alternatively you can also use OpenSearch) as the search engine and graph index, and a Postgres or MySQL database instance, it requires an instance of Apache Airflow to orchestrate the metadata ingestion. Albeit, OpenMetadata does only recommend using Airflow, you can also use an orchestrator of your choice. If you are interested in an in-depth comparison of modern orchestrating tools, have a look at our blogpost “Data Orchestration: Is Airflow Still the Best?“.
OpenMetadata itself has a rather simple architecture, there are only two services required: openmetadata-ingestion and openmetadata-server. The first is responsible for ingesting metadata from various sources. This is orchestrated by the Airflow component. Therefore, it uses OpenMetadata’s ingestion library (openmetadata-ingestion). This library can also be used if metadata ingestion is not to be done in the UI. The latter service contains both the actual backend of OpenMetadata and the corresponding frontend. All communication within OpenMetadata happens through REST APIs. Please see the figure below to get an overview of all required components and how their interact.

For our OpenMetadata deployment, we went with the default component choices. We deployed Airflow as an orchestrator, Elasticsearch as search engine and graph index, and MySQL as database. Using OpenMetadata’s official helm chart and their instructions for deploying to GKE, the deployment was fairly straightforward and worked out of the box like a charm.
DataHub
DataHub is an event-based data catalog and – based on its range of features – can be considered a metadata platform analogous to OpenMetadata. It was originally developed and used internally by LinkedIn. In early 2020, they decided to release it as open source. Since then the adoption and community around it grew rapidly. Today, DataHub is mainly developed and maintained by Acryl. They also have a SaaS offering for DataHub on their product line. Nevertheless, Acryl is strongly committed to the open source model and promises to remain “truly open source“. This means that the vast majority of features (if not all) are and will be part of the open source distribution. However, they may not be at the same level of maturity or sophistication. In fact, this is then left to the open source community.

Looking at the architecture, DataHub can be considered for sure as the most complex of all candidates in this comparison. The following components are required as prerequisites for DataHub:
a) relational database to store metadata, which serves as source of truth of all information in DataHub. Officially supported are MySQL, Postgres, and MariaDB.
b) Elasticsearch as search engine
c) a graph index which can be realized by using again Elasticsearch or going with Neo4J
d) a message broker that fosters the event-based communication between DataHub’s internal components. Apache Kafka is the default choice here.
e) until version 0.10.3 a schema registry has been required as well but this is now obsolete
DataHub itself constitutes at least two different services:
a) the backend itself. Due to the event-based nature of DataHub, any interaction in the user interface that affects metadata, or the ingestion of metadata, creates an event in a Kafka topic. That event is picked up by the backend service to update the database. This functionality can be outsourced to two additional services that can be managed individually: the Metadata Change Event (MCE) consumer service and the Metadata Audit Event (MAE) consumer service. The ingestion of metadata takes place either in a dedicated container, if it has been configured and started in the frontend. Alternatively, one can ingest metadata programmatically by using the Python SDK.
b) the frontend. The frontend communicates with the backend via its GraphQL interface. Thus, the user can search for metadata, add tags, or modify the metadata, which is then communicated to the backend through Kafka.
Of course, this architecture brings more complexity into play than the other tools, which means more effort to implement and maintain. Nonetheless, this is also a differentiator, as it increases flexibility. It allows DataHub to be scaled more individually, and provides a lot of powerful tools to build custom use cases on top of it.
Using DataHub’s helm charts and keeping the recommended default setup (MySQL as database, dedicated Kafka instance, Elasticsearch for search & graph index, MCE & MAE in the backend), deploying DataHub was quite easy for us and worked immediately.
Feature Comparison
With the above overview of the various candidates and their architectures, it is now time to do a detailed comparison between them. First, we begin with a tabular overview of some hard and some easy-to-grab facts. Second, we present a detailed feature comparison based on our own sandbox deployments. In this section we refrain from including Amundsen, as we don’t feel comfortable to judge without being able to speak from our personal experience.

That’s about our general impression of both tools, let’s now come to the most interesting part. In the following, we will contrast them in detail alongside some carefully selected aspects which we assess as essential for a data catalog tool. This comparison is entirely based on our sandbox environment that we created for this blogpost.
Metadata Ingestion
In OpenMetadata the metadata ingestion configuration can happen (and we guess it’s the preferred way) via the UI. Alternatively, it can be done by writing down the configuration in a YAML file and ingesting metadata via the CLI tool or SDK from locally/external systems. The setup via the UI feels really easy and is combined with an interactive and high-quality documentation at the side that really stands out.

Additionally, the ingestion can be scheduled by a (internal) deployment to the Airflow instance. You then get the state of the runs directly in the UI and can see logs etc from there. OpenMetadata has different ingestion types, the first one is always the ingestion of metadata itself. Based on this one can additionally configure additional ingestions for these sources, e.g., lineage information or data profiling.

The options DataHub offers are quite similar. It allows you to define the ingestion via the UI. The ingestion is then internally scheduled by a cron mechanism and executed in a separate container. Alternatively, one can define YAML recipes and trigger the ingestion from any supported system by using the CLI or SDK. All ingestion options, even lineage and profiling, are defined and configured in one place and not separately.
In contrast to OpenMetadata, the configuration in the UI is not that ideal. A lot of config options seem to be missing and API/config changes are not reflected or documented enough. So you need to open the documentation in parallel or best stay with the YAML config which is also possible in the UI and works better. Regardless, you can view and jump directly into the assets created by each ingest run.

Be aware that both tools have connectors with a higher or lower level of maturity. So depending on your tech stack, one catalog might be preferable to the other just because it better supports your existing system landscape.
Lineage Details
OpenMetadata offers out of the box table and column level lineage for views with a nice visualization in the UI. The required data is extracted by parsing the SQL statement of the underlying asset. It also recognizes renaming of columns without issues.

DataHub on the other side offers table lineage extraction by using a SQL parser, DDL statement or (in case of BigQuery) by reading job logs. This worked in our case also flawlessly.
At evaluation time DataHub didn’t support column level lineage for BigQuery, but it should be available in the current release.
Both tools allow you to manually modify the lineage in the web UI. This can be beneficial for lineage that is not directly technically visible, but needs to be maintained for notifications. Moreover, DataHub even allows for file-based lineage definition and programmatic ingestion of lineage information.
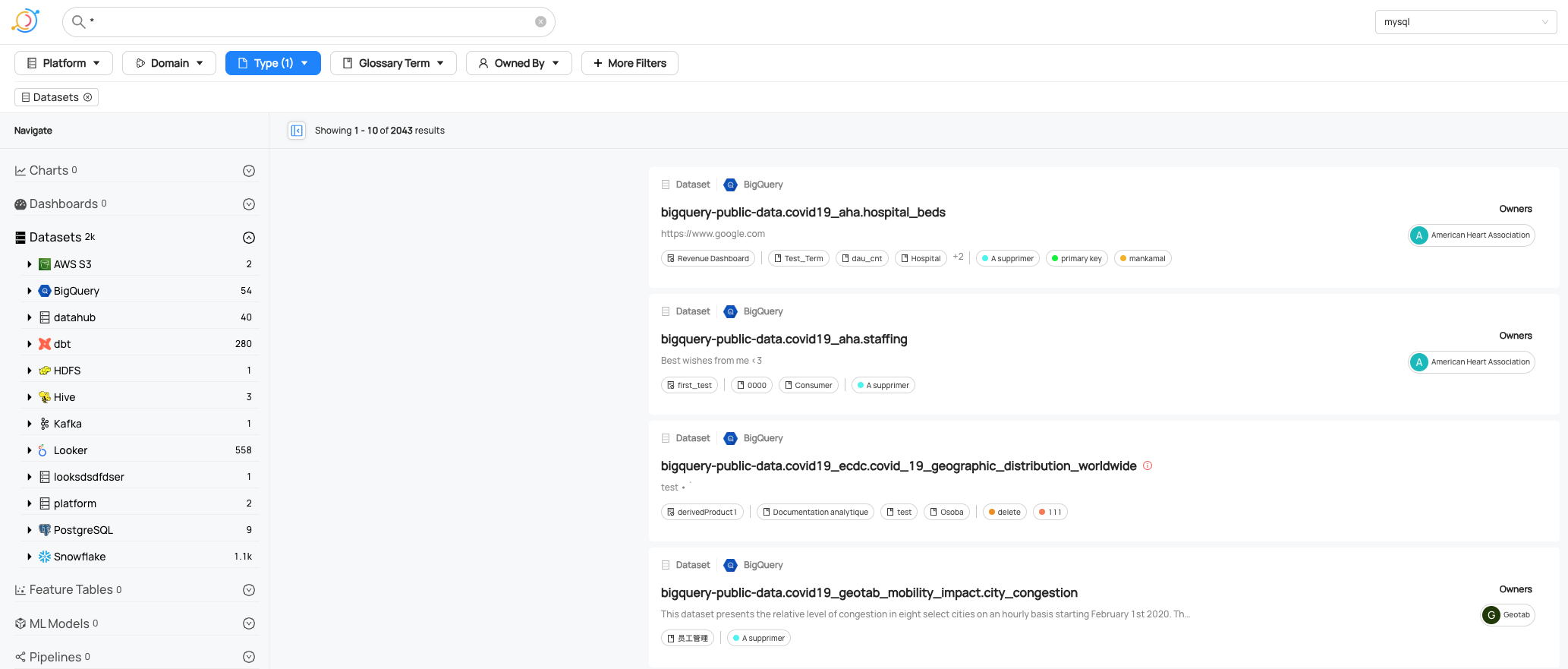
Exploring/Navigating in the Catalog
At first glance, OpenMetadata’s Explore section seems a bit unstructured, as it doesn’t have a natural hierarchical structure. However, assets are easy to find thanks to a variety of filtering options and a reliable search.
DataHub structured their explore navigation a bit differently, e.g. for BigQuery tables the navigation is based on environment -> GCP project -> dataset -> table. So it’s more a technical way of navigating through the catalog which could be counterintuitive for non-techies. This has been the default navigation style until 0.10.5. From then on, DataHub launched a new browse and search page. This is now the default page of DataHub, but the old one is still available.
Profiling and Metadata Tests
In OpenMetadata profiling can easily be added via the UI. It provides convenient parameters like either the row count or percentage of the table to use for profiling. In addition, there is an automatic PII tagging functionality which can be applied to columns individually. Test cases for some columns can be added per table directly in the profiling tab. Once all cases are configured, a simple click on Create Test Suite will create a job. With deploy, schedule, or run action the test is deployed and executed as an additional Airflow DAG. Upon completion, you can then view the results directly in the data asset. It is also possible to define the profiling or tests via YAML config and submit them via the CLI tool or the SDK. This way, you can generate them from personalized configs if you want to apply the same settings to multiple tables.
In case a metadata test fails lately it gets marked as new and a user can acknowledge the failure. Later, after investigation, one can resolve it with a comment about what the root cause is. This will keep all discussions and resolutions in one place and visible to all interested persons. In the next (v1.2) release, a new page for browsing the history of issues will be added.

In DataHub, profiling is part of the metadata ingestion recipes. This means that with each ingestion run, jobs are run to profile the tables. As this could be costly, they have built in functionality to reduce the amount of data to be processed. For example, by only reading the latest partition or only if the table has changed since the last run. Additionally, the metrics to be calculated can be configured per recipe, so either for one table or all in the datasets/project. This can be both an advantage and a disadvantage depending on the number of tables and profiling requirements.
DataHub has also built in testing by supporting Great Expectations but the tests aren’t managed by DataHub itself. Instead, one needs to run the test suite externally and configure Great Expectations accordingly. The results are then automatically communicated to DataHub through the REST API. For explicit metadata tests they provide an interface but from the UI it’s only usable in the SaaS solution. It allows automated asset classification and governance monitoring, like checking if a data asset is properly tagged, has a user or description, and things like that.

Authorization
One of the main principles of a data catalog is to allow people to discover data assets. Though, organizations often want to control access at the individual or team level. Therefore, authorization features often play an important role when introducing a new tool. In general, both DataHub and OpenMetadata allow for authorization management via roles and policies.
In OpenMetadata, you can assign roles to users and teams to control who can do what with the entities. Teams can be managed from within OpenMetadata. Unfortunately, it’s not yet supported to take recourse to groups defined in the authentication provider. A team can be one of the type Organization, Business Unit, Division, Department or Group to try to reflect your hierarchical structure in the organization.
A role consists of one to several policies, and policies consist of multiple rules (e.g., Glossary, Add Owner). It defines which operations the actors are allowed to perform on which resources based on optional conditions such as isOwner or similar.
Comparatively, DataHub provides the ability to use users and groups (e.g. ingested via Azure AD or created in DataHub) to manage asset access and permissions. They suggest using roles and applying them to users, but for advanced use cases you can also directly create policies that are used by the roles under the hood. Policies are separated into platform permissions, like managing users, and metadata permission, like adding tags or terms to entities. While platform policies just give privileges to actors (users, groups), metadata policies define privileges to actors (users, groups or owners) for specific resources only. This allows fine grained access controls based on teams, domains or other levels which are relevant to you.
Upgrade and Deployment
For upgrades of the Helm chart, OpenMetadata provides detailed steps on how to migrate to the next version. They include the backup steps in case of a rollback and necessary manual steps to migrate schemas. In contrast, DataHub Helm charts are equipped with four Kubernetes jobs for setting up and migrating Kafka, Elasticsearch, SQL DB and the system itself which does everything for you.
So for the happy path and without a dedicated platform team DataHub is the more comfortable way for upgrades and deployments but if something does not work out of the box (and we faced it in production already). In contrast, OpenMetadata seems to have the better documentation and detail level to identify what changed and how to rollback or fix it. However, with the release of version 1.1.1 introduced a migration job that performs some migration tasks during the deployment. So let’s see whether our impression holds true for future releases as well.
Roadmap
Both catalogs provide a detailed roadmap at least for the next major release which sounds promising and proves an actively developed project.
Nevertheless, while DataHub is mostly focused on enhancing the OSS version and (so far) only developing minor SaaS features on the OpenMetadata side, it looks quite the opposite. Certainly a lot of OSS features will be added, but also some of the interesting features will only be available in the SaaS offering and it looks like the same for the next releases. So maybe they will focus on getting people on the platform in the future, but that’s just a feeling from our side. They may also support a lot of community contributions like DataHub does so that it remains valuable as an OSS variant as well.
References:
OpenMetadata OSS roadmap
DataHub OSS roadmap
In summary, we have also condensed our extensive comparison into a visual representation. Please bear in mind that we only want to highlight a slight preference for one of the tools when one bar is out. We are not suggesting that one tool is completely superior to the other. Both do a really good job in all of these categories, as you should have seen in our comparison above.

Summary
In our case, Amundsen didn’t make the cut. Thus, we were left with OpenMetadata and DataHub, but even with that narrow selection, it’s not easy.
Both authors already have a lot of practical experience with DataHub since it was released as a small project in 2021. We like the simplicity and extensibility of the project to adapt it to our needs and processes. In addition, DataHub really feeds our engineering mindset as a lot of features allow a lot of customization for advanced usage.
But the capabilities of OpenMetadata, how quickly they’ve gotten to a state where it’s a real competitor to DataHub, and the look and feel make it a great candidate. As already mentioned, the interaction-based design is a key differentiator. In addition, governance-related features are better supported. Requesting changes to data assets, assigning tasks, or approval workflows are natively supported, to name a few. In general, Open Metadata feels cleaner and more stable than DataHub, and we would give it a chance.
There is one aspect we can only express as a gut feeling (the future will tell). At the moment OpenMetadata is a great OSS product, but looking at the roadmaps it seems that in the future the managed service will be promoted more than the OSS project. However, we do not want to put too much weight on this and hope that our impression is deceptive. DataHub on the other hand is really community driven (so far). We don’t have the feeling that many useful features will only be available in the managed version.
In summary, we are really glad that there are two such great data catalog tools available as open source. Both are solid choices for any organization looking to improve its data management. The final choice depends on your preferences and your individual use case and requirements.
If you would like to discuss data management and our experience with data catalogs, or if you would like a small workshop, please contact us.
How do you like this comparison? Do you disagree at any point? Let us know in the comments.


