
Nowadays, we rely a lot on technology. As such every second a tremendous amount of data is being collected and processed. Companies can only utilize this tremendous amount of data by building reliable, maintainable, and robust data pipelines. A large company, especially a technology-oriented company, can have more than a thousand data pipelines. How can companies manage so many pipelines?

This is only possible due to data orchestration tools like Airflow whose primary task is to simplify the management of data pipelines. Data orchestration is a subfield of workflow orchestration. Workflow orchestration is responsible for the management of related tasks. For instance, when you wake up in the morning, you will probably follow your routine: tooth brushing, making yourself a sandwich, hopping into the shower, and so on. Every activity represents a task. You will usually do them in order, but you could also do some of them simultaneously, e.g. toasting your toast and going in the shower. All of these tasks would be related.
The same concepts apply to data orchestration, e.g. pulling data out of some database, storing raw data into some file on a file system, validating your data, aggregating your data, and so forth. All of these activities can be viewed as tasks that we need to work off to get our desired result. A typical result could be a cleaned and validated dataset for machine learning model training.
If you have only one pipeline, you would not need any orchestration tools. Orchestration gets more interesting when you have several pipelines which need to be managed and which need to be run on schedule. E.g. one pipeline should run every hour, the second should run daily at 6 a.m. and the third one needs to run every 10 minutes. Of course, you could set up some cron job that executes your pipelines at the right time but you would need to manually manage all of these cron jobs. Moreover, the cost of maintenance increases dramatically with every new feature you add to your pipelines, e.g., data governance features, logging, or monitoring. All of these requirements can potentially be handled & facilitated by a data orchestrator. But before diving into the world of data orchestration, let us have a look at the history of workflow orchestration.
Airflow’s appearance
Cron jobs
Before any open-source workflow orchestration tools were released, developers had to set up cron jobs. On UNIX systems, a cron job utilizes cron-daemons. These daemons are processes that run in the background and most often fulfill maintenance work. Creating a cron job is pretty simple. Imagine, you have a bash script named „example.sh“ and you want to run this bash script every 5 minutes, then you could open your crontab configuration via
|
1 |
crontab -e |
and append into this configuration file the following line:
|
1 |
*/5 * * * * ./example.sh |
That’s it. Furthermore, the cron-daemon was invented by Brian W. Kernighan. The algorithm behind the original cron-daemon is very simple. You simply have an infinite long-running process that would check every minute whether the time condition is fulfilled. If it is fulfilled, it will launch a child process that runs the given command. In our case, it will execute the bash script. If it is not fulfilled, it will just wait for the right time to come. A common problem that can arise is when a daemon unexpectedly stops working, then you would need to manually restart the daemon.
Furthermore, cron jobs are only able to launch a process but don’t provide any monitoring or logging utilities. Also, the daemons run on only one machine, there is no trivial way to distribute jobs across machines, thus scalability is a problem. On top of that, there is no clear separation between local development environments and a production server. But it was never the cron job’s intention to cover all of these aspects, developers have just misused cron jobs to launch workflows.
Spotify: Luigi
The need for data orchestration increased when more and more data needed to be handled. Spotify was a front-runner and created Luigi which was the first tool that launched as an open-source project in late 2012. Luigi offered a class-based approach to data orchestration and propagated the notion of tasks. With Luigi, you can define tasks as classes, define dependencies between them and let them run together. A classic object-oriented design (OOD) approach. But Luigi lacks features like a pipeline trigger. You still need a cron job to trigger Luigi pipelines at the right time.
Airbnb: Airflow
In June 2015, it was time for Airflow, which was developed at Airbnb, to appear on the stage as an open-source project. Airflow was the first workflow orchestration tool to have a modern-looking web UI and a scheduler with a trigger that can kick off pipelines on schedule. As time has gone by, the open-source community has grown and more and more features have been implemented in Airflow. During that time, Airflow was regarded as the best open-source workflow orchestration tool and that is why so many companies have adopted Airflow into their production environment.
Later on, workflow orchestration tools like Kubeflow, Argo, Flyte, Prefect, Dagster, and many more emerged, challenging Airflow’s position in this domain.
Airflow’s dominance
You might ask: “What made Airflow so popular and dominant?“ The answer to this question can be given by looking closer at Airflow. Airflow describes itself on the official homepage as follows:
“Airflow is a platform created by the community to programmatically author, schedule and monitor workflows“
Airflow’s strength lies in the fact that the open-source community has become fairly large and active. Authoring pipelines in Airflow can be only done via the programming language Python. Since this is a very popular language, it is a convenient choice for many developers out there. Airflow is also providing a lot of features that help develop and monitoring data pipelines. Moreover, since Airflow was one of the first data orchestration tools to go open source and provide a web UI, many developers were gravitating towards Airflow. Moreover, as time has gone by, all large public cloud vendors have published a managed service for using Airflow in production-ready environments. But can Airflow hold its dominant position in the long term?
Let’s assess Airflow’s current position by experimenting! Let’s build a toy pipeline in Airflow.
The Experiment
But this experiment would be boring without competitors. Our competitors in this experiment will be two other data orchestration tools, Dagster and Prefect! Why Prefect and Dagster? In my opinion, these orchestration tools have the highest potential to surpass Airflow in the long term.
To systemize our experiment, I will present you with 7 assessment categories – each data orchestration tool will be ranked in each category. Each tool can collect up to 5 stars in each category. In the end, we will sum up the number of stars each tool collected and elect the champion of this little experiment. These are the assessment categories: Setup/Installation, Features, UI/UX, Pipeline Developer Experience, Unit Testing, Documentation, and Deployment.
Before diving into the code of the actual pipeline we are going to implement, I want to give you a little backstory to this pipeline: Imagine we are the CEOs of some franchise restaurants. Each restaurant is managed by a dedicated manager and after each day, the manager will register the revenue that the restaurant made. We, as the CEOs, want to know whether our franchise is performing well or badly, so we tell our Data Engineer to build a pipeline that should generate two plots, one showing how the revenue of each franchise develops over time per day and the second one showing the average revenue made by each franchise. The structure of the pipeline will look as depicted in figure 1.

Prerequisites
Before you can follow along with this experiment, we have to install Airflow. A simple method to install Airflow is to use Docker/Docker Compose. Just follow the steps in the official documentation. There is just one subtlety that is not mentioned in the documentation right away and that is how to define our dependencies since we will use pandas for data frame manipulation and plotly for plot generation. Also, we will need a provider package that allows us to connect to a Postgres database. This step comes before executing the command docker compose up. Copy & Paste the following requirements.txt file into your Airflow home directory under $AIRFLOW_HOME :
|
1 2 3 4 |
pip pandas plotly apache-airflow-providers-postgres |
After this step, we have to modify our docker-compose.yml file a little bit, please change the following lines under the x-airflow-common service:
|
1 2 3 4 5 6 7 |
x-airflow-common: &airflow-common # In order to add custom dependencies or upgrade provider packages you can use your extended image. # Comment the image line, place your Dockerfile in the directory where you placed the docker-compose.yaml # and uncomment the "build" line below, Then run `docker-compose build` to build the images. # image: ${AIRFLOW_IMAGE_NAME:-apache/airflow:2.4.3} build: . |
We simply comment out the image attribute and un-comment the build attribute. This will instruct Airflow to not use its base image but to build an image from our custom Dockerfile. Since we don’t have a Dockerfile yet, we will create a Dockerfile in the same directory with the following content:
|
1 2 3 |
FROM apache/airflow:2.4.2 COPY requirements.txt . RUN pip install -r requirements.txt |
Now we are ready to launch Airflow with:
|
1 |
docker compose up |
This will launch the webserver, scheduler, worker, trigger, Airflow’s Postgres database, and Redis. Also, we will need our own Postgres database where we can store our franchise data, so follow the instructions on the official Postgres webpage on how to install a Postgres database. Alternatively, you can use Docker to set up a Postgres database. You will also need to run the following SQL query to set up the table with toy data after you have created a database:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 |
CREATE TABLE stores ( id BIGSERIAL PRIMARY KEY, manager VARCHAR(30) NOT NULL, city VARCHAR(20) NOT NULL, street VARCHAR(20) NOT NULL, street_number INTEGER NOT NULL, revenue DOUBLE PRECISION NOT NULL, day DATE NOT NULL ); INSERT INTO stores (manager, city, street, street_number, revenue, day) VALUES ('Raphael Rodriguez', 'Aachen', 'Pontstrasse', 4, 4724.57, '2022-11-01'), ('Raphael Rodriguez', 'Aachen', 'Pontstrasse', 4, 2579.35, '2022-11-02'), ('Raphael Rodriguez', 'Aachen', 'Pontstrasse', 4, 5804.42, '2022-11-03'), ('Joe Merkur', 'Koeln', 'Trankgasse', 24, 5608.32, '2022-11-01'), ('Joe Merkur', 'Koeln', 'Trankgasse', 24, 2475.62, '2022-11-02'), ('Joe Merkur', 'Koeln', 'Trankgasse', 24, 12843.76, '2022-11-03'), ('Alice Mueller', 'Koeln', 'Keupstrasse', 124, 6764.56, '2022-11-01'), ('Alice Mueller', 'Koeln', 'Keupstrasse', 124, 4524.35, '2022-11-02'), ('Alice Mueller', 'Koeln', 'Keupstrasse', 124, 4792.64, '2022-11-03'), ('Berno Goeth', 'Bonn', 'Koblenzer Strasse', 47, 1357.35, '2022-11-01'), ('Berno Goeth', 'Bonn', 'Koblenzer Strasse', 47, 2597.25, '2022-11-02'), ('Berno Goeth', 'Bonn', 'Koblenzer Strasse', 47, 899.96, '2022-11-03'); |
Okay, we are good to go!
The Pipeline
Airflow works with the concept of Directed Acyclic Graphs (DAGs) where each task represents a node. The edges are given by the dependencies between the tasks. Our pipeline will consist of 4 tasks. To create our first DAG, run the following command in the root directory of the Airflow workspace:
|
1 2 3 4 |
cd dags mkdir stores && cd stores mkdir ingestion plotting transformation touch pipeline.py |
This will create a directory named stores inside of the dags directory and create 3 subdirectories inside of it: ingestion, plotting, and the transformation directory. Inside the stores‘ directory, we also create a file named pipeline.py which will hold our DAG definition. Your project structure should look similar to figure 2.

DAG Definition
Now, we are ready to author our first pipeline, so let us start with outlining the DAG inside of pipeline.py:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 |
import pendulum from airflow.decorators import dag @dag( dag_id="franchise_analysis_pipeline", description="Analysing franchise data", schedule="0 7 * * *", start_date=pendulum.datetime( year=2022, month=11, day=1, hour=7, tz='Europe/Berlin' ), catchup=False, default_args={ 'retries': 0 }, ) def franchise_analysis_pipeline(): pass franchise_analysis_pipeline() |
There are two ways to write DAGs in Airflow but we will use what Airflow refers to as the TaskFlow API. In my opinion, it increases readability. We import the pendulum library since Airflow does not allow the usage of the DateTime library. This has to do with Airflow’s scheduler. With the dag decorator in place, Airflow will know which function defines our DAG.
Airflow also needs to identify our DAG, so we should give it a unique dag_id. Also, we add a description, telling Airflow that our pipeline should run daily at 7 a.m. and that it should start from the 1st of November 2022 onwards. The timezone is specified to our current timezone location and we also define a catchup and retry parameter. Catchup tells Airflow whether to schedule all the runs which we have missed, e.g. when we create our pipeline on the 3rd of November 2022, then catchup=False tells Airflow to not schedule any runs from the 1st of November 2022 onwards but only from the 3rd November 2022. We can also pass a parameter named retries. When a task fails, Airflow will schedule the task run as often as we specified our retry count. This is useful if e.g. some tasks fail rarely due to timeout issues, then a retry might solve the problem but in our case, this is not needed.
Task: Postgres Ingestion
Next, we should write out our tasks. Therefore we create a file named postgres.py inside of the ingestion directory and write the following skeleton inside of it:
|
1 2 3 4 5 6 |
from airflow.decorators import task from airflow.providers.postgres.hooks.postgres import PostgresHook @task def ingest_franchise_data_from_postgres(target_file: str): pass |
Defining a task is simple, just apply the task decorator on ingest_franchise_data_from_postgres for this purpose. We can also already import PostgresHook since we will need it to establish a connection to our Postgres database. But before we write out the business logic, we have to tell Airflow where it can find our database. Therefore log in to the web UI of Airflow and hover over the field Admin in the top navigation bar. Then click on Connections which should list all of your connections. Since you didn’t create any connections yet, the list should be empty, click on the plus sign and you should see a formula like the one illustrated in figure 3.
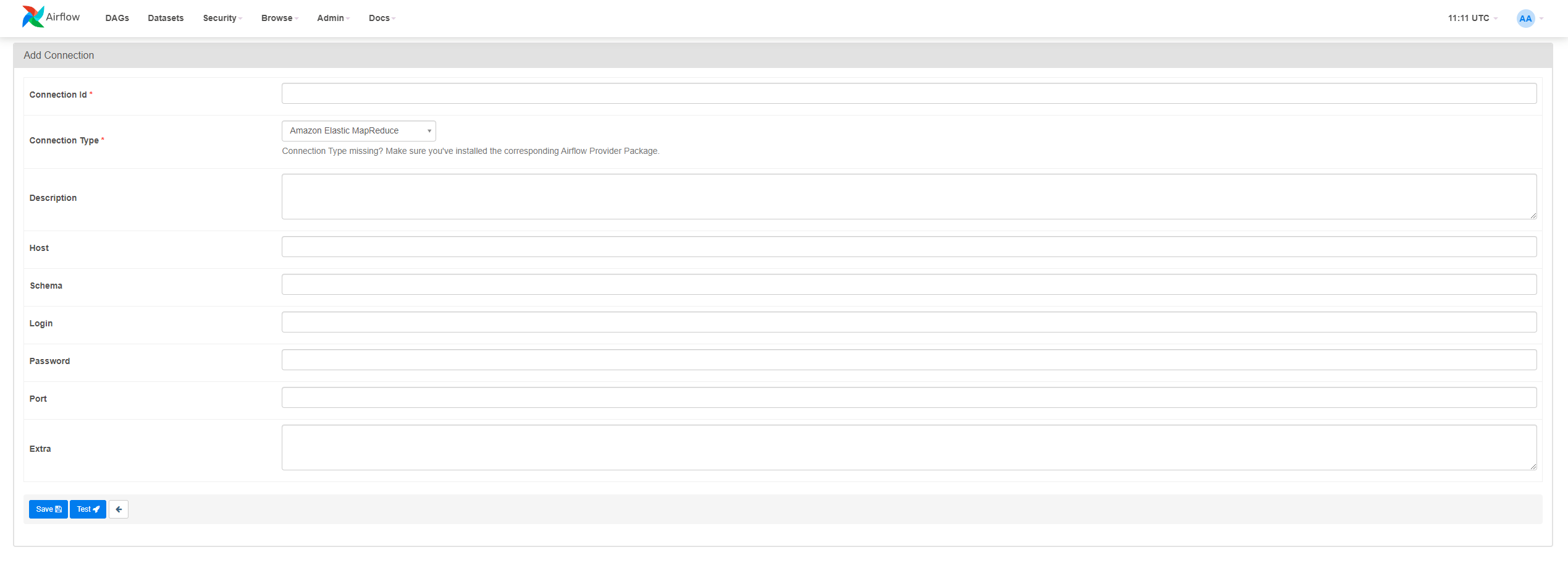
Specify the following parameters:
- Connection Id: „postgres_franchise“. This should specify a unique name for the connection, such that we can unambiguously refer to it in our code
- Connection Type: „Postgres“
- Host: „localhost“, when you deployed your database on your host machine, otherwise choose the appropriate hostname
- Schema: your database name
- Login: the database user
- Password: your database password
- Port: port of your database, the default port in Postgres is 5432.
Afterward, click on Test to check whether your credentials are correct or not. Then click Save and we can continue with our code.
The business logic of the ingestion task is straightforward. It should query the data from the Postgres database, open a CSV file and write the data with an appropriate header in it. With the business logic in place, our task will look like this:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 |
from airflow.decorators import task from airflow.providers.postgres.hooks.postgres import PostgresHook @task def ingest_franchise_data_from_postgres(target_file: str): import os import csv os.makedirs(os.path.dirname(target_file), exist_ok=True) sql_statement = """ select id, manager, city, street, street_number, revenue, day from stores; """ postgres_hook = PostgresHook(postgres_conn_id="postgres_franchise") connection = postgres_hook.get_conn() cursor = connection.cursor() cursor.execute(sql_statement) result = cursor.fetchall() connection.commit() with open(target_file, 'w', newline='') as file: target_csv = csv.writer(file) target_csv.writerow(['id', 'manager', 'city', 'street', 'street_number', 'revenue', 'day']) for row in result: target_csv.writerow(row) return target_file |
The PostgresHook requires an argument: postgres_conn_id. We can pass the connection id which we specified in the connection list to our hook. Afterward, the task executes our SQL statement and fetches the records. These are then written into a CSV file. Note, that we import the required libraries inside of the task (local imports). This is recommended by Airflow since top-level imports affect the loading time of a DAG. You can find out more in the Best Practices section of the official Airflow documentation. Also, we pass an argument target_file to our function which indicates the path where our CSV file should be stored to.
Task: Plotting Revenue vs. Time
It’s time to plot some data. Create a new python file series.py inside of the plotting directory. The task should look like this:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
from airflow.decorators import task @task def plot_revenue_per_day_per_manager(source_file: str, base_dir: str): import os import pandas as pd import plotly.express as px target_file = f"{base_dir}/plots/revenue_per_day_per_manager.html" os.makedirs(os.path.dirname(target_file), exist_ok=True) df = pd.read_csv(source_file) fig = px.line(df, x='day', y='revenue', color='manager', symbol="manager") fig.update_layout( font=dict( size=20 ) ) fig.write_html(target_file) |
Our task will accept the following two arguments:
- source_file: Location of the CSV file with our raw data
- base_dir: Top-level directory where we will store our plots
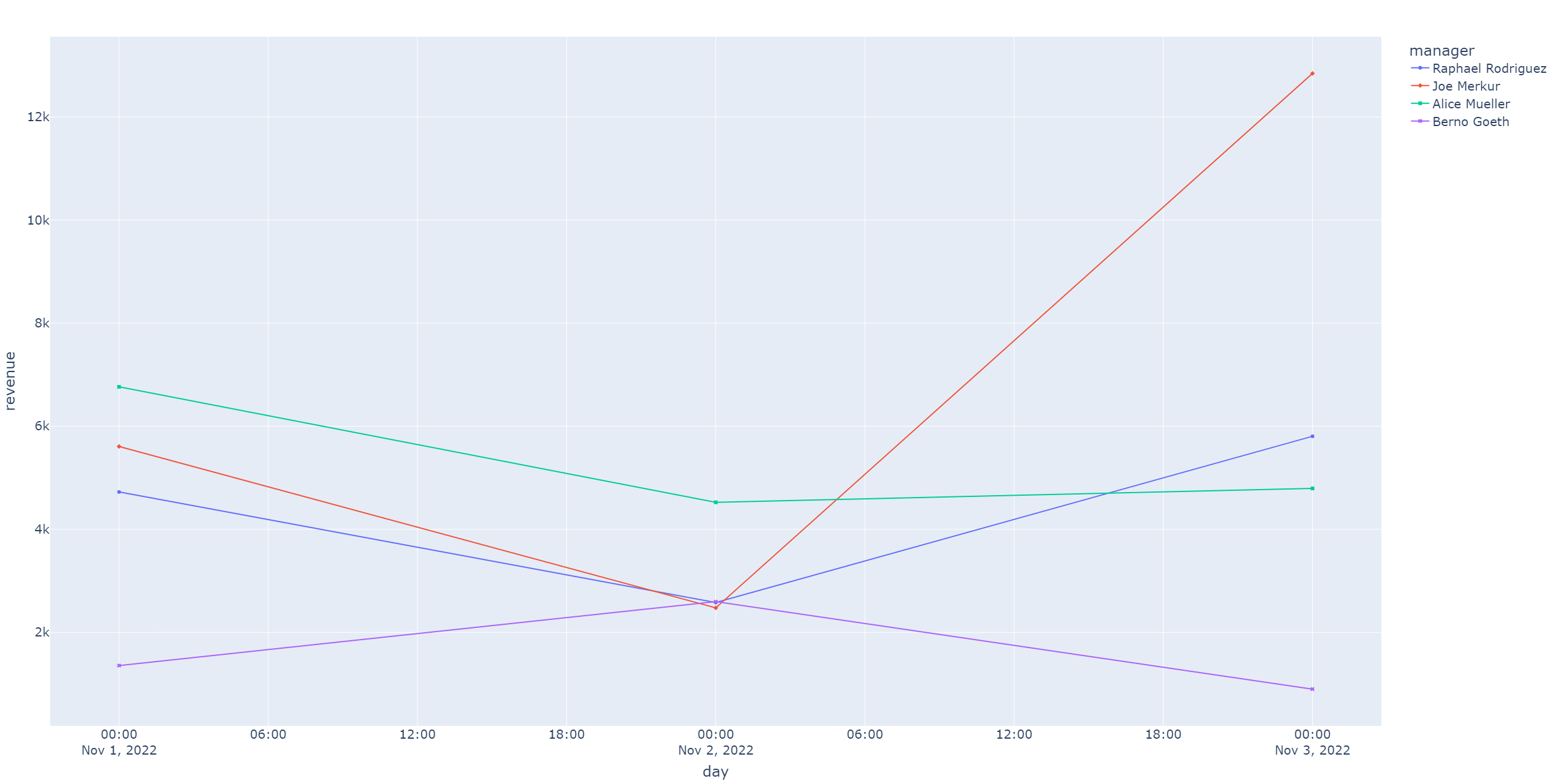
Then again, we import what we need and define our target_file which specifies the storage location of our plot. Note, that we create a .html file because plotly allows us to create interactive plots. The resulting plot is a line plot where we have the date on the x-axis and the revenue on the y-axis. Finished! Let’s aggregate some data next!
Task: Aggregation
We would like to compute the average revenue per franchise/manager. Therefore, create a new Python file aggregation.py inside of the transformation directory. Copy & paste the following code:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 |
from airflow.decorators import task @task def aggregate_avg_revenue_per_manager(source_file: str, base_dir: str): import os import pandas as pd target_file = f"{base_dir}/storage/agg_avg_revenue_manager.json" pickle_file = f"{base_dir}/storage/agg_avg_revenue_manager.pkl" os.makedirs(os.path.dirname(target_file), exist_ok=True) df = pd.read_csv(source_file) result = df.groupby(["manager" "city", "street", "street_number"]).aggregate('mean') result["average_revenue"] = result["revenue"] result = result.drop(columns=["revenue"]).reset_index() result.to_pickle(pickle_file) result.to_json(target_file, orient="records") return pickle_file |
We define two file paths:
- target_file: a json file which holds our aggregated data
- pickle_file: holds our transformed data frame
To aggregate the revenue, we simply have to compute the mean and drop the revenue column. Moreover, we reset the index such that we obtain a clean indexed data frame which we then pickle to our local file system. Our task returns the path to the pickled file such that the next (downstream) task can plot the data.
Task: Plotting Average Revenue vs. Manager
We are left with the last task, plotting the aggregated data. Create a new Python file aggregation.py inside of the plotting directory – the code should look like this:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 |
from airflow.decorators import task @task def plot_avg_revenue_per_manager(pkl_file: str, base_dir: str): import os import pandas as pd import plotly.express as px target_file = f"{base_dir}/plots/agg_avg_revenue_manager.html" os.makedirs(os.path.dirname(target_file), exist_ok=True) df = pd.read_pickle(pkl_file) fig = px.bar(df, x='manager', y='average_revenue', hover_data = ['city', 'street', 'street_number'], labels = {'average_revenue': "Average Revenue by Manager", 'manager_name': "Manager"}) fig.update_layout( font=dict( size=20 ) ) fig.write_html(target_file) |
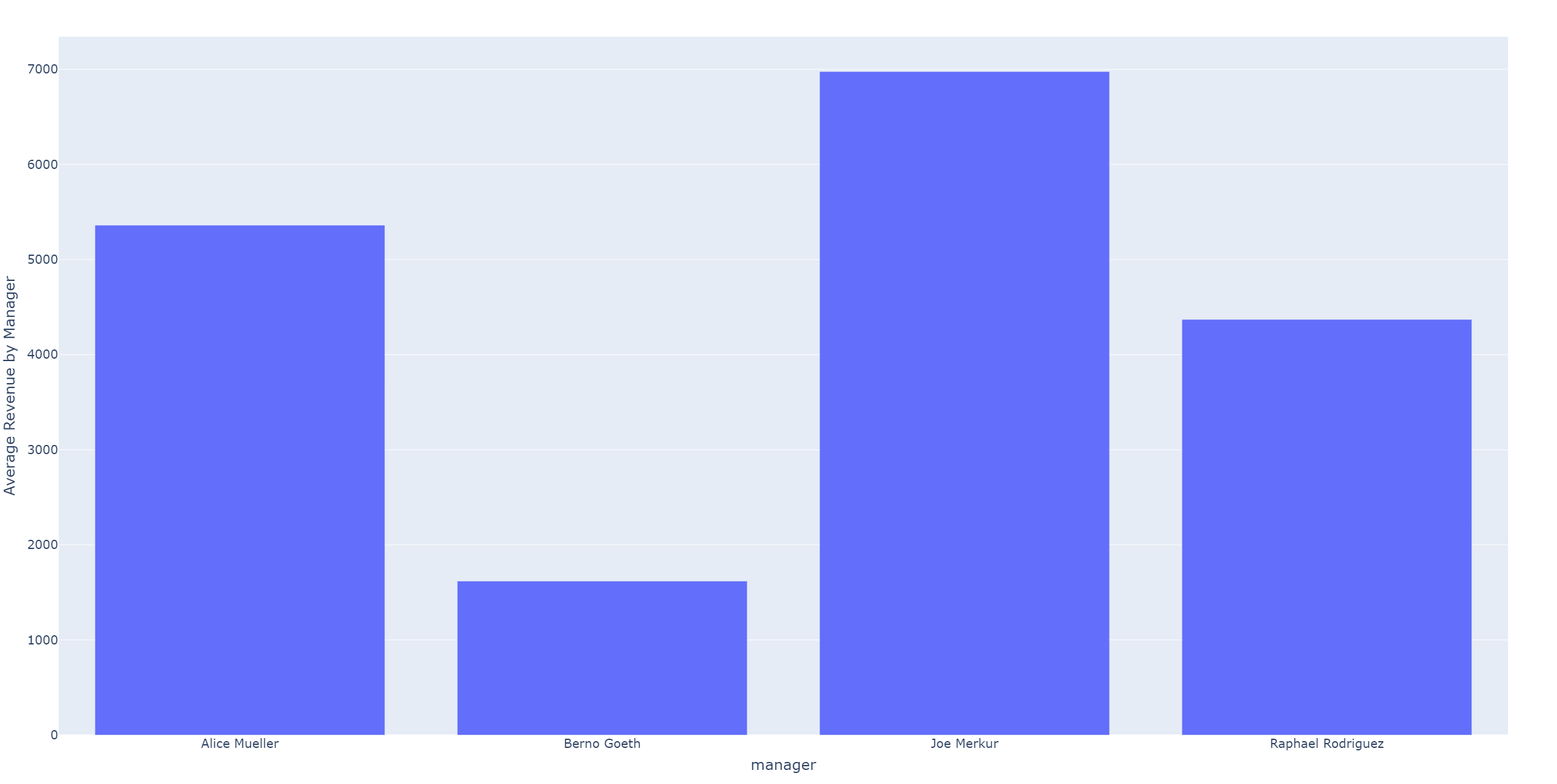
We load the data from the pickled file into a data frame and create a bar plot where we have the manager on the x-axis and the average revenue on the y-axis. On top of that, we enrich our plot with more information appearing on hover like the city and street of the respective franchise. We also adjust the labels and write our HTML file to its target location defined by target_file.
We are almost at the end, we only have to wire all tasks together inside of our DAG definition – where we will specify the dependencies between the tasks.
Finish the DAG Definition
Add the following lines of code in our python file named pipeline.py where our DAG definition resides:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
from stores.ingestion.postgres import ingest_franchise_data_from_postgres from stores.transformation.aggregation import aggregate_avg_revenue_per_manager from stores.plotting.aggregation import plot_avg_revenue_per_manager from stores.plotting.series import plot_revenue_per_day_per_manager @dag( ... ) def franchise_analysis_pipeline(): base_dir = "/opt/airflow/dags/data" target_file = f"{base_dir}/stores.csv" source_file = ingest_franchise_data_from_postgres(target_file) pkl_file = aggregate_avg_revenue_per_manager(source_file, base_dir) plot_revenue_per_day_per_manager(source_file, base_dir) plot_avg_revenue_per_manager(pkl_file, base_dir) franchise_analysis_pipeline() |
I left out all of the other details and only included the relevant lines of code. We pass the return values as input to the appropriate tasks and Airflow is then able to infer the dependencies. Simple as that.
Results
To kick off the pipeline, switch to the web UI and wait for the pipeline to load in the DAG list. If you don’t see your pipeline, you should wait a few minutes until the list refreshes. Typing errors and other errors will be caught by Airflow and will be displayed as an error message. Another way to check whether the pipeline is working, is to execute the following command in a terminal:
|
1 |
python pipeline.py |
If no errors pop up, this means that our pipeline is correctly defined. Anyway, when you click on the pipeline name on the web UI, you will see a different window where you can click on the play button. This will trigger the pipeline and you should see something showing up on your run history. Wait for the pipeline to complete. I invite you to look around, the UI has information and you can discover a lot of details. One recommendation is to click on the Gantt view. If you click on the graph view, you will see the graph structure of our data pipeline as depicted in figure 4 and see that all tasks are marked as successful which can be seen by the green outline.
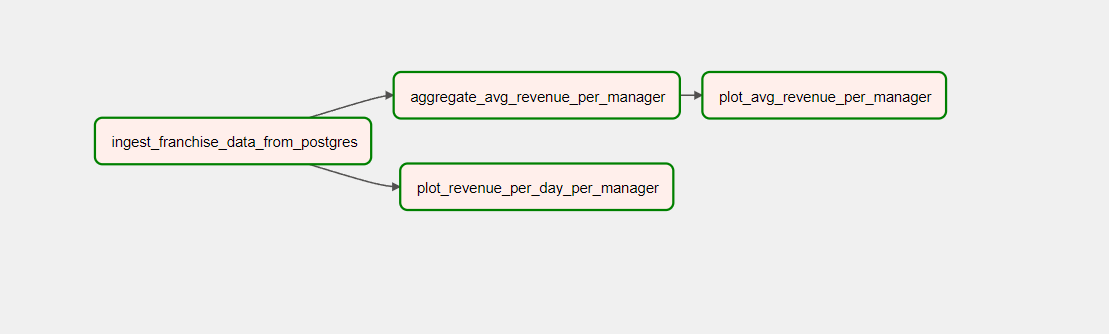
By the way, figure 5 and 6 show the plots which we generated with our pipeline. As you can see, Airflow is pretty powerful and that is why Airflow has become so dominant in our data-driven world. But Airflow is not perfect, in Part 2 of this blog article, you can read about Airflow’s weaknesses and how its competitors perform in comparison.
Final Remarks
Note, that this pipeline implementation in Airflow does not represent a production grade implementation. When you have lots of data to process, then you should refrain from using simple tasks and use so called Airflow Operators. Please handle your processing workload in instances like a Spark cluster or use the KubernetesPodOperator to process your workload on a Kubernetes cluster. This has the following advantage: Airflow will then only handle orchestration and will not deal with any workload handling. The business logic is outsourced to e.g. Kubernetes and you can far more easily scale Pods on Kubernetes to satisfy your resource requirements than in Airflow. But since this is an advanced topic, I wanted to keep it simple for this blog article such that anyone can have an entry point into the world of Apache Airflow since not everyone knows how to setup a Kubernetes cluster or a Spark cluster. But at a later point you will want to definitely check out the KubernetesPodOperator and the SparkSubmitOperator.
Bonus
Of course, this article has limited space and your reading time is precious, such that I cannot mention all the features that Airflow has to offer. But I want to mention a few more features of Airflow here which are pretty useful for data engineers.
Replaying Tasks
Sometimes one of your tasks may fail due to some unfortunate event, e.g. your database was not available because the database server crashed. If you want to re-run your pipeline, you should select your failed task and then click on „Clear“. When you click on your failed task, you should see a similar UI view as illustrated by figure 7.
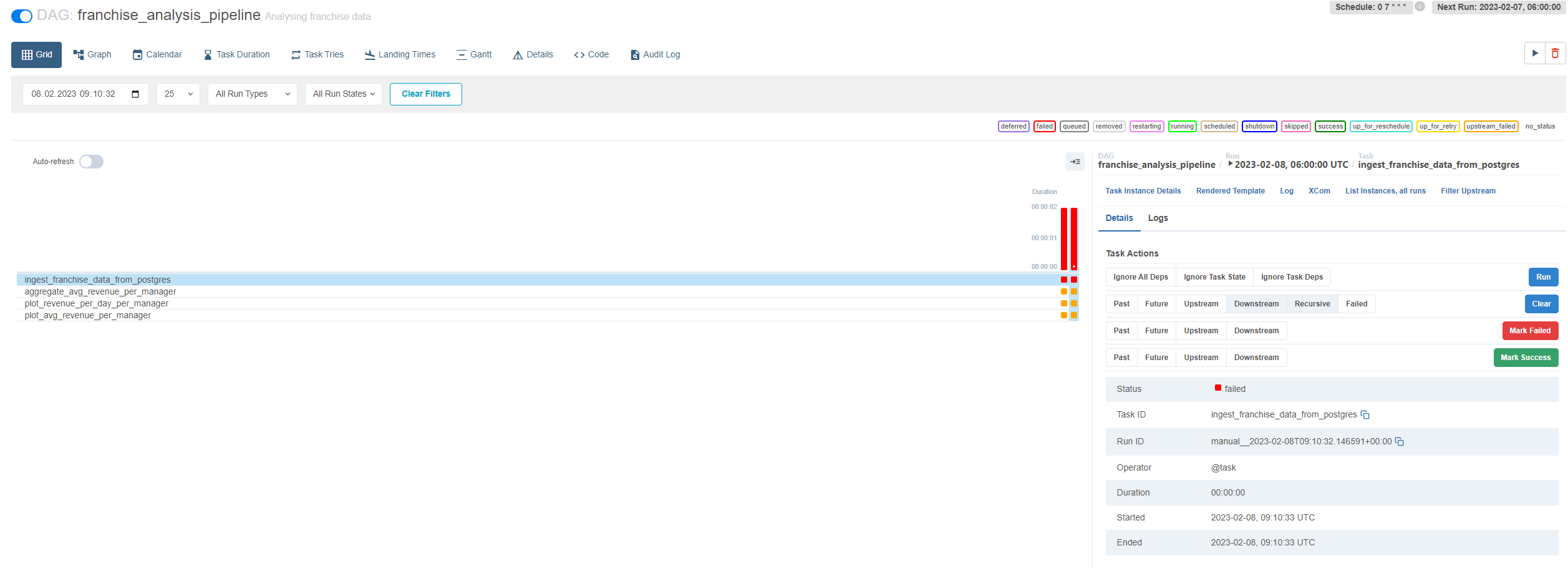
When you click on „Clear“, a confirmation message will pop up that will show you what kind of changes are made when you continue. Note, that you have several options here, I clicked on Downstream and Recursive which will clear any tasks that are downstream from the selected task and any tasks that are cross-dependent on our selected task, e.g. having other DAGs that rely on that task.
Looping over tasks multiple times
Sometimes you might want to run your tasks multiple times over some set of variables. The following code snippet should demonstrate to you how you can accomplish this:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 |
@task def first_task(variable): return variable @task def second_task(variable): return variable**2 @dag( dag_id="for_loop_dag", description="Showing how for loop works for tasks", ... ) def example_dag(): variables = [1, 2, 3] for variable in variables: intermediary_result = first_task(variable) result = second_task(intermediary_result) example_dag() |
The unnecessary details are left out in this code snippet and only the relevant part of the code is shown. Essentially, we are looping over 3 values and computing the square of these values. Thus, the tasks first_task and second_task are running 3 times in total.
Slack Integration
Of course, we can also integrate Airflow with Slack, e.g. you may want to send alerts to Slack when something happened on your Airflow instance. This can be accomplished by using another provider package named apache-airflow-providers-slack which comes with a SlackWebhookHook. This hook allows you to send messages to your Slack channels. If you want to find out more about this integration, have a look at the following link: Slack Integration.


