
Nachdem wir uns in den bisherigen Artikeln unserer Blogpost-Serie zur Snowflake Data Cloud bereits Snowpipe und Streams & Tasks angesehen haben, wollen wir uns nun mit Dynamic Tables eine weitere Möglichkeit anschauen, Prozesse zur Datenverarbeitung zu implementieren. Mit den Dynamic Tables bietet Snowflake eine einfache und flexible Möglichkeit, komplexe SQL-basierte Transformationen zu erstellen.
Was macht Dynamic Tables besonders?
Entgegen einer normalen Tabelle, die mit einem CREATE-Statement erstellt und DML-Befehlen inhaltlich definiert wird, werden Dynamic Tables wie Views als Ergebnis einer SQL-Abfrage definiert. Zusätzlich müssen lediglich das zu verwendende Warehouse und das sogenannte Target Lag angegeben werden. Letzteres definiert die Zeitspanne, die zwischen Aktualisierungsläufen verstreichen darf, und legt somit die maximale Zeit fest, die eine dynamische Tabelle hinter ihren zugrundeliegenden Basistabellen zurückbleiben darf.
Die resultierende Tabelle muss also weder explizit erstellt, noch müssen manuelle Datenprozesse implementiert werden, die Datensätze hinzufügen, ändern oder löschen. Diese Eigenschaft macht die Erstellung von Daten-Pipelines unter Verwendung dynamischer Tabellen besonders einfach. In den SQL-basierten Definitionen können auch bereits bestehende Dynamic Tables verwendet werden. Hierdurch lassen sich mit vergleichsweise geringem Aufwand umfangreiche Verarbeitungsstrecken erstellen, in denen die einzelnen Schritte aufeinander aufbauen können (beispielsweise das Laden von Dimensionen vor den Fakten eines Data Warehouse).
Die regelmäßige Aktualisierung der Daten unter Wahrung dieser Abhängigkeiten übernimmt Snowflake: Ein automatisierter Prozess überprüft anhand des Target Lag, wann die Tabelle aktualisiert werden muss. Neue oder geänderte Datensätze werden nach Möglichkeit inkrementell geladen, vorausgesetzt der automatisierte Prozess kann anhand der der Tabelle zugrundeliegenden Abfrage ein Inkrement bestimmen (abhängig von den in der Abfrage verwendeten SQL-Ausdrücken).
Diese Eigenschaften ermöglichen nicht nur Einsparungen von Zeit und Kosten. Da Entwicklungsteams weniger Ressourcen für manuelle Datenprozesse, Abhängigkeiten und Scheduling benötigen, bleibt mehr Raum für die Entwicklung zusätzlicher Features und anderer wichtiger Aspekte.
Verwendung
Wir demonstrieren die Verwendung von dynamischen Tabellen, indem wir 4 davon erstellen. Von diesen stehen jeweils 2 in Abhängigkeit zueinander. Während eine Abhängigkeit zwischen 2 der erstellten Tabellen mit eigenem Target Lag besteht, veranschaulichen die anderen beiden die Verwendung der Downstream-Abhängigkeit:
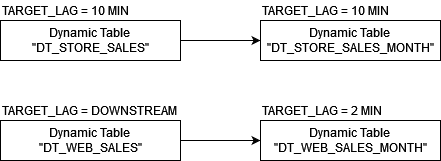
Damit dieser Aufbau besser nachvollziehbar ist und problemlos nachgebaut werden kann, verwenden wir den Snowflake Beispieldatensatz TPC-DS (siehe Links).
Konkret führen wir die folgenden Schritte aus:
- Erstellen der 4 Tabellen
- Abfragen der Metainformationen
- Monitoring der Ausführung
Szenario 1: Tabellen mit eigenem Target Lag
Auf Basis der Tabelle STORE_SALES definieren wir 2 Tabellen, die die Daten in unterschiedlichen Aggregationsstufen zur Verfügung stellen.
Die erste Tabelle verknüpft die Ladenverkäufe mit Datum, Produkt und Filialnamen:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 |
CREATE OR REPLACE DYNAMIC TABLE DT_STORE_SALES TARGET_LAG = '10 MINUTES' WAREHOUSE = MY_DEMO_WH AS SELECT DATE(D.D_DATE) AS D_DATE, CONCAT(T.T_HOUR, ':', LPAD(T.T_MINUTE, 2, 0), ':', LPAD(T.T_SECOND, 2, 0)) AS D_TIME, SS.SS_QUANTITY, SS.SS_WHOLESALE_COST, SS.SS_LIST_PRICE, SS.SS_SALES_PRICE, I.I_CURRENT_PRICE, I.I_WHOLESALE_COST, I.I_PRODUCT_NAME, S.S_STORE_NAME, S.S_CITY, S.S_STATE FROM STORE_SALES SS JOIN DATE_DIM D ON D.D_DATE_SK = SS.SS_SOLD_DATE_SK JOIN TIME_DIM T ON T.T_TIME_SK = SS.SS_SOLD_TIME_SK JOIN ITEM I ON I.I_ITEM_SK = SS.SS_ITEM_SK JOIN STORE S ON S.S_STORE_SK = SS.SS_STORE_SK; |
Die zweite Tabelle soll diese Informationen aggregieren und die Gesamtmenge sowie die durchschnittlichen Großhändler-, Listen- und Verkaufspreise pro Monat und Produkt angeben:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
CREATE OR REPLACE DYNAMIC TABLE DT_STORE_SALES_MONTH TARGET_LAG = '10 MINUTES' WAREHOUSE = MY_DEMO_WH AS SELECT YEAR(D_DATE) AS D_YEAR, MONTH(D_DATE) AS D_MONTH, I_PRODUCT_NAME, SUM(SS_QUANTITY) AS SS_QUANTITY, AVG(SS_WHOLESALE_COST) AS AVG_SS_WHOLESALE_COST, AVG(SS_LIST_PRICE) AS AVG_SS_LIST_PRICE, AVG(SS_SALES_PRICE) AS AVG_SS_SALES_PRICE FROM DT_STORE_SALES GROUP BY YEAR(D_DATE), MONTH(D_DATE), I_PRODUCT_NAME; |
Beide Tabellen wurden mit einem Target Lag von 10 Minuten erstellt. Durch diese Konfiguration ist also sichergestellt, dass die Daten in beiden Tabellen maximal 10 Minuten hinter den zugrundeliegenden Basistabellen zurückbleiben, ehe sie automatisiert durch Snowflake auf den Stand der Quelldaten gebracht werden.
Wenn wir uns die dynamischen Tabellen in unserem Schema anzeigen lassen, können wir anhand des SCHEDULING_STATE erkennen, dass beide aktiv sind:
|
1 |
SHOW DYNAMIC TABLES IN SCHEMA TPC_DS.MY_SCHEMA; |

Wir warten ein paar Minuten ab, und sehen uns dann die Historie der Aktualisierungen an:
|
1 2 3 |
SELECT NAME, STATE, STATE_CODE, STATE_MESSAGE, DATA_TIMESTAMP, REFRESH_START_TIME, REFRESH_END_TIME FROM TABLE (INFORMATION_SCHEMA.DYNAMIC_TABLE_REFRESH_HISTORY(NAME_PREFIX => 'TPC_DS.MY_SCHEMA.')) ORDER BY data_timestamp DESC; |

Anhand der Start- und Endzeitpunkte erkennt man, dass DT_STORE_SALES_MONTH immer dann aktualisiert wird, wenn DT_STORE_SALES erfolgreich aktualisiert wurde. Snowflake erkennt also die Abhängigkeit zwischen den beiden Tabellen und legt die Aktualisierungszeitpunkte zusammen (auch erkennbar anhand des DATA_TIMESTAMP). Diese Optimierung seitens Snowflake würde auch dann erfolgen, wenn die beiden Tabellen ein unterschiedliches Target Lag hätten.
Szenario 2: Tabellen mit Downstream-Abhängigkeit
Alternativ zu einer Zeitangabe kann das Target Lag auch als Downstream konfiguriert werden. Diese Tabellen werden nur dann aktualisiert, wenn Abhängigkeiten zu anderen dynamischen Tabellen dies erforderlich machen.
Auf Basis der Tabelle WEB_SALES definieren wir 2 weitere Tabellen.
Die erste Tabelle verknüpft die Onlineverkäufe mit Datum, Produkt und Versandart:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 |
CREATE OR REPLACE DYNAMIC TABLE DT_WEB_SALES TARGET_LAG = 'DOWNSTREAM' WAREHOUSE = MY_DEMO_WH AS SELECT DATE(D.D_DATE) AS D_DATE, CONCAT(T.T_HOUR, ':', LPAD(T.T_MINUTE, 2, 0), ':', LPAD(T.T_SECOND, 2, 0)) AS D_TIME, WS.WS_QUANTITY, WS.WS_WHOLESALE_COST, WS.WS_LIST_PRICE, WS.WS_SALES_PRICE, I.I_PRODUCT_NAME, SM.SM_TYPE, SM.SM_CODE FROM WEB_SALES WS JOIN DATE_DIM D ON D.D_DATE_SK = WS.WS_SOLD_DATE_SK JOIN TIME_DIM T ON T.T_TIME_SK = WS.WS_SOLD_TIME_SK JOIN ITEM I ON I.I_ITEM_SK = WS.WS_ITEM_SK JOIN SHIP_MODE SM ON SM.SM_SHIP_MODE_SK = WS.WS_SHIP_MODE_SK; |
Die zweite Tabelle soll diese Informationen wieder aggregieren und die Gesamtmenge sowie die durchschnittlichen Großhändler-, Listen- und Verkaufspreise pro Monat und Produkt angeben:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
CREATE OR REPLACE DYNAMIC TABLE DT_WEB_SALES_MONTH TARGET_LAG = '2 MINUTES' WAREHOUSE = MY_DEMO_WH AS SELECT YEAR(D_DATE) AS D_YEAR, MONTH(D_DATE) AS D_MONTH, I_PRODUCT_NAME, SUM(WS_QUANTITY) AS WS_QUANTITY, AVG(WS_WHOLESALE_COST) AS AVG_WS_WHOLESALE_COST, AVG(WS_LIST_PRICE) AS AVG_WS_LIST_PRICE, AVG(WS_SALES_PRICE) AS AVG_WS_SALES_PRICE FROM DT_WEB_SALES GROUP BY YEAR(D_DATE), MONTH(D_DATE), I_PRODUCT_NAME; |
Wir warten wieder ein paar Minuten ab, und sehen uns erneut die Historie der Aktualisierungen an:
|
1 2 3 |
SELECT NAME, STATE, STATE_CODE, STATE_MESSAGE, DATA_TIMESTAMP, REFRESH_START_TIME, REFRESH_END_TIME FROM TABLE (INFORMATION_SCHEMA.DYNAMIC_TABLE_REFRESH_HISTORY(NAME_PREFIX => 'TPC_DS.MY_SCHEMA.')) ORDER BY data_timestamp DESC; |

Wie in der obigen SQL-Definition festgelegt, wird die Tabelle DT_WEB_SALES_MONTH in Abständen von ca. 2 Minuten aktualisiert. Da hierfür die Tabelle DT_WEB_SALES verwendet wird, läuft deren Aktualisierung unmittelbar vorher.
Wichtig: Um keine unnötigen Kosten zu verursachen, sollte abschließend die automatische Ausführung der Aktualisierungen für alle Tabellen ausgesetzt werden:
|
1 2 3 4 |
ALTER DYNAMIC TABLE DT_STORE_SALES SUSPEND; ALTER DYNAMIC TABLE DT_STORE_SALES_MONTH SUSPEND; ALTER DYNAMIC TABLE DT_WEB_SALES SUSPEND; ALTER DYNAMIC TABLE DT_WEB_SALES_MONTH SUSPEND; |
Error Handling
Wenn das der dynamischen Tabelle zugrundeliegende Statement fehlschlägt, wird dies in der Historie der Aktualisierungen entsprechend markiert:
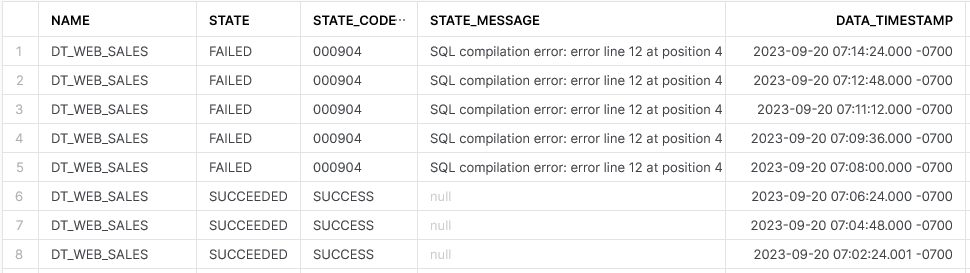
Geschieht es 5 mal in Folge, wird die regelmäßige Aktualisierung der Daten für diese Tabelle automatisch deaktiviert:

Dynamische Tabellen die aufgrund einer Abhängigkeit von dieser Deaktivierung betroffen sind, werden ebenfalls automatisch deaktiviert.
Eine Aktualisierung der Daten würde dann erst wieder erfolgen, wenn wir den Fehler beheben und die Aktualisierungen reaktivieren.
Benachrichtigungen über fehlgeschlagene Aktualisierungen und deaktivierte dynamische Tabellen ließen sich beispielsweise mit der integrierten Snowflake-Prozedur SYSTEM$SEND_EMAIL() versenden.
Betrachtung der Kosten
Die Kosten einer dynamischen Tabelle setzen sich aus 3 Komponenten zusammen:
- Storage umfasst den für eine Tabelle benötigten Speicherplatz pro TB.
- Cloud Services Compute wird verwendet, um zu überprüfen, ob die zugrundeliegenden Daten einer Tabelle sich geändert haben. Nur wenn dies der Fall ist, wird eine Aktualisierung angestoßen. Diese Kosten werden nur in Rechnung gestellt, wenn sie über 10 % der gesamten Warehouse-Kosten eines Tages betragen.
- Virtual Warehouse Compute wird verwendet, um im Rahmen von Aktualisierungen die Quelldaten zu lesen, sie zu transformieren und das Resultat in die Zieltabelle zu schreiben.
Dynamic Tables vs. Streams and Tasks
Im vergangenen zweiten Teil unserer Blogpost-Serie zur Snowflake Data Cloud haben wir uns Streams und Tasks angesehen. Da sich beide Artikel mit Wegen beschäftigen, Daten in Snowflake zu transformieren, möchten wir noch kurz auf Gemeinsamkeiten und Unterschiede dieser beiden Möglichkeiten eingehen:
| Dynamic Tables | Streams und Tasks | |
|---|---|---|
| Ansatz | Deklarativ: Zieltabelle wird als Ergebnis einer Abfrage definiert | Imperativ: Zieltabelle muss explizit erstellt und mit DML-Befehlen bewirtschaftet werden |
| Umfang | Nur SQL-basierte Transformationen | Tasks können neben SQL-Abfragen auch Prozeduren sowie benutzerdefinierte und externe Funktionen verwenden |
| Scheduling | Automatische Aktualisierung unter Berücksichtigung der Abhängigkeiten, Aktualität der Daten nur innerhalb des Target Lag | Task-basierte Aktualisierung muss manuell eingeplant werden, Berücksichtigen der Abhängigkeiten ist Teil der Entwicklungsarbeit, Aktualität der Daten kann dabei genauer definiert werden |
| Inkrement | Der automatische Aktualisierungsprozess lädt neue oder geänderte Datensätze nach Möglichkeit inkrementell | Task-basierte inkrementelle Verarbeitung auf Basis von Streams muss explizit umgesetzt werden |
Ob nun dynamische Tabellen oder Streams und Tasks das geeignetere Werkzeug zur Datentransformation sind, kommt also in der Praxis auf die konkreten Anforderungen an die Verarbeitungsstrecke an.
Fazit
Mit Dynamic Tables bietet Snowflake ein einfaches und sehr vielseitig einsetzbares Werkzeug, mit welchem unterschiedlichste Transformationen auf Basis komplexer SQL-Abfragen erstellt werden können. Auch größere Datenpipelines lassen sich mit geringem Aufwand erstellen, da die hinter den Tabellen stehenden automatisierten Aktualisierungsprozesse das Scheduling, die Einhaltung von Abhängigkeiten sowie das inkrementelle Laden der Daten übernehmen.
Für diese Reduzierung in der Entwicklungskomplexität nimmt man allerdings einige Einschränkungen in Kauf. So gibt man beispielsweise die vollständige Kontrolle über den exakten Zeitpunkt der Datenaktualisierung ab. Auch externe Tabellen, Clustering und Search Optimization sowie externe und nicht deterministische Funktionen werden aktuell noch nicht von Dynamic Tables unterstützt.
Links
https://docs.snowflake.com/en/user-guide/dynamic-tables-about
https://docs.snowflake.com/en/user-guide/sample-data-tpcds
https://docs.snowflake.com/en/user-guide/email-stored-procedures


