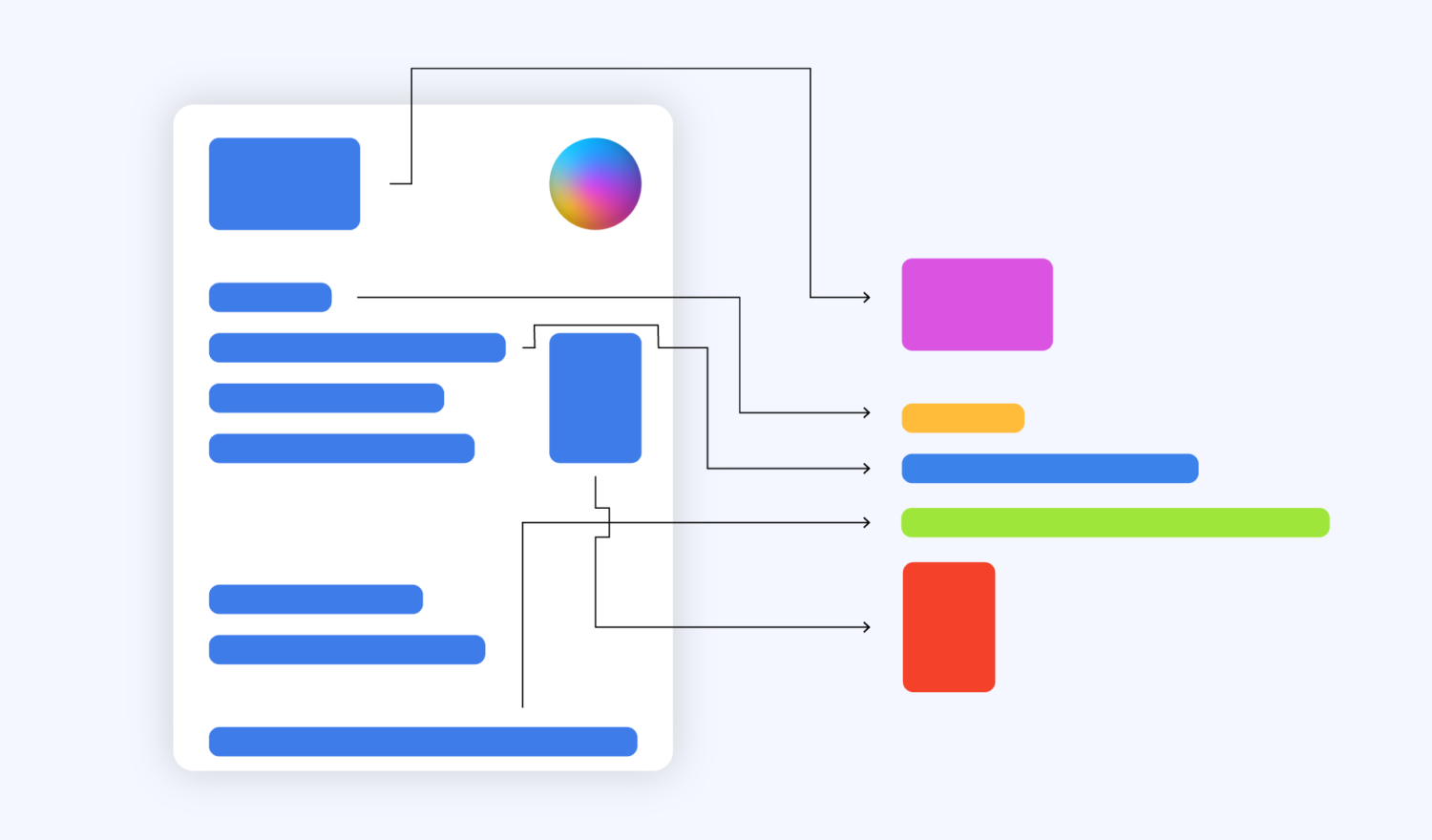
The past years and even decades have seen rapid increases in automation and digitalization, with “paperless office“ being only one of the terms coined in recent years. Some areas, however, appear to be less affected by this trend: documents. While documents are available via native/scanned PDF files or images, their semi-structured format often needs additional processing, for example, OCR. The task of extracting structured information from semi-structured documents is often referred to as Intelligent Document Processing (IDP) or DocumentAI. In the following sections, current trends, developments, and challenges in implementing DocumentAI systems are explored.
An important decision is: make or buy. While both Microsoft Azure and Google Cloud offer a complete package with model, model training and labeling, vendor lock-in, and confidential/privacy data requirements may limit the use of the respective service. Additionally, it may prove valuable to develop the knowledge and capabilities in-house. As is often the case, no perfect system exists (yet). The field is still highly active and changing rapidly, with a new model getting published nearly every month. To answer the question of “make or buy“ it is helpful to make a detour to what is possible and what is available off-the-shelf.
Problem: The ghost from the past
Even if the document was a native PDF with a text layer and without any need for OCR, the problem persists: PDFs are a graphical format that only allows placing a letter, an image or a vector graphic on the canvas without any built-in capability to represent words, paragraphs, tables: This is why “selecting“ text in a PDF document sometimes does not follow the apparent visual structure of the document. In fact, this feature is only possible because the PDF reading app uses a heuristic to group letters to words, words to paragraphs, and so on. It becomes even worse when multi-pane or other complex layouts are involved. Often, documents and their underlying formats prioritize human readability and are easy to print – but they lack a well-formed machine-readable structure.
This is not surprising, as the main driver for the document format was, as the name Portable Document Format (PDF) already suggests, the need for a format that renders a document exactly the same on every device regardless of the underlying operating system and configuration.
Easily extracting information from the document was not on the agenda, thus even a simple task such as the extraction of the “total sum“ field from a scanned and OCRed receipt may involve more than a simple lookup. For some cases, custom document-specific extraction rules can solve the problem – but this kind of approach does not scale and, therefore, quickly becomes unfeasible.
The solution
As we have seen, there is more to a “digital“ document than meets the eye – literally.
So how to address the problem? Interestingly, the “mundane“ field of DocumentAI/Intelligent Document Processing (IDP) leveraged several technologies from other disciplines and combined them – a first hint that extraction sometimes is surprisingly difficult.
Traditional approaches
Traditional approaches often work with handcrafted features, mainly using the visual location of a word or a letter (bounding box) on the canvas as well as the textual data itself. With feature engineering, both the bounding boxes and the textual information can be refined and integrated further: The “total sum“ field, for example, is likely to consist mostly of numbers that may be placed close to the bottom of a page.
While these approaches are relatively easy to implement via Decision Trees, and a combination of TF-IDF matrices and custom features, lots of tinkering, trial and error, and feature engineering are involved. Above all, however, models trained on one dataset tend to not generalize well to slightly different ones. Also, long-range dependencies between words are hard to model with Decision Trees (a solution would be to use RNNs or Attention Based Models such as the Transformer), resulting in a simplified representation of the meaning of text. On the upside, simpler models are easier to understand, diagnose, and interpret and faster to train. You do not need an expensive sports car to go grocery shopping.
Modern approaches
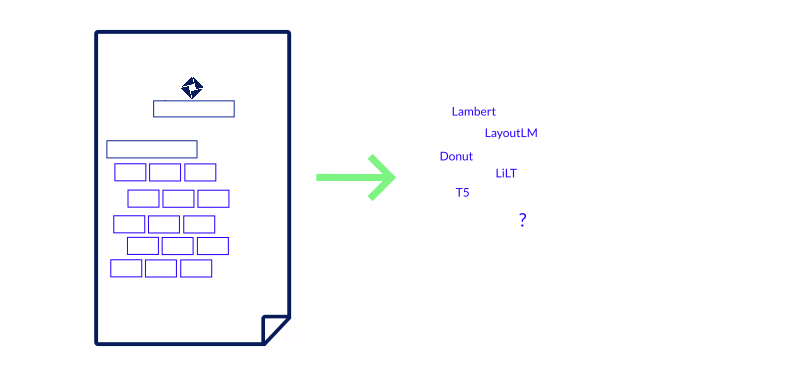
But sometimes a regular car just is not enough: With LAMBERT, Garncarek et al. introduced a layout-aware encoder-only model in 2021 based on RoBERTa with added bounding box coordinates that result in a significantly better performance than RoBERTa alone.
One year earlier, Xu et al. from Microsoft Asia Research published LayoutLM, which uses the BERT architecture and bound box coordinates but also adds image embeddings obtained from a Faster-R-CNN, adding another modality, the image of a page, to the toolchain. LayoutLM is currently available in its 3rd iteration, which swaps the Faster-R-CNN backbone with a linear embedding for better and easier integration with the remaining BERT architecture. As of writing this, LayoutLMv3 can be regarded as the state-of-the-art model for several tasks. That being said, only the first version was available under a permissive license, rendering the successors unfit for commercial applications.
A promising alternative is LiLT by Wang et al. published in 2022, which is available from the huggingface hub under a permissive license that allows commercial use (MIT). LiLT again drops the image modality and uses only bounding box layout information, coined “layout flow“, together with the RoBERTa “text flow“. What makes this model particularly interesting is that both flows are loosely coupled, allowing to take the layout flow from a LiLT model on English receipts and fine-tune it with a corresponding off-the-shelf pre-trained RoBERTa German model serving as the text flow. This ability to move quickly from one language to another is an essential asset for many business applications.
Recent developments
While the models discussed in this section are much larger and more complex than traditional approaches, they also tend to generalize much better to related data and do not need to be custom fitted to the data set using feature engineering. In contrast to the aforementioned models which rely on provided text information that was either gathered via OCR (for scans/photos) or an available native text layer in the PDF, other solutions such as Donut published by Kim et al. in 2022 are “OCR-free“, which is particularly interesting for a custom task such as handwriting recognition.
Another promising direction is the “re-discovery“ of the “full“ transformer with encoder and decoder blocks, such as the T5 model published in 2020 by Raffel et al., that does not need any bounding box annotations for training. Therefore, it is less costly and easier to train such a model, since human labeling of bounding boxes on the document structure is no longer needed. At training time, the model only relies on the text information and the key-value pairs that should be extracted. A database export would suffice. Powalski et al. from Applica (now part of Snowflake) enhanced the T5 model further and introduced the TILT model by making it multi-modal by adding an image and bounding boxes. A process they call “Going Full-TILT Boogie“.
And with the growing capabilities of Document Question Answering, no pre-configured learned structure might be needed at all. Simply ask questions about the document in natural language: “What is the total sum of all the items?“. But for now, this only works reliably with non-complex documents.
ChatGPT
Another quite promising contender is – of course – ChatGPT and similar models. While they were not specifically trained as DocumentAI models, they have astounding capabilities, especially in the so-called zero-shot area: ChaptGPT, for example, is surprisingly good at extracting information from text even if it has never seen text data from the niche domain of concern. This is all thanks to the remarkable generalization capabilities these models possess.
What ChatGPT lacks, however, is the multi-modality: For now, it only accepts and processes text input without layout information. The latter is, as we have seen, crucial for complex documents with multi-level tables. Furthermore, few have both the resources and willingness to use such a complex and closed-source model within the organization, where privacy, compliance, and economic viability are major concerns. That being said, it is worthwhile to test-drive ChatGPT for DocumentAI tasks and less complex use cases.
🤗 and the power of collaboration
Nearly every recent contribution is available from the huggingface hub, making it much easier for the Data Scientist / Machine Learning Engineer to get started and move to another model. See the huggingface blog post on DocumentAI for further information on the relevant benchmark datasets, metrics, license issues, and related disciplines. To keep up with the latest innovations and model releases, Paperswithcode provides leaderboards on popular benchmark datasets, while Niels Rogge’s Tranformer Tutorials and Phillip Schmid’s blog are valuable resources for a hands-on guide
Challenges
Even though many models and benchmarks exist, real-world data tends to be different and more challenging to solve. Notable exceptions such as Applica’s Kleister-NDA or IBM’s DocLayNet remain rare, and oftentimes simple tasks such as receipt understanding are far less challenging than complex documents with layout shifts and tables. For companies, it can therefore be difficult to assess whether their extraction tasks can be automated with the currently available models. Starting with a pilot means considerable time-invest – especially labeling the documents can be costly, even if open source solutions such as Label Studio are leveraged.
What works well in a paper is not guaranteed to transfer to the “real world“. Even having a perfect model only means one part of the toolchain is ready.
How to get started with DocumentAI
Arguably more important than chasing benchmark scores and using the absolute “best-of-the-best“ approach is to establish data literacy within the company and get an overview of existing in-house data and the challenges faced with processing and automation. Keeping an overview of a challenging and fast-paced environment is difficult and requires technical expertise as well as practical experience and intuition. Most of the mentioned models are publicly available. Still, their integration with existing systems and processes, a robust (re-)training and inference pipeline, and the toolchain for pre-processing and labeling are vital parts as well.
To get a firm understanding of the opportunities of the technology and its use within your company, the following questions may guide you through the decision-making process: Can your company benefit from DocumentAI? How could it be integrated with existing systems? How to transform and ingest document data at scale? Is SaaS (software as a service) from big software vendors an option, or is a custom solution a better fit for the requirements?
Off-the-shelf SaaS solutions have the advantage of a quick setup, low technical barriers, and the flexibility of an on-premise installation. But they are not very customizable, and in a rapidly changing environment settling for one provider can be problematic – especially if many capable models are freely available. Thus, for documents with complex tables or handwriting, a custom training process might be necessary.
A follow-up blog post will explore the tools needed to implement DocumentAI at a company. So stay tuned for more stories about sports cars and a hands-on guide on how to drive Intelligent Document Processing home.


