In modern cloud-native architectures, service meshes find broad adoption. Service meshes add a separate layer to microservice clusters which enhances the resilience. The service mesh is formed by sidecar proxies that handle networking, observability, and security-related tasks. However, the additional proxies and their network traffic service meshes add overhead to the hosts. With extended Berkley Packet Filter (eBPF), the Linux kernel community added a new extension technology to the kernel, enabling an event-based execution of applications in the kernel context without needing kernel recompiles or restarts. This thesis analyzes if eBPF can reduce the increased resource usage of service meshes and focuses thereby on the networking features. Next to the communication between a service and its sidecar, this includes the movement of service mesh features to the kernel previously located in the sidecars. First, eBPF’s possibilities are examined and then evaluated in a practical comparison in load tests.
The analysis showed that it is possible to skip the Linux networking stack when using eBPF to communicate between a microservice and its sidecar. Additionally, service mesh networking features up to Open Systems Interconnection (OSI) layer five can be moved from the sidecar proxy to the kernel. The load tests were performed using an Istio service mesh that was extended to use eBPF by Merbridge. The results of the tests did show a high variance and inconsistent results across several iterations, which leads to the result that Merbridge is not improving an Istio-based service mesh. Future work should further investigate the reasons for this lack of performance improvement.
Introduction
When applications moved from monolithic approaches to microservice architectures, a standardized communication layer was formed by integrating a communication library into each microservice in the cluster.
Moreover, decoupling, a key principle of microservices, led to the adoption of different programming languages and frameworks for each microservice. While networking aspects across microservices often followed a consistent communication protocol and schema, this resulted in duplicated implementations across multiple frameworks and programming languages. Consequently, managing bug fixes and applying hotfixes became increasingly cumbersome, necessitating many changes.
With the rise of microservices, cloud-native, which is “used to describe container-based environments used to develop apps that have been built with services that can scale independently from each other and run on an infrastructure provided by a cloud provider“, developed. In addition to microservices, cloud-native includes their encapsulation in containers and their orchestration and scheduling. In addition, schedulers, like Kubernetes, abstract the underlying hardware, which enables a separate contemplation of the cluster hardware and the applications running in the cluster. Next to standardized communication, solutions that help monitor, manage, and troubleshoot the cluster applications became needed, becoming increasingly challenging in fast-changing environments.
One solution for these problems is the introduction of service meshes, which implement a new layer for service-to-service communication decoupled from the actual application. They do not need to get integrated into the applications and are, therefore, independent of the microservice implementations. The most prominent architecture is the sidecar model, which adds a proxy application to each microservice. Additionally, service meshes are optimized for the needs of highly dynamic cloud-native environments, such as Kubernetes clusters. Besides the networking features, especially observability and security-related features are optimized for these requirements.
With the extended Berkley Packet Filter (eBPF), the Linux kernel community implemented the ability to extend the slowly developing kernel with sandboxed applications at runtime, which negates the long waiting times for new kernel features or the circuitous handling of kernel modules. By its modularity, eBPF opens up new possibilities, enabling custom applications to run in the kernel space. This fuels networking, observability, and security innovation while empowering existing concepts like service meshes to optimize communication paths and resource impact.
This thesis builds on this idea and analyzes how far eBPF and service meshes can be combined. The aim is to display and analyze how far service mesh features can be moved to the kernel and if eBPF can enhance service meshes regarding resource usage and networking overhead.
Following an introduction of the main features, service meshes are subsequently examined in terms of strengths, weaknesses, and fields of application. Afterward, eBPF is introduced as a new kernel technology, which includes the features and possible applications. Followed by an implementation of eBPF to service meshes, a focus is set on networking enhancements, which are then validated by load tests.
Service Meshes
Architecture
The concept of service meshes is to place a lightweight application next to the actual microservice. Then, all traffic delivered to or sent from the microservice is routed through this application which is why they are called sidecar proxies. All sidecar proxies form the data plane, one of two architectural abstraction layers, which locates the functionality of a service mesh.
The second abstraction layer in service meshes is the control plane, which forms the actual service mesh by connecting the stateless sidecar proxies. In addition, it provides Application Programming Interfaces (APIs) and tools that can control and configure the behavior of the service mesh. The configuration includes the data plane policies, rules, and settings applied to the sidecar proxies. Furthermore, the control plane is responsible for platform integration as, for example, Kubernetes. This is necessary to get information about new services starting or services terminating to keep the service discovery updated. Since the control plane is indispensable in a service mesh, it is a component that has to be highly available and distributed.
This architectural approach solves several problems. The first one is the decoupling of communication and business logic. The sidecar implements the communication and network requirements, for example, traffic encryption. As a result, the microservices can concentrate on their business logic and the API accessing its functionality. Furthermore, applying communication and network features to all the sidecar proxies is done at once. This enables faster, more agile deployments since just one application has to be changed to apply the update. In addition, the microservices’ source codes need no updates, which reduces the number of changes. Simpler and faster developments and deployments are the results that increase usability.
However, additional service mesh configuration might be necessary, but implementing cluster-specific communication in the microservices is unnecessary. Moreover, the microservices do not have to know that a sidecar exists or that it changes parts of the communication by, for example, routing a request.
Summarized, service meshes help to “decouple the infrastructure from the application code“, which “simplifies the underlying network topology“. The developers, therefore, do not have to implement network behavior, but operators can create policies to describe the network behavior, mode identity, and traffic flow. The goal is to make service-to-service communication visible, manageable, and controlled across the microservice cluster.
Features
One of the features is the architecture itself. Service meshes change the communication and networking features’ location into a standardized architectural layer across all microservices. As discussed in Chapter II-A, implementing communication and networking functionalities requires changes in the sidecar but not in every microservice. As a result, feature development or deployment of breaking changes in the communication simplifies. Additionally, modernizing microservices is another benefit when introducing a service mesh. Implementing new networking features in the microservices is unnecessary since the sidecar takes this task. For example, this could be useful if a legacy application in the cluster does not support the newest encryption protocols.
Generally, the features of service meshes can be summarized in three categories:
- Traffic Control
- Security
- Observability
Traffic Control
The main goal of traffic control is to “provide granular [and] declarative control over network traffic“. The basic idea is to create an abstraction for delivering requests reliably from one microservice to another. In order to manage the traffic flow, service meshes are aware of all services available and maintain this state in a service registry.
The service registry helps the service mesh to make routing decisions on several OSI layers. The basic routing is located in the third and fourth OSI layers, where the payload and the payload’s encoding do not matter. Additionally, many service meshes provide traffic management on the application layer (OSI layer seven). An example of traffic control in the application layer is routing based on different Hypertext Transfer Protocol (HTTP) endpoints. These features of service meshes enable, for example, canary deployments or A/B testing.
Additionally, service meshes can help to increase resilience by providing features such as circuit breaking, retries, or timeout mechanisms. Furthermore, the sidecar proxies can offer the possibility of mitigating cascading failures or temporary outages. Service meshes can also handle throughput, latency, and (latency-aware) load balancing, which can increase the performance of microservice architectures.
Furthermore, since the service mesh is aware of what is happening in the cluster, it can apply changes to solve challenges like temporary outages without additional implementation in the microservices. With the help of the sidecars, service meshes can use retry mechanisms to intercept short-term failures. A service mesh can also handle failover mechanisms or dynamic shifting of traffic when performing protocol updates. An example of such an update could be a new field in an API that is required for new features or breaking changes in the communication flow.
Security
Since the number of microservices increases, the interconnections between services rise too. This leads to more protect-worthy communication links, which lowers the overall security. Additionally, microservices need to be validated as trustworthy.
An example would be a payment system that only some other services should have access to. Therefore, access to the payment service should be generally prohibited, and only a few services that interact with it have access.
In order to decide whether requests are allowed, service meshes identify the requesting services by their service name or additional labels. In addition to access rights, identities can help track requests. An often-used model is the Zero Trust security model, which evolved from the Perimeter Security model and states that network participants no longer automatically gain access to the system as soon as they join the network. Therefore, every request must be authenticated and authorized to decide whether access is allowed. Zero Trust security claims to “never trust, always verify“.
In order to increase overall security, service meshes can enforce security, policy, and compliance requirements across all microservices. This includes securing the service-to-service communication by encrypting the communication channel or adding identities to the microservices. Both can be accomplished by protocol translation or encryption protocols like Mutual Transport Layer Security (mTLS). The mTLS protocol is based on the Transport Layer Security (TLS) protocol which authenticates the server a client wants to communicate with. Additionally, the communication between the server will be encrypted. When using mTLS, the client is authenticated by the server in addition to the server’s authentication at the client. Since both parties of the communication have to authenticate, both have verified identities that can be used to check further authorization policies. There is no need for complex perimeter security models, like subnets, that are hard to set up and maintain since every request will be authenticated and authorized by the service mesh. In order to enable these features, service meshes can generate and manage certificates, administrate keys, Single Sign-on (SSO) tokens, or API keys.
Observability
Since service meshes route all traffic through the sidecar proxy, all communication is transparent to it. This data can enable features in the area of observability, tracing, and diagnostics. Moreover, troubleshooting is more straightforward since the service mesh can help find correlating service interactions that might lead to problems. The sidecars will provide the data for observability, tracing, and diagnostics. Therefore, no additional implementation in the microservices is necessary. This includes simple health checks, performance monitoring, and collecting logs.
The extendet Berkley Packet Filter (eBPF)
The extended Berkley Packet Filter (eBPF) is the further development of the Berkley Packet Filter (BPF), which was developed by Steven McCanne and Van Jacobsen in 1992. BPF is a network packet filter that performs the filtering mechanism in the kernel space instead of the user space. As a result, the performance compared to filters that copy the whole packet from the kernel to the user space improves significantly. The further development of BPF, eBPF, was the answer of the Linux kernel community to the long kernel update cycles and the circuitous handling of kernel modules. Kernel modules are an extension feature of the kernel that can enhance its functionality.
Like BPF, eBPF is located in the Linux kernel. Compared to BPF, which is a packet filter in the kernel, eBPF can run sandboxed programs of any kind in the privileged context of the kernel. Therefore it is often called the kernel’s mini Virtual Machine (VM).
With this in mind, eBPF makes the kernel highly customizable and helps to “safely and efficiently extend the kernel’s capabilities without requiring to change the kernel’s source code or load kernel modules“. That is why developers can enhance the kernel and the Operating System (OS) for their needs without waiting for the community to update the kernel officially.
On the one hand, eBPF programs are restricted to the kernel space and cannot cross the border between the kernel and the user space. In order to control eBPF, there is a stable API for the user space available. On the other hand, eBPF programs have access to the internal APIs of the OS, which enables rich security, observability, and tracing functionality. This includes monitoring or tracing applications running in the user space. Additionally, the proximity to the kernel allows eBPF programs to optimize for performance heavily. This is also accomplished by compiling out unused functionality.
eBPF Program Structure
Separating eBPF into a development and a runtime mechanism is possible. In the development phase, the actual eBPF program is defined and compiled into bytecode, a binary format the kernel’s eBPF API accepts.
Afterward, the kernel loads the eBPF program, which verifies the application and compiles it to the targeted Central Processing Unit (CPU) architecture.
In order to run an eBPF application, the kernel’s eBPF API expects bytecode as input. Since writing bytecode is possible but not the most common development method, several compiler suites (e.g., LLVM) and abstractions (e.g., eBPF Go Library) exist. These allow writing eBPF programs in different programming languages like C, C++, or Go.
The resulting bytecode includes the actual eBPF program and the description of the used eBPF maps. Before the application can be run, the kernel verifies if the eBPF program harms the kernel and compiles it for the targeted CPU architecture.

Hooks
The execution of an eBPF application is event-driven. Therefore, the program includes a description of the so-called hooks the application wants to listen to. Each eBPF application can specify one hook point.
Many hook points allow, for example, listening for system calls, function entries and exits, network events, or kernel tracepoints. Figure 1 displays examples of points in the Linus kernel at which eBPF programs can be triggered. If the predefined hooks do not fit the requirements, kernel probe (kprobe) and user probe (uprobe), provide the possibility to attach the eBPF program almost anywhere in the kernel or user applications. The hook points are defined by the program type of the implemented eBPF program.
In general, eBPF programs cannot call regular kernel functions, but helper functions exist to simplify the implementation of eBPF programs. They differ in the eBPF program types, and they form a generalized API that enables eBPF programs to “consult a core kernel-defined set of function calls in order to retrieve/push data from/to the kernel“. The most used helper functions are random number generators, time functions, or functions that help access the eBPF maps, which the next chapter focuses on.
Maps
n order to share data, eBPF introduces a mechanism called maps. Maps can be used by eBPF programs in the kernel space as well as applications running in the user space. For example, with maps, metrics for monitoring can be delivered to an application running in the user space that displays them in a dashboard. The possibility to exchange data between (eBPF) programs helps with more complex scenarios where different hooks and programs must be combined.
Maps consist of efficient key-value stores that are located in the kernel space. In order to enable user space programs to access the data as well, eBPF offers an API to the user space.
Fields of Application
The development capabilities of eBPF enable a variety of domains in which eBPF can be used. Since the original BPF is a packet filter, one of eBPF’s biggest strengths is managing network traffic. As in BPF, creating network policies that can even engage the raw packet buffers is possible. This allows quick decisions about what to do with the packet since both enable filtering network packets before the network stack of the Linux kernel. Moreover, with eBPF, it is possible to bypass the complex networking and routing paths of the Linux kernel.
Additional to the filters, the ability to access the raw packet buffers enables load-balancing right at the source of the connection. Depending on the network topology, this can remove the overhead of resolving Network Address Translation (NAT) since Destination Network Address Translation (DNAT) does not need to be conducted.
Furthermore, eBPF can enhance networking capabilities by offloading TLS and mTLS. Moreover, complex protocol negotiations and parsing can be improved with the help of eBPF.
When taking a more detailed look at the possibilities of eBPF, programs of the type eXpress Data Path (XDP) can be used in various use cases. XDP allows packets to no longer be transmitted or prepared for the in-kernel networking stack. Moreover, in the offloaded mode, the XDP program is executed directly in the Network Interface Controler (NIC). This is perfect for Distributed Denial-of-Service (DDoS) mitigation, firewalling, or load balancing at OSI layer three or four.
An example of a load-balancer, based on XDP, is Facebook’s Katran project, which enables building high-performance layer four load-balancing forwarding planes.
Dropping packets at the earliest stage possible is also helpful for filtering mechanisms and processing before the kernel’s networking stack. An example of filtering mechanisms is denying access for specific Internet Protocol (IP) ranges or filtering for the existence of header information.
For example, if the applications on a node only support Transmission Control Protocol (TCP) traffic, packets of other types can be dropped. Besides filtering, preprocessing before the kernel’s networking stack can be useful, for example, for encapsulation or mechanisms like NAT (especially Source Network Address Translation (SNAT) and DNAT).
Additionally to the networking capabilities, eBPF can be used to improve a system’s observability. First, the networking capabilities of eBPF enhance the observability of the network and the tracing of requests. Since eBPF programs can see every request, they can aggregate context data and metrics without routing the traffic to, for example, an extra tool in the user space.
Here, XDP is also a good example since it is useful for flow sampling, monitoring, and other network analytics. With the Linux perf infrastructure, pushing a truncated packet, a packet with the full payload, and custom data to the user space are possible. Furthermore, traffic analysis can be stopped if the traffic flow is classified as trustworthy.
With the different probes, tracepoints, and perf events, eBPF programs can attach nearly everywhere in the kernel. Therefore, it is possible to implement a variety of probes and sensors to collect context-rich data, all of which can be accomplished without changing the kernel’s implementation. However, this includes the tracing of the kernel as well as programs running in the user space.
The security capabilities of eBPF are based mainly on networking and observability features. This is the case since much security is about what information and data are visible and collectible. Moreover, as displayed by the previous chapters, eBPF can investigate nearly every function call in the Linux kernel. Therefore, it is feasible to undertake system introspections with very low overhead.
The different eBPF program types enable the implementation of security-related features at many different layers and hook points in the kernel.
In the networking area, package drops are the most crucial defense mechanism in case of DDoS mitigation. With XDP, this is possible early in the networking stack. This results in minimal computational resources that are used to process the packet. If the packet is dropped, this computational cost should be minimal, introducing XDP as the perfect match for this task.
Therefore Cloudflare, a worldwide acting company providing a Content Delivery Network (CDN), Domain Name Service (DNS) servers, and cloud-related security products, decided, for example, to implement their DDoS defense with XDP, which is now running across their whole infrastructure.
Additionally, Cilium, a Container Networking Interface (CNI) based on eBPF, advertises the automatic encryption of connections with the IPsec infrastructure of the kernel. With this mechanism, it is possible to implement encryption on OSI layer three with the help of eBPF and the helper functions provided.
Furthermore, seccomp-bpf, a kernel feature based on eBPF, implements a syscalls filter, limiting the potential misuse of syscalls. The filter then checks if syscalls belong to an application’s set of allowed syscalls. This feature is used widely in the area of containerization and orchestration of containers. Docker, for example, uses seccomp-bpf to apply custom seccomp security profiles, and Kubernetes uses it to implement security contexts for, for example, pods.
Service Mesh Networking with eBPF
Service Meshes often are applied to modern clusters that are based on Kubernetes. The Kubernetes control plane includes a component called kube-proxy, which uses in its standard configuration a technology called iptables to apply, update, and delete rules dependent on the cluster configuration. In general, iptables get used to “set up, maintain, and inspect the tables of IP packet filter rules in the Linux kernel“. More concretely, the kube-proxy implements the iptables rules to provide the Service object abstraction in the cluster. This allows an automatic load balancing between several instances of an application merged in a Service object to only provide one API for all running instances to the cluster.
Service meshes often sit on top of this iptables-based infrastructure layer, which is why they also use this technology for their base routing. For example, Isito, one of the most used service mesh implementations, uses iptables to route between an application and its corresponding sidecar proxy.
Since the check of iptables processes sequentially, the process slows down the more rules exist. This can become a problem within large Kubernetes clusters that include a lot of application instances and Service objects. If a service mesh is also deployed to the cluster, the number of rules increases even more. As a result, the check gets even slower, which decreases the performance of the whole cluster. The first impact is a higher latency of connections in the cluster. Additionally, the high number of iptables checks claim more CPU time, which leads to higher utilization.
-
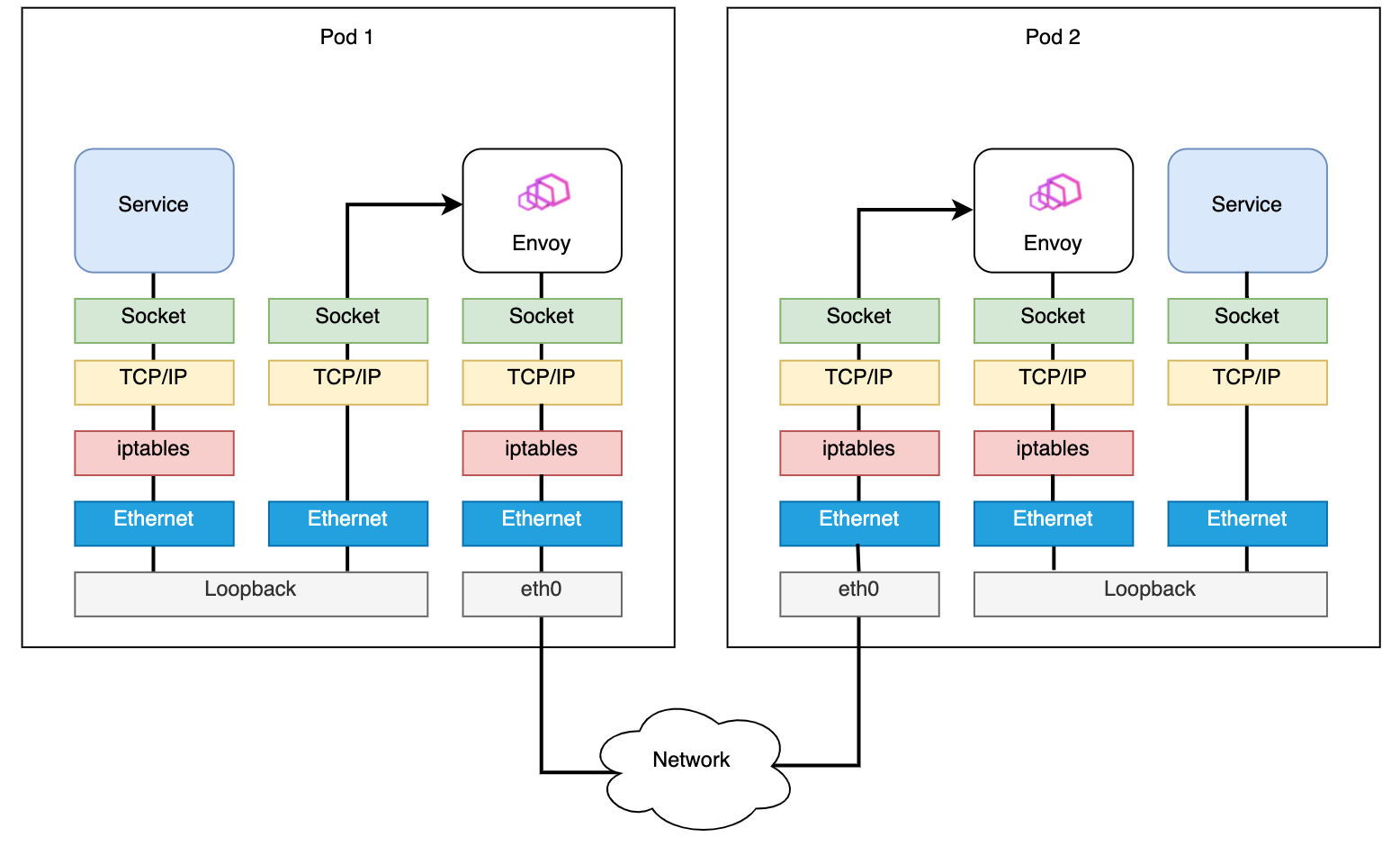
Fig. 2. Routing in a service mesh using the example of Istio
Furthermore, when communicating between, for example, two applications in a service mesh, the iptables rules will be checked several times. Figure 2 displays that the rules get checked whenever an application and the correspondent sidecar proxy communicate. In addition, the iptables rules are executed every time a packet leaves or accesses a Kubernetes Pod or, to be more precise, whenever a packet crosses a network namespace border.
Summarized, in large service meshes in Kubernetes clusters, the sequential check of iptables rules can decrease performance. As a result, the latency in the cluster increases. In addition, checking the iptables rules needs more CPU cycles, leading to higher utilization.
The described problems of iptables can be solved by an updated iptables implementation or an alternative technology. Since, as mentioned before, the further development of kernel technologies is slow and complex, the likelihood of an iptables update is small. However, due to its flexibility, an eBPF program could implement the requirements that currently are solved using iptables in a completely different way.
-
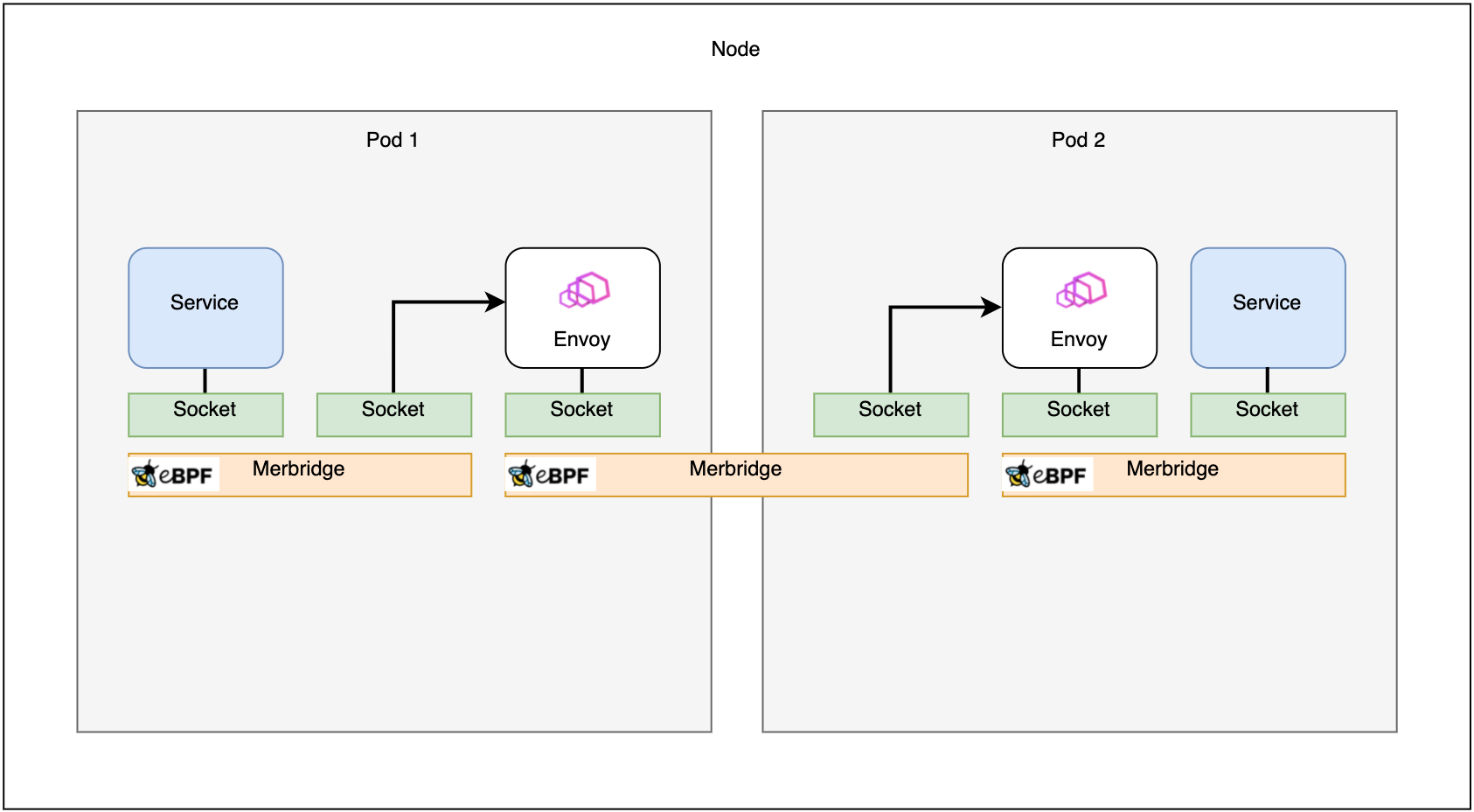
Fig. 3. Routing in a service mesh with eBPF
The raw Linux sockets are the first level in the networking stack eBPF can interact with when sending a packet from a cluster application. At this stage, the eBPF application has access to the packet and the sockmap, a special-purpose eBPF map containing information about all sockets on a host. With this feature, eBPF programs can be implemented that route packets directly between two sockets.
As a result, every time a packet is sent from an application, a corresponding eBPF application can be triggered that sends the packet directly to the destination’s socket. In a service mesh, this application would be the sidecar proxy. This socket-to-socket connection bypasses most of the Linux networking stack, including checking iptables. If the request’s destination is located on the same host, as shown in Figure 3, the routing between the destination’s sidecar can also be optimized using eBPF. Furthermore, mechanisms like NAT are no longer necessary, and the service mesh extends its functionality by interacting with packets at such a low network stack level.
The main advantage when using eBPF is that it has access to the information earlier than iptables. The second advantage is the data structure of eBPF compared to iptables. When using iptables, the complete list of rules is checked sequentially every time. This also includes rules for different networking namespaces or IP ranges. Compared to that, eBPF’s data structure maps are key-value stores. These key-value stores allow rules to be sorted, categorized, and summarized. Therefore, the check of rules is way more performant since only the subset of relevant rules can be checked.
Furthermore, next to the routing between the sidecars and applications, eBPF can also be used to implement other networking features of a service mesh. This includes interactions up to the fourth OSI layer. Consequently, sidecar proxies become unnecessary since they can be bypassed as long as the processing of the network features does not cross the border to OSI layer five. This bypass results in the request paths having two hops less, which decreases the latency and CPU load even more. Additionally, the proxy has to implement fewer features, which results in more lightweight sidecar applications.
Implementing service mesh features in eBPF can also be viewed critically. This is mainly because many features require handling on the application layer, which eBPF is not supporting. For this reason, the packages would have to be passed on to a user-space application (proxy application). If service mesh features are implemented with eBPF and additional proxies in the user space are necessary, the overall complexity increases. Using one component that handles service mesh features could simplify the understandability, especially while debugging or troubleshooting.
When implementing more features of a service mesh with eBPF, the question arises of how the eBPF applications receive the data necessary to make decisions. This includes information like service discovery information for load-balancing decisions or policy rules. Unfortunately, it is difficult for eBPF programs to collect this data since eBPF is a reactive, event-based implementation. In order to realize this by using eBPF, complex implementations are necessary that include broad knowledge about the overlying scheduling and processing layers. Therefore, in most cases, it makes sense to implement an additional application in the user space that knows the scheduling and processing mechanisms and has easier access to user space resources via corresponding APIs. The user space application could also preprocess the collected information and transfer it into an easy-to-handle format for eBPF programs. Results can then be written to maps that eBPF programs can use at runtime, and the user space application can update continuously.
The described scenarios show that it is possible to implement networking features of service meshes with eBPF. The shift of functionality to the kernel space relieves in all service mesh applications the proxy application. Depending on the feature set used in a service mesh, more features are implemented using eBPF, which shifts criteria like feature isolation or security granularity towards the optimal. With the decreased resource usage of eBPF-based implementations, the sidecar proxy architecture becomes uncomely. This architecture shift is, for example, visible in the Cilium Service Mesh, which uses a proxy per node and eBPF instead of the sidecar approach widely used by service mesh implementations such as Istio or Linkerd.
Load Tests
Requirements
Two aspects are interesting when performing load tests on a sidecar-based service meshes in the context of eBPF. On the one side, this is the performance of the service meshes under different loads, and on the other side, the comparison of the results between the implementation with eBPF and the implementation without eBPF. The analysis results from Chapter IV point out two metrics that are interesting to look at. Since eBPF enables skipping the kernel’s networking stack, many calculations in the CPU are omitted. Therefore, the expected result of the load tests is that using eBPF reduces the utilization of the CPU. The omitted calculations also save time, leading to an expected latency decrease. Therefore, these load tests will also compare the latency when benchmarking eBPF against an iptables-based implementation.
Furthermore, one of the biggest problems when using iptables is the number of rules applied. The more rules that exist, the slower the sequential execution of iptables. Therefore, the load test setup should also consider the number of applied rules.
Test Setup
The load test setup is based on a Kubernetes cluster of three nodes, consisting of four virtual CPUs, eight GB of Random Access Memory (RAM), and 30 GB of storage each. Additionally, one extra node exists, which persists the monitoring data.
The nodes are VMs in the inovex Cloud Services (iCS), a Cloud-Plattform owned by the inovex GmbH.
Next to the Kubernetes control plane node is a node running a monitoring stack consisting of Prometheus, Grafana, and several exporters. The third node in the cluster runs the actual load test, which includes a server and a client application. Since eBPF is a kernel technology restricted to one host, a higher impact is expected if the communicating applications run on the same host. Therefore this node runs a simple web server (httpbin) and a client (k6) that constantly requests that server. The client also collects latency metrics for each request.
In order to provide networking functionality to the cluster, a CNI needs to be installed. In this setup, Calico is the installed CNI that enables the basic networking in the cluster. Its base configuration uses iptables to route the traffic to the correspondent destination.
To fulfill the requirement of many iptables rules, another component called Cluster-Flooder is deployed to the cluster. The Cluster-Flooder is a proprietary development and takes advantage of the handling of Pods and Services by Kubernetes. Since their creation produces iptables rules, the Cluster-Flooder configures a number of Pods and Services that will be created. To inflate the number of rules, the endpoints for each Service will be all Pods initialized by the Cluster-Flooder. The Cluster-Flooder was configured to start 250 Pods and 250 Services for these tests.
Istio is the sidecar-based service mesh selected for these tests. It will inject a sidecar into the Kubernetes Pods of the httpbin and k6, which adds the two applications to the service mesh. All other applications will be excluded from the service mesh since they do not communicate. Proportionally, the overhead of the sidecar proxies is too high compared to the additional iptables rules. For completeness, it is important to mention that adding the server and the client to the Istio service mesh adds more iptables rules.
The service mesh has some basic configuration. This includes the encryption of all communication between the applications in the service mesh by using mTLS. Additionally, there are policies applied to the httpbin. First, all incoming traffic is forbidden, except the k6 application requests the /get endpoint with an HTTP GET request on TCP port 80. The last configuration added to the service mesh is a two-second timeout for requests to the httpbin application. Two seconds were selected since users tolerate waiting times up to two seconds.
To introduce eBPF functionality to the Istio service mesh, Merbridge will be used. Merbridge mainly focuses on routing traffic between the sidecar and the application. However, the traffic to other Pods located on the same cluster node is also managed by Merbridge. Therefore Merbridge ensures that eBPF is used for both the service-to-sidecar and the Pod-to-Pod routing, which perfectly fits the requirements of these load tests. It is important to mention that Merbridge does not move other service mesh features from the networking area to the kernel.
Result Analysis
-

Fig. 4. An excerpt of the latency distribution of the load tests
Figure 4 shows the latencies of different tests with Calico and Merbridge. The box displays the mean, the 25th, and the 75th percentile of the measured latency for each test run. The whiskers show the fifth and the 95th percentile.
When taking a look at the results, there are two things noticeable. One conspicuousness is the significant variance in the results for each technology. For example, when looking at the results for Calico, the results reach from approximately 2.5 ms up to nearly 20 ms. Furthermore, when using Merbridge, the whiskers reach from about 3 ms up to 140 ms. Primarily, the test with ID four shows significant outliers, but the results generally show considerable uncertainty.
Additionally, no improvement is visible when using Merbridge, which was expected from the analysis results.
-

Fig. 5. The maximum CPU on the third node for different technologies
In addition to missing improvements regarding the latency when using Merbridge, the captured maximal CPU load does not improve either. The maximum CPU is inconsistent when looking at Figure 5 results. Especially when using Merbridge, the results of these tests are in the range of 39.7% to 65.7%, which is quite a big difference.
While looking for optimizations, three explanations for these problems were found. The first is cloud noise in the iCS. To accomplish the best capacity utilization grade on the physical hosts, the cloud is slightly over-scheduled with VMs (verbal information from Hannes von Haugwitz and Christian Rohmann, 10.03.2023), which can result in CPU steal. Moreover, the network utilization on the host machine, influencing the load test results, is unknown.
Tackling the noisy cloud is challenging since its scheduling and network utilization are not manipulable. In order to keep the time gap between testing the two technologies as small as possible, the execution of their tests happens in succession. As a result, Calico will be tested first and, right afterward, Merbridge with the same test configuration.
When taking a closer look at the CPU load on the node the load tests run on, it is noticeable that the kube-proxy has a very high utilization when the Cluster-Flooder’s Pods get started. The kube-proxy utilizes a CPU core with close to 100% for quite a long time by running an iptables-restore process. This was noticeable across deployments that were using Calico as well as Merbridge. One way to solve this issue is to wait until the kube-proxy finishes its rules restoration, which takes at least 25 minutes. Another less time-consuming solution embraces changes in the configuration.
After testing different Cluster-Flooder configurations, it is noticeable that the number of Pods created by the Cluster-Flooder has a higher impact on the kube-proxy’s CPU utilization than the number of initialized Services. A sweet spot was found with 50 Pods and 500 Services, resulting in 101806 entries in the iptables ruleset, resulting in an iptables overhead for less than five minutes, which is a significant improvement compared to the previous configuration.
Additionally, the httpbin, used as the server application for the load tests, showed a high utilization at a request rate of 200 requests per second. In addition, the latency seemed relatively high for such a simple request pattern, with just 200 requests per second. Therefore, the httpbin was exchanged with an NGINX container to see if it could handle a higher rate of requests better. Tests showed that the NGINX utilizes the CPU significantly less than the httpbin. Therefore, to minimize the likelihood of the httpbin being a bottleneck, resulting in a distortion of the results, for all upcoming tests, k6 will request an NGINX server instead of a httpbin.
With these improvements, the load tests are repeated. Additionally, the number of requests was increased to 1000 and 1500 requests per second since the NGINX can handle way more requests per second at the same CPU utilization.
-

Fig. 6. The average request duration for different technologies displayed for each testing pair
Figure 6 shows the results of the latencies where the test pairs were executed right after one another. When looking at the boxplots that display the test pairs, it is visible that the results are not consistent either, even though this setup tries to minimize the impact of cloud noise on the measurement. This is the case for Calico and Merbridge. Additionally, the results also show that there is no improvement when using Merbridge over using Calico, independent of the number of requests. In some cases, the latency is even worse compared to Calico.
-

Fig. 7. The maximum CPU on the third node for different technologies displayed for each testing pair
When comparing the test pairs’ maximum CPU utilization in Figure 7, no improvement is visible when using Merbridge. Merbridge performs slightly better in most test cases, but the difference with Calico is marginal. However, it is noticeable that the maximum CPU utilization is noticeably worse when using Merbridge in two of the six test pairs. Therefore a generalized proposition is difficult.
Conclusion
The analysis showed that eBPF can bring promising improvements to service meshes. This is especially the case for the networking between a workload and its sidecar. The sidecar application can even be bypassed when the service mesh’s networking functionality below OSI layer five is implemented with eBPF.Since eBPF is located in the kernel space, it is not made to interact with network packets on OSI layers five and above. The kernel is missing features to handle traffic at these layers, so functionality on these layers must be implemented from scratch. As a result, eBPF should not aim to handle such traffic but rather hand it over to user space applications that profit from already existing implementations and programming APIs.
The results of the load tests are sobering, while the theoretical analysis was promising. First, in this load test setup, problems such as cloud noise exist, which makes it difficult to compare the service mesh implementations. Furthermore, the impact of eBPF is way smaller than expected. Even though many layers of the kernel’s networking stack will be skipped with Merbridge, the kernel’s networking implementation is heavily optimized for the use cases of these load tests.
Overall, eBPF seems like a promising technology that can, in theory, enhance service mesh networking. Compared to Calico, no improvement was visible when using eBPF in the form of Merbridge to communicate in an Istio service mesh.
Outlook
Overall, much exciting research can be done based on the results collected. The load test results did not clearly show that eBPF in the form of Merbridge improves Istio’s networking implementation. Further investigation is necessary to point out possible architectural or implementation mistakes. This includes a detailed analysis of the various eBPF programs forming Merbridge.
Furthermore, it would be interesting how a complete shift of all service mesh features on the OSI layers three and four to eBPF would look like. Merbridge focussed on communication between the different parts of the service mesh, but networking features, like load balancing, were not yet adapted by eBPF. The impact of these implementations on performance is an exciting future investigation.
The load tests showed that overloading the kube-proxy’s default configuration is easy. Additionally, the kube-proxy has a mode where it uses an IP Virtual Server (IPVS) instead of iptables. Its rule checks are already optimized, resulting in a consistent processing performance independent of the cluster size. Therefore, it would be interesting to compare these two technologies and analyze to what extent replacing IPVS with eBPF would make sense.
During the load tests, the noise of the used cloud infrastructure was an additional problem. A future investigation could perform the same tests in a more quiet environment. This would help to verify whether the inconsistent measurements problem was caused by the iCS. Besides this, a less noisy environment could help to pinpoint the causes of missing improvements using Merbridge.
The analysis of this thesis mainly focused on the networking enhancements of eBPF in service meshes. Observability and security are two promising fields of application of eBPF which could broadly improve service meshes. In networking, the improvements mainly focused on shifting service mesh functionality into eBPF. In contrast, when using eBPF for observability and security-related tasks, the features of service meshes could be expanded.


