
Notice:
This post is older than 5 years – the content might be outdated.
etcd [1] is a consistent, distributed key-value store which uses the raft consensus algorithm [2]. etcd is used by many projects but it is probably best known for being the data store of Kubernetes. Most applications use etcd to store some key-value pairs and read consistently from it. There is also the possibility to watch for changes on a given key space (e.g. with prefix matching). Currently etcd supports 2 APIs for storing data, etcd v2 and etcd v3. These 2 are not compatible and data stored in v2 can’t be accessed over v3 (since they changes the storage backend).
Our Scenario
In our scenario we use etcd as a central configuration store (see image 1 below) for our bare-metal Kubernetes deployments. In etcd we store e.g. which nodes are part of which Kubernetes cluster (and the versions of the used components like the Kubernetes version). The actual configuration for systems like Matchbox [3] are rendered by confd [4].
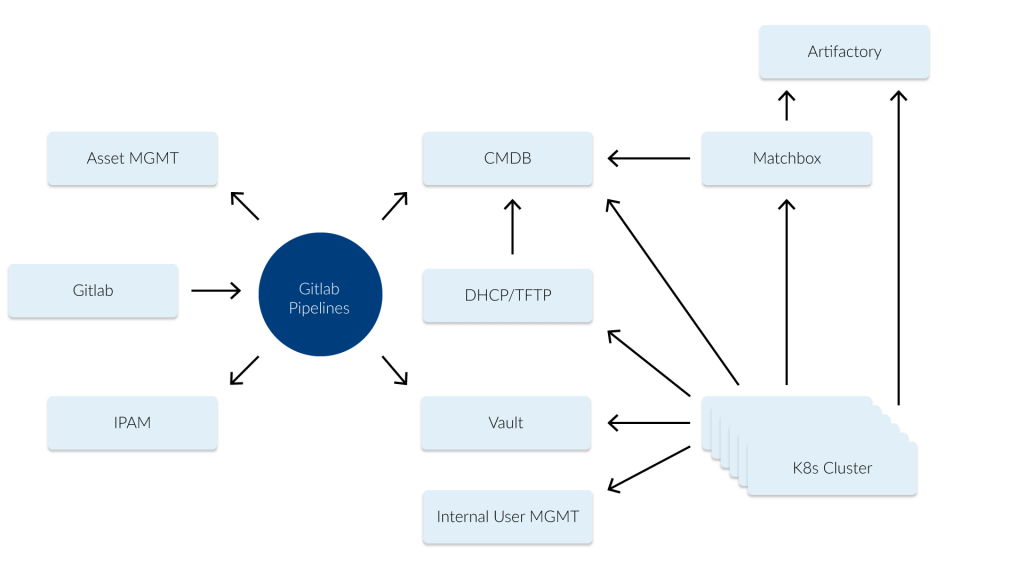
The system has been running for more than 2 years without any major issues (most of the issues we had were some bad configurations). One of the special use-cases is that we also manage the current deploy-state of a machine over etcd. We can set a machine to a “redeploy“ state which means the machine will be rebooted and redeployed with the config while also configuring our DHCP service to tell the machine it should fetch the config from Matchbox or if the machine should boot from disk. This mechanism gave us the required flexibility to maintain these clusters with a small team. In order to secure our etcd we use authentication and multiple different users and roles [5]. Many systems like a node, Matchbox and the DHCP server are reading from the same values, e.g. to trigger a reboot on a node and also set it to new provisioning in the DHCP.
What Happened
For a long time we were using etcd v2 which was the default. With etcd 3.4 v3 became the default and v2 was deprecated and will be removed in the future. As a small project we changed all our clients to use etcd v3, which is based on gRPC. The good thing was that the transition for us was pretty smooth. We didn’t need to migrate any data (we just recreated all data stored in etcd). Currently we have multiple stages for testing our infrastructure and in our development state we noticed strange behavior after we switched to v3. Our deployments were pretty inconsistent, e.g. some nodes came up with an older configuration and some nodes didn’t even reboot or were redeployed.
When we dug into this issue we saw that etcd returned different values when we queried it and recently even more issues were opened which are all related to data inconsistency when authentication is enabled. The main issue seems to be fixed in 3.4.5 (but even now other issues are still open).
How We Solved It
etcd v3.4.5 was not yet released when we observed this, so we were left with three options:
- Revert the migration (very work intensive)
- Disable authentication (which was no option for us, since this would allow everybody to change the behaviour of our deployments)
- Reduce the number of etcd nodes to 1
We choose option 3 since our etcd nodes are running on fairly reliable VMs and if the they were not available for a short period of time it wouldn’t be a major incident since the clusters would still be operating. During an incident the only blocker we have is that we can’t deploy updates or new Kubernetes clusters. With a short Mean Time To Recover (MTTR) for our etcd VM we accepted this risk.
I wonder why there are not some failure stories with this nice little bug: https://t.co/9GozCoctOY debugging this one was fun 😀
— Johannes Scheuermann (@johscheuer) February 24, 2020
Outlook
Even with a “battle-tested“ component such as etcd [6] which is used in nearly all Kubernetes deployments (except for k3s deployments) you can see strange behaviour. The good thing for us was that we could solve this issue with a pretty simple workaround.
[1] https://etcd.io
[3] https://github.com/poseidon/matchbox
[5] https://github.com/etcd-io/etcd/blob/master/Documentation/op-guide/authentication.md
[6] https://jepsen.io/analyses/etcd-3.4.3


