
In the current technological landscape, an extensive range of voice assistants and dictation software have been developed, capable of processing human speech for diverse purposes. Nevertheless, the majority of these applications necessitate manual language specification by the user, as they lack the capability of automated language identification. The simultaneous use of several languages is only possible to a very limited extent.
For the language assistants in private use (Google Assistant, Apple Siri, Amazon Alexa), this automatic language identification is not absolutely necessary since the languages spoken do not change often. The language identification, however, would be essential for applications that are intended to be used in public spaces. An example of this would be chatbots at train stations or airports with the purpose of answering questions from a wide variety of people in different languages. Software that reliably identifies the spoken language would be essential for easy and efficient verbal communication between the chatbot and the users. Other applications for this kind of software, which are described later in detail, would be online translators or large video streaming platforms.
Current models for language identification
Several language identification models have already been developed but with significant limitations. Many of these models have narrow language coverage, while others suffer from high classification error rates. Consequently, current models do not possess the necessary accuracy for unambiguous language recognition, which is a critical requirement for the aforementioned applications. In these applications, a vast array of languages must be identified with very high accuracy in order to be useful in the real world.
In some of the previous approaches, Convolutional Neural Networks (CNNs) (Revay and Teschke, 2019), a combination of CNNs and Recurrent Neural Networks (Bartz et al., 2017), and a combination of a Gaussian Mixture Model and a Support Vector Machine (Mitra, Garcia-Romero, and Espy-Wilson, 2008) were used to identify languages in audio. These models were created and tested using only six languages. These models can identify spoken languages with very good accuracies (around 90 % classification accuracy). However, the amount of languages used in these approaches is too limited to be of practical use.
As for models which are able to recognize more languages, there have been models like wav-to-vec-51 (Conneau et al., 2023), mSLAM-CTC (Bapna et al., 2022) or Whisper (Radford et al., 2022). These models have been tested with mediocre results on the FLEURS test dataset (Conneau et al., 2023) which includes 102 languages:

We can see that currently available models exhibit a clear trade-off between the number of languages they can identify and their identification accuracy. Researchers have not yet developed a reliable method that can identify many languages while achieving very high accuracy.
Learning the wrong objectives
The biggest challenge for training new models for language identification is that during the training process, the model can learn the wrong objectives. More precisely, the model could learn the voices or specific audio characteristics of the audio files rather than the difference between the languages themselves. The gravity of this problem increases for a smaller dataset. A larger model can easily learn to differentiate between a small number of voices or other audio features like the characteristics of the specific microphones used.
This effect has been observed during our own training and testing efforts of new models. When using a part of an initial dataset as a validation dataset, the training and validation accuracy were constantly very high. However, when testing the model with a different dataset that did not include the same voices but the same languages, the accuracy regularly dropped to an accuracy only marginally higher than the accuracy which would be expected for a random classifier. This indicates that language-specific features have not or only to a very limited extent been learned. Consequently, other unwanted features like specific voices or audio characteristics have been learned.
The Solution
In the training process, a dataset with many different voices and audio characteristics can be used in order to avoid learning the wrong objectives and to ensure that language-specific characteristics are learned. Also, the relative share of speakers of each gender should be similar for each language. If, for example, for one language the speakers are mostly female while for a different language the speakers are mostly male, the model could simply learn to differentiate between the two genders and not between the two languages.
Furthermore, for validation and testing of the model, different datasets with different speakers should be used to ensure that the only common characteristic of the training and validation/test data is the language that is being spoken. In this article, the previously mentioned methods of overcoming the problem of the model learning false objectives have been implemented by using the FLEURS dataset. This dataset includes many different speakers as well as no speaker overlap between the development, test, and training sets.
The synergistic combination of foundation models
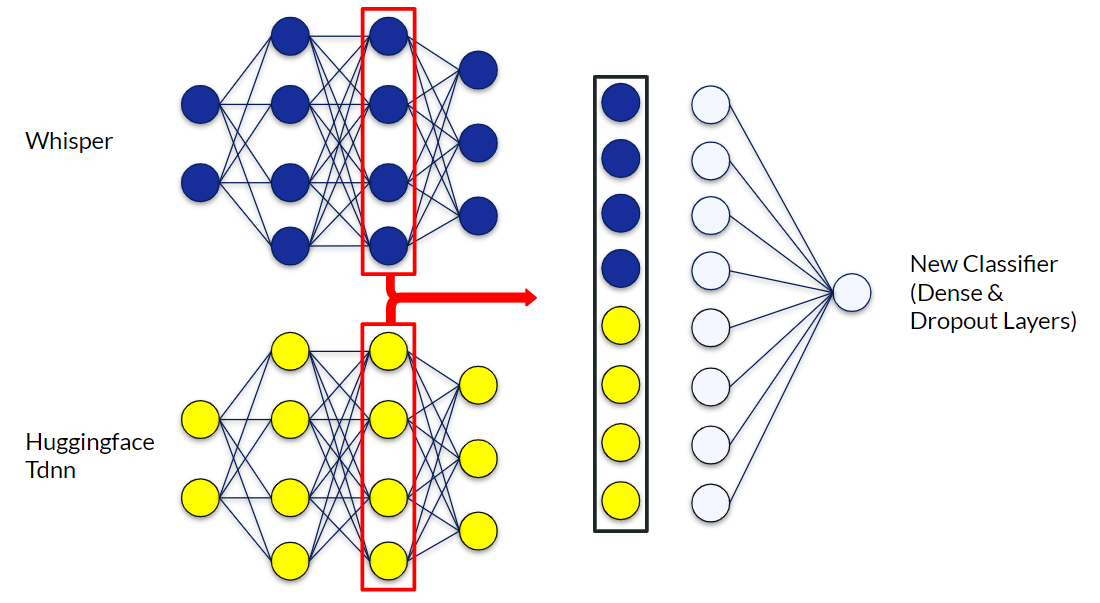
Our method, which combines and enhances the current language identification models, can be summarised as training of a new classifier model which uses existing large foundation models as embedding layers. Within this approach, the already existing models were used as a basis to extract relevant information from the audio files. Then a newly trained model was built on top of them, only representing the last layers in order to perform the final classification.
In the experiments, we built an instance of this approach that utilizes a combination of the penultimate layers of Whisper and Time Delay Neural Network. We took the output vectors of the penultimate layers of these two models, concatenated them, and used these concatenated vectors from each audio file as input vectors for the training of a new classifier model. For training, validation, and testing, the corresponding audio files from the FLEURS training, development, and test dataset have been used. Using this approach, the penultimate layers of the two models are essentially combined. Instead of the original output layers of each model, the newly trained model acts as an output layer that can classify a combined input vector.
An example of a simple, binary classification with one output neuron could look like this:
Experimental results on the FLEURS dataset
To develop this approach, we used the complete FLEURS dataset, which contains 102 languages. We evaluated this approach using the FLEURS test dataset and present the results of this evaluation, along with a comparison to existing models, in the following table:

We can largely attribute the bad results of the individual Whisper model to the fact that it lacked training for many languages present in the FLEURS dataset. On the other hand, we can largely attribute the positive results of the combination method to the usage and extension of Whisper by adding the missing classes. Nevertheless, the combination of the two models still outperforms the individual models whose classes have been extended by using the method described above (adding the new readout model). When we evaluated those models individually, we found that the Whisper model achieved an accuracy of around 87.5 %, and the Time Delay Neural Network achieved an accuracy of around 76.5 %.
Practical use of the results
The enhancement of language identification accuracy can affect a variety of real-world scenarios. One example for the affected areas would be the automatic generation of subtitles for online video platforms. Here a large amount of user-generated videos in unknown languages are uploaded regularly. In order to choose the correct speech-to-text model for the transcription, the language would first have to be identified. Also, service chatbots in public areas like airports or train stations with multinational conversation partners could be enhanced by being able to identify languages, making conversations possible without the user having to select a specific language.
Additionally, the results could be relevant for online translators, as many of them are able to recognize any language from text, but not from speech. In the case of Google Translator, for example, a language must be selected for using the voice input. When using text as input, however, the language of the text can automatically be identified and translated into the desired language. Improved language identification in speech could be used to automatically identify the language of the voice input.
When training speech-to-text models, we can collect audio data in large amounts from the internet. However, when we need to train models for a specific language, we must verify the language of the audio data. Since verifying language manually would take a lot of time, we could use a language identification model.
Finally, as our approach requires only the training of the small classifier model, it is very useful for groups with limited compute resources as we only execute the forward inference pass of the large foundation models. All the experiments we conducted were done on a single node with a single GPU.
Conclusion
The combination of different models as an embedding layer and the training of a final classifier achieves higher accuracy than the current models individually. This increase in classification accuracy, however, comes with an increase in the inference time. This is due to the forward propagation being executed for multiple models. Additionally, the training process within this method requires data collection and time for the training of the model. When implementing a similar method, one should consider the trade-off between inference time and classification accuracy. Finally, we have significantly improved the initially described problem of low accuracy for classifying many languages.
Furthermore, we can use the method of combining models in a specific domain and training a model on top not only for language identification but also for other relevant applications like image classification. By using this method, we can potentially improve classification performance in other domains as well.
The contents of this blog post are based on a master’s thesis written by Benedikt Augenstein.
References
Bapna, Ankur et al. (2022). “mslam: Massively multilingual joint pre-training for speech and text“. In: arXiv preprint arXiv:2202.01374.
Bartz, Christian et al. (2017). “Language identification using deep convolutional recurrent neural networks“. In: Neural Information Processing: 24th International Conference, ICONIP 2017, Guangzhou, China, November 14–18, 2017, Proceedings, Part VI 24. Springer, pp. 880–889.
Conneau, Alexis et al. (2023). “Fleurs: Few-shot learning evaluation of universal representations of speech“. In: 2022 IEEE Spoken Language Technology Workshop (SLT). IEEE, pp. 798–805.
Mitra, Vikramjit, Daniel Garcia-Romero, and Carol Y Espy-Wilson (2008). “Language detection in audio content analysis“. In: 2008 IEEE International Conference on Acoustics, Speech and Signal Processing. IEEE, pp. 2109–2112.
Radford, Alec et al. (2022). “Robust speech recognition via large-scale weak supervision“. In: arXiv preprint arXiv:2212.04356.
Revay, Shauna and Matthew Teschke (2019). “Multiclass language identification using deep learning on spectral images of audio signals“. In: arXiv preprint arXiv:1905.04348.


