
This article explains the popularity bias in recommender systems and introduces a graph-based debiasing strategy.
When using a web system, you are usually supported by a recommender system. Any content or – more generally – any item that is shown to you is specifically selected by the system. This prevents you from information overload. However, recommender systems frequently face a popularity bias. As a consequence, (biased) recommendations not only pose a threat to the fair representation of items but may also harm the degree of personalization. This article describes the popularity bias and proposes a graph-based debiasing strategy.
Popularity bias in recommender systems
Recommender systems suggest items that are generally tailored to the needs and preferences of target users. To provide recommendations, they mainly use feedback data that users generate while using the web system. This feedback data can be enriched with various side information about items and users.
Let us take a look at the example of a system that recommends tweets on Twitter: a user might have liked tweets about the new football transfers and live results of the Premier League. This explicit feedback can be processed based on item content, e.g. its topic, resulting in recommendations about football. A collaborative filtering approach instead analyses relationships between users by assessing similar rating behaviours – being agnostic to the specifics of the underlying domain. Another user, for example, might like the same tweets as above. But on top, the user engaged with a tweet about the English national team. Now, due to similar preferences inferred from similar feedback, this tweet can serve as a recommendation for the initial user. As recommender systems are in constant exchange with users and update their recommendations based on the given feedback, the process resembles a feedback loop. However, this feedback loop tends to be biased. The continuous exchange with the users not only causes biases that are generally present in humans but also biases that are induced or amplified by the way the recommender system processes the feedback data.
This article will focus on the popularity bias, which describes how popular items are over-represented in recommendations while less popular ones get less exposure. Besides missing fairness of representation, this can also reduce the user experience and harm a user’s trust in the system. When users are already familiar with popular items and in need of more niche as well as novel items, (re-)recommending popular ones is against their needs.
Let us consider Twitter again: tweets from popular users like Cristiano Ronaldo, for example, receive a lot of feedback. This potentially leads to the recommender system classifying his tweets as generally more relevant. It can surely be justified for certain recommendations if Cristiano’s tweets match the preferences of the user. The problem is, however, that Cristiano’s digital reach is not a direct indicator of personal relevance. His popularity deprives other tweets – which might be a better match for a specific user – of the possibility of being determined as relevant. Consequently, the popularity bias decreases the degree of personalization of recommendations and even threatens a fair representation of items. The majority of Twitter users have less than 400 followers, making it hard to get noticed, be seen as relevant and gain reach. Therefore, it is important to consider popularity when designing and developing a recommender system. If the bias is not taken into account, the feedback loop even strengthens and the lack of personalization causes users to lose interest and trust in the web system.
Debiasing strategy
In order to debias a recommender system with respect to popularity bias, I implemented a collaborative in-processing strategy which is based on PageRank – a network analysis algorithm developed by Google Search. The goal of PageRank is to determine the importance of nodes in a network or for a particular node. Thus, the results of PageRank can serve as features identifying relevant users for a model-based recommender system.
PageRank
PageRank utilises the stochastic process of a random walk on a defined graph. Let the random walk start at node \(i\). It either transitions to a neighbouring node \(j\) with transition probability \(\alpha \cdot t_{ij}\) or jumps to a random node in the network with a transition (jump) probability \((1 – \alpha)\), which is set by a chosen damping parameter \(\alpha \in [0,1]\). The jumping vector \(v\) is defined as a distribution over all nodes, where concentrating the whole density on one node would result in a personalized PageRank. Now, the probability of the random walk updates from \(p_k\) to \(p_{k+1}\) is as follows:
\(p_{k+1} = \alpha \cdot \underbrace{T p_k}_{transition} + (1- \alpha) \cdot \underbrace{v}_{jump}, \quad \text{with the transition matrix } T = (t_{ij})_{n \times n}\)
The principle of PageRank can be illustrated in the original context of Google Search whose goal is to find web pages relevant to a given query. The graph consists of nodes representing web pages that are linked to each other via edges. Now, imagine a person who surfs the web and randomly clicks on links to get from one page to another. But sometimes the surfer closes a tab and restarts on an arbitrary page. PageRank simulates this behaviour repetitively. The result is a probability distribution \(p \in \mathbb{R}^{n}\) with \(n\) being the total amount of all web pages and \(p_i\) describes the likelihood that a surfer who randomly clicks on links will land on a particular page \(i\). For math enthusiasts: the probability converges to a stationary distribution of the Markov chain, where states are web pages, and transition probabilities relate to links between pages.
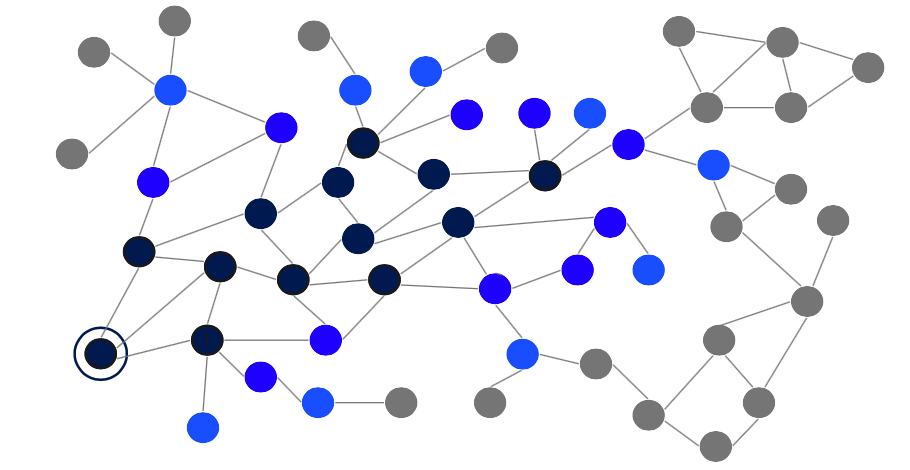
- Figure 1: Personalized PageRank applied to an undirected graph
Fairness-aware PageRank
My proposed implementation is the fairness-aware PageRank (FAPR) which integrates fairness locally by modifying the random walk. To do this, every node in the graph belongs to exactly one group of nodes \([V_k]\), which can be based on popularity. Alternatively, it can also be based on other attributes such as gender, for instance. The method then takes into account the group a particular node was assigned to in order to adjust the transition probabilities according to a predefined fairness policy \(\phi_k \in \mathbb{R}\) for every \([k]\).
The normalized fairness policy assigns a proportion to each group that describes how much of a node’s outgoing transition probabilities should be maximally allocated to the specific group:
\(\phi_k = \sum_{j \in V_k}\tilde{t}_{ij}\)
To clarify this modification, let us return to the example of web pages: whenever a surfer plans to click on a link, the probability of choosing a particular page also depends on the fairness policy. If there are mainly links to pages that are declared as popular, the probability of clicking on popular pages is bounded and the remaining part is shifted to more unpopular pages. But what happens if there are no unpopular pages? In this case, FAPR looks for unpopular pages in the second-degree neighborhood (i.e. using two links to get to this page) and adds new transition probabilities. To calculate these transition probabilities, the weights of the paths that end at nodes of the particular group are aggregated and normalized.
FAPR is a local approach to include fairness and thus every node benefits from the modifications. My implementation also works for weighted edges and uses a customizable fairness policy. The type of node attribute, the number of classified groups, and the corresponding group sizes can be changed individually. Furthermore, I investigated adjusting a larger network compared to the network sizes of previous research works on PageRank modifications.
Data: Twitter’s social network
As part of the RecSys Challenge 2021, Twitter provided a dataset of observed and artificially sampled tweet engagements. One data point contains information on whether a user engaged with a tweet of the authoring user. I concentrated on a collaborative approach without analysing if the engagement can be considered a positive or negative rating. Therefore, I filtered for the engagement types “like“ and “retweet“ as well as for the most commonly used language which can be assumed to be English.
Based on this data, I constructed a graph with nodes representing users and directed weighted edges indicating the number of total engagements between two users. Moreover, I utilized a breadth-first search and selected an induced subgraph. The resulting graph contains 3,697,785 nodes, i.e. users, and 7,254,686 edges. I applied a personalised FAPR where I had to define a fairness policy. Since the challenge proposed a popularity-bias-aware metric using popularity-quintiles based on the number of followers to classify users, I followed this definition of fairness. Thus, every node corresponds to a group \([V_k]\) with \(k \in \{1,2,3,4,5\}\) according to the number of followers with more followers reflecting higher popularity.
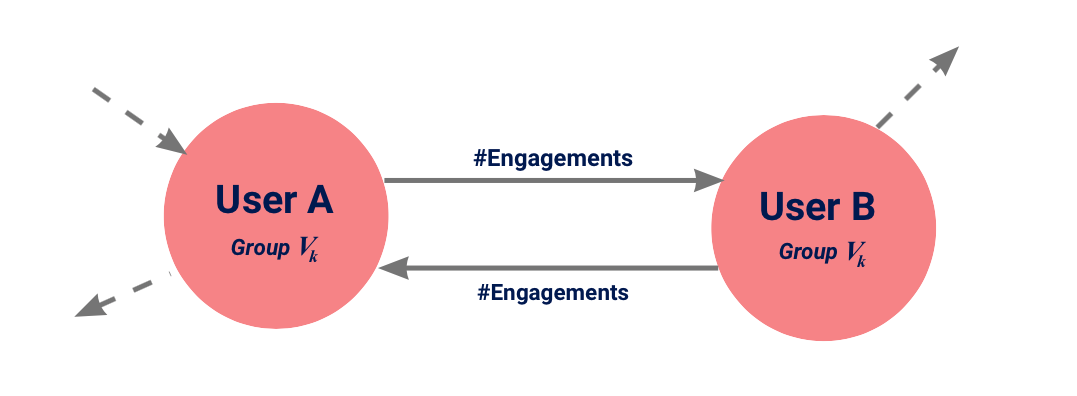
- Figure 2: Every node represents a user and is assigned to a group \([V_k]\). The directed edge indicates the number of “likes“ and “retweets“ between two users.
Results & conclusion
I evaluated my approach by utilising a generalised version of the Gini index (GGI). Some people might remember this metric in the context of income inequality. In general, the index is based on the area of the Lorenz curve which compares the allocation among values of a frequency distribution. In this case, it indicates which portion of the PageRank belongs to which percentage of users ranked by their popularity. GGI ranges from 0, representing perfect equality, to 1 perfect inequality.

- Figure 3: Lorenz curves for the original unconstrained PageRank and the FAPR using a uniformly distributed fairness policy.
Figure 3 reveals the popularity bias: 1 % of the most popular users get 26.7 % relevance determined by the original PageRank. Depending on the fairness policy in FAPR the distribution shifts closer to the grey line that reflects an equal distribution. FAPR influence on relevance distribution is reflected by the orange line which decreases the popularity bias, e.g. by reducing the relevance of the topmost popular percent from 26.7 % to 13.8 %. Furthermore, FAPR improves the GGI significantly from 0.40 to 0.14 towards a state of less concentration.
Integrating fairness means manipulating the actual outcome of PageRank. I tried to investigate the resulting changes to the recommender system. Therefore, I computed the root mean squared error comparing the applied modifications to the unconstrained PageRank. However, it is difficult to analyze the actual decline in the precision of the system, since dissenting or „unpopular“ recommendations may also be relevant to users, although the metric indicates the opposite.
As web systems continue to grow in importance, recommender systems have an enormous impact on users. Therefore, it is essential to recognise unfair influences and to build in measures to gain control over these influences. This is exactly the underlying aim of my bachelor thesis on Fairness in Recommender Systems: Graph-Based Approach to Reduce the Popularity Bias. In conclusion, research in fairness-aware recommender systems starts with awareness and ends with versatile implementations to gain influence over biases.
References
- Baeza-Yates, R. (2018). Bias on the web
- Tsioutsiouliklis, et al. (2020). Fairness-Aware Link Analysis
- Mansoury, et al. (2020). Feedback Loop and Bias Amplification in Recommender Systems
- Bachelor Thesis by Eva Engel: Fairness in Recommender Systems: Graph-based Approach to Reduce the Popularity Bias



Very inspiring work! Just wanted to leave a comment that the math equations don’t display on smart phones, so I get a math equation error message all over the place.
Best,
Marija
Thanks for the info Marija,
we’re already on it! 🙂