
Federated Learning is a novel approach to collaboratively train machine learning models on the private data of multiple participants. It promises to ensure privacy by sharing only model parameters, but not private data. Despite that promise under certain conditions, an adversarial participant is able to execute attacks on privacy and the resulting model. In this blog post, we focus on two attacks: First, reconstruction attacks which are able to reconstruct samples from the distribution of the private training data using the shared model parameters. Secondly, poisoning attacks, which manipulate the training data to deceive the resulting model into misclassifying samples. Combining those two attacks leads to a new, more advanced attack scheme that allows poisoning any arbitrary class even if it is unknown to the attacker. Therefore, we focused on the question if all classes are equally vulnerable to the combined attack approach. If this is not the case, it could be of great interest to protect more vulnerable classes, while it would also be more difficult for an attacker to successfully carry out the attack.
What is Federated Learning?
Machine Learning (ML) is an established method to solve data-driven challenges in all of our daily lives. It is particularly suitable for solving tasks in the areas of computer vision, speech recognition, and natural language processing. Therefore, it requires a huge number of training data to learn the patterns and regularities necessary to solve a task. However, in many cases tasks cannot be solved using ML because they require collecting private data, which the owners are not willing to share because they fear information leakage. While this fear is totally reasonable, Federated Learning (FL) comes to the rescue by allowing to train ML models on private data without collecting it. In FL, multiple participants collaborate in a federated learning setup to train an ML model by only sharing model parameters but not private data.
Assuming for example a scenario where we need to train a reliable tumor detection, which requires many tumor x-ray images. The process of collecting this data from multiple hospitals and getting the consent of every patient makes this process a challenging and sometimes even impossible task because the effort is too high. However, with FL multiple hospitals could collaboratively train a model for tumor detection on their private x-ray images, which results in a reliable prediction for the diseases without sharing their private patient data. This would also allow training the detection of new diseases, like COVID-19, without the time-consuming task of data collection at first. In the same way, credit fraud detection could be trained by a group of banks, without sharing their private credit fraud data. Also, data collected on end devices can be used for FL as they do at Google to train a text-auto-completion on the text input data of smartphone users. Smart homes, autonomously driving cars, and a billion more end devices do collect high-quality but private data in real-time which is spread across end devices and could be made accessible for model training through federated learning. Generally, the principle of FL allows unlocking the potential of distributed private data in many areas by a collaboration of parties from healthcare, the (industrial) internet of things, and companies from the economy.
This blog post does not go into details of FL but assumes you have a basic understanding of the process. If you need a refresher or deeper insights into the topic, you can read my first blog post “Federated Learning: A Guide to Collaborative Training with Decentralized Sensitive Data“ [1].
Reconstruction attacks in Federated Learning
FL promises privacy by only sharing model parameters and no private data. In general, the model parameters shared in FL are not assumed to remember sensitive information, but only the patterns and regularities necessary to solve the ML task. Recent research has shown that it is possible to extract information about the underlying training data from model parameters using reconstruction attacks based on Generative Adversarial Network (GAN) [2]. It can be applied in FL to reconstruct samples most similar to the samples used for training, and therefore also leaks information about the distribution of the underlying private data. Before you start to doubt the privacy in FL, we can give you the all-clear, because the applicability of reconstruction attacks always requires special edge cases to be fulfilled. The reconstruction attack utilizing a GAN thereby assumes that an unsupervised label voting takes place before the training, which is explained later. Therefore, it can be executed by any participant and does not have to take place at the central server, which we assume to be a trustworthy entity. A GAN is a well-known technique to generate new samples from a data distribution normally used for the generation of artificial but realistic data, for example for text synthesis, image generation, or text-to-image translation. In FL, this property is exploited to reconstruct samples that are close to the private training data of a participant. At multi-class models, it can generate samples of a specific class that is of special interest to the application of the poisoning attack. A GAN consists of a generator and discriminator network which are jointly trained on the real data. The generator learns to generate artificial samples while the discriminator judges those samples to be fake or realistic in order to teach the generator to only generate samples that are close to the training data distribution. In FL, an adversarial client executes the reconstruction attack by holding the generator model and training it with the central model as a discriminator. In order to be able to act as a discriminator, the central model needs an additional output for the detection of fake samples. To achieve this adjustment of model architecture, we assume that the number of classes that are present in the data of the participants is unknown. Therefore, before the FL takes place, all participants have to tell the curator the labels they own data off. The curator then designs the central model to have the necessary number of outputs to classify the data of all participants. The adversarial client thereby commits an unknown additional label no participant owns data which is then used to identify fake samples when the central model is used as a discriminator. This hacky application of a GAN in FL allows the generator model to slowly learn how to generate samples of an arbitrary class alongside the FL process.
Poisoning attack in Federated Learning
Another attack scheme applicable to FL is the Poisoning Attack [3]. It aims to purposely mislabel training data in order to confuse the model into misclassifying samples. Specifically, we use it to trick the attacked model to misclassify samples of an attacked class A for a target class T. Concretely, this leads to a model confusing, for example, a digit 1 for a digit 0. In FL, any participant can execute this attack by purposely mislabeling its private training data in order to confuse the central model. Specifically, it could be used to harm competitors, which then suffer from the consequences of false predictions. There is a catch with this attack, which is that samples of the attacked class A must be present at the attacking participant. This limits the area of application to the classes a participant holds samples of. Further, to harm competitors, it could be of great interest to an adversary to attack a class he does not own samples of. This attack scenario has not been possible until now but is made possible by applying the combined poisoning and reconstruction attack as described in the following.
Combined – reconstruction and poisoning – attack
The approach used in this blog post combines the reconstruction and data poisoning attack and is introduced by Zhang et al. in 2019 [4]. The combination of these two attacks allows an adversarial client to attack an arbitrary class without the need of owning training data of it. This is an advancement to general poisoning attacks, which always require the availability of samples of the attacked class. The figure below shows the process of this attack scheme in 5 steps using the MNIST data set. In step 1 the central model is distributed to all participants. Steps 2 and 3 exclusively take place with the adversarial participant. In step 2 the adversarial participant trains the Generative Adversarial Network on the central model, learning to produce samples of class G (in this case the digit 1). In step 3, samples of class G are generated and mislabeled with the labels of the target class T (in this case class 9). The mislabeled data is added to the training data of the adversarial client. In step 4 all clients train their copy of the central model on their local data set. Thereby, the adversarial client uses the modified data set, consequently poisoning the model in its local training round. Finally, in step 5 all models are collected and aggregated by the central curator. These steps are repeated throughout the federated training which ends when the central model achieves a specified accuracy.

The combined reconstruction and poisoning attack has many advantages which make it a powerful attack. First, it does not require the adversarial participant to hold samples of the to be mislabeled class but generates these. In addition, these samples can be used to observe the reconstructed characteristics of an unknown class, but this is out of the scope of this blog post. Second, any participant can execute the attack, and it does not need any additional capabilities in the FL setup except enough computational power to train the Generative Adversarial Network.
Are all classes equally vulnerable to the combined attack?
When applying the combined attack with the described attack scheme, an adversarial client has to choose which combination it aims to attack. It has to specify the class to generate samples depicted as G and the targeted class the generated samples should be mislabeled as depicted as T. When applying this attack scheme on a data set with ten classes, this results in 10 x 10 – 10 = 90 possible combinations. We avoid combinations generating and targeting the same class, which obviously is not in the sense of the attack scheme. With such a huge number of possible combinations, the question arises if all of those are equally vulnerable to the combined attack. If there is a difference in the success of an attack, it could make sense to carefully pick the to-be-attacked class combinations and as a defender to carefully protect those vulnerable classes.
Further to answer this question, we focus on applying the experiments on the MNIST and FMNIST datasets, which contain 10 classes respectively. For both data sets, we evaluate the attack accuracy on all possible combinations, as explained later. At first, we focus on the results of the reconstruction attack, which show that we are successful in reconstructing images from both data sets. The first row shows exemplary generated images of the MNIST data sets containing digits from 0 to 9. All of them are humanely identifiable but are not perfect representations of their represented class. The second row shows the reconstructed samples from the FMNIST data set featuring fashion objects. They are partially identifiable but show a big lack of detail in all representations. While the reconstructed images of both data sets certainly are not perfect in terms of human readability, they are sufficient to poison the central model as shown in the following.

In order to measure the vulnerability of attacking a certain combination, we compute the attack accuracy on a test data set containing data of all classes. It is equal to the percentage of correctly misclassified data of class G as class T:
attack accuracy = number of samples from class 𝐺 classified as 𝑇 / total number of samples in 𝐺
Note: Because of reasons unknown to us, our implementation was not able to induce a poisoning with a steadily increasing attack accuracy. In order to handle the constantly fluctuating attack accuracy over the training process, we only depict the average attack accuracy over the whole training period.
Let’s take a look at the results of attacking all 90 combinations of the MNIST data set. The matrix depicts the average attack accuracy for all combinations averaged over three experiments. We will not go into details of the single results, but illuminate the two insights of this matrix which are: First, it is not the case that a generator and poisoning class can be switched to reach similar or equal good average attack accuracy. This would be visible through a symmetric matrix mirrored at the main diagonal. This is not the case, as there are many combinations that do reach a significantly different attack accuracy from their mirrored counterpart. Second, there is no class that is significantly vulnerable or robust to the combined attack. Rather, there are single combinations that show a better effect of the combined attack in comparison to the other combinations.
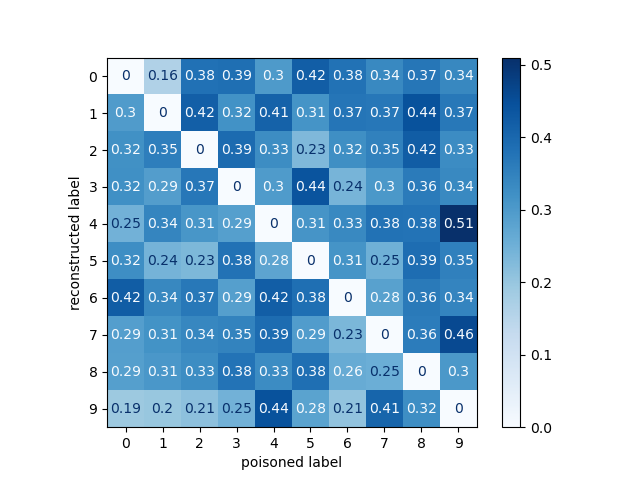
The results of attacking all 90 combinations of the FMNIST data set look similar and confirm the two insights shown by the results from the MNIST experiments. Also, here we will not go into details of the single results, but illuminate the two insights of this matrix which are: First, mirrored combinations do not reach similar accuracy which is shown by an unsymmetrical matrix. Second, there is no class that is significantly vulnerable or robust to the combined attack. Rather, there are single combinations that show a better effect of the combined attack in comparison to the other combinations.

The histogram depicts the average attack accuracy for all combinations and both data sets in direct comparison. It clearly shows that the attack on the MNIST dataset reaches average attack accuracies between 0.2 and 0.5. There is a single outlier that reaches a very high average attack accuracy of over 0.5. Without that outlier, the smooth distribution shows an equal distribution around the mean, but it is clearly shifted to the right to the higher average attack accuracy. The attacks on the FMNIST data set are significantly more scattered between the minimum average attack accuracy of 0.0 up to above 0.55. A significant number of 10 attacks were not successful at all by reaching average attack accuracies under 0.1. A total of 12 attacks reach lower average attack accuracies than the worst MNIST attack. On the other hand, a number of 10 attacks are significantly better than the best MNIST attack when ignoring the outlier. Surprisingly, this comparison shows that the vulnerability of a data set is very dependent on the chosen combination in both cases. Furthermore, in the case of the FMNIST data set, there are extreme cases that show no success at all while others are especially vulnerable to the attack.

Conclusion
This blog post gave an introduction to the combined reconstruction and poisoning attack in FL to furthermore investigate if all classes are equally vulnerable to the combined attack. FL is vulnerable to the reconstruction attack using a GAN and images from the training data distribution can be generated. However, it can only be applied if an additional output can be added to the central model, in our setup by unsupervised label voting. The generated samples then can be used to enhance the scope of the poisoning attack. However, the combination of those two attacks surely widens the scope of applicability, but not necessarily is effective for all class combinations. Depending on the data set and targeted class combination, the results of the attack can show nearly no effect at all or be very successful. This irregularity shows that the combined attack is difficult to be applied in order to achieve maximum effect, especially if the utilized data is widely unknown, as generally is the case in FL.
References
[1] Christian Becker (2020) Federated Learning: A Guide to Collaborative Training with Decentralized Sensitive Data – Part 1 inovex Blog
[2] Hitaj et al. (2017) Deep Models under the GAN: Information leakage from collaborative deep learning – Proceedings of the ACM Conference on Computer and Communications Security
[3] Tolpegin et al. (2020) Data Poisoning Attacks Against Federated Learning Systems – ESORICS 2020: Computer Security
[4] Zhang et al. (2019) Poisoning attack in federated learning using generative adversarial nets – Proceedings – 2019 18th IEEE International Conference on


