
In this blog post, I will show you how we finetuned and evaluated a ResNet pre-trained on generic ImageNet data to a specific use case. I will share the takeaways we gained during our evaluation and reveal how well our optimized document retrieval works in practice.
Convolutional Neural Networks (CNN’s) are on everyone’s lips and are known for their strength in extracting information from images. We at inovex make use of the power of CNN’s as well. In the Service-Meister research project, a document retrieval is implemented using a contextual image search. It aims to support service technicians in retrieving information from manuals by uploading a picture of the affected device. For the image retrieval process, a CNN is applied.
The use case
The topic I am covering with you today is part of the Service-Meister research project, funded by the German Federal Ministry of Education and Research (BMBF). Service-Meister aims to address the increasing diversity and complexity of industrial machines by providing technicians with AI-powered services to support their work. One area of this project is covered by a collaboration of Krohne Messtechnik GmbH and inovex. Krohne offers its customers the possibility to monitor flow rates of water pipes. In this context, one goal of the project is to simplify the maintenance of the applied technical instruments.
This use case deals with the support of a service technician in retrieving information for a Krohne device during a maintenance repair. Due to the variety of different devices and their complexity, the technician is reliant on the usage of manuals. Currently, these have to be searched manually for any defective device and each unknown error message. Since this causes unnecessary effort and downtime, inovex and Krohne Messtechnik GmbH are developing a solution to simplify the process of obtaining information for repairing a device. For this purpose, a service technician can use his mobile device to capture a photo of the affected device or a displayed error code. He can then upload this photo to a search engine implemented by inovex.
An underlying CNN compares the taken photo with pictures from the manual. The most similar image is retrieved and the service technician is directed to the corresponding manual and the page on which the device or error code is shown. Thus, manually browsing the handbooks becomes obsolete. This search can prove particularly helpful when taking photographs of fault messages, damaged parts or error codes. The technician can immediately obtain possible solutions if the corresponding incident is visually represented in the manuals.
What happens under the hood?
So, what is happening if a technician uploads a picture to our search engine? To provide the technician with information about the photographed device, we apply content-based image retrieval. So let’s first cover the basics.
The goal of content-based image retrieval (CBIR) is to extract images from a database that are similar to a given query image. The procedure for doing so is illustrated below.

Convolutional Neural Networks (CNN) are especially suitable feature extractors for CBIR. Rather than using the classification output of the network, the information is taken from a layer prior to the output layer. These vectors contain image descriptive properties and are therefore used as a feature for CBIR.
But back to our use case: Our goal is to provide the technician with relevant information about the captured device. To do this, we proceed as follows:
- Extract the most similar manual image. In advance, a database is created containing the feature vectors of all the images appearing in the Krohne manuals. By performing a content-based image retrieval, the most similar picture to the captured image is selected.
- Return the according manual page. Alongside the device image, its manual page is stored. This information is passed to the technician, who is thus spared from browsing through all the manuals by himself. In the manual, he can retrieve all the information he needs.
The initial situation
The project started by applying an ordinary ResNet152V2 Neural Network pre-trained on ImageNet data for the image retrieval task. ImageNet contains about 1.2 million images of different classes such as dogs, flowers, cars etc. Networks trained on ImageNet data already have very mature features that are suitable for many image-analyzing applications. It is therefore no surprise that the ResNet in use can already handle our image retrieval satisfactorily. But the network is not prepared for the use case in any way.
Finetuning the model
By applying the upcoming optimization strategies, we want to specialize the network for recognizing Krohne devices. We anticipate that this will result in a more accurate and reliable image retrieval.
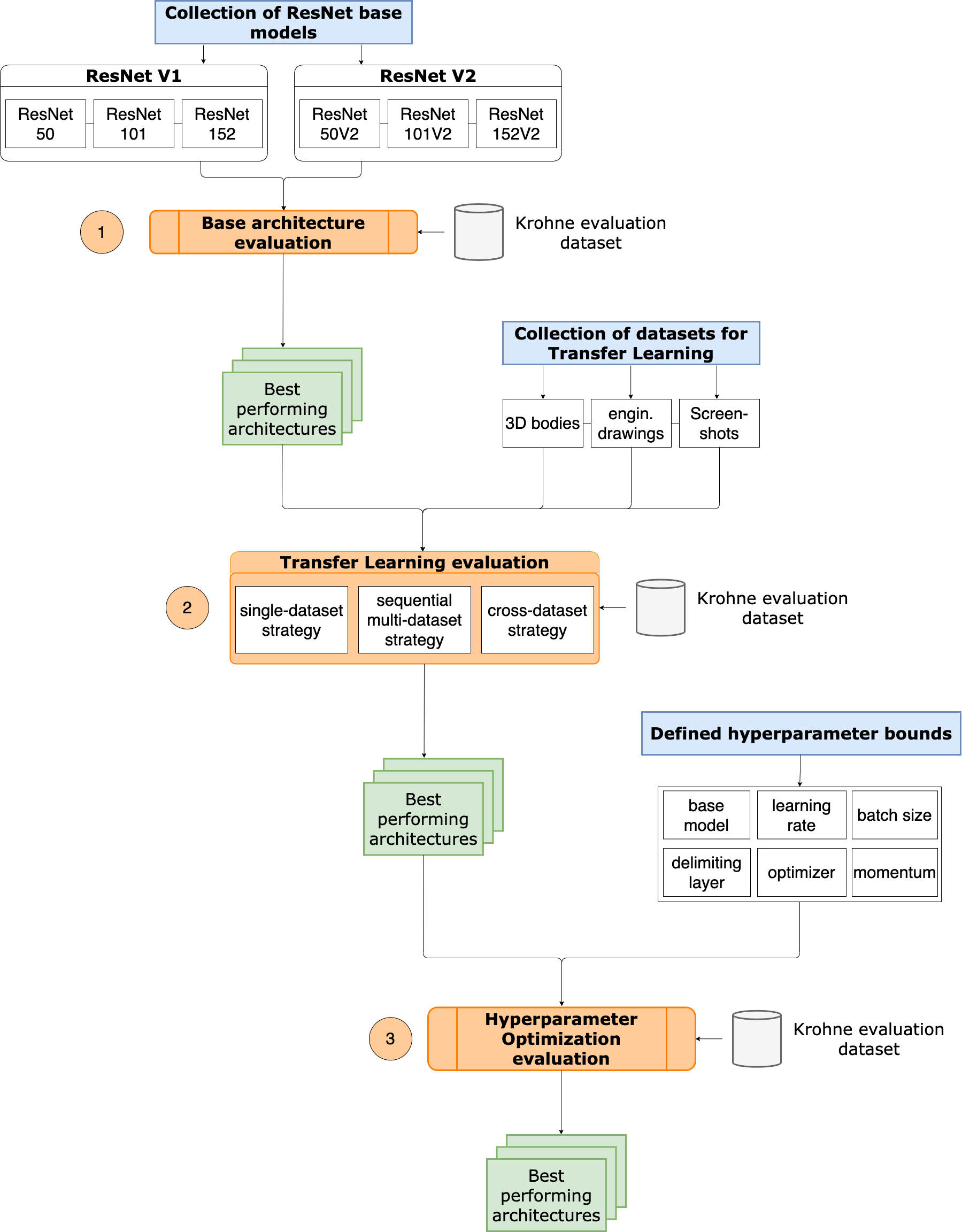
The accuracy of a Neural Network for contextual image retrieval is influenced by the finetuning of the network to the specific application and the choice of suitable hyperparameters. Therefore, we formulated the following roadmap that will be executed step-by-step:
- Choosing a suitable base ResNet architecture
- Specializing the ResNet by retraining on relevant image structures that are expected to occur during the retrieval task
- Performing a hyperparameter optimization for an optimal training environment
So let’s have a closer look at these three optimization steps.
Step One: Choosing an architecture
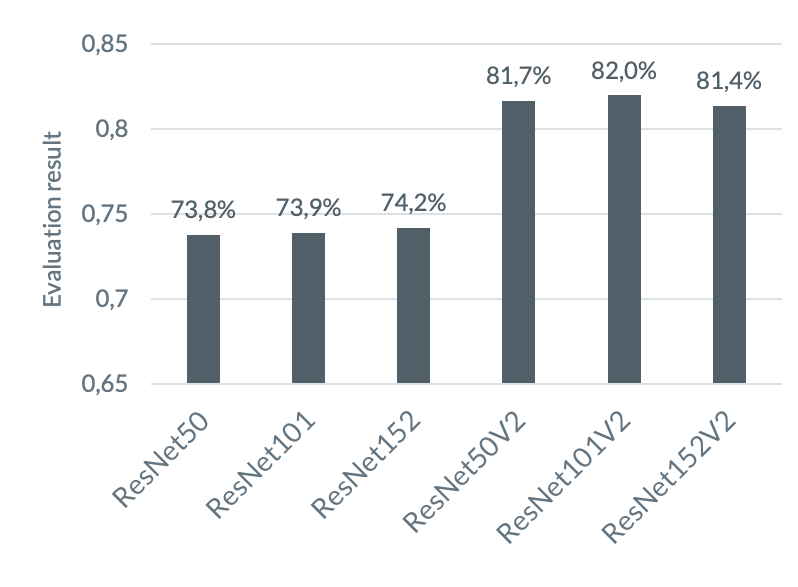
The pre-trained ResNet network forms the foundation for our optimization work should therefore not be chosen at random. The Keras API provides six different pre-trained models for this purpose, namely ResNet50, ResNet101, and ResNet152, in versions 1 and 2 respectively. Simply put, versions 1 and 2 differ in the arrangement of the internal components of a Residual Block – you can check out this video for more details. ResNet101 and ResNet152 increase their complexity compared to ResNet50 by concatenating more Residual Blocks. To find the best performing base architecture, the different ResNets are benchmarked against each other without previous finetuning.
Step Two: Retraining the model
After we found our suitable candidate for the upcoming optimization work, we are all set to start. So far, the neural network is trained on images of dogs, cats, and co. To further push the precision of the vectors, it is advisable to retrain our ResNet on important image structures occurring in the target data [2].
In the end, our ResNet will be used to identify captured photographs of Krohne devices. Ideally, we would therefore train with a dataset that contains such images. Krohne provided us with a dataset that contains all images appearing in their manuals. However, since we will use this dataset to evaluate our models, we had to find an alternative. So we reached out to open-source datasets and attempted to recreate the composition of images that appeared in the manual.
We started by inspecting the Krohne dataset which is divided into 13 classes, each representing an instrument type. You can view samples of it below, where the images are already sorted according to the three categories into which we divided the dataset: 3D objects, engineering drawings and screenshots.

For each of these categories, we searched for a corresponding dataset online. Have a look at snippets of these datasets below.



By training with these datasets, we hope to teach the model to compose complex 3D objects and familiarize it with elements from drawings and screenshots. The datasets are not ideal for this purpose – but for lack of a dataset with images that mimic the later use case, we will work with what we have.
Now it is time to train the ResNet with all three datasets. We came up with the following strategies:
- Single-dataset strategy: A network is retrained to one selected dataset.
- Sequential multi-dataset strategy: A network is subjected to several retraining sessions in consecutive order. Each training targets a different category.
- Cross-dataset strategy: All three datasets are combined into one large dataset and the network is retrained on this cross-dataset.
For the training implementation, we followed well-established Transfer Learning recommendations. When applying retraining, we first behead the pre-trained model and stitch a new, randomly initialized one on top. To avoid the destruction of underlying rich features, the layers with pre-initialized weights are frozen. This allows the brand new head of the network to adapt to the new dataset. Next, the entire network is opened for finetuning all weights. We limit the duration of both steps by applying the Early-Stopping method. After training, the weights of the network are saved for later usage. When training sequentially on multiple datasets, the network subsequently goes through additional training runs using further datasets.
Step Three: Performing a hyperparameter optimization
During retraining, we applied recommended guidelines for hyperparameter selection which allowed us to yield a satisfactory convergence behavior. But to provide our model with the most ideal training environment possible, we should tailor the hyperparameters to our use case. The quality of the parameters is measured by the validation accuracy our ResNet can achieve during training.
Let’s keep in mind that our ResNet will not be used for classification later on. Rather, underlying feature vectors will be extracted to measure the similarity of the input image to the images in our database. Therefore, a high validation accuracy is not necessarily related to an improved accuracy when performing our CBIR task. Nevertheless, we give hyperparameter optimization a try and ask ourselves: Does a higher validation accuracy correlate with a better CBIR result?
To implement our hyperparameter optimization, we rely on Keras Tuner, a framework that lets us specify which variables and which search space we want to examine. We decided to go for an investigation of the following parameters: Learning rate, optimizer, and batch size. In addition, we included the choice of the ResNet base architecture and the so-called delimiting layer which defines the boundary up to which layers will remain frozen when opening the model for weight adjustments. As a tuning technique, we applied the Hyperband algorithm.
tl;dr: Strategy overview
So, let’s roll all of this up in an overall strategy flow that we are going to follow in the course of this study. Take a look at the flow diagram below. First, we determine the ResNet architecture on which we will base our optimization work (1). We then prepare this ResNet trained on ImageNet data for our use case by retraining it on relevant image structures (2). Our Neural Network, once trained on a very broad spectrum, is now specialized to our selected datasets. To find out if we can achieve better results by increasing the validation accuracy of our ResNet, we perform a hyperparameter optimization to boost the effectiveness of our models’ training (3).
Measuring the improvements
To measure whether the optimization work on our ResNet paid off, we developed an evaluation pipeline that reveals how the performance of our ResNet improved. Multiple retrained networks can be benchmarked against each other. So before presenting our results and takeaways, let me introduce you to our evaluation pipeline.
How we measure improvements
For the implementation of our evaluation concept, the dataset provided by Krohne is used. For evaluation, this dataset is divided into two batches (1). The first batch consists of 80 percent of the images. These are used to build a database for each model we want to evaluate. The other batch contains the remaining images and is used to evaluate how reliably the network can extract the matching manual entry.
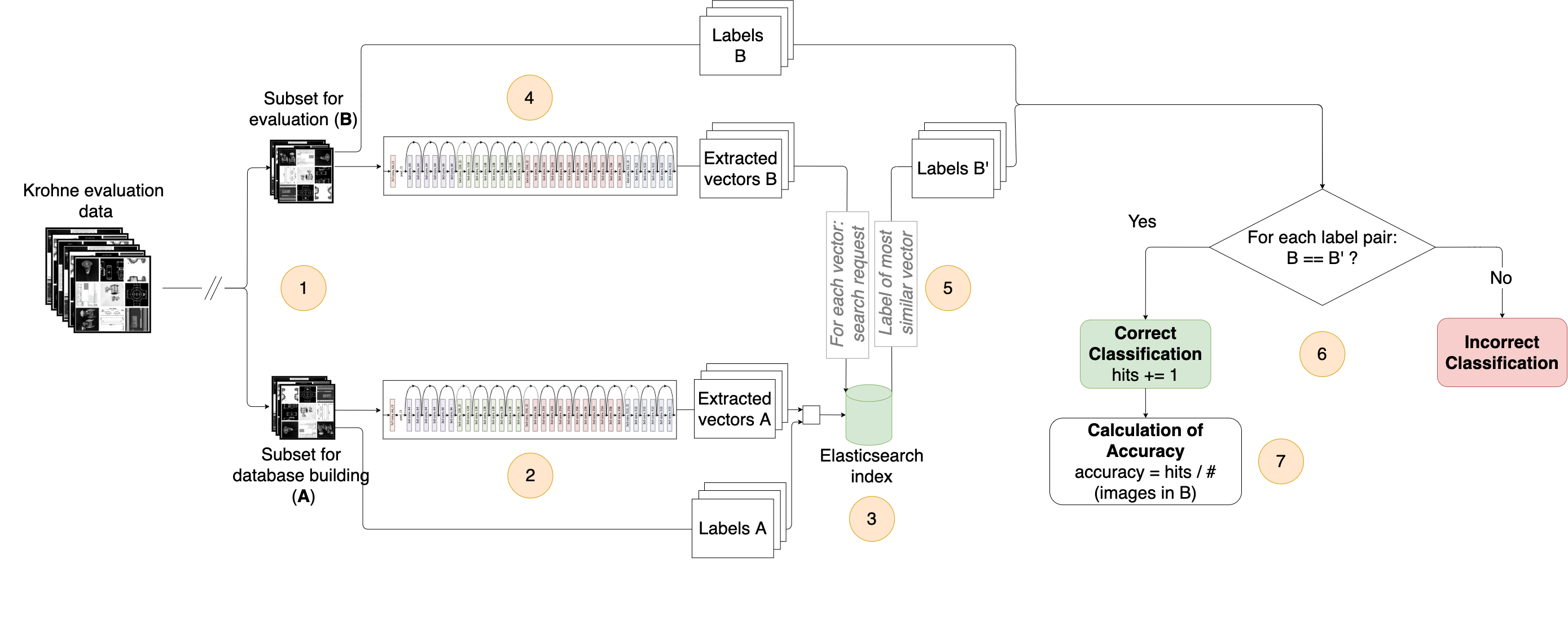
After splitting, the database entries for each model are set. To do so, all images of the corresponding batch are fed into the network, and the vector of the last layer prior to classification is extracted (2) and stored in an Elasticsearch index together with the label assigned to the respective image (3). After creating a separate database for each network, they are presented with the images of the second batch. The resulting output vectors are extracted again (4) and matched for cosine similarity with the vectors stored in Elasticsearch (5). The label that is stored alongside the most similar vector is returned. By comparing this label with the label of the input image, the output of the network can be titled as a hit or a miss (6). After processing all images of the evaluation batch, a hit rate is calculated (7). This value serves as an indication of the accuracy of the network, which we use as a comparison value with the other networks tested.
The entire evaluation process is repeated ten times and an average score is calculated. In each run, the images are reshuffled. This increases the repeatability of the experiment and thus ensures that we can compare multiple evaluation runs.
Evaluation results and takeaways
It is now time to reveal the results and takeaways we gained during our model optimization. We investigated three different factors and determined how they affect the image retrieval capability of our model: The choice of the base ResNet architecture, the choice of datasets for retraining and methods to combine them as well as the effect of hyperparameter optimization on the evaluation results. Overall, an evaluation result improvement of 3.9% could be achieved, leading to an accuracy of 85.3% during evaluation. In the following, I will summarize our insights. All statements refer to our use case and have not been tested for their applicability to other use cases.
1. ResNets pre-trained on ImageNet data are powerful feature extractors
When we exposed pre-trained ResNets without preparing them for their task, they achieved remarkable results. They were able to identify the correct label in up to 82% of all cases.
2. ResNet’s version 2 is superior
As the chart shows, all ResNetV2’s outperformed their predecessors. However, the results of the ResNetV2 networks differ only marginally. Further, our optimization strategies affected all V2 models similarly; accordingly, each V2 model is a suitable choice for our use case.
3. Finetuning a pre-trained network for their upcoming task pays off
We discovered that the accuracy of the network and the similarity between the datasets applied for retraining and the target dataset are positively correlated. As proof of this, consider the graph where we trained our models with only one of our datasets. While training on datasets that contained similar structures to those in the target data increased our models’ performance, totally unrelated datasets such as a collection of dog pictures worsened their accuracy. A training on target data showed the highest accuracy and outperforms all previous attempts due to a maximal similarity between retrained and target data. It should be noted, however, that some images appear twice in the target dataset which could simplify the image retrieval task for this model during evaluation.
Based on the positive correlation found between the image retrieval capability and the similarity between retraining and target data, the network we deployed in our search engine is retrained on the Krohne dataset.

4. If no suitable dataset is available for retraining, use the cross-dataset strategy
We investigated which strategy for training on multiple datasets is superior. Our concern that the sequential training method would lead to a discard of previously learned structures was confirmed. ResNets trained on all three datasets consecutively showed similar behavior to ResNets trained on the last dataset only.
If no dataset can be found that can cover all image categories occurring in the target dataset, different datasets should be collected and shuffled into one dataset. By retraining with a combined dataset, a performance improvement of up to 1.9% compared to training on a single category and an improvement of 2.0% compared to a network pre-trained only on ImageNet data of the same architecture could be measured, validating statement 3.
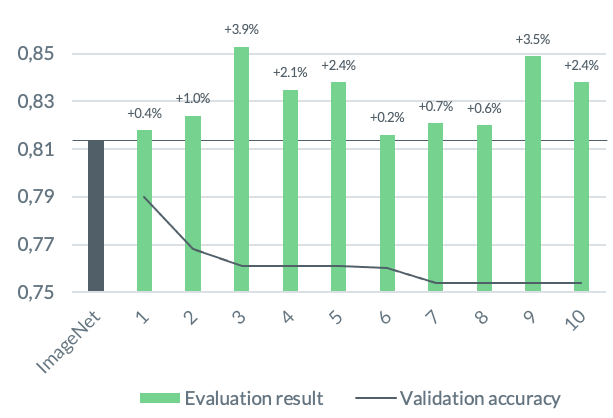
5. An increased validation accuracy does not correlate with a better image retrieval capability (but a hyperparameter optimization might be worth it)
The graph shows the evaluation results of the models that scored the best validation accuracies during retraining, in descending order. You can easily notice that an increased validation accuracy does not correlate with a better image retrieval ability.
Nevertheless, parameter optimization allowed us to identify models with high image retrieval capabilities. The best evaluation result measured in this study (+3.9%) was achieved by a model found during hyperparameter optimization.
And how does it perform in action?
Since our model will not deal with manual images later on but with images from built-in devices, the really important question is: How does our ResNet specialized on Krohne data perform in practice? We already deployed the model in our search engine, so let’s answer this by uploading some test images:
| Input image | Retrieved image(s) |
 |
  |
 |
 |
 |
  |
As you can see, devices with no distracting objects in the background (see examples #1 and #2) are recognized by the model. The extracted images look similar to the captured image. However, note that the extracted device does not necessarily match the exact device that is shown on the input image. Further, if other objects are present, the results indicate that the model cannot extract the device of interest from the image (see example #3). Instead, it considers the entire image context – unfavorable considering that the technician will later shoot an image of a built-in device.
Therefore, we are not yet satisfied with the final result – however, it is quite obvious what our model is struggling with. To support our model in extracting the object of interest, we developed the following approaches:
- Removing irrelevant background details during preprocessing
- Retraining the model with captured photos of built-in devices
We will address these approaches and evaluate if they can further boost the accuracy of our model. Any updates will be shared on this blog – stay tuned!
References
[1] Ryszard S Choras. Image feature extraction techniques and their applications for cbir and biometrics systems. International journal of biology and biomedical engineering, 1(1):6–16, 2007.
[2] Artem Babenko, Anton Slesarev, Alexandr Chigorin, and Victor Lempitsky. Neural codes for image retrieval. In European conference on computer vision, pages 584–599. Springer, 2014.
[3] Wu, Zhirong and Song, Shuran and Khosla, Aditya and Yu, Fisher and Zhang, Linguang and Tang, Xiaoou and Xiao, Jianxiong. 3d shapenets: A deep representation for volumetric shapes. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 1912-1920. 2015.
[4] Eyad Elyan, Carlos Moreno-Garc ́ıa, and Pamela Johnston. Symbols in Engineering Drawings (SiED): An Imbalanced Dataset Benchmarked by Convolutional Neural Networks, pages 215–224. 05 2020.


