For fashion recommender systems, one typically deals with very large and sparse data sets. These characteristics make it especially challenging to build high-quality personalized recommender systems. This article describes the project Graph Learning Based Fashion Recommendations as a part of TUM Data Innovation Lab in collaboration with inovex. The project allowed us – five TUM students with diverse backgrounds – to explore the possibilities of graph learning for fashion recommender systems under the supervision of Frauke Beccard and Lea Petters from inovex. During one semester, we implemented three graph approaches: Random Walk, Graph Embedding, and Graph Neural Network. Finally, we compared the generated recommendations.
Many real-life problems can be represented as a graph – a structure that captures different entities and their relationships as nodes and edges. This allows for a variety of new machine learning models as well as approaches that purely leverage the topology (structure) of the graph. In general, graphs can be useful in a variety of different domains. For example, graphs representing molecular structures can use graph classification algorithms to predict the properties of a molecule. Moreover, node classification algorithms can be used to identify fraudulent nodes in networks. Community detection in graphs can be used to identify clusters in a graph. Thereupon, social networks can use these communities to identify users that share common interests. Finally, Link prediction can be used, in the context of recommender systems, to find possible relationships between certain nodes, for instance, customers and articles.
Why use graphs for fashion recommender systems?
In today’s world, especially online, customers constantly have the choice of which content to consume or which products to buy. The ever-growing number of items that are offered makes it increasingly difficult for users to make a good choice in a reasonable amount of time without assistance. Here, fashion recommender systems can support the customers by proposing suitable articles, e.g., based on purchase history.
The large amount of data that can be used for a recommender system is traditionally modeled using tabular or relational approaches. However, graph-based approaches can help discover interesting relationships or patterns with less effort. For new or unseen data, limited information can be leveraged to connect new nodes to an existing graph.
These factors make graphs very suitable for modeling data in recommender systems. Hence, recommender algorithms that leverage this structure offer a lot of potentials.
Graph architecture
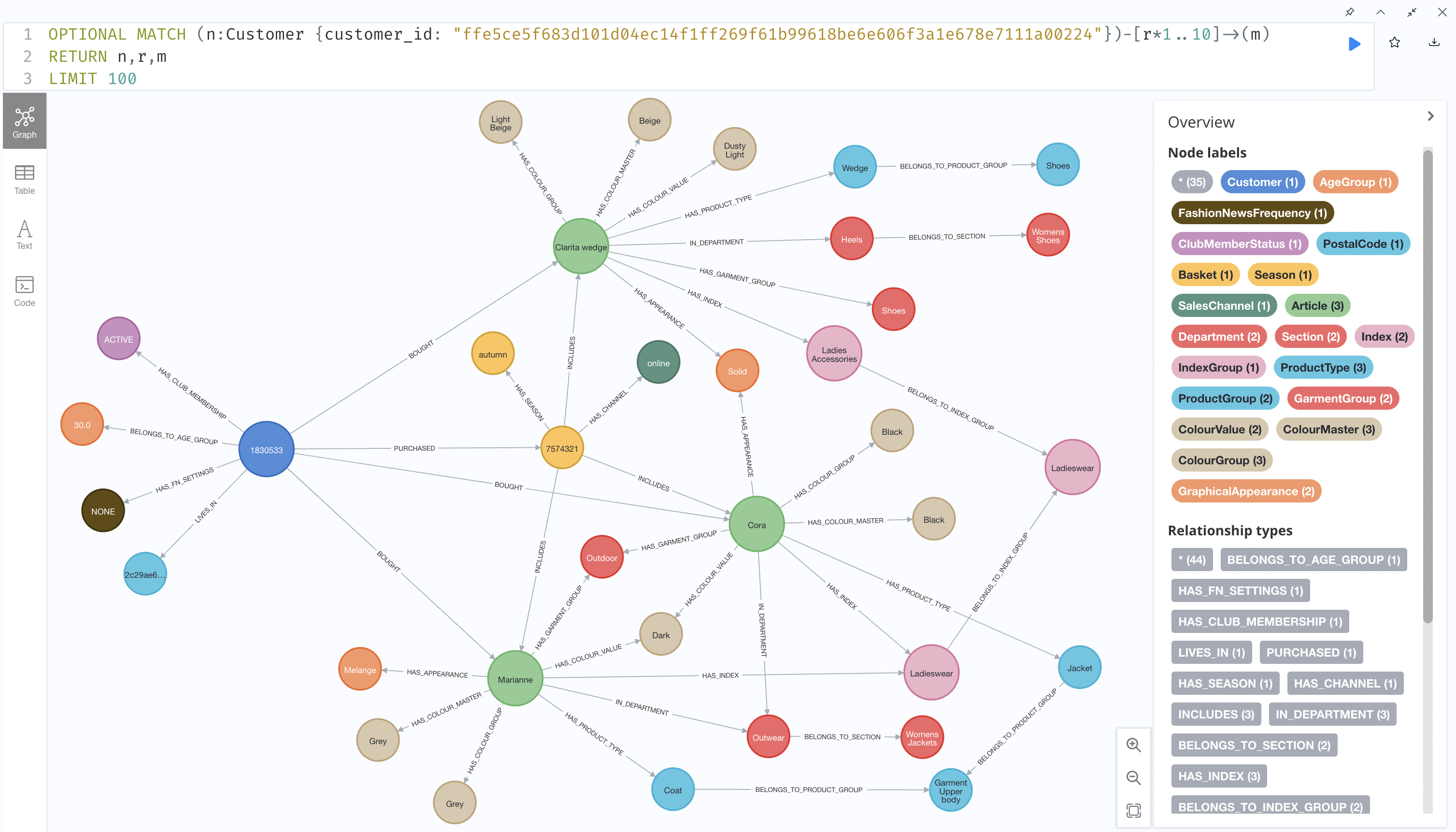
We modeled our data using the following graph architecture where we have multiple entities and relationships around customers and articles. Such networks of entities, attributes and relationships are also known as knowledge graphs.

For implementing the graph, we decided to use Neo4j – an open-source graph database. It provides vast resources in terms of documentation and it comes with a Graph Data Science library (GDS) with built-in functionalities to analyze graph structures. Our final graph ended up having approximately 11M nodes and 80M edges.
How to obtain recommendations using graph-learning approaches?
Random Walk: Leveraging the graph’s topology
In the Random Walk approach, a random walker traverses the graph from a defined start node. The nodes that are visited on random paths contain information about the surroundings of the start node. If we limit the number of steps our random walker takes through the graph, we can gather information about the neighborhood of the start node rather than the whole graph. In our recommender system, we start the random walk from the customer node for which we want to generate recommendations. After a finite number of steps, we get a set of visited nodes. We then filter for article nodes that did not appear in the customer’s purchase history. Finally, the top 10 most visited articles are then recommended and ranked by their visits.
The Random Walk was executed using Neo4j’s Graph Data Science library that comes with an out-of-the-box Random Walk implementation. Executing the Random Walk in the database improves performance significantly, as the communication between the database and the recommender system is very time-consuming.
|
1 2 3 4 5 6 7 |
CALL gds.randomWalk.stream( graphName: String, configuration: Map ) YIELD nodeIds: List of Integer, path: Path |
Graph Embedding: Using a low-dimensional graph representation
Graph Embedding approaches leverage the graph structure or topology to convert nodes into low-dimensional vectors. These vectors, also known as embeddings, reflect the graph structure, meaning that two nodes with similar neighborhoods will be assigned similar embeddings. In order to generate recommendations based on this strategy, we used k-nearest-neighbors (KNN) to get the most similar articles to a customer based on the embedding vectors and their distances. For this approach, we again leveraged the Neo4j GDS library for both the embedding generation and KNN calculation.
For the embedding generation, we used the Fast Random Projection (FastRP) algorithm. The major reason for this choice was that FastRP has a good performance by using sparse random projections. Along with this, it is easily scalable since embedding computation is performed iteratively and it handles limited memory well.
|
1 2 3 4 5 6 7 |
CALL gds.fastRP.mutate( graphName: String, configuration: Map ) YIELD nodeCount: Integer, nodePropertiesWritten: Integer |
Eventually, we used filtered KNN to obtain the final recommendations. Filtered KNN extends the classic KNN allowing us to calculate similarities between specific source and target nodes.
|
1 2 3 4 5 6 7 8 |
CALL gds.alpha.knn.filtered.write( graphName: String, configuration: Map ) YIELD nodesCompared: Integer, relationshipsWritten: Integer, similarityDistribution: Map |
Graph Neural Network: Link prediction using an encoder-decoder architecture
Graph Neural Networks (GNN) are machine learning techniques that optimize for a task (e.g. classification, regression) leveraging data graph structure. They create vector embeddings for all the nodes in a graph, using operations known as graph convolutions. In the end, neighborhood-aware embeddings, which capture knowledge from nodes and relationships, are created and can be used to perform different tasks such as node classification, graph classification, or, as in our case, link prediction. We predict the probability that an edge exists between a customer and an article, in other words, the probability that the customer will buy that article.
Model architecture
The common architecture to perform link prediction between two nodes in a graph is using their embeddings as an input to a regular neural network, which outputs a probability (i.e. edge probability) that the two nodes are connected.
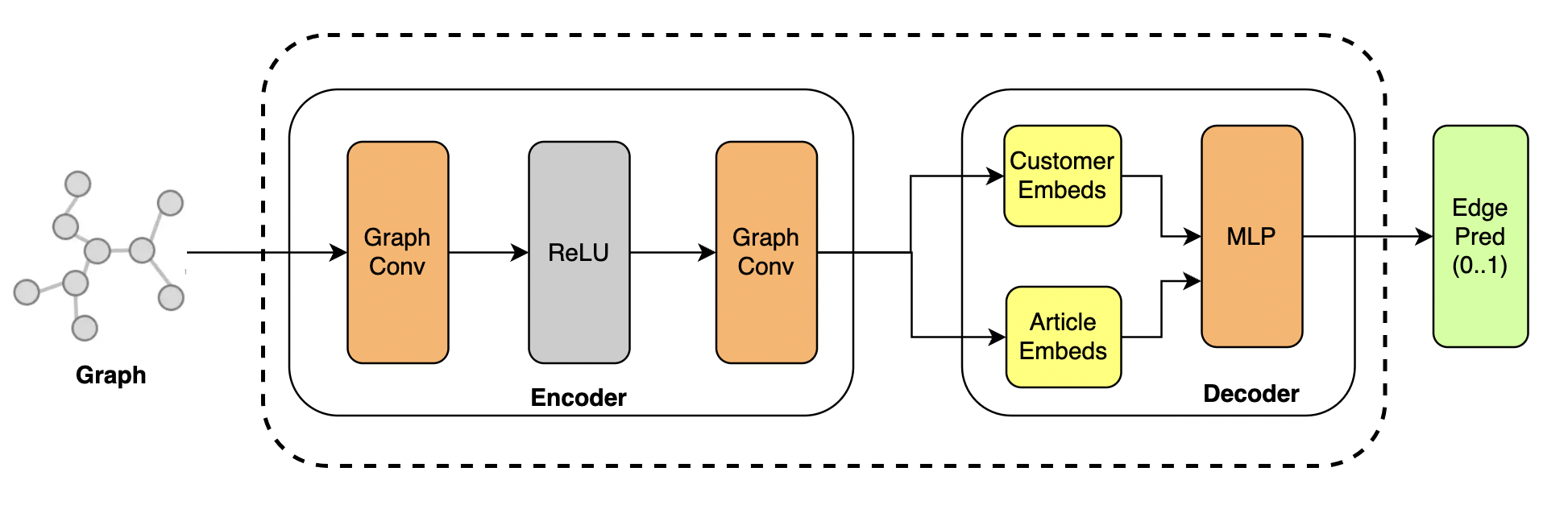
Multiple components can be configured in this architecture. The one that has the biggest influence on the performance is the graph convolution type that creates neighborhood-aware embeddings. In general, graph convolutions implement an iterative process called message passing so that for each node: 1) information from neighbors is collected, 2) this information is aggregated, and finally, 3) the node embedding gets updated. One type of graph convolution is GraphSAGE, which is characterized by two factors: neighborhood sampling and learnable aggregation functions. GraphSAGE convolutions do not use all the node’s neighborhood to compute embeddings, but rather a sample of it, making the overall message-passing process faster and scalable when dealing with large-scale graphs. On the other hand, using learnable aggregation functions, instead of regular operations (e.g., mean or sum), improves the generalization power. Considering these factors and the scale of our graph, we considered GraphSAGE the most suitable choice when implementing our GNN approach.
Implementation with PyTorch Geometric
For building the model we used PyTorch Geometric, which is a library based on PyTorch specifically for graph structures. It supports building both homogeneous and heterogeneous graphs, and it has built-in GNN operators such as GraphSAGE. Furthermore, it offers functionalities for mini-batching and random sampling for link prediction, which also supports negative sampling.
Our GNN was trained with computational resources from the Leibniz Supercomputing Centre (LRZ). Furthermore, we used an NGC docker container from NVIDIA and customized it with our specific package versions. The training was executed on a DGX A100 GPU from NVIDIA with 80GB Memory. After training, the model binaries were used to obtain recommendations in our main recommender pipeline.

How does a prototypical graph-based recommender service look like?
In order to demonstrate what a prototypical recommender service could look like, we implemented a web application by using the open-source web framework streamlit (see here for a demo of the service). Recommendations in our web application were obtained by communicating with two Neo4j databases.

The application database was used to receive content related to customers (e.g. status, membership, postal code) and articles (e.g. name, description, image URL). All image URLs associated with an article in the database pointed to an Object Storage where the image files were stored. In addition, the training database was used to run the graph algorithms with enough resources in order to generate recommendations for the Random Walk and Graph Embedding approaches. Specifically for GNN-based recommendations, model binaries were included in the application. These binaries contained the trained model and pre-computed node embeddings for faster inference.

Finally, we could visually compare the three approaches. For example, here are the recommendations for a random customer.



Conclusion
In conclusion, graph-based approaches offer a lot of potential for building recommender systems, especially for fashion, where large and sparse datasets make it challenging to develop personalized systems. By representing the data as a graph, interesting relationships and patterns can be discovered with less effort and new or unseen data can be easily incorporated. We explored and compared three graph-based approaches, namely Random Walk, Graph Embedding, and Graph Neural Network. Each approach utilized different techniques to leverage the graph structure, such as traversing the graph with a random walker, converting nodes into low-dimensional vectors, and creating neighborhood-aware embeddings using graph convolutions. These approaches were implemented using Neo4j and its Graph Data Science library and PyTorch Geometric. Overall, graph-based approaches have great potential for building fashion recommender systems.


