Kafka Connect Plugins are a way to extend Apache Kafka in order to get data into a Kafka Topic or to extract data from it.
There are a lot of out-of-the-box Sink and Source Connectors. Most of them capture some data input from off-the-shelf software like databases and write the captured data back to another storage or database. But sometimes the out-of-the-box solution does not fit your specific needs. For such cases, Kafka offers the possibility to write your own Kafka Connect Plugin. In the following article, we will show you how such an individual Connect Plugin can be implemented.
About Kafka Connect
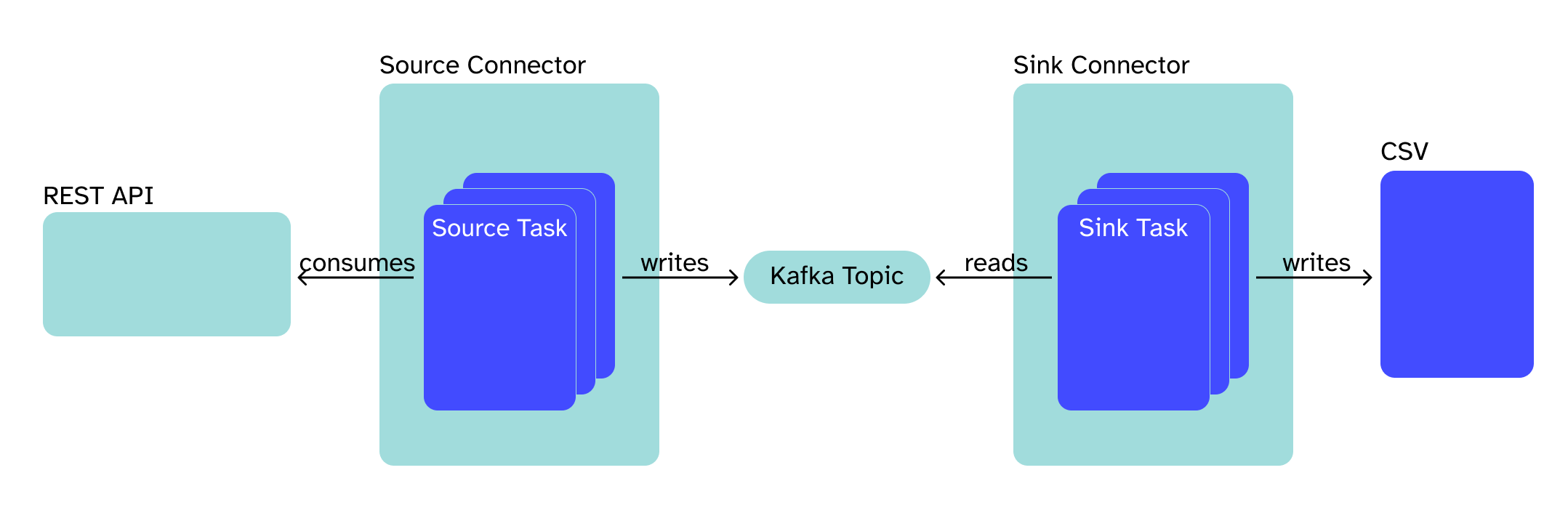
Kafka Connect is used for streaming data between Kafka and other external systems. In order to get data into a Kafka Topic so-called Source Connector can be used. It captures the data in a continuous manner and writes to a Kafka Topic while keeping track of the already read data.
One can compare a Source Connector with a Kafka Producer. By using a Sink Connector one can read data from a topic and write it into an external data system like a database. Hereby the connector also keeps track of the written data. A Sink Connector acts like Kafka Consumer. Both Source Connector and Sink Connector form a Kafka Consumer Group.
Introduction to the use case
In light of the Volkswagen emission scandal in 2015 it was discovered that in many cities in Germany, the air was highly polluted with particulates. Some of these cities were enforced by courts to take action to reduce these emissions. Therefore some cities closed their roads to vehicles with very high emissions. Due to that a very heated debate was held in politics and media.
In one of these cities, namely Stuttgart, the automotive capital of Germany, the public questioned whether banning cars helped to reduce emissions or not. In order to give an answer to this question a local initiative developed easily buildable open-source sensors. The public was encouraged to build and install these sensors outside their homes. The local initiative also provides the infrastructure to collect data from these sensors. The collected data is publicly available via an API.
In this blog post, we will make use of this API in order to demonstrate the functionality of Kafka Connect. Hereby we will show how to implement a Source Connector which retrieves data from the aforementioned API in a periodic manner. That Source Connector will send the data to a Kafka topic which then will be consumed by a Sink Connector. This Sink Connector aggregates the data from that topic and writes it to a CSV file on an hourly basis.
The Sensor API
The sensor API provides an endpoint that returns all sensor data of the last five minutes for a given location. The location is given by a bounding box, i.e., a rectangular area defined by two geo coordinates. In addition, the data can be filtered by sensor type.
The API will return a JSON list with the sensor values and additional information:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 |
[ { "sensordatavalues": [ { "id": 32029110016, "value_type": "P1", "value": "15.90" }, { "id": 32029110177, "value_type": "P2", "value": "10.18" } ], "timestamp": "2023-02-23 15:11:59", "location": { "exact_location": 0, "longitude": "8.394", "country": "DE", "latitude": "48.984", "id": 62686, "indoor": 0, "altitude": "115.9" }, "sampling_rate": null, "id": 14284695600, "sensor": { "sensor_type": { "manufacturer": "Nova Fitness", "name": "SDS011", "id": 14 }, "id": 38865, "pin": "1" } }, ... ] |
For the city of Karlsruhe, the data can be retrieved by this URL.
Implementation
Kafka Connect Source Connector Implementation
To develop a custom Source Connector, we have to extend the following classes from the Kafka Connect library:
The SourceTask class is responsible for writing the desired data into a configured Kafka Topic. In order to do so, the poll() method needs to be provided. Within this method, the data has to be retrieved and provided as a List of SourceRecords to Kafka. Within our example, the AirQualitySourceTask extends the SourceTask class. The poll() method here calls the Sensor API (see above) and transforms the incoming data into SourceRecords.
The poll() method is called by Kafka in a constant manner. In order to avoid too much load on the API, we wait between two calls for four minutes (see DataService class for details).
The SourceConnector is the main entry point used by Kafka Connect. It receives the connector config from Kafka and is responsible for providing task configurations for the SourceTasks. The AirQualitySourceConnector class is used to provide a SourceConnector class.
Internally, the AirQualitySourceTask initializes an AirQualitySourcePartition for every location in its task configuration. The AirQualitySourcePartition keeps track of the source partition and its current offset and ensures that no duplicate sensor readings are created. By this, the AirQualitySourceTask is able to retrieve the last captured ID from the API in case of a failure.
In addition to the classes mentioned before, the AirQualitySourceConnectorConfig (implementing the AbstractConfig) defines the configuration needed by the Source Connector and is used by Kafka Connect to parse the connector JSON config. This allows Kafka Connect to pass the connector config to the connector as a Map.
Tasks and source partitions for parallelizing
As explained in the section above, a Source Connector can execute multiple tasks for parallel ingestion. To parallelize our requests to the Sensor API, we allow the Source Connector to be configured for multiple locations. This allows us to distribute the locations among multiple tasks, thus reading sensor data in parallel.
In the configuration for the Source Connector, we specify a list of comma-separated locations. A location consists of the lat / long value of the first geo coordinate, followed by the lat / long values of the second coordinate. The example below shows the configuration of Karlsruhe, Stuttgart, and Cologne:
|
1 2 3 4 5 |
name=airquality_source_connector connector.class=de.inovex.airquality.connector.source.AirQualitySourceConnector tasks.max=2 topics=topic1 locations=48.949;8.265;49.086;8.513,48.755;9.130;48.828;9.249,50.964;6.911;50.899;7.039 |
Every configured location for which we retrieve data represents a source partition. The number of locations gives us the maximum level of parallelism. We implement this using the taskConfigs function, which receives the maximum number of tasks and creates configs for every task:
|
1 |
public List |
We create task configs by simply copying the existing connector config. We only modify the locations string such that each location is contained in exactly one task config. The Kafka Connect library already provides the convenient helper function
groupPartitions(List
|
1 2 3 4 5 6 7 8 9 10 11 |
@Override public List return ConnectorUtils.groupPartitions(config.getLocations(), maxTasks).stream() .map(l -> createTaskConfig(l)).collect(Collectors.toList()); } private Map HashMap taskConfig.put("locations", String.join(",", locations)); return taskConfig; } |
One element of the list returned by the taskConfigs(int maxTasks) method corresponds to one SourceTask which is spawned by Kafka.
In our example, we have set maxTasks to 3 so that one SourceTask is responsible for one location. This value depends highly on the source your connector shall capture and the resources of the server where your Kafka Connector shall run.
Retrieve sensor data seamlessly with source partitions and offsets
The Sensor API always returns all data of the last five minutes. If we query the API after this time, we will lose records. On the other hand, if we query after two minutes already, we will receive duplicates, as the querying window overlaps.
To avoid this, we can use the concept of source partition offsets. For every source partition, we define the offset as a tuple of the ID and the timestamp of the sensor reading. When sending a record to Kafka in the Source Connector, we also give this source offset to Kafka Connect which will store the information internally. We also set the offset in our task.
The next time we query the API, we simply ignore all records up until the sensor reading with the ID and timestamp given by the last offset. This way, we avoid both missing records and duplicates.
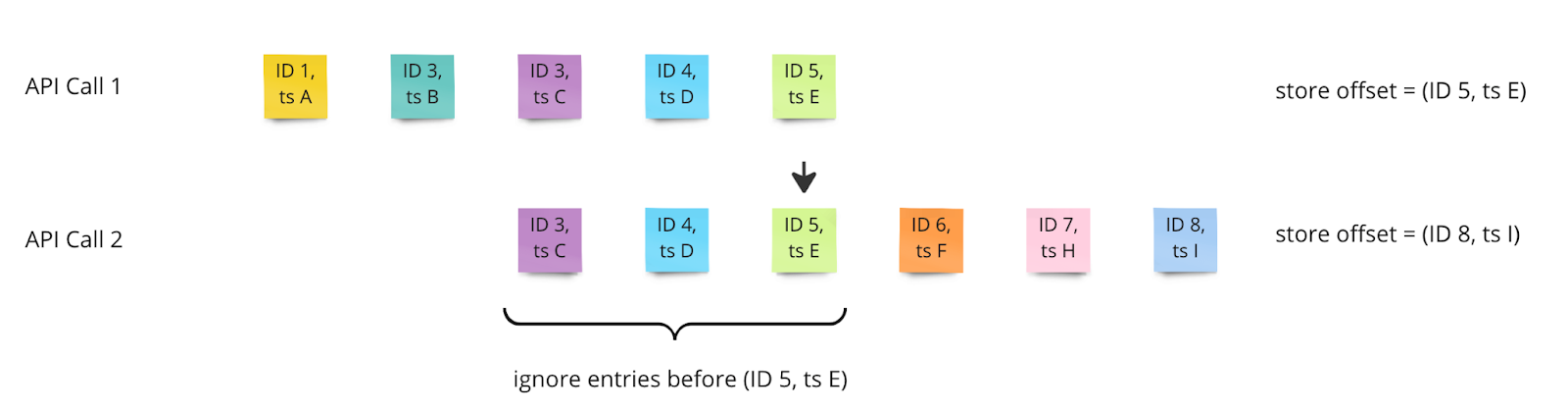
Kafka Connect provides the last offset to the connector task, so we can access this information even if the connector is restarted and the tasks are initialized.
Kafka Connect Sink Connector Implementation
For the custom Sink Connector, we implement the following classes:
In the AirQualitySinkTask (implementing the SinkTask class) the put() function defines what shall be done once records are read from a topic. The preCommit() function defines how and when offsets can be committed.
The AirQualityCsvFileWriter (uses an opencsv CSVWriter) is used to open a file and write out the data in the correct CSV format.
The AirQualitySinkConfig (implementing the AbstractConfig) creates a very basic config with Kafka’s configDef().
The AirQualitySinkConnector (implementing the SinkConnector class) gets called when deploying the Sink Connector. In this all other classes are collected. The AirQualitySinkConfig gets created in start() , the AirQualitySinkTask gets returned in taskClass() and it can be defined what should happen when the connector stops in stop() .
Write data to CSV files
In the task the object topicDateHourWriter is defined. It saves all FileWriter per hour per topic-partition as we want to write one file per hour.
In the put() method for each record a new hour-to-FileWriter-map is created in topicDateHourWriter if it does not exist yet.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
public class AirQualitySinkTask extends SinkTask { ... @Override public void put(Collection logger.info("Start put"); for (SinkRecord record : records) { // get topicPartition from record and add if not seen before final TopicPartition topicPartition = new TopicPartition(record.topic(), record.kafkaPartition()); Map topicPartition, tp -> new HashMap<>()); ... } ... } |
After some casts, we write the records to the CSV file. Finally, we save the latest offset per hour.
|
1 2 3 4 5 6 7 8 9 10 |
dateTimeHourWriter.computeIfAbsent(dateTimeHour, k -> { try { return csvWriterProvider.get().dateTimeHour(dateTimeHour).build(); } catch (Exception e) { throw new IllegalStateException(e); } }).write(sensorData); // put the latest processed offset in latestOffset latestOffset.put(dateTimeHour, record.kafkaOffset()); |
Committing offsets
For the
preCommit() function we need to define which offsets (records) can be committed. Since we want to write one file per hour only offsets of past hours can be committed.
To achieve this the first thing we need to do is to get all hour-to-FileWriter-maps of past hours.
|
1 2 3 4 5 |
// write csv when full hour changed, iterate over dateTimeHourWriter // get writer from past full hours Map .filter(e -> e.getKey().isBefore(currentHour)) .collect(Collectors.toMap(Map.Entry::getKey, Map.Entry::getValue)); |
Then we need to get the latest offset of the latest past hour.
|
1 2 3 4 5 6 7 8 9 10 11 |
// get latest hour of past data Optional // if no pastHour available there is nothing to commit if (lastPastHour.isEmpty()) { logger.info("Nothing to commit"); continue; } // get latest offset from latest past hour Long lastCommitableOffset = latestOffset.get(lastPastHour.get()); |
This is the latest offset we can commit, so we return this as commitableOffset. Before returning we can also close all writers of past hours.
|
1 2 3 4 5 6 7 |
// this offset is the last to commit commitableOffset.put(topicPartition, new OffsetAndMetadata(lastCommitableOffset)); // close all finished writers for(CsvFileWriter writer: pastDateHourWriter.values()){ writer.close(); } |
Conclusion
In this post, we have shown you how you can build your own Kafka Connect Plugin. Compared to just using Consumers and Producers to read and write to/from external resources Kafka Connect offers a sophisticated way to handle parallelization (by SourceTask and SinkTask classes) and operations.
If you want to try this out yourself check out the Readme in the Repository and run the Connectors in a Docker container.


