
This article examines the application of Machine Learning models to predict software vulnerabilities in source code based on its graph representation. For this purpose, two different approaches are used for learning graph embeddings of source code in the context of an appropriate classification to distinguish vulnerable and non-vulnerable code samples. The first approach is based on graph2vec followed by a Multilayer Perceptron, while the second approach involves the use of Graph Neural Networks. We compare both approaches on the Draper VDISC dataset.
Developing software systems is costly as software engineers have to handle the complexity of software development and deliver highly functional software products on schedule while at the same time avoiding bugs and vulnerabilities. A software vulnerability is a fault or weakness in the design, implementation or operation of software that can be exploited by a threat actor, such as a hacker, to perform unauthorized actions on a system [1]. Different analysis techniques are applied to detect vulnerabilities in source code during development, such as static and dynamic analyzers [2]. However, both static and dynamic analyzers are rule-based tools and thus limited to their hand-engineered rules [3]. Moreover, these tools cannot handle incomplete or incorrect information very well – data that does not have an associated rule will be ignored [4]. The use of Machine Learning (ML) is the key to the intelligent analysis of huge amounts of data and the development of the corresponding intelligent and automated applications. A useful property of several ML systems is that they can detect „hidden“ features that are not obvious to a human to include in a rule-based tool [5]. This in turn has opened the door for many different contributions in the field of software vulnerability analysis and detection using ML [6].
Methodology
For source code to be processed in an ML model, a conversion into mathematically processable objects is required. There are different ways to represent a source code as well as different techniques to create mathematical representations that can be fed into ML models. This blog post focuses on graphical representations of source code that capture comprehensive program syntax, structure and semantics. Figure 1 shows the individual steps of two possible approaches for binary classification of vulnerability source code using ML before going into detail in the next section.

As usual, a training data set of the source code has to be pre-processed, i.e. outliers are removed and it is checked for plausibility and blanaciousness of the classes before it is finally put into a form suitable for further steps. Since we focus here on graph representations, the source code is then transformed into a graph form by means of so-called Abstract Syntax Trees (ASTs).
In order to generate graph embeddings from the extracted ASTs, two different approaches are considered. The first approach follows a transductive method [7], specifically graph2vec, which first takes a graph as input and transforms it into a lower dimension of an embedding vector. Then, a classical binary classification model (1: vulnerable, 0: non-vulnerable) such as a Multilayer Perceptron (MLP) is applied to this embedding vector. The second approach follows an inductive method [7], specifically a Graph Neural Network (GNN), which can be applied directly to graphs and provide an end-to-end capability for node-, edge- and graph-level embedding and prediction.
Experimental Evaluation
Since this blog post compares both approaches mentioned, we address all individual steps and their experimental settings in the following.
Draper VDISC Dataset
For evaluation, the Draper VDISC dataset is used, which contains 1.27 million synthetic and real function-level samples of C and C++ source code. The dataset contains different types of Common Weakness Enumeration (CWE) that are summarized in Table 1.
Table 1: Vulnerability types in the Draper VDISC dataset and its frequencies.
| CWE ID | Frequency | Description |
| CWE-120 | 38.2 % | Buffer Copy without Checking Size of Input (‚Classic Buffer Overflow‘) |
| CWE-119 | 18.9 % | Improper Restriction of Operations within the Bounds of a Memory Buffer |
| CWE-469 | 2.0% | Use of Pointer Subtraction to Determine Size |
| CWE-476 | 9.5 % | NULL Pointer Dereference |
| CWE-Other | 31.4 % | Improper Input Validation, Use of Uninitialized Variables, Buffer Access with Incorrect Length Value, etc. |
Data Preprocessing
Data preprocessing is required to fix the imbalanced dataset, which is crucial to achieve good classification results. The imbalanced dataset is fixed by creating per-vulnerability models to be trained only on samples containing the same vulnerability type to measure the detectability of different vulnerability categories on equal terms. Thus, undersampling is applied to make the number of vulnerable and non-vulnerable samples equal.
In addition, the retrieved balanced dataset is divided into training, validation and testing subsets (80% / 10% / 10%) as is common in practice. This is a necessary prerequisite to get an overview of the generalisability of the ML model and to evaluate it effectively.
Abstract Syntax Tree
The data structure of an AST is of the type tree, representing the semantic structure of a source code written in formal language. Each node of the tree represents a construct that occurs in the source code [8]. In the second step of the approach, the AST of the source code is generated, which is achieved by using a parser called Clang, available in the clang index library (Cindex). Figure 2 shows an example of source code from the Draper VDISC dataset with its generated AST using the Clang parser. In this AST, each node denotes a component class for the C language family.
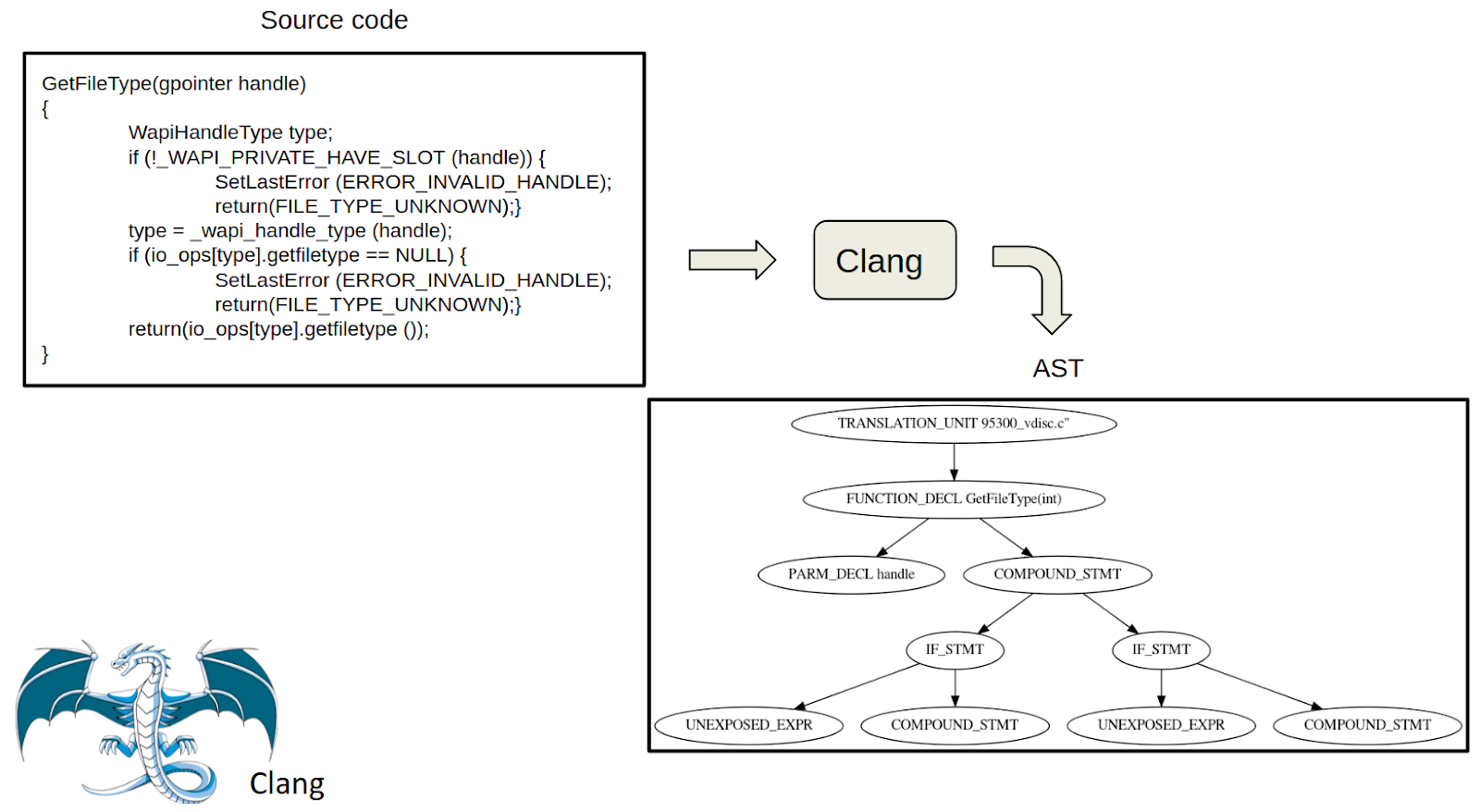
The denotation starts with the name of the code sample and then defines a function declaration, i.e., „FUNCTION_DECL“, which is the main function of that code sample. This main function has two children or sub-functions, the first one is a parameter declaration „PARM_DECL“ and the second one is a compound statement „COMPOUND_STMT“ which is a combination of two or more simple statements. IF statements are denoted as „IF_STMT“. Unexposed expressions „UNEXPOSED_EXPR“ refer to expressions that have the same operations as any kind of expression and whose location, information and children could be extracted, but whose specific kind is not exposed through this interface.
Next, we build graph representations based on structural features of extracted ASTs such as connections, indices and degrees of each node in an AST. For instance, the extracted AST representation from Figure 2 is as follows:
{„edges“: [[1, 2], [2, 3], [2, 4], [4, 5], [5, 6], [5, 7], [4, 8], [8, 9], [8, 10]],
„features“: {„1“: 1, „2“: 2, „3“: 0, „4“: 2, „5“: 2, „6“: 0, „7“: 0, „8“: 2, „9“: 0, „10“: 0}},
where
edge = [start node, destination node]
feature = {“node index“ : degree}.
Here, the degree indicates the depth of the node, i.e., the number of children each node has.
Graph2vec
Graph2vec is a neural embedding framework that enables learning graph embeddings in an unsupervised manner. The embedding captures the structural similarity of graphs, i.e., embeddings with structurally similar graphs are close to each other in vector space. The basic idea of graph2vec is inspired by the neural document embedding doc2vec, which exploits the composition of words and word sequences in documents to learn their embeddings based on training skip-gram models. In graph2vec, this approach is extended by considering the entire graph as a document and the rooted subgraphs (comprising a neighborhood of a certain degree) around each node as words that compose the document.

In this experiment, we use the graph2vec model to create embedding vectors of size \(128\) for each graph.
Multilayer Perceptron
After the embeddings are generated, classical ML models can be applied to predict a vulnerability (1: vulnerable, 0: not vulnerable). In this experiment, we use an MLP. However, this can also be replaced by other classification models such as a support vector machine or logistic regression. For training, the generated embedding vectors and the corresponding labels are fed into an MLP model containing three linear layers as visualized in Figure 4. As the embedding is of size \(128\), the input layer has \(128\) neurons followed by a ReLU activation function. Then, a hidden layer with the same characteristics follows. The output layer consists of a single neuron with a sigmoid activation function to predict a value between \(0\) and \(1\), that represents the probability that an instance belongs to the positive class (vulnerable).

For training the MLP model, an Adam optimizer with a starting learning rate \(0.01\) and the binary cross entropy (BCE) loss function are used. In addition, a form of early-stopping is applied during the training process in order to prevent the model from overfitting the data and becoming too complex. This regularization method is configured to stop the training if there is no improvement in the validation loss after \(5\) epochs.
Graph Neural Network
As an alternative to the 2-step approach (graph2vec + MLP), we use a GNN for classification in this experiment. The GNN framework is a deep learning model for integrated node-, edge- and graph-level embedding as well as prediction. The main advantage of a GNN is that it uses a form of neural message passing where vector messages are exchanged between nodes and updated using neural networks. The architecture of the GNN used in this experiment is shown in Figure 5.

The GNN takes a graph as input and computes its node-level embedding with an embedding size of \(128\) by applying three graph convolutional layers (GCNConv) with three ReLU activation functions. As a result, each node learns features from its three-hop neighborhood and creates its embedding vector. In order to create embedding at graph-level, two pooling layers are applied. The first layer is a global mean-pool layer which provides graph-level-outputs by averaging node features across the node dimension. The second layer is a global max-pool layer which provides graph-level-outputs by finding the channel-wise maximum over the node dimension. The output of the embedding process is an embedding vector of size \(256\), representing an entire graph from the input. To perform a classification on this embedding vector, the GNN model – analogous to the MLP – contains three linear layers that serve as a binary classifier. To make an accurate comparison between both approaches, we train the GNN model using the same configurations used for training the MLP such as the optimizer, learning rate, loss function and early-stopping.
Experimental Results
The learning curves obtained by training the MLP or GNN models to classify samples of the vulnerability type CWE-120 are shown in Figure 6.

Figure 6(a) shows that both the training loss and the validation loss of the MLP model reduce rapidly in the first few epochs until the validation loss increases again (at the 50th epoch) and no longer improves. This leads to the training being stopped after \(5\) epochs, i.e., at epoch \(55\), due to the early-stopping method applied. Figure 6(b) shows that the GNN model tends to over-fit the data faster, i.e.,in fewer epochs, than the MLP. Thus, training stops after \(6\) epochs, as the validation loss starts to increase immediately after the first epoch and continues to fluctuate until it ends at 0.599, while the training loss only decreases slightly. Similar behavior can be observed when training both models for the remaining vulnerability categories.
To evaluate how well the models classify new samples that were not used during the training process, samples from the test subset of each CWE category are fed into the models to be evaluated on performance metrics such as accuracy, precision, recall and \(F_1\)-score. The results are shown in Table 2.
Table 2: Classification performance for each vulnerability type.
| Model | Accuracy | Precision | Recall | F1-Score |
| CWE-120 | ||||
| MLP | 0.681 | 0.682 | 0.686 | 0.684 |
| GNN | 0.671 | 0.637 | 0.779 | 0.701 |
| CWE-119 | ||||
| MLP | 0.719 | 0.721 | 0.723 | 0.722 |
| GNN | 0.731 | 0.716 | 0.779 | 0.746 |
| CWE-469 | ||||
| MLP | 0.660 | 0.634 | 0.776 | 0.698 |
| GNN | 0.746 | 0.752 | 0.761 | 0.756 |
| CWE-476 | ||||
| MLP | 0.562 | 0.573 | 0.574 | 0.574 |
| GNN | 0.543 | 0.532 | 0.660 | 0.589 |
| CWE-OTHERS | ||||
| MLP | 0.640 | 0.663 | 0.598 | 0.629 |
| GNN | 0.625 | 0.620 | 0.657 | 0.638 |
Conclusion and Code
In this blog post, both inductive and transductive methods are used to learn vulnerability patterns in C/C++ source code based on their graph representations to predict vulnerable code for further analysis. The two proposed approaches are able to effectively generate graph embeddings and predict vulnerable source code based on them. The first approach generally has a better generalization performance than the second which over-fits the data after a few epochs. Nevertheless, in this experiment, the second approach outperforms the first regarding its \(F_1\)-score.
REFERENCES
[1] X. Sun, Z. Pan, and E. Bertino, Artificial Intelligence and Security, 1st ed. Essex, England: Springer, Cham, 2019, eBook ISBN 978-3-030-24268-8.
[2] K. Filus, P. Boryszko, J. Domanska, M. Siavvas, and E. Gelenbe, “Efficient feature selection for static analysis vulnerability prediction,“ Sensors, vol. 21, no. 4, 2021.
[3] R. Russell, L. Kim, L. Hamilton, T. Lazovich, J. Harer, O. Ozdemir, P. Ellingwood, and M. McConley, “Automated vulnerability detection in source code using deep representation learning,“ 12 2018, pp. 757– 762.
[4] Z. Bilgin, M. A. Ersoy, E. U. Soykan, E. Tomur, P. Comak, and L. Karaçay, “Vulnerability prediction from source code using machine learning,“ IEEE Access, vol. 8, pp. 150 672–150 684, 2020.
[5] I. H. Sarker, “Machine learning: Algorithms, real-world applications and research directions,“ SN Computer Science, vol. 2, no. 12, 03 2021. [Online]. Available: https://doi.org/10.1007/s42979-021-00592-x
[6] S. M. Ghaffarian and H. R. Shahriari, “Software vulnerability analysis and discovery using machine-learning and data-mining techniques: A survey,“ ACM Comput. Surv., vol. 50, no. 4, Aug. 2017. [Online]. Available: https://doi.org/10.1145/3092566
[7] M. Grohe, “Word2vec, node2vec, graph2vec, x2vec: Towards a theory of vector embeddings of structured data,“ in Proceedings of the 39th ACM SIGMOD-SIGACT-SIGAI Symposium on Principles of Database Systems, ser. PODS’20. New York, NY, USA: Association for Computing Machinery, 2020, p. 1–16.
[8] P. D. Thain, Introduction to Compilers and Language Design, 2nd ed., 2021, iSBN 979-8-655-18026-0.


