
Hinweis:
Dieser Blogartikel ist älter als 5 Jahre – die genannten Inhalte sind eventuell überholt.
Kombination hybrider Technologien im Data-Warehouse
Neben dem im vorherigen Kapitel beschriebenen Nutzen spezialisierter Dienste jeweils für einen Verwendungszweck bietet es sich besonders in der Cloud an, auch innerhalb eines gewählten Data-Warehousing-Schichtenmodells für die Datenpersistenz unterschiedliche Technologien intelligent miteinander zu kombinieren. Dies wird in der Abbildung Kombination hybrider Technologien im Data-Warehouse illustriert und soll in diesem Abschnitt noch einmal verdeutlicht werden.
 Die Hersteller traditioneller relationaler Datenbanksysteme bieten inzwischen auch Möglichkeiten zur direkten Integration von Big-Data- und No-SQL-Systemen. So kann eine Landing Zone, in der die Daten aus den Quellsystemen zunächst in Rohform angereichert werden, statt aus fix definierten Tabellen auch aus Textdateien auf Basis eines Hadoop Distributed File System (HDFS) bestehen. Die Inhalte des Ordners werden über eine Struktur-Definition der Datenbank bekannt gemacht – vergleichbar mit einer View. Neue Daten stehen dem Datenbanksystem nach der Speicherung im HDFS für die Integration in Abfragen und die Weiterverarbeitung sofort zur Verfügung. Die Query Optimizer sind dabei in der Regel so fortschrittlich, dass bei der Ausführung der Abfragen auch die Vorteile der unterschiedlichen Technologien ausgenutzt werden. Beispielsweise werden Filter bereits im Hadoop Layer parallelisiert angewendet und so nur die notwendigen Daten an das Datenbanksystem zurückgegeben.
Die Hersteller traditioneller relationaler Datenbanksysteme bieten inzwischen auch Möglichkeiten zur direkten Integration von Big-Data- und No-SQL-Systemen. So kann eine Landing Zone, in der die Daten aus den Quellsystemen zunächst in Rohform angereichert werden, statt aus fix definierten Tabellen auch aus Textdateien auf Basis eines Hadoop Distributed File System (HDFS) bestehen. Die Inhalte des Ordners werden über eine Struktur-Definition der Datenbank bekannt gemacht – vergleichbar mit einer View. Neue Daten stehen dem Datenbanksystem nach der Speicherung im HDFS für die Integration in Abfragen und die Weiterverarbeitung sofort zur Verfügung. Die Query Optimizer sind dabei in der Regel so fortschrittlich, dass bei der Ausführung der Abfragen auch die Vorteile der unterschiedlichen Technologien ausgenutzt werden. Beispielsweise werden Filter bereits im Hadoop Layer parallelisiert angewendet und so nur die notwendigen Daten an das Datenbanksystem zurückgegeben.
Diese Art der Integration, die dem sogenannten „Schema-on-Read-Pattern“ folgt, hat den Charme, dass der operative Integrationsaufwand für Daten überschaubar ist und die Behandlung dateninhärenter Probleme erst zu dem Zeitpunkt erfolgen muss, an dem die Daten für die Analyse notwendig sind. Die Historisierung der Daten auf dem HDFS ist auch in der Cloud wesentlich günstiger als in einer relationalen Datenbank.
Der Einsatz spezialisierter Speicherformen findet weiter Anwendung im optimalen Vorhalten der Daten für die Datenanalyse in Online-Analytical-Processing-Systemen (OLAP). Dieses bietet neben der performanten in-memory Analyse auch die erleichterte Navigation durch definierte Hierarchien. Bei der Entscheidung für eine solche Technologie neben der relationalen Data-Warehouse-Basis tun sich die Systemverantwortlichen oft schwer, weil hier wiederum andere Patterns für den Betrieb notwendig sind als bei der klassischen Datenbank. Diese Hemmnisse entfallen bei Platform-as-a-Service-Angeboten, so dass die Entscheidung für den Einsatz mehrerer spezialisierter Technologien leichter fällt.
Erhöhte Agilität
Die tendenziell überlasteten EDV Abteilungen vieler Unternehmen – besonders im Mittelstand – tun sich schwer mit der Infrastruktur für junge und hochkomplexe Technologien. Wenn in der Projekt-Ramp-Up-Phase zunächst Hardware abgeschätzt, bestellt und eingerichtet werden muss, stagniert die Systementwicklung für einige Zeit, was natürlich zu Konflikten mit den Stakeholdern führt.
Die Bereitstellung auch großer verteilter Systeme geht bei Public-Cloud-Anbietern innerhalb von Minuten vonstatten. Spätere Anpassungen bzgl. Skalierung oder Auswahl der Komponenten sind schnell und unkompliziert möglich.
Unabhängig davon spielt die schnelle und flexible Bereitstellung von Entwicklungsumgebungen zu Projektbeginn eine große Rolle und schafft später zusätzliche Sicherheit bei Upgrades oder Patches der Serverkomponenten und Entwicklertools. Die Provisionierung auch komplexer, mehrschichtiger Systeme kann über Container-Technologien und Scripting wiederholbar eingerichtet werden. Über VPNs und Verzeichnissynchronisierungen können diese Umgebungen im Netzwerk der Unternehmen für Anwender:innen transparent eingebunden werden.
Diese Optionen stellen eine erhebliche Entlastung für die IT-Abteilungen dar und führen damit zu besseren Voraussetzungen für die Business-Intelligence-Entwickler:innen.
In der Abbildung Erhöhte Agilität durch Cloud Ressourcen wird die typische Topologie von ausgewachsenen, mehrstufigen Business-Intelligence-Umgebungen aufgezeigt. Hier wurde das On-Premises-Netzwerk über ein Site2Site VPN so mit der Cloud verbunden, dass die dortigen Dienste und Server für die Anwender wie im lokalen Netz nutzbar sind.

Die Entwickler:innen arbeiten auf einem geteilten Server, um die Entwicklertools zentral installieren und verwalten zu können. Der Ausfall einer solchen Entwicklungsinfrastruktur wird oft unterschätzt und kann sehr teuer werden, da wertvolle Zeit für den Projektfortschritt verloren gehen kann. Deshalb gibt es in der Cloud noch weitere Versionen dieses Servers. Zum einen zur Vermeidung von Ausfällen und auch um neue Software-Komponenten für die Unterstützung der Entwicklung wie beispielsweise ein neues Plug-in für die Quellcodeverwaltung unter realen Bedingungen testen zu können. Das Gleiche gilt auch für die nebenstehenden Server-Umgebungen, die in der Cloud schnell ausgerollt und deren Leistung dabei je nach Anforderung angepasst werden können. Die Server können zur Kostenoptimierung auch nur bedarfsweise genutzt und sonst abgeschaltet werden.
Da BI-Systeme in der Regel aus einer ganzen Reihe spezialisierter Server-Komponenten bestehen, sollte der Aufwand für den Rollout baugleicher Umgebungen nicht unterschätzt werden. Hier gibt es in der Cloud sehr viele technische Möglichkeiten, allen voran neben virtualisierten Maschinen auch feingranulare Container-Technologien wie Docker.
Schnelle Innovationszyklen der Hersteller
Der Unterschied zwischen Cloud und On-Premises-Software macht sich insbesondere bei der Rollout-Frequenz neuer Features bemerkbar. Oft liegen bei On-Premises-Produkten Jahre zwischen neuen Versionen, in der Cloud sind es teilweise nur wenige Wochen. Es ist einleuchtend, dass Deployments von Cloud Komponenten auf zentral verwalteten, hoch automatisierten Systemen des Anbieters einfacher auszurollen sind, als ein Release für die unterschiedlichen, abgeschotteten Systemumgebungen aller Kunden.
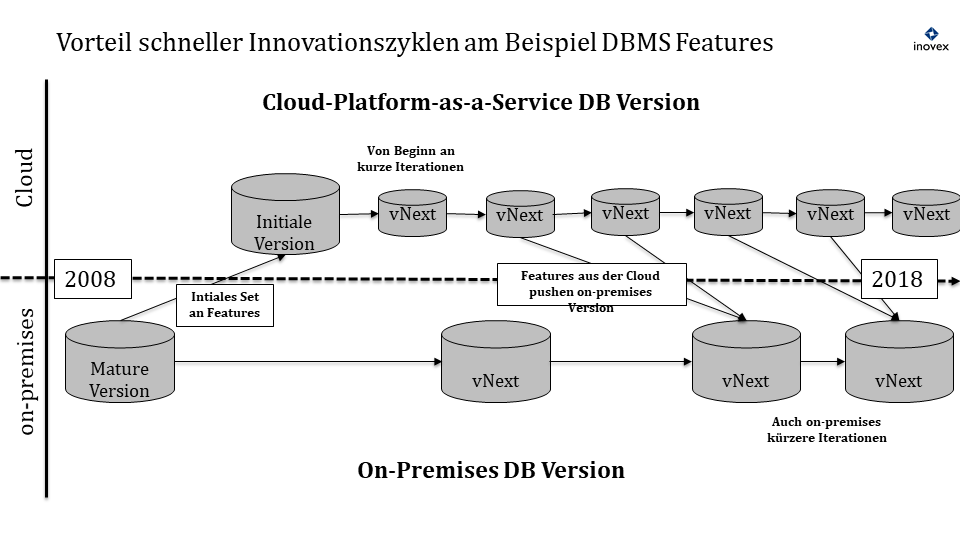
In der Abbildung Vorteil schneller Innovationszyklen am Beispiel DBMS Features sieht man die Weiterentwicklung eines Datenbank-Systems des gleichen Herstellers in der gemanagten Cloud Version und der schon länger verfügbaren On-Premises-Version über den Zeitstrahl.
Die erste Cloud-Version der Datenbank war auf Basis-Features beschränkt und nur geeignet für einfache Applikationen. Neben der Funktonalität mussten zunächst auch die Kinderkrankheiten in der damals neu geschaffenen Public-Cloud-Welt geheilt werden, was zur Erweiterung der PaaS-Version auf spezielle Anforderungen wie Firewalling und der Storage-Architektur führte.
Darüber hinaus entwickelte der Hersteller neue spezifische Features, die nur in der Cloud möglich sind, so zum Beispiel das Up- und Downscaling der Datenbankleistung per Knopfdruck über Microservices-Technologie.
Von Anfang an waren in der Cloud aus den oben angeführten Gründen wesentlich kürzere Release-Zyklen möglich.
Nach einer Phase der Evaluation folgte die Anpassung der internen Entwicklungsstränge, um Features nur noch einmal für beide Versionen zu entwickeln. Das wurde ermöglicht durch zusätzliche Abstraktionsschichten auch im on-premises Produkt.
Stand heute kommen neue Features für die Datenbank des Herstellers in der Regel zuerst in der Cloud zum Einsatz. Die Gründe sind neben dem schnellen Rollout auch die Möglichkeiten für schnelles Feedback durch erweitertes Monitoring und im Notfall für das schnelle Bugfixing.
Die in der Public Cloud in sehr großer Menge vorhandenen Log-Daten über die Nutzung der Datenbank eignen sich hervorragend als Trainingsdaten für Data-Science-Algorithmen, die vom Hersteller kontinuierlich zur Verbesserung der Datenbanken-Engine eingesetzt werden. Außerdem bekommen die End User intelligente Vorschläge für Anpassungen in der Datenbank. Das breite Feedback durch das große Testfeld in der Cloud führt zur stetigen Verbesserung der Stabilität und Sicherheit des Produkts.
Inzwischen gibt es auch schon Features für die hybride, gemeinsame Nutzung der on-premises und Cloud-Datenbanken, wie die kostengünstige Auslagerung historischer Daten in die Cloud, die im Abschnitt über die Optimierung von Betriebskosten beispielhaft vorgestellt wird.
Diese Entwicklung wäre für den Hersteller, dessen Datenbank in den letzten Jahren beständig Marktanteile gewonnen hat, nicht möglich gewesen, ohne die schnellen Entwicklungszyklen, die durch Cloud-Plattformen ermöglicht wurden. Dieses Beispiel lässt sich auf viele andere technische Bereiche, nicht nur im Business-Intelligence-Umfeld, übertragen.
Optimierung von Betriebskosten
Da Cloud-Systeme von den Kunden in aller Regel gemietet werden, fallen nur minimale initiale Investitionskosten an. Entscheidungsprozesse für Budgetfreigaben gestalten sich so meist einfacher.
Falls die ausgewählten Software-Komponenten sich wider Erwarten nicht optimal für die Aufgaben eigenen, ist ein Umrüsten auf andere Dienste oder sogar der komplette Ausstieg aus der gemieteten Infrastruktur möglich. Das vermeidet gerade bei großen Big-Data-Projekten finanzielle Risiken.
Die Synergieeffekte beim Einkauf der Hardware auf Seiten der Cloud-Anbieter und der hohe Automatisierungsgrad der Cloud Infrastrukturen führen zu niedrigen Kosten, die an den Endkunden weitergegeben werden. Damit können On-Premises-Rechenzentren preislich kaum konkurrieren.
Auch die bereits beschriebene Möglichkeit der zeitlich gesteuerten Skalierung zur Vermeidung von Leerlauf bietet dem Kunden viele Spielraum für Kostenoptimierung.
Als Beispiel dafür, wie Kosten gespart werden können, dient das Szenario in der unten stehenden Abbildung Optimierung von Betriebskosten – bei gleicher Daten-Verfügbarkeit. Bei On-Premises-DWHs entstehen oft hohe Betriebskosten für das Vorhalten historischer Daten. Deshalb wird aus Kostengründen oft unterschieden zwischen historischen Daten, die gelöscht oder offline archiviert werden, und aktuellen Daten, die im Data Warehouse für den schnellen Zugriff zur Verfügung stehen. Zur Lösung von Fragestellungen, die auch ältere Daten beinhalten, müssen die Daten dann ad-hoc mühsam zusammengestellt werden.

In dem Use Case werden die älteren Daten ab einem definierten Zeitpunkt automatisch aus dem On-Premises-Data-Warehouse in ein fast baugleiches Cloud-Data-Warehouse verlagert. Bei Abfragen werden die historischen und aktuellen Daten automatisch aus den Datenspeichern kombiniert und den Nutzer:innen als ein zusammenhängender Datensatz zurückgegeben.
Dadurch sind historische und aktuelle Daten immer im Zugriff – transparent für die Berichte und Applikationen. Bei den historischen Daten sind höhere Latenzen meist akzeptabel. Die Funktionalität wird gerade bei schnell wachsenden Datenmengen über die Cloud-Lösung bei geringeren Kosten on-premises realisiert. Bei Bedarf ist das Hochskalieren des Cloud-Data-Warehouse kein technisches Problem, sondern lediglich eine Kostenfrage.
Weiterlesen
Im 1. Artikel dieser Serie geht es um Connectivity in die Cloud sowie Skalierbarkeit und Chancen durch Technologievielfalt. Teil 3 wird Szenarien mit global verteilten Daten, Ausfallsicherheit in der Cloud, Edge Computing, Herausforderungen und Risiken behandeln sowie ein Fazit des Autors bieten. Stay tuned!



One thought on “Hybride DWH-Architekturen: Mehrwerte von Cloud Services (Teil 2)”