
Notice:
This post is older than 5 years – the content might be outdated.
Humans are constantly being taught and acquire knowledge: first by parents, later in school by teachers and at work by colleagues. In fact, learning is a process that can be generalized across all living creatures – and also machines with the advent of sophisticated hardware and algorithms. This article introduces preference-based inverse reinforcement learning and explains how it can support a snake-like robot to learn to move forward efficiently.
Snake-like Robot
Snake-like robots have several use cases such as exploration, inspection, monitoring, as well as search and rescue missions. Their usage is inspired by the natural movements of real snakes which can move forward relatively quickly on various different terrains. It is noteworthy that the snake robot ACM−R5 is the only robot that is able to perform cleanup missions at the devastated nuclear power plant of Fukushima, Japan.

In order to save time and energy, I used a simulation environment for learning how to move efficiently. The simulation was handled by the MuJoCo Physics Engine. The snake-like robot agent and its environment are shown in the figure below. We see that it consists of nine building blocks (brownish elements) which are coupled via eight joints (red balls in between), each of which connects two building blocks.

Concept: Preference-based Inverse Reinforcement Learning
In the part that follows, I provide a more intuitive analogy with my approach that still explains well how I embedded ranking of experiences into inverse reinforcement learning. The procedure consists of three major steps:
- Data Creation
- Data Labeling
- Preference Learning
Data Creation
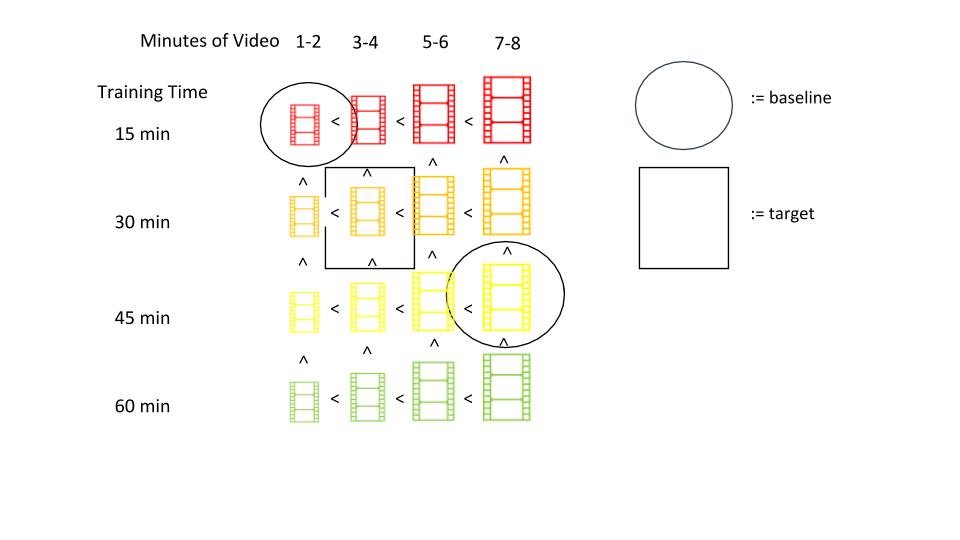
Let us consider four siblings that all play a game for a certain amount of time. The first one plays for 15 minutes, the second for 30 minutes, the third for 45 minutes, and the fourth for 60 minutes. We assume that the more time you practice the better you perform on the game. Behavior is guided by some static reward that increases a total game score depending on the actions that were taken. Each of the siblings has the goal to achieve a high total score. This framework of learning from experience while interacting with some environment is called reinforcement learning (see this blogpost for a detailed introduction into reinforcement learning). After practice, each of the siblings learnings is evaluated by letting them play for another eight minutes. This time, their interactions are recorded which results in four tapes with eight minutes each. Every tape is then cut into four snippets which last for two minutes each. Those snippets are the raw data or independent variables for the final preference learning step.

Data Labeling
Now, we have several snippets with side-information like agent or which minutes were taken out of the respective tape. From the set of available snippets we can randomly pick pairs, triplets, etc. without replacement. The triplet case looks as follows: three unique snippets are randomly selected. In order to classify the snippets, two rules of thumb are used: first, snippets within one tape, that are cut out at the end of that tape, are classified better than those, that are cut out earlier on. Second, one tape from a sibling, that had more time to practice than another one, is also classified better than the tape from one with less training time.
Thus, I make a comparative distinction between good and bad snippets assuming that longer practice and longer play lead to better scores stemming from more competent agent behavior. To quantify good and bad properly, I propose a binary classification scheme that labels good snippets with 1 and bad ones with 0 – like thumbs up or thumbs down. With this rules in place, it becomes straightforward to label the best snippet within a pair of snippets with a thumbs up and the other or worst with a thumbs down. For the remaining snippet within a triplet that stands in between, we calculate the distance towards the other two snippets. Intuitively, we want to assign the label of the closest already labeled snippet to the remaining snippet. Thereby, I can derive a dataset of pairwise and another of triplet-wise snippets.
Preference Learning
In the last step, I introduce the cousin of the four siblings. She assumes that the initial reward signal is not the most appropriate way to achieve the highest possible score. Hence, she tries to identify the most relevant features to achieve a high total score. And she does so by looking at the snippets. She starts by watching the first triplet of the training set. Specifically, she tries to approximate the reward for each minute of each snippet. Intuitively, a higher predicted reward means what she sees is more likely to obtain a higher total score, given her current knowledge. Next, the predicted rewards for each snippet are summed up, resulting in three cumulative reward predictions – one for each snippet. Lastly, we compare whether the order of her prediction matches the order introduced by the labels of the triplet, respectively pair. She iterates multiple times through the training set until she reaches a good enough understanding of how to value certain actions in specific states.
This process of inferring the reward signal given some demonstration is called inverse reinforcement learning. Since this procedure is conducted by comparing multiple ranked demonstrations at once, we refer to it as preference-based inverse reinforcement learning (PbIRL).
To finally evaluate how well the cousin is at grasping which behavior yields a high total score, the siblings could play the game again but now using the cousin’s reward signal instead.
Applying PbIRL to the Snake-like Robot
Although playing video games and snake-like robot movement are not the same, my concept describes how to generate a synthetic reward function, alias the cousin, which is also applicable to reward snake-like agent. In reinforcement learning, the behavior of an agent is guided by a policy which presents a mapping from state observations to actions. In the analogy, each sibling depicts a different maturity of the initial policy. This initial policy is responsible for creating the raw training dataset, alias snippets. Each snippet is more or less a sequence of information that is generated by different stages of the initial policy interacting with the simulation environment. This is just one way of creating the initial training dataset. Generally, one can be very creative about how to obtain the raw dataset as long as the features are related to the task at hand. In the data labeling section, I defined the quality of a demonstration: one factor is the sibling from whom the snippet was recorded, and the other one was which part of the tape it is. In my approach, the former factor is defined by the stage of the initial policy and the latter one which part of the demonstration is taken. Applied to the snake-like robot that is initially trained via Proximal Policy Optimization (PPO), this means that we extract multiple episodes or policy rollouts after a regular interval to learn a better reward function that yields the observed direction of behavioral change.
In addition, I opted for a neural network, alias cousin, to learn the relevant features that explain high total scores. In the case of the snake-like robot, the total score depends on two metrics, the distance the snake moved forward within a certain period of time and also the power efficiency it achieves while moving forward. Thus, covering a long distance and also having a low power consumption is desirable.
Conclusion
It turned out, that the snake was able to travel longer distances than the PPO-trained agent by using reward signals from the neural network trained with the PbIRL-approach. However, it does not outperform the PPO-policy with respect to power efficiency. Having two concurring goals makes the problem seemingly more challenging and requires further investigation. Comparing pairwise and triplet-wise approaches with each other, the latter achieves much better results than the former. For more detail check out the full thesis here.
Long story short: Preference-based inverse reinforcement learning is a research field with high potential. With more sophisticated reward learning schemes, like preference-based ones, we may unlock this potential.
Sources
[1] Daniel Brown et al. (2019) Extrapolating Beyond Suboptimal Demonstrations via Inverse Reinforcement Learning from Observations
[2] Daniel Brown et al. (2020) Safe Imitation Learning via Fast Bayesian Reward Inference from Preferences


