
Today, deep neural networks achieve state-of-the-art performances on a variety of different natural language processing (NLP) tasks. However, they become increasingly complex and usually need a tremendous amount of data for their training. Moreover, many downstream tasks in NLP require labeled data, the annotation of which is a tedious and very costly activity that can make an approach infeasible, which is why there is a definite need to investigate approaches designed to reduce the amount of data necessary for training such complex networks.
In this article, we therefore take a deeper look at a novel approach called active curriculum learning (ACL) [1] that combines active learning (AL) and curriculum learning (CL) specifically for this purpose into one framework and apply it to named entity recognition (NER) as well as sentiment analysis. In particular, we use the CoNLL 2003 and OntoNotes5 data sets as well as the SST-5 data set to evaluate ACL for the respective task.
What is Active Curriculum Learning?
Before we go into the details of the combination of AL and CL in ACL let us quickly review the objectives and workings of the individual approaches.
Active learning is based on the idea that knowing the labels of a few but informative data points can be equally or more beneficial for training than knowing the label of every single instance in a data set. To this end, an iterative procedure is used in which the most informative instances are selected from the unlabeled training data based on a sampling strategy and presented to a human expert for annotation in each iteration. The model is then continuously retrained on the expanding set of labeled data.
Curriculum learning [2], on the other hand, aims at mimicking the process of human learning where one typically starts with easy examples to learn new concepts before working one’s way up to handle more complex ones. Thus, instead of presenting data in randomly packed batches to the model, as it is usually done, a manually crafted or maybe even learned measure of difficulty is used to sort the instances in the training data according to their complexity. Easier instances are then presented before harder ones during the training process.
Active curriculum learning now takes advantage of the fact that both approaches calculate a score for each instance x in the training data through the sampling strategy as well as the difficulty measure, and combines both with a simple weighted linear function,
acl score(x) = α·al score(x) + β·cl score(x)
where α and β control the influence of the respective approach on the selection of instances. Their values were limited to 1 and ±0.5, but in theory could take any desired range values.
In order to calculate the al score of an instance we compare the use of two different sampling strategies as suggested by the original paper [1]:
- Minimum Margin Sampling: For each token in a sequence, we calculate the difference between the two classes that were assigned the highest and second highest probability. The results are then averaged over the length of the sequence to get the average token margin. We select those instances with lowest values, as this signals a higher level of uncertainty for correct classification.
- Maximum Entropy Sampling: For each token in a sequence, we calculate the entropy and average the results over the length of the sequence to get the average token entropy. We select those instances with highest average entropy, since this indicates a higher level of uncertainty.
For the cl score the paper [1] uses two difficulty measures widely used in the literature and introduces seven novel difficulty measures designed to extract deeper information about the complexity of an instance based on additional models and the syntactic properties of an instance:
Standard Difficulty Measures
- Sentence Length: We calculate the length of a sequence in terms of tokens and, intuitively, consider shorter sequences to be easier than longer ones.
- Word Frequency: For each token in a sequence we calculate the number of occurrences in the currently labeled data normalized by the total number of tokens in the currently labeled data. We then average the results over the length of a sequence and consider sequences with higher values as easier.
Model-based Difficulty Measures
- Number of Children from Parse Tree: We calculate the average number of children in the dependency parse tree of an instance and consider sequences with higher values as easier.
- Sentence Score from GPT-2 Model: We calculate a score for a sequence according to the GPT-2 Language Model that indicates how likely the given sequence occurs in natural language. We regard those instances with lower values as easier.
- Loss from Longformer Language Model: We calculate the average loss of the Longformer Language Model generated by the tokens in a sequence and, intuitively, consider sequences with a lower average loss as easier.
Syntactic Difficulty Measures
- POS/Tag/Shape/Dep: These represent four separate measures where, exactly the same way as for the Word Frequency difficulty measure, we calculate the average frequency of different linguistic features of the tokens in a sequence.
The ACL training process then follows an iterative procedure very similar to that from AL (Figure 1) where in each iteration we select (or query) 500 new instances with the highest acl score that are then labeled and used to retrain the model, which in this case is a Bi-LSTM with a two layer Feed Forward Network. Once we have gone through a total of 15 iterations and we stop the training. At this point the model has seen 8000 instances which corresponds to approx. 57% of the CoNLL 2003 data set and 7% of the OntoNotes5 data set.
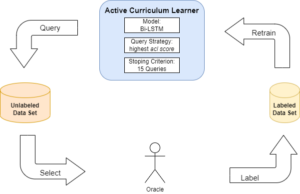
Figure 1: Iterative cycle in ACL.
Results of ACL on NER
We combine every sampling strategy with every difficulty measure and evaluate the ACL approach for NER on our two data sets in terms of Macro F1. In comparison to using CL on its own, Figure 2 shows that ACL brings more benefits for harder tasks, since the improvement of the Macro F1 is much more noticeable on the OntoNotes5 data set that distinguishes a lot more classes than the CoNLL 2003 data set. Additionally, we can see in Figure 2 that there is a gradient for the performance improvement. In particular, the poorer performing difficulty measures like the Sentence Length measure experience a much stronger performance boost from the additional AL than those that perform already well on their own like the model-based measures.
When it comes to the question which sampling strategy is more useful for ACL we notice

Figure 2: Improvement of the Macro F1 of ACL over CL on the CoNLL 2003 (left) and OntoNotes5 data set (right).
that the Maximum Entropy Sampling in general brings the higher improvement. Through using this sampling strategy we are even able to reach the performance of a Bi-LSTM trained with all available data with only 57% of training data on the CoNLL 2003 data set.
The improvement for AL, on the other hand, was not as prominent as for CL, since the two sampling strategies performed very well on their own and therefore, in the same way as with well performing difficulty measures, seem to not have as much of an advantage from ACL.
Approaches to improve ACL
Combining Difficulty Measures
In order to enhance the performance of ACL, we firstly investigate whether the different categories of difficulty measures can complement each other, as each of them covers a different aspect of complexity. In particular, we focus on those measures that achieved the best performance in a category, since these encoded difficulty in the most useful way, and combine them in pairs using a linear approach,
combined cl score(x) =δ·cl score1(x) +ε·cl score2(x) δ, ε∈{−0.5,1,0.5}
where cl score1(x) and cl score2(x) denote the score of an instance x produced by the difficulty measures from two different categories. For the combination of multiple difficulty measures with AL we then use the exact same weighted linear combination as for the basic ACL approach,
acl score(x) =α·al score(x) +β·combined cl score(x)
and simply exchange the cl score of an instance with its combined cl score.
Unfortunately, our results show that the use of more than one difficulty measure is neither helpful for CL on its own, since only the performance of the poorer performing difficulty measure in a combination improves, nor is it able to improve over the best performing combinations of a single difficulty measure with AL in most cases. The basic ACL approach is therefore still the better option with less effort for calculating the acl score.
BERT
LSTMs have recently been surpassed in their performance by transformer-based models like BERT [3] that have achieved new state-of-the-art performances for various NLP problems including NER. This is why we are interested in investigating whether such a model can also improve the performances of our AL, CL, and ACL approaches. We therefore merely exchange the previously used Bi-LSTM with the uncased version of the BERTBASE model and leave all other aspects of the three approaches unchanged.
Our results show that the performance of all of our approaches increases substantially through the use of a more sophisticated model which is especially due to BERT having a much better handling of the rarely occurring types of entities in our two data sets. On the CoNLL 2003 dataset this improved performance even leads to both sampling strategies, half of the difficulty measures as well as almost all ACL combinations reaching the performance of BERT that is trained with all data, thus, giving us multiple options to reduce the amount of training data.
Application to Sentence Classification
Since the original approach solely focused on ACL for NER, we are also interested to see if the approach with BERT is also adaptable to other NLP tasks and how it performs for these. In particular, we chose sentiment analysis on the SST-5 data set as representative for the broader field of sentence classification as an additional task to apply ACL to.
Due to the extremely easy adaptability of BERT as well as the sampling strategies and difficulty measures to work for a sentence classification task, very few modifications to the original ACL approach were necessary. The results further show that there are some similarities between the behavior of ACL for sentiment analysis and that for NER. In particular, we see once more that the improvement through the additional AL is especially high for the worst performing difficulty measures and continues to decrease with an increasingly good performance until it even negatively affects the performance of measures that perform well on their own. However, we also notice some differences in that, for example, the performance does not increase most with the better performing sampling strategy (in this case Minimum Margin Sampling) like for NER, which could hint at the fact that the Maximum Entropy Sampling is generally more suitable for ACL, but research in future work has to confirm this assumption.
Conclusion
In general, we have seen that ACL improves the performance of those approaches that experience the most difficulties in correctly classifying tokens or sentences, especially for harder tasks when the less sophisticated Bi-LSTM is used. However, whenever an approach is already working well on its own like the two sampling strategies or the model-based difficulty measures, the addition of the respective other approach can in fact be more of a hindrance to the performance. In summary, we can therefore say that ACL is only a suitable alternative to AL or CL on their own in cases where the respective approach struggles to correctly recognize named entities or classify the sentiment of a sentence.
References
[1] Jafarpour, B., Sepehr, D., and Pogrebnyakov, N. (2021). Active curriculum learning. In Proceedings of the First Workshop on Interactive Learning for Natural Language Processing, pages 40–45, Online. Association for Computational Linguistics.
[2] Bengio, Y., Louradour, J., Collobert, R., and Weston, J. (2009). Curriculum learning. In Proceedings of the 26th Annual International Conference on Machine Learning, ICML ’09, page 41–48, New York, NY, USA. Association for Computing Machinery.
[3] Devlin, J., Chang, M.-W., Lee, K., and Toutanova, K. (2019). Bert: Pre-training of deep bidirectional transformers for language understanding


