This blog post elaborates on the interface of knowledge graphs and explainability in natural language processing. We briefly introduce the core concepts and recent approaches in the field. Afterwards, we present our own model and an interactive visualization, which aims to improve the explainability of the performed text classification.
State of the Art in NLP
Modern Natural Language Processing (NLP) methods become more and more powerful. Just recently, OpenAI showed with its giant transformer model GPT-3 that scaling model and data leads to impressive few-shot capabilities on various NLP tasks.
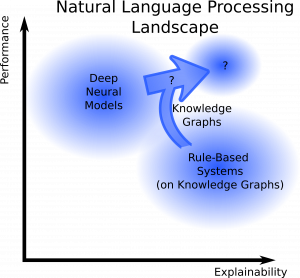
Unfortuantely, the generated texts are not really explainable. All of the knowledge in this and other neural models is hiding inside some kind of black-box, it seems to be some kind of black magic. Also, one cannot simply trust these model, often they fail leading potentially dangerous outcomes.
In contrast to that behavior, recent legislation demands some kind of explanation for all decisions affecting people, be it decisions from humans or AI algorithms. So somehow, one has to make NLP models more explainable. Ideally, one combines all of the three existing explainability approaches, depicted below: By using other generated or known example cases, explaining the influence of the different inputs in the model (variational approach) and using inherently interpretable models where possible. For a detailed summary of all these methods have a look at the great book by Christoph Molnar.

In addition to that lack of explainability, it is hard to change or update factual knowledge in neural models, as it is spread across many of their connection weights. Such changes might be necessary, for example, if a new president was elected or a company was renamed. In traditional rule-based systems this is easy, as this information is stored in a knowledge base, often in the form of a knowledge graph (KG).
These KGs have the nice property that knowledge can be easily added, deleted, or updated. The links between the stored entities correspond to real interpretable relations. So their information is also inherently explainable to a human, if annotated correctly with respective tags, so called literals. They are also very flexible in their structure, such that very different kinds of knowledge can be represented in them.
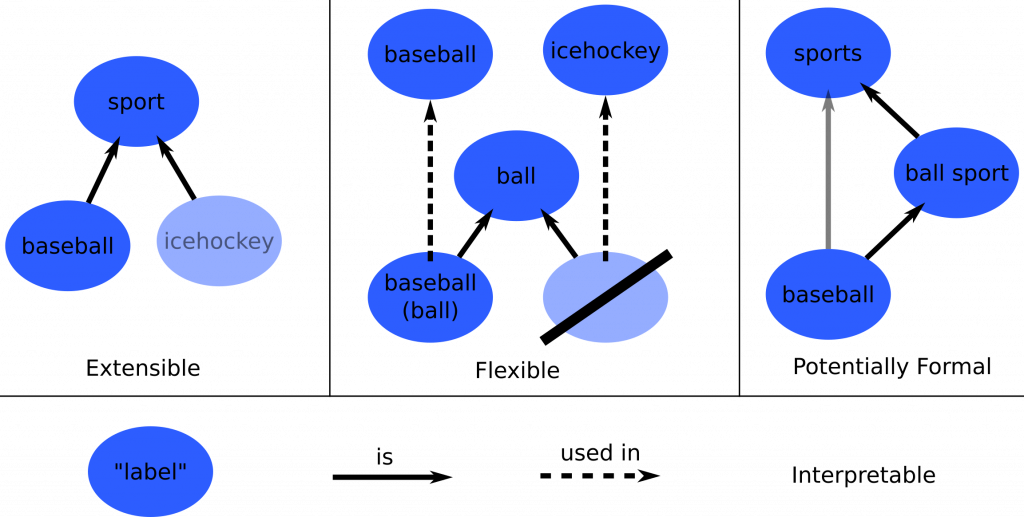
These reasons call for an integration of KGs into (neural) NLP models. And there is much recent work in this direction already. Commonly, KGs are integrated into neural network models via one of the following techniques:
- Knowledge graph embeddings: Here the structural information is vectorized with techniques already known from NLP as in Word2Vec and beyond (e.g. TransE, ConvE, SimplE, BoxE)
- Paths or subgraphs: The local neighborhood around relevant entities is used directly, as also humans (and rule-based systems) do in their reasoning paths. (e.g. in (Asai et al., 2020), OpenDialKG)
- Literal information: As usually a KG’s entities and relations are annotated by text in natural language (literals), this can be used in text processing model like BERT. (e.g. in K-BERT, KEPLER)
Experiments
In order to test the impact of integrating KG information in neural NLP models, we ran some text classification experiments. We integrate the KG via the literals and relation types of an entities one-hop neighborhood.
Our model, the Sandwich-Model, has two internal paths, a direct (green) and a KG path (blue).

This enables us to direct information flow in our model. In one case, the KG is not integrated at all leaving us with a vanilla transformer-based model. In the other, the input text is only used to attend on neighbors in the KG.
Therefore, we can investigate the influence of the KG information. We also train all the embeddings and layers from scratch in order to keep the KG as the only additional information source beyond the input text.
For our experiments, we use the mid-size KG ConceptNet, which contains both factual and commonsense knowledge. As a dataset we take the 20NewsGroup dataset. It is a collection of emails posted in different interest groups in the days of the early internet. Given the email text, one needs to predict the news group it was posted in. One example in this dataset would be the following:
Giants Win the Pennant!! Giants Win the Pennant !! Gi… OOOPS
I guess I’m a little early here…
See you in October…
The term „Win“ and the excitement in the email suggest here that it might be related to sports. Indeed, there are two classes in the dataset related to sports: ‚rec.sports.baseball‘ and ‚rec.sports.hockey‘. But without any additional information or knowledge about the US sports, this classification is also hard to understand for a human. Here, additional KG information can be helpful: In ConceptNet there are actually entities for „giants“ and „pennant“. And there are triples stating that:
„giants“ are a „baseball team“
and
„pennant“ is located at a „sporting event“
So this gives enough information to classify it correctly as „rec.sports.baseball“. Now, let’s see if our model can infer the correct class in a similar way.
Explainability Visualization
As our model is just a simple classifier, all we retrieve are class scores. So we have to somehow make the internal workings explainable. This can be done with some model-agnostic explainability algorithms, for which we use the Captum Library that integrates nicely with PyTorch. From this library, we take the IntegratedGradients method, with some experiments also with GradientSHAP. They are both based on the gradient of the model’s output probabilities with respect to the different inputs (or inputs‘ embeddings).
Considering all the entities and tokens in the text, you end up with lots of numbers. How can they be made more interpretable? Visualization is key here. Actually, we implement a custom visualization that can be interactively expanded. Only the interesting parts are shown, while irrelevant inputs are hidden.
So how does this look like for our example from above?
In the graphics below, you can see the different classes with their predicted probabilities on the left, the input text tokens in the middle and optionally the knowledge graph neighbors on the right. The attribution values of the inputs (first number) are visualized via the colored rectangles, attention values (second number) correspond to the circle colors inside.
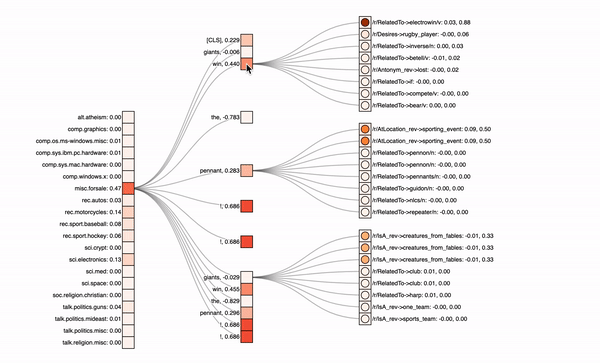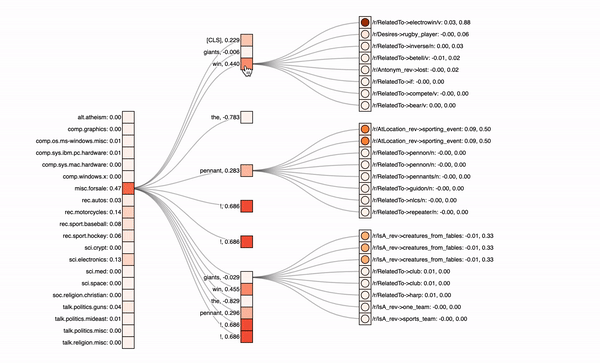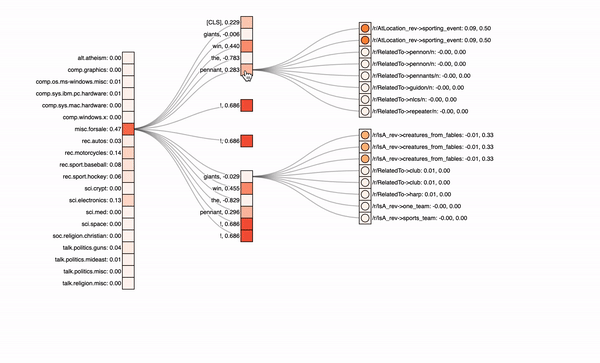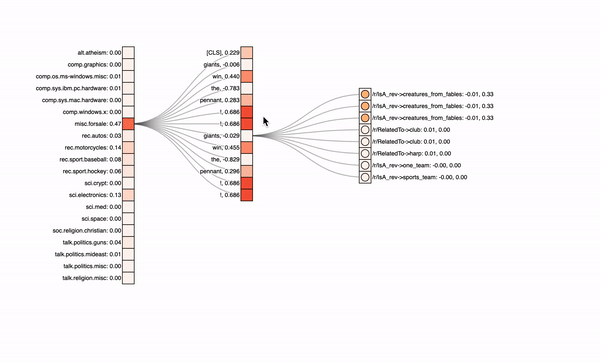
Sandwich-Model with both direct and KG path
expand by clicking on the rectangles in the center column
For a model with both the paths, one can see that it focuses on the exclamation marks. It therefore predicts the wrong „misc.forsale“-class. Also, if you click on the different text tokens in the center column, you will see that the knowledge graph input on the right does not get a lot of attribution, it is not really relevant for this model’s predictions. Note also that missing entities or neighbors, like for the exclamation mark, lead to padding tokens in our model. If we now look at another model excluding the direct path and therefore putting more emphasis on the knowledge graph, we see the following:
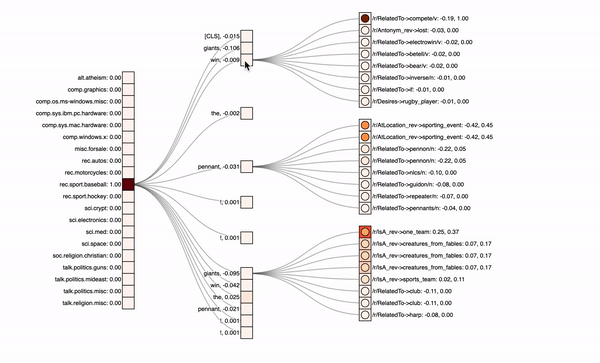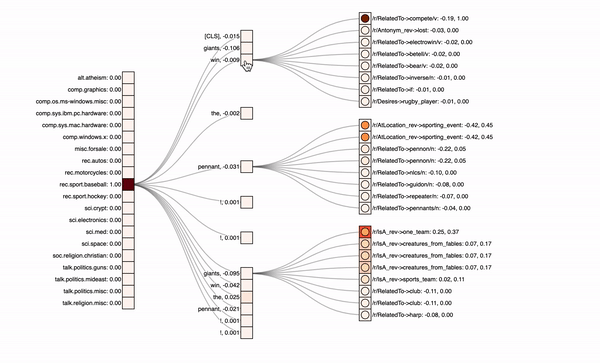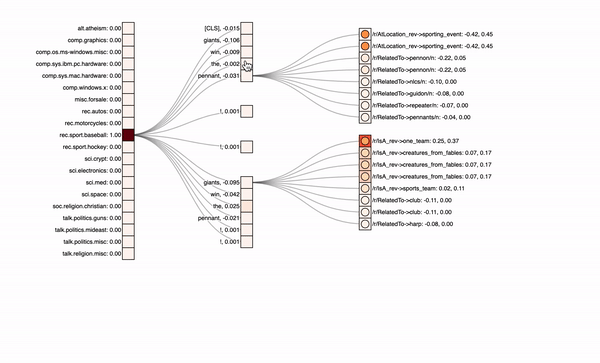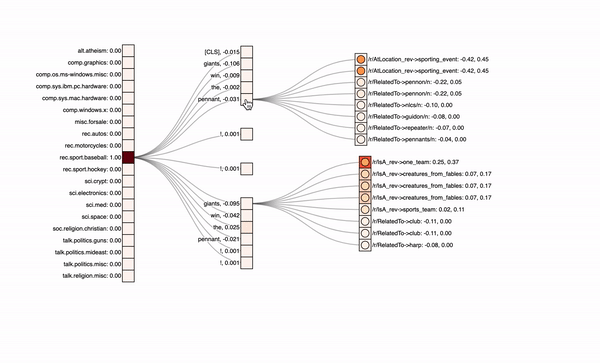
Sandwich-Model with only the KG path
expand by clicking on the rectangles in the center column
Actually, the class is correctly predicted and also the knowledge graph information gets a lot more attribution. But still some irrelevant info, at least from a human perspective, is somehow focused. We also have to admit that this is one example in many and actually only sometimes the knowledge graph is really beneficial.
Conclusion
Although our setting was experimental, using this visualization enabled us to compare the behaviour of different model variants and make sense even from faulty predictions. We also see that including the KG can potentially improve the explainability of the predictions, although it can still be optimized a lot.
Moving towards real-world scenarios and productions systems, one would avoid training the embeddings from scratch and rather integrate pre-trained embeddings or even whole models like BERT. Also, the integration of two- or three-hop neighborhoods should greatly improve the model performance and explainability. In the future, probably many more NLP models will integrate this kind of structured knowledge. Besides the possible performance benefits, as shown here, this should also make neural models more explainable at last.
Entstanden im Rahmen einer Studienarbeit an der TU München, unterstützt durch Sebastian Blank (inovex), Edoardo Mosca (TUM), Dr. Florian Wilhelm (inovex) und Prof. Dr. Georg Groh (TUM).