
Hinweis:
Dieser Blogartikel ist älter als 5 Jahre – die genannten Inhalte sind eventuell überholt.
Anwendungskomponenten, die mittels Kubernetes als Pods ausgeführt werden, können über mehrere Knoten eines Clusters verteilt sein. Die knotenübergreifende Netzwerkkommunikation stellt daher eine besondere Herausforderung dar. Aufgrund der Vielzahl unterschiedlicher Netzwerkumgebungen stellt Kubernetes zwar grundlegende Anforderungen an Netzwerkimplementierungen, setzt diese selbst aber nicht um. Stattdessen wird auf eine verbreitete Spezifikation, das Container Network Interface (CNI), für die Anbindung entsprechender Netzwerkimplementierungen zurückgegriffen. Aufgrund dieser Entkopplung sowie der breiten Akzeptanz von CNI steht eine Vielzahl kompatibler Plugins für die Verwendung mit Kubernetes zur Verfügung.
Diese Artikelserie fasst die Untersuchungen meiner Bachelorthesis aus September 2019 zusammen, in der ich die Grundlagen des Kubernetes Networkings beleuchtet und die funktionalen und technischen Unterschiede dreier bekannter Netzwerk-Plugins aufgezeigt habe. Darüber hinaus wurden mögliche Kriterien dargelegt, die für den Vergleich weiterer Plugins oder die Entscheidungshilfe bei der Auswahl eines Plugins herangezogen werden können.
Nachdem wir uns im ersten Teil dieser Serie mit den Grundlagen des Container- und Kubernetes Networkings befasst haben, schauen wir uns in diesem Teil die CNI-kompatiblen Plugins Project Calico, Cilium und Weave Net einmal konkret an. Da die im Rahmen meiner Thesis getätigten Untersuchungen sehr umfangreich waren und den Umfang eines Blogposts übersteigen würden, beschränke ich mich hierbei auf eine Zusammenfassung der wichtigsten Erkenntnisse. Ausschnitte aus dem jeweiligen „Deep Dive“ sowie die abschließende Vergleichsmatrix bieten dennoch einen detaillierten Einblick in das jeweilige Plugin. Einen kurzen Überblick über die angewendete Methodik möchte ich euch ebenso nicht vorenthalten.
Was wurde wie verglichen?
Bei meinen Untersuchungen habe ich mich für ein stufenweises Vorgehen entschieden. Ausgehend von einem Weitblick beziehungsweise „High Level“ heraus habe ich mich schrittweise den technischen Details genähert und abschließend kleine Testszenarien mit jedem Plugin durchgeführt.
In der ersten Stufe wurden die Rahmendaten des Projekts gesichtet, wie etwa Anbieter, Reifegrad oder Lizenz. Primär an der jeweiligen Dokumentation orientiert wurden funktionale Merkmale herausgestellt und in die Kategorien Konnektivität und Sicherheit untergliedert.
In der zweiten Stufe erfolgte die Herausstellung der technischen Merkmale. Es wurde der Frage nachgegangen, wie die zuvor beschriebenen funktionalen Merkmale technisch umgesetzt werden. Hierzu gehörte insbesondere die Architektur, also welche grundlegenden Komponenten zur Umsetzung des Netzwerks benötigt werden und welche internen Mechanismen und Technologien dabei zum Einsatz kommen. Auch hierbei wurde sich noch primär an den Dokumentationen orientiert. Wo immer es an Dokumentation mangelte, wurde stellenweise bereits der Code der Plugins herangezogen.
Stufe 3 umfasste einen Deep Dive, nachdem das jeweilige Plugin in einem Testcluster (Kubernetes v1.15, Docker 18.09) installiert wurde. Erzeugte Kubernetes-Ressourcen sowie virtuelle Netzwerkgeräte (Schnittstellen, Bridges, veth-Paare usw.) wurden mit verschiedenen Linux Tools untersucht, um die verwendeten Protokolle der Kommunikationsvorgänge sowie die internen Datenpfade nachvollziehen zu können. Augenmerk lag auf der Umsetzung der knoteninternen und knotenübergreifenden Kommunikation. Die Untersuchungen wurden in die Bereiche Installation, erzeugte Architektur und Herstellung der Konnektivität unterteilt.
In der vierten und letzten Stufe wurden pro Plugin zwei einfache Testszenarien durchgeführt, um einen ersten Eindruck der Plugins im Praxiseinsatz zu erhalten. Zum einen wurde eine bandbreitenintensive Datenübertragung zwischen zwei Pods unterschiedlicher Knoten und zwei Pods desselben Knotens mit iperf3 simuliert und dabei die mittels Prometheus Node Exporter exportierten Metriken überwacht (Throughput Test). Zum anderen wurde eine latenzkritische verteilte Anwendung (Microservice Topologie) mit dem Istio Tool Isotope simuliert (Mock-Up), die eingehende HTTP-Anfragen nach einem definierten Schema an verschiedene Microservices weiterleitet. Mittels Fortio wurde die Latenz bis zur Beantwortung der Anfrage an den Initiator gemessen (Latency Test). Der Testaufbau kann der folgenden Abbildung entnommen werden:

Besonders der mit Isotope bereitgestellte Topologiekonverter kann als Mock-Up-Tool zum Nachbilden von Microservice-Architekturen nachdrücklich empfohlen werden. In Kombination mit Fortio entsteht ein idealer Testaufbau zur Durchführung und Visualisierung von Belastungstests. Die genutzte Topologie wies die folgende Struktur auf:

Da hinsichtlich der Hardware der Testumgebung Einschränkungen bestanden (z.B. konnte lediglich in einem Gigabit-Netzwerk getestet werden), gaben die Testergebnisse in der Einzelbetrachtung wenig Aufschluss über die Leistungsfähigkeit eines Plugins. Sie boten einen ersten Eindruck im direkten Vergleich zueinander, zeigten aber nicht die technischen Belastungsgrenzen auf – insbesondere bei den Durchsatztests. Primäres Ziel war hingegen, einen möglichen Testaufbau zu entwickeln und die Plugins im Praxiseinsatz zu testen und zu belasten.
Project Calico
Project Calico erzeugt ein clusterweites Layer-3-Netzwerk und stellt die Kommunikation zwischen den Knoten mittels klassischem IP-Routing und BGP Route Distribution sicher. Dabei fungiert jeder Knoten gleichzeitig als Router und pflegt in seiner Kernel-Routing-Tabelle, welche Workloads auf welchen Knoten im Cluster erreichbar sind. Dazu existiert das DaemonSet calico-node, das auf jedem Knoten einen Pod mit dem Agent Felix für die Konfiguration von Routing- und iptables-Regeln sowie einem BIRD Daemon für die BGP-Funktionalitäten ausführt. Felix erzeugt auf seinem jeweiligen Knoten Routingregeln für die lokal ausgeführten Pods, bevor der BIRD Daemon diese per BGP an die übrigen Knoten des Clusters propagiert. Um die Komplexität des Routings gering zu halten und nicht für jeden Pod des Clusters eine eigene Routingregel implementieren zu müssen, werden knotenspezifische Subnetze erzeugt, die eine Route Aggregation für alle Pods eines Knotens ermöglichen.
Auf die Verwendung eines Overlays kann bei Project Calico vollständig verzichtet werden, wodurch sich sowohl der Paket-Overhead als auch die Ressourcennutzung durch den Wegfall von Encapsulation und Decapsulation der Nutzdaten reduziert. Knotenintern wird durch die Aktivierung von proxy_arp auf den veth-Paaren sichergestellt, dass jegliche ARP-Anfragen mit der MAC-Adresse des Hosts beantwortet werden und durch Pods initiierter Datenverkehr grundsätzlich durch die im Linux Kernel integrierten Routing- und Filterfunktionen des Hosts auf Layer 3 verarbeitet wird. Dies ermöglicht eine zentrale Kontrolle der Datenflüsse, was zugleich der Grund für den Verzicht auf eine Linux Bridge ist (=> Umsetzbarkeit von Netzwerkrichtlinien zwischen zwei lokalen Pods). Durch die Nutzung von verbreiteten Standards wie BGP, ARP, Linux Kernel Routing oder iptables und den möglichen Verzicht auf ein Overlay, lässt sich Calico mit grundlegenden Netzwerkkenntnissen leicht administrieren und debuggen. Calico verfolgt nach eigenen Angaben ein What-You-See-Is-What-You-Get-Netzwerkmodell, bei dem jedes Paket klar definiert, woher es stammt und wohin es übertragen wird. Falls durch das vorliegende Underlay-Netzwerk jedoch nicht anders möglich, kann auch Calico auf IP-in-IP und VXLAN als Tunnelprotokolle zurückgreifen. Project Calico implementiert neben den Kubernetes Network Policies zusätzlich ein eigenes Netzwerkrichtlinienmodell in Form einer Custom Resource Definition: Es bietet einen erweiterten Funktionsumfang und neben allow auch die Aktionen deny, log und pass sowie eine Priorisierung der Regeln über deren Reihenfolge. Auf Anwendungsebene kann jedoch nativ, also ohne das Hinzuziehen zusätzlicher Lösungen wie Istio, lediglich nach ICMP-Attributen gefiltert werden. Calico unterstützt als einziges der betrachteten Plugins das automatische Propagieren von sonst lediglich intern verfügbaren ClusterIPs mittels BPG, wodurch auf einen Load Balancer bzw. Ingres Controller zur Veröffentlichung von Services verzichtet werden könnte. Eine Lastenverteilung erfolgt dennoch, nämlich über mehrere Routen mit identischen Kosten (equal cost multi-path).
Abbildung 3 veranschaulicht den Aufbau des Podnetzwerks sowie die durch tcpdump ermittelten Datenpfade bei der Verwendung von Project Calico v3.8.1 mit IP-in-IP.

Eine Besonderheit im Vergleich zu der im ersten Teil dieser Serie aufgezeigten möglichen Implementierung eines Podnetzwerks (Abbildung 4) fehlen hier aus beschrieben Gründen ( proxy_arp) die Bridges. tunl0 stellt die Schnittstelle zu den übrigen Knoten dar. Sie ist immer mit der ersten Hostadresse des jeweiligen Subnetzes versehen und kapselt das ursprüngliche IP-Paket in ein umschließendes IP-Paket, um die Nutzdaten ohne NAT über das Underlay-Netzwerk übertragen zu können. Durch die von Felix erzeugten Routingregeln wird also an ein entferntes Subnetz gerichteter Datenverkehr grundsätzlich über diese Schnittstelle weitergeleitet.
Project Calico bietet seit v3.13 eine alternative Implementierung der Data Plane auf Basis von eBPF als Tech Preview. Details zu eBPF werden im Folgenden im Kontext von Cilium erläutert. Außerdem hat sich auch eine kostenpflichtige Variante (Calico Enterprise) etabliert, während Project Calico zum Zeitpunkt der Untersuchungen noch vollkommen kostenlos war. Mit v3.14 wurde zudem eine Data Plane Encryption mit Wireguard eingeführt (Tech Preview). Zum Zeitpunkt der Untersuchungen (Mitte 2019) bot Project Calico als einziges der drei Plugins noch keine Verschlüsselung der Data Plane.
Cilium
Cilium implementiert ebenfalls ein Layer-3-Netzwerk mit knotenspezifischen Subnetzen, setzt jedoch auf den weniger verbreiteten extended Berkeley Packet Filter (eBPF). Dabei handelt es sich um eine neue Linux-Kerneltechnologie, mit der sich Datenflüsse sehr flexibel und hardwarenah beeinflussen lassen. An verschiedenen Stellen im Kernel, den Hook Points, lassen sich BPF-Programme ausführen, die Datenpakete abfangen und manipulieren (z.B. blocken oder weiterleiten) können. Diese BPF-Programme werden in CPU-Instruktionen kompiliert, sodass sich die Datenpfade mit klassischen Linux-Bordmitteln nicht ohne weiteres nachverfolgen lassen: Während bei Calico die Ausführung von $ ip route bereits ausreicht, um die Funktionsweise des Podnetzwerks nachzuvollziehen, ist bei Cilium ein Studium der BPF-Programme notwendig. Diese werden durch den als DaemonSet ausgeführten Cilium Agent in Abhängigkeit des Clusterzustandes (wie etwa aktiven Pods und Network Policies) generiert, kompiliert und in den Kernel injiziert.
Standardmäßig setzt Cilium die knotenübergreifende Kommunikation mit VXLAN um, Geneve ist alternativ ebenfalls zur Encapsulation nutzbar. Falls es die Begebenheiten des zugrundeliegenden Netzwerks zulassen, kann jedoch auch bei Cilium auf ein Overlay verzichtet werden. Die BPF-Programme überreichen dabei die Datenpakete an die Routing-Funktion des Linux Kernels, statt sie für die weitere Übertragung einzukapseln. So können sie über die Kernel Routing-Tabelle weiterverarbeitet werden. Die Konfiguration der Routen übernimmt Cilium jedoch nicht.
Cilium setzt die Kubernetes Network Policies ebenfalls mit eBPF um und bietet ebenso wie Project Calico zusätzlich ein eigenes Netzwerkrichtlinienmodell in Form einer Custom Resource Definition. Darüber bestehen im Vergleich zu Project Calico und Weave Net die meisten Möglichkeiten zur Filterung auf Anwendungsebene, z.B. mittels HTTP-Attributen. Eine Besonderheit ist ein identitätsbasierter Ansatz. So müssen bei einer Netzwerkrichtlinie, die über Labels auf eine Gruppe von Pods angewendet wird, klassischerweise die auf den Knoten erzeugten Filterregeln ständig mit den aktuellen IP-Adressen der zutreffenden Pods aktualisiert werden. Schließlich können Pods häufiger hinzugefügt und gelöscht werden. Bei Ciliums identitätsbasierten Ansatz hingegen werden bei der Encapsulation der Nutzdaten von den Kubernetes Labels abgeleitete Identitätslabels vorangestellt. Diese ermöglichen eine deutlich effizientere Verarbeitung durch die BPF-Programme, als bei der Auswertung des IP-Header. Cilium bietet außerdem eine integrierte Verschlüsselung mittels IPSec, die sich bei Verwendung mit Overlay aber noch im Betastadium befindet.
Abbildung 6 fasst meine Untersuchungen hinsichtlich des Aufbaus und der mit tcpdump ermittelten Datenpfade bei der Nutzung von Cilium v1.5.5 mit VXLAN grafisch zusammen. Die durch Cilium verwendeten Hook Points sind ebenso wie die dort verknüpften BPF-Programme an den entsprechenden Stellen markiert. Am Traffic Control (TC) Ingress beziehungsweise Egress Hook können Programme für den eingehenden beziehungsweise ausgehenden Datenverkehr einer Netzwerkschnittstelle ausgeführt werden. Eingehend wird der Hook nach der initialen Verarbeitung eines Datenpakets durch den Netzwerkstack ausgeführt, allerdings noch vor Erreichen von Layer 3. Er eignet sich für die knoteninterne Verarbeitung von Datenverkehr, z.B. die Weiterleitung an andere Workloads. Cilium kann zusätzlich den Express Data Path (XDP) Hook nutzen, der sich z.B. bei der Verwendung von Network Policies für das frühzeitige und effiziente Verwerfen von unerwünschtem Datenverkehr anbietet: Entsprechende BPF-Programme werden über den Netzwerktreiber einer Schnittstelle ausgeführt, weshalb sich Datenpakete bereits vor Erreichen des Netzwerkstacks abgreifen lassen. Für die Nutzung des Socket Operation Hook sowie des Socket send/recv Hook muss Sockmap Acceleration aktiviert werden. Die Untersuchungen wurden mit dem Linux Tool tc zur Anzeige der Traffic-Control-Einstellungen im Kernel sowie mit bpftool durchgeführt. Letzteres dient zur Anzeige von BPF-Programmen am TC- und XDP-Hook. Der Quellcode der BPF-Programme ist auf GitHub einsehbar. Weitere Erläuterungen zu den Hook Points und BPF sind in der Dokumentation zu finden.
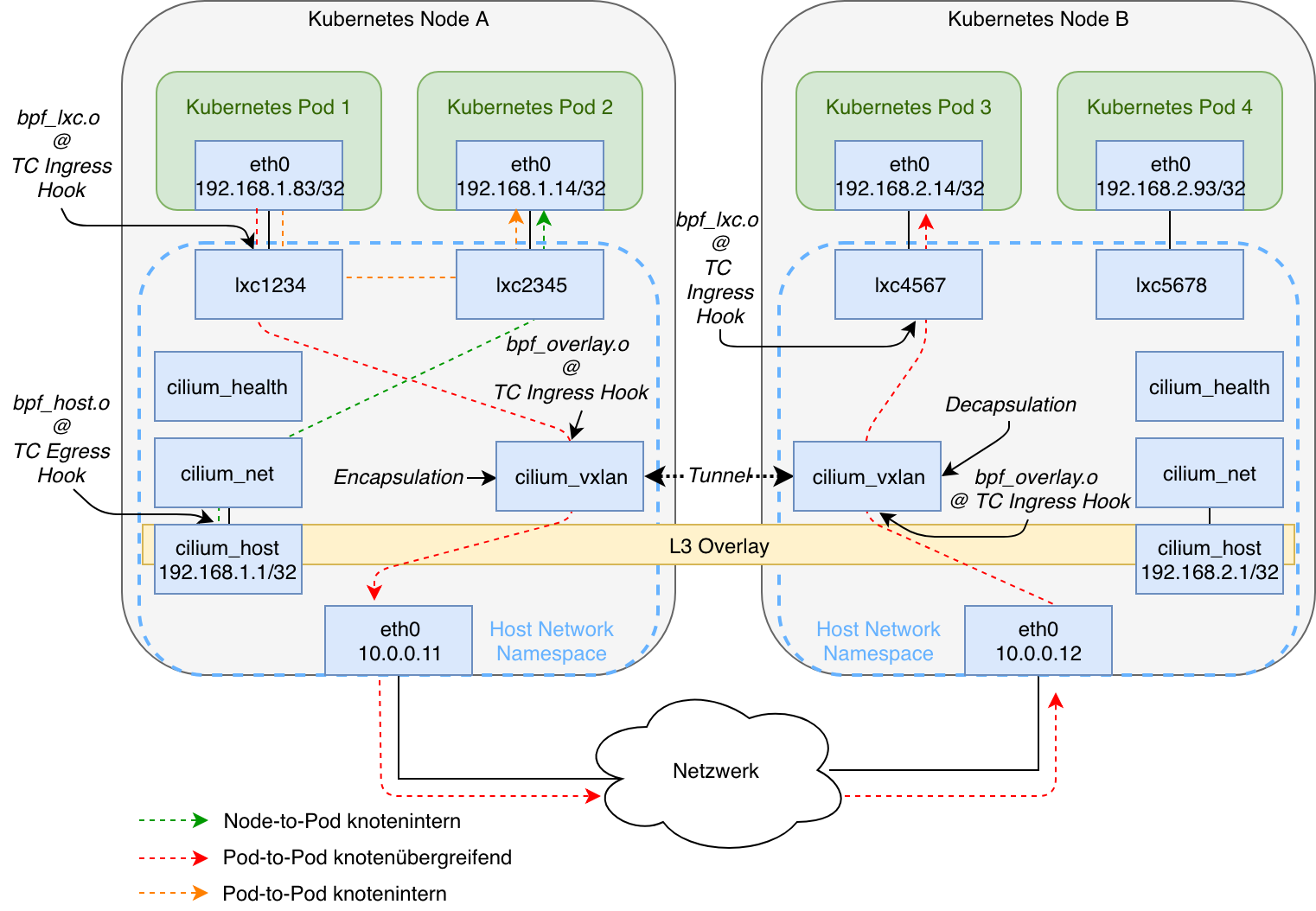
Die dargestellte cilium_host-Schnittstelle dient dem durch das Hostsystem initiierten Datenverkehr: Auf jedem Knoten existieren Routingregeln, nach denen an die knotenspezifischen Subnetze und somit an das Podnetzwerk gerichteter Datenverkehr über cilium_host geleitet wird. Dies hat den Effekt, dass dem initiierten Datenpaketen eine valide Quell-IP-Adresse aus dem Podnetzwerk für nachfolgende Antwortpakete zugewiesen wird
Seit meinen Untersuchungen Mitte 2019 sind auch bei Cilium viele Neuerungen und eine rege Weiterentwicklung zu beobachten. Mit Hubble existiert z.B. eine auf Cilium und eBPF aufbauende, verteilte Networking- und Observability-Plattform für cloudbasierte Workloads. Sie soll Einblicke in die Netzwerkinfrastruktur bieten sowie die Kommunikation zwischen Microservices transparenter machen. Auch die Verschlüsselung mittels IPSec ist derweil bei der Verwendung von nativem Routing (ohne Overlay) stable. Seit v1.6 wird außerdem in Verbindung mit Kubernetes kein separater Key-Value Store mehr benötigt, während zuvor bei der Installation von Cilium ein dediziertes etcd-Cluster erzeugt wurde. Auch auf kube-proxy und die damit verbundene Vielzahl an iptables-Regeln für die Umsetzung von Services kann nun durch einen auf eBPF basierenden Ansatz vollständig verzichtet werden. Mit v1.8 (Juni 2020) wurden weitere auf iptables basierende Funktionen durch native eBPF-Implementierungen ersetzt, wie z.B. die Umsetzung von Services des Typs NodePort.
Weave Net
Weave Net ist das älteste aller betrachteten Plugins und wurde ursprünglich für die Verbindung von Docker Containern entwickelt. Im Gegensatz zu Project Calico und Cilium spannt es ein clusterweites Layer-2-Netzwerk auf und nutzt dabei Standards wie das Address Resolution Protocol (ARP) und Forwarding Information Bases zur L2 Neighbour Discovery.
Für die knotenübergreifende Kommunikation stehen bei Weave Net zwei Methoden zur Verfügung: Der Fast Datapath Modus, der vollständig innerhalb des Kernels stattfindet, sowie der Sleeve Modus als Rückfall, bei dem Datenpakete für nicht-lokale Ziele im Kernel mittels pcap abgegriffen und durch den als DeamonSet ausgeführten Weave Router per UDP an den Weave Router des Zielknotens weitergeleitet werden. Da Weave Net ein virtuelles Layer-2-Netzwerk bereitstellt und damit simuliert, dass alle Workloads an einem gemeinsamen Netzwerkswitch angeschlossen sind, muss eine Overlay-Technologie für die knotenübergreifende Pod-to-Pod-Kommunikation eingesetzt und ausgehende, nicht-lokale Ethernet Frames eingekapselt werden. Das gilt selbst dann, wenn sich alle Knoten im selben lokalen Netzwerk befinden. Die Entscheidung, ob eine Verbindung im Fast DP Modus aufgebaut werden kann, wird je nach Begebenheiten knotenindividuell getroffen (siehe Abbildung 5):
Forwarding Information Bases werden sowohl innerhalb der knotenlokalen Linux Bridges als auch innerhalb der auf jedem Knoten ausgeführten Weave Router gepflegt. Letztere fungieren ins knoteninnere (also gegenüber den Workloads) wie klassische Switches. Sie sind einerseits mit der eigenen knoteninternen Bridge und andererseits logisch mit denen aller anderen Knoten des Clusters verbunden. Nach extern übersetzen sie jedoch von Layer 2 durch Encapsulation in Layer 3, um Ethernet Frames netzübergreifend übertragen zu können. Sie bilden über TCP eine Control Plane, tauschen Topologieinformationen untereinander aus und erkennen automatisch neue Knoten im Cluster. Durch die Kenntnis eines jeden Knotens, welche Knoten miteinander verbunden sind, können sie auch in teilvermaschten Netzen eingekapselte Frames über Intermediate-Knoten übermitteln.
Durch die zusätzliche Übertragung von Metadaten innerhalb des Weave-Net-eigenen Kapselungsformats (Sleeve Modus) beziehungsweise des VXLAN Headers (Fast Datapath) lernt jeder Knoten, der ein UDP-Datagramm mit eingekapselten Ethernet Frames zur Weiterverarbeitung erhält, über welchen Knoten die Absender-Pods (in Form ihrer MAC-Adresse) der eingekapselten Frames erreichbar sind. So baut jeder Weave Router – vergleichbar mit einem Switch – eine Informationsbasis auf und kann künftige lokal initiierte Frames zielgerichtet zustellen. Damit soll verhindert werden, dass Datenverkehr für nicht-lokale Ziele – wie bei einem Hub – an alle Knoten des Clusters gesendet wird. Liegen innerhalb der FIBs noch keine Informationen zur Lokalität des Zielpods vor, werden diese initial durch klassische ARP Broadcasts ermittelt.
Insofern sich die Knoten ohne NAT erreichen können und der Port 6784 freigegeben ist (typischerweise in lokalen Netzen), setzt Weave Net im Rahmen von Fast Datapath auf das Linux Kernelmodul Open vSwitch. Dabei erteilt der Weave Router aus dem User Space heraus Anweisungen auf Basis der von ihm gesammelten Informationen, wie Frames verarbeitet beziehungsweise weitergeleitet werden sollen. Fast Datapath läuft einschließlich der Encapsulation von Frames vollständig im Kernel ab und ist somit schneller und effizienter als die Verarbeitung des Datenverkehrs durch die Weave Router im Sleeve Modus. In letzterem sind mehrere Kontextwechsel notwendig, da Datenpakete von der initiierenden Applikation im User Space an den Kernel gereicht und anschließend durch den Weave Router im User Space wieder abgegriffen werden.
Weave Net setzt Kubernetes Network Policies mittels iptables um und kann jegliche knotenübergreifende Kommunikation verschlüsseln (Control Plane + Data Plane). Die genauen Mechanismen für die knotenübergreifende Kommunikation sind durch den Einsatz des Weave Routers beziehungsweise Open vSwitch ohne eine zusätzliche Einarbeitung weniger transparent. Weave Nets Architektur ist hingegen äußerst simpel gehalten: Das gesamte Weave Net Deployment besteht aus lediglich einem Pod pro Knoten (DaemonSet) mit einem Container für den Weave Router sowie einem weiteren Container für den Network Policy Controller. Ein verteilter Key-Value Store wird durch Weave Net nicht benötigt.
Abbildung 6 fasst meine Untersuchungen hinsichtlich des Aufbaus des Podnetzwerks und der mit tcpdump ermittelten Datenpfade bei der Nutzung von Weave Net v2.5.2 mit Fast Datapath grafisch zusammen.
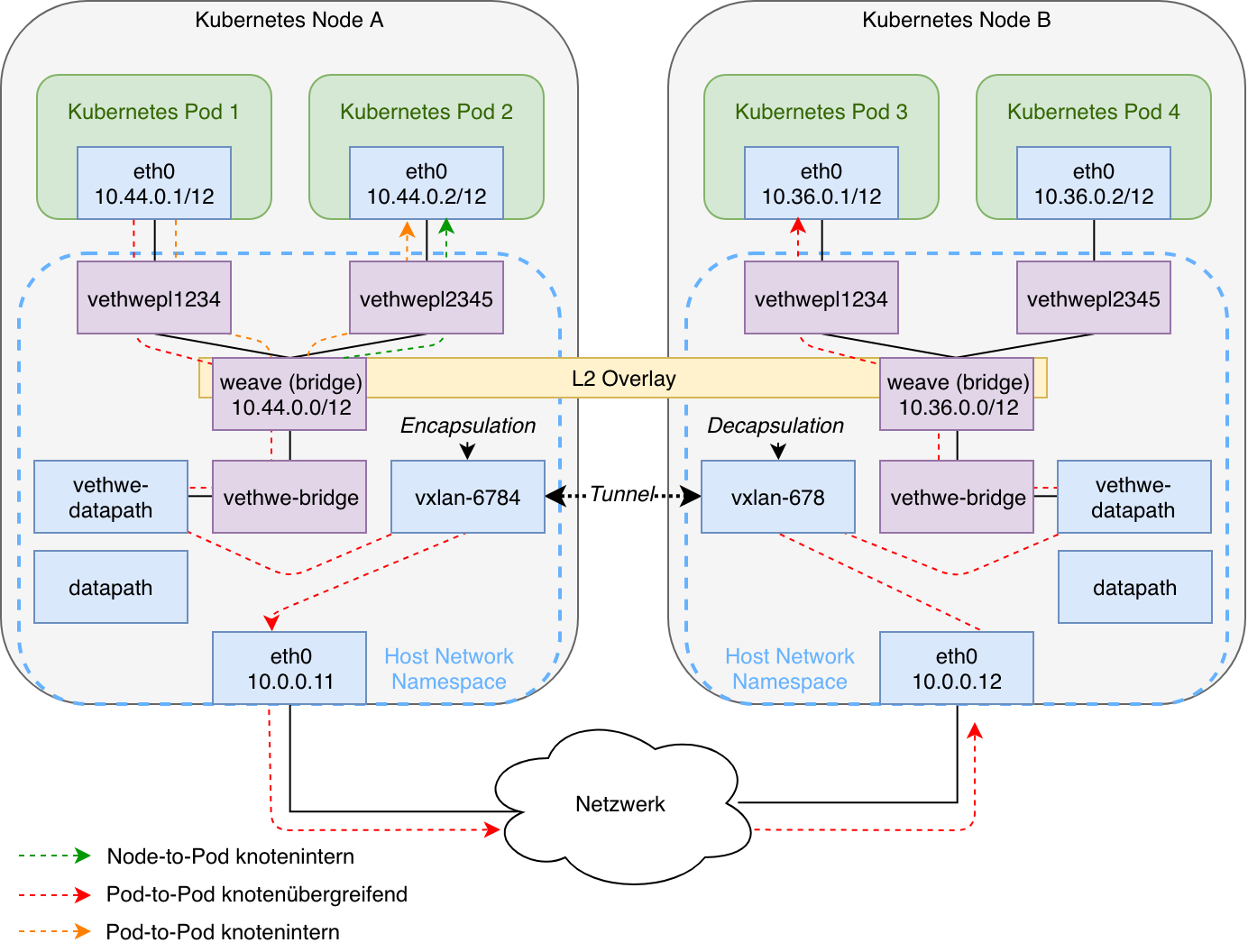
Durch den Knoten selbst initiierte und an das Podnetzwerk gerichtete Datenpakete werden via Routingregel über die weave-Bridge geleitet und dort mit einer validen IP-Adresse aus dem Podnetzwerk versehen. Das veth-Paar bestehend aus vethwe-bridge und vethwe-datapath stellt die virtuelle Ethernetverbindung zwischen lokaler Linux Bridge und dem Open vSwitch Datapath in Form der datapath-Schnittstelle dar, an der Datenpakete abgegriffen und injiziert werden.
Seit meinen Untersuchungen Mitte 2019 sind bei Weave Net (aktuell in v2.6.5 aus Juni 2020) im Vergleich zu Project Calico und Cilium hauptsächlich Bugfixes und Verbesserungen zu beobachten, wie sich den Releases auf GitHub entnehmen lässt. Erwähnenswerte neue Features blieben demnach aus.
Vergleichsmatrix
Wichtige funktionale und technische Merkmale der drei betrachteten Plugins sind in der am Ende dieses Artikels aufgeführten Vergleichsmatrix zusammengefasst. Sie kann beim Auswahlprozess unterstützen oder als Grundlage für den Vergleich bzw. die Untersuchung weiterer Kubernetes Netzwerk-Plugins herangezogen werden. Die Vergleichsmatrix wurde nach bestem Gewissen auf Basis meiner Untersuchungen und den Informationen aus den jeweiligen Dokumentationen zusammengestellt. Außerdem wurde sie im Rahmen dieses Artikels noch einmal auf den aktuellen Stand gebracht. Dennoch können die Daten aufgrund des Umfangs und der Komplexität der Thematik sowie der regen Weiterentwicklung von Project Calico und Cilium derweil unvollständig oder ungültig geworden sein.
Bewertung der Eignung
Project Calico kann als Allrounder eingestuft werden. Das Plugin besitzt keine nennenswerten Schwächen und bietet eine Kombination aus umfangreichen Netzwerk- sowie Sicherheitsfunktionen. Da es für den Aufbau eines Podnetzwerks neben BIRD ausschließlich auf Linux Bordmittel zurückgreift, ist es leicht verständlich und mit Netzwerkgrundkenntnissen leicht zu betreiben und zu debuggen. Infolge der uneingeschränkten Nutzungsmöglichkeit mit nativem Routing bietet sich Calico besonders für Projekte an, bei denen Zugriff auf eine physische Infrastruktur besteht und kein Overlay benötigt wird. Eine ausbleibende Encapsulation von Nutzdaten begünstigt durchsatzintensive Anwendungen. Aber auch mit Overlay stellt Calico für durchsatzintensive Anwendungen aufgrund der simplen und effizienten IP-in-IP Encapsulation mit lediglich 20 Byte Overhead eine gute Wahl dar. Dank BGP lässt sich ein durch Calico verwaltetes Podnetzwerk zudem ideal in vorhandene Netzwerkinfrastrukturen integrieren, z.B. durch das automatische Propagieren einer sonst ausschließlich clusterintern verfügbaren ClusterIP. Eine Skalierungsgrenze wird seitens Calico nicht genannt, lediglich bei über 4.000 Knoten sollte auf ein separates etcd-Cluster zurückgegriffen werden, statt den Kubernetes etcd über die Kubernetes API mitzubenutzen. Die Integration von Wireguard als Tech Preview ist ein wichtiger Schritt, um den Nachteil der fehlenden Verschlüsselung gegenüber Cilium und Weave Net zu eliminieren. Die nachträgliche Einführung einer eBPF Data Plane neben weiteren Features zeigt außerdem, dass das Projekt technologisch keineswegs stillsteht und auch zukünftig mit einer großen Dynamik zu rechnen ist.
Cilium kann als Netzwerklösung mit Sicherheitsfokus betrachtet werden. Umfangreiche Möglichkeiten hinsichtlich der Netzwerkrichtlinien sowie deren Verarbeitung durch einen identitätsbasierten Ansatz machen Cilium für Projekte attraktiv, bei denen umfassende Absicherungen zwischen vielen Workloads notwendig sind. Ist also im Voraus eine große Anzahl an Netzwerkrichtlinien abzusehen, sollte Cilium in Betracht gezogen werden, da der identitätsbasierte Ansatz im Vergleich zu einer Vielzahl von iptables-Regeln, die zudem auf jedem Knoten fortlaufend aktualisiert werden müssen, effizienter und schneller von statten gehen sollte. Außerdem wird die Effizienz und Skalierbarkeit eines Clusters durch den Verzicht auf kube-proxy und iptables bei der Umsetzung von Kubernetes Services begünstigt. Beides gilt es jedoch im Einzelfall durch weiterführende Tests zu prüfen. Die hohe Anzahl an Issues im offiziellen GitHub-Projekt sind ein Indiz für eine große Beliebtheit. Dass mit der Nutzung von Cilium der Einsatz der noch sehr jungen und komplexen Technologie eBPF einhergeht, muss berücksichtigt werden, bietet zugleich aber auch großes Potential, das zwischenzeitig auch durch Project Calico erkannt wurde. Cilium eignet sich nachweislich für sehr große Cluster und wurde mit 5.000 Knoten, 100.000 Pods und 20.000 Services getestet. Die zahlreichen neuen Features der letzten Monate, wie z.B. Hubble oder die stetigen Optimierungen rund um eBPF, belegen auch bei Cilium eine sehr aktive Weiterentwicklung und das regelmäßige Setzen von technologischen Maßstäben im Bereich Container Networking.
Weave Net kann als Netzwerk-Plugin mit dem Fokus auf Netzwerkfunktionalitäten zusammengefasst werden. Es kann die Konnektivität zwischen Pods in teilvermaschten Umgebungen durch die beschriebenen Selbstlernprozesse herstellen und eignet sich somit für Topologien, bei denen andere Plugins Probleme bereiten könnten. Die tatsächliche Praxisrelevanz solcher Szenarien bleibt jedoch fraglich. Aufgrund der Implementierung eines Layer-2-Netzes mit FIBs könnten in größeren Umgebungen mit einer hohen Knotenanzahl aufgrund der Entstehung großer Broadcastdomänen jedoch mitunter andere Lösungen geeigneter sein. Dies ist im Einzelfall durch weiterführende Tests zu überprüfen. Für Szenarien, in denen auf ein Overlay verzichtet werden soll, ist Weave Net nicht geeignet. Werden Filterfunktionen über die der Kubernetes Network Policies hinaus benötigt, stellen Calico beziehungsweise Cilium die bessere Wahl dar. Hingegen bietet Weave Net bereits am längsten eine stabile, integrierte Verschlüsselung der Data Plane. Bei der Skalierung eines Clusters mit Weave Net muss das Verbindungslimit der Control Plane beachtet werden, das standardmäßig 100 Verbindungen pro Knoten beträgt. Bei deutlich mehr Knoten kann es bei einer Vollvermaschung zu übermäßiger Rechen- und Netzwerklast kommen und eine Reduktion des Limits erfordern. Dies hätte eine teilvermaschte Topologie zur Folge, in der sich einzelne Knoten nicht mehr direkt erreichen können und Latenzen steigen. In Umgebungen der Größenordnung mehrerer hundert Knoten ist Weave Net daher im Vergleich zu Calico und Cilium weniger prädestiniert. Weave Net ist eine ausgereifte Netzwerklösung und konzentriert sich im Rückblick auf die letzten Monate primär auf Bugfixes und kleine Verbesserungen statt auf nennenswerte, neue Features.
Zusammenfassung
Was lässt sich aus den durchgeführten Untersuchungen nun schlussfolgern und zusammenfassen? Alle untersuchten Plugins sind einfach zu installieren und stellen die Konnektivität im Cluster zuverlässig her. Aus einer distanzierten Sichtweise heraus ist es schwierig, eine allgemeingültige Empfehlung auszusprechen, da jedes Plugin gleichermaßen gebrauchstauglich ist. Aufgrund der hohen Individualität von Anforderungen und zugrundeliegender Infrastrukturen kann und soll zudem kein „Testsieger“ ausgemacht werden – zumal die in meiner Thesis durchgeführten Messungen keine signifikanten Unterschiede aufwiesen, die die Untauglichkeit eines Plugins belegen würden. Hier würde die Entwicklung weiterführender Testszenarien, insbesondere unter dem Einsatz von Network Policies, Jumbo Frames oder performanterer Hardware mehr Aufschluss über die Tauglichkeit eines Plugins in bestimmten Einsatzszenarien geben. Dennoch zeichnen sich die verschiedenen Lösungen im Detail durch einige wichtige funktionale und technische Unterschiede aus, die in Abhängigkeit des durchzuführenden Projekts und der zur Verfügung stehenden Infrastruktur individuelle Vor- und Nachteile aufweisen und bei der Auswahl berücksichtigt werden sollten. Einige Aspekte habe ich in diesem Artikel dargelegt. Sie können ebenso wie die erarbeitete Vergleichsmatrix die Entscheidungsfindung maßgeblich unterstützen und ersparen eine zeitintensive Einarbeitung in die umfangreiche Thematik rund um das Kubernetes Networking. Vorab sollten allerdings zumindest die folgenden Fragen beantwortet werden, um eine Vorauswahl herausfiltern zu können:
- Welche Anzahl an Knoten ist zu erwarten?
- Bestehen Präferenzen hinsichtlich IPv4 oder IPv6?
- Bestehen Präferenzen hinsichtlich der Topologie des Podnetzwerks (L2 oder L3)?
- Wird ein Overlay benötigt?
- Wird eine integrierte Verschlüsselung benötigt?
- In welchem Umfang und auf welchen Layern sollen Network Policies zum Einsatz kommen?
Für eine verbindliche Aussage hinsichtlich des Verhaltens eines Plugins unter bestimmten Voraussetzungen sind situationsspezifische Tests unabdingbar. Einige Möglichkeiten für die Durchführung solcher Tests wurden zu Beginn dieses Artikels aufgezeigt, woran für zukünftige Untersuchungen angeknüpft werden kann. Da besonders Cilium und Project Calico bezüglich ihrer Weiterentwicklung einer großen Dynamik unterliegen – vor allem rund um eBPF – ist für ein vollständiges Bild eine regelmäßige Neubewertung der Plugins unerlässlich. Auch sollten weitere Plugins wie Flannel oder Kube-router, die im Rahmen meiner Bachelorthesis nicht betrachtet werden konnten, nicht außer Acht gelassen werden.
| Project Calico | Cilium | WeaveNet | ||
|---|---|---|---|---|
| Anbieter | Tigera Inc. | Isovalent Inc. | Weaveworks Inc. | |
| Preis | kostenlos, optional Calico Enterprise (kostenpflichtig) | kostenlos | kostenlos, optional WeaveCloud (kostenpflichtig) | |
| OpenSource / Lizenz | ja, Apache License, Version 2.0 | ja, Apache License, Version 2.0 (User Space Komponenten); General Public License, Version 2.0 (BPF Code Templates) | ja, Apache License, Version 2.0 | |
| Support | Community + kostenpflichtig | Community + kostenpflichtig | Community + kostenpflichtig | |
| Quellcode | https://github.com/projectcalico | https://github.com/cilium/cilium | https://github.com/weaveworks/weave | |
| Dokumentation | https://docs.projectcalico.org/ | https://docs.cilium.io/en/latest/ | https://www.weave.works/docs/net/latest/ | |
| Programmiersprachen | Go, Ruby, Python | Go, C | Go | |
| aktuelle Version | v3.14.1 (29.05.2020) | v1.8.0 (22.06.2020) | v2.6.5 (10.06.2020) | |
| erstes Release | 16.01.2015 (v0.10) | 28.03.2017 (v0.8.0) | 30.12.2014 (v0.7) | |
| Issues offen/geschlossen | 118/1105 (10,7%) | 440/3427 (12,8%) | 411/1713 (24,0%) | |
| Kernel Version | >= 3.10 | >= 4.9.17 (wegen eBPF) | >= 3.8 | |
| Kubernetes Version | >= v1.9, aktuelles Release getestet mit >= v1.16 | >= v1.9, aktuelles Release getestet mit >= v1.11 | >= v1.4 | |
| Empfehlung max. Clustergröße | 4k Nodes mit Kubernetes etcd, keine Angabe bei externem etcd | 5k Nodes, 100k Pods, 20k Services (durch Cilium getestet, mehr möglich) | (pro Knoten 100 Control Plane Verbindungen zu anderen Knoten) | |
| CLI-Tool | ja, calicoctl | ja, cilium-agent (in "cilium-*" Pods) | ja, weave | |
| Konnektivität | ||||
| IP-Versionen | IPv4, IPv6 | IPv4, IPv6 | IPv4 | |
| Adressierung / IPAM | knotenspezifische Subnnetze (mehrere pro Knoten bei Erschöpfung), optional Subnetting für verschiedene topologische Bereiche möglich | knotenspezifische Subnetze | clusterweites Netz, zusammenhngender Adressbereich pro Knoten, der untereinander dynamisch ausgehandelt wird | |
| Topologie Podnetzwerk | clusterweites Layer 3 Netzwerk | clusterweites Layer 3 Netzwerk | clusterweites Layer 2 Netzwerk | |
| Layer 2 Encapsulation | - | - | VXLAN (FastDP), eigenes Tunnel Protokoll (Sleeve) | |
| Layer 3 Encapsulation | IP-in-IP, VXLAN | VXLAN, Geneve | - | |
| Nutzung ohne Encapsulation | ja, natives Routing mit autom. Konfiguration (BGP) | ja, natives Routing mit manueller Konfiguration | nein, da knotenüberspannendes LAN (Layer 2) | |
| Standard-Konnektivität | L3 Overlay mit IP-in-IP Encapsulation | L3 Overlay mit VXLAN Encapsulation | L2 Overlay; knotenindividuell, vorzugsweise FastDP mit VXLAN Encapsulation | |
| Umsetzung Routing | Linux Kernel Routing, (alternativ extended Berkeley Packet Filter (eBPF) als "Tech Preview") | extended Berkeley Packet Filter (eBPF) | Weave Router selbstlernend (FIB) / Open vSwitch | |
| Standard MTU | 1480 Bytes (IP-in-IP) | 1450 Bytes (VXLAN, über Route in Workloads) | 1376 Bytes (FastDP) | |
| Key-Value Store / Datastore | Kubernetes etcd / CRDs (bis 4000 Nodes), etcd | Kubernetes etcd / CRDs (bis 250 Nodes), etcd, consul | lokal pro Knoten (/var/lib/weave/weave-netdata.db) | |
| Service Load Balancing | kube-proxy (intern), Propagieren der virtuellen ClusterIPs mittels BGP an externe Router mit Equal Cost MultiPath (extern), (eBPF anstelle von kube-proxy als "Tech Preview" (intern)) | eBPF anstelle von kube-proxy (intern) | kube-proxy (intern) | |
| Sicherheit | ||||
| Kubernetes Network Policies | Ingress + Egress mit allen durch die Kubernetes API unterstützten Funktionen | Ingress + Egress mit allen durch die Kubernetes API unterstützten Funktionen | Ingress + Egress mit allen durch die Kubernetes API unterstützten Funktionen | |
| Eigene Network Policies | Anwendung auf Ingress + Egress Traffic oder beide mit den Aktionen Allow, Deny, Log, Pass und den Match-Kriterien nummerierte Ports, Porträume, benannte Ports; Protokolle: TCP, UDP, ICMP, SCTP, UDPlite, ICMPv6; ICMP Attribute; IP Versionen (v4, v6); IP oder CIDR; Label-Selektoren; Namespace-Selektoren; Service-Account-Selektoren. Außerdem Sortierung / Priorisierung von Regeln | Anwendung auf Ingress + Egress Traffic oder beide mit der Aktion Allow und den Match-Kriterien nummerierte Ports, Porträume, benannte Ports; Protokolle: TCP, UDP; IP oder CIDR; Label-Selektoren, Namespace-Selektoren, Services, Entities, DNS-Namen, andere Cluster (MultiCluster); HTTP Attribute, Kafka Attribute (beta), DNS Attribute; Service-Account-Selektoren. Außerdem CiliumClusterwideNetworkPolicy: non-namespaced und cluster-scoped, ermöglicht die Nutzung von Node-Selektoren | nein | |
| Umsetzung Network Policies | iptables, (eBPF als "Tech Preview") | eBPF mit identitätsbasiertem Ansatz | iptables | |
| integrierte Verschlüsselung | (ja, WireGuard als "Tech Preview") | ja, IPSec (beta bei Nutzung mit Overlay) | ja, NaCi bei Sleeve, ESP (IPSec) bei FastDP |



Hallo Simon,
vielen Dank für deine informativen und verständlichen Blog-Artikel zum Thema „Kubernetes Networking“.
Ich habe diese Artikel (glücklicherweise) gefunden bei der Suche nach Informationen zu „Kubernetes Network“ und „Kubernetes Network Policies“.
Da meine Erfahrungen mit Kubernetes einerseits nicht über das Anfänger-Level hinausreichen und ich anderereseits aus der Legacy-Welt mit bare-metal Servern und Netzwerk-Segmentierung (WAN, LAN, DMZ) mit Firewall-Regeln komme wäre ich mich an einem weitergehenden Informationsaustausch mit dir interessiert. Hierfür möchte ich besser verstehen, wie man die Legacy- und Cloud-Native Welt bestmöglich zusammen bringen kann. Falls du Interesse an einem Diskurs hast würde ich mich über eine Email freuen.
Gruß
Thomas
Hey Thomas,
danke dir für deine Nachricht. Ich leite sie an Simon weiter.
Viele Grüße und weiterhin viel Spaß beim Lesen!
Hallo Simon, hast du vor, diesen Teil ins Englische zu übersetzen? Der erste Teil hat mir sehr gut gefallen und es fällt mir schwerer, ihn auf Deutsch zu lesen, obwohl mir die Verwendung von Übersetzern geholfen hat.
Ich warte auf die englische Version.
Grüße und Danke fürs Teilen.
Hey Carlos,
vielen Dank für dein Interesse! Leider werden wir den Artikel in absehbarer Zeit nicht übersetzen. Ich kann dir leider auch nur gängige Übersetzer empfehlen.
Viele Grüße!