
The term Data Mesh became very popular in 2022. Many blog posts describe the concept and common architecture of a Data Mesh. We would like to share with you our journey from a central data lake to a Data Mesh and the experience we gained in a project with a large media technology company over the last 16 months. We will also take a deep dive into the technical implementation of our approach.
Together with our customer, we were faced with the task of building a scalable data system solution that would serve as a platform for more than 30 teams that produce, consume, and share data within the company.
What happened in the past?
The traditional approach that many companies have used in the past is to transform their data platforms to be more focused on data.
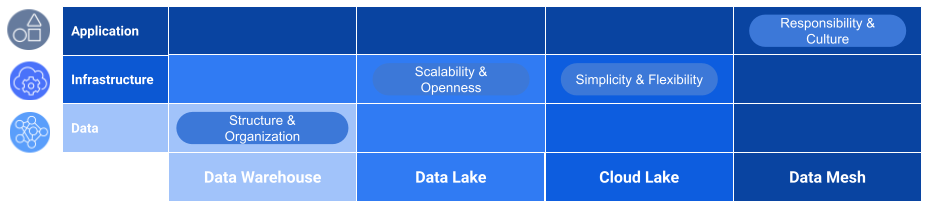
It often started with a large monolithic Data Warehouse, which reached its boundaries of flexibility and scalability with more and more data becoming available. As a consequence, on-premise data lakes were the medium of choice until cloud infrastructure became available whereas most of the on-premise lakes got shifted into the Cloud to become even more flexible.
Every platform architecture has its own pros and cons. However, if you are interested, please visit our events page for past talks about that topic at the Online Meetup, Breakfast Bits: Data Mesh.
We want to start our journey with the implementation of a cloud data lake and identify the pain points Data Mesh helps us with.
The cloud data lake
First of all, the Google Cloud Platform was chosen as the main cloud provider. The goal was to make use of the scalability and flexibility of the cloud to build ETL pipelines and store data. The data lake consists of four zones: the landing zone where data could be ingested by external providers, and the raw zone where data is copied over from the landing zone or loaded by dedicated processes and gets persists in its original and raw status. Following the raw is the cleaned zone, where data is cleaned and formatted to Parquet files. The files are subsequently loaded into the curated zone, where business aggregations take place and the data is transformed according to the consumer’s needs.
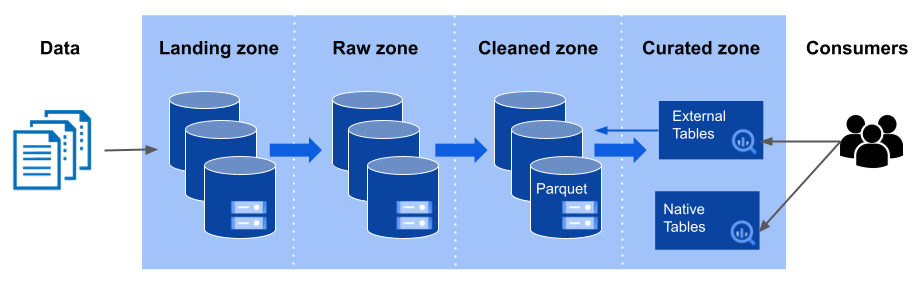
For all four zones, GCS buckets were used as a data storage solution. Furthermore, Big Query tables have been provided to simplify data access for consumers and stakeholders. In most cases, external tables were created on top of the Parquet files in the cleaned zone for exploration purposes. For production cases, additional procedures load data from the curated zone to native Big Query tables. This pattern has been applied to every data source that was on-boarded to the cloud data lake.
When using such a generic pattern, it is easy to handle the provisioning of the entire lake (resources and access) via Terraform, e.g. by providing different modules. The user who wants to onboard a new data source does not have to write any Terraform code. Instead, they define the source’s name in a YAML config file as well as the schema of the native table and the parties to whom he wants to give access to that new source. It is as easy as that!
So, what was the problem?
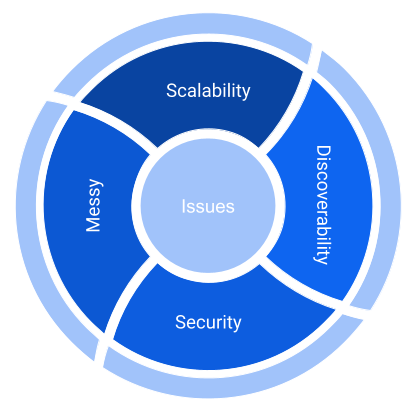
This approach has been successful and widely embraced by product teams utilizing the cloud lake as a data sink for their individual data products. The solution had one simple drawback: It does not scale very well with the increasing number of data product teams using it!
Bottleneck
One reason for that is, that the whole infrastructure was handled within one single Terraform state which was deployed via one repository. With more and more product teams using the data lake, more people needed access to this repository. Data products naturally evolve quite fast, thus it often happens that new tables get created or existing ones get changed. During the peak, we had 6-8 different product teams using the same repository to deploy their data infrastructure. Even in those circumstances, we found this repository to be a bottleneck, let alone if more than 30 teams were to use it.
Security
Another aspect is security. Due to the generalized approach of granting access through the same repository as the data infrastructure, it’s easy to provide access to individual buckets or tables. This is beneficial for all parties involved. However, due to the fact that everyone has access to the repository, basically, everyone can set permission for every resource without anyone else being aware of that.
Restricting repository access to only one data lake team could have increased the aforementioned bottleneck problem.
Missing Overview
With an increasing number of data sources being ingested in a centralized place, one can easily lose track of the current status of a particular data ingestion process. It might happen that a product team onboarded a data source in the past but then switched to another during product development. Alternatively, the entire product may have been discontinued while the data ingestion process remains in operation but is no longer adequately maintained. Potential consumers who explore the data lake may not be aware of whether the data is consumable or not.
In large companies, organizational restructuring is not uncommon. This often leads to the challenge of migrating processes and data between different departments. Data products may need to consume data from other departments that do not have the same infrastructure and conditions as the data product team. Two possible solutions exist for addressing these issues.
The first one is to migrate all data into a common one-fits-all-solution like a data lake. This solution is very unlikely to happen as it requires much effort and is cost-intensive. Furthermore, it does not scale well either, since it is likely to happen again for every new department or sub-team of which the data is needed.
The other solution is to do nothing and let the data infrastructure be as is. This results in having multiple data lakes within the same company that are completely different implemented and handled. The problem with this solution is that it can cause a complete loss of visibility over the company’s data. It’s even possible that different teams may onboard the same data source multiple times in their individual Data Lakes due to a lack of knowledge and documentation. As a consequence, data silos are created which nowadays is a pattern we definitely want to break.
Getting data infrastructure ready for the future
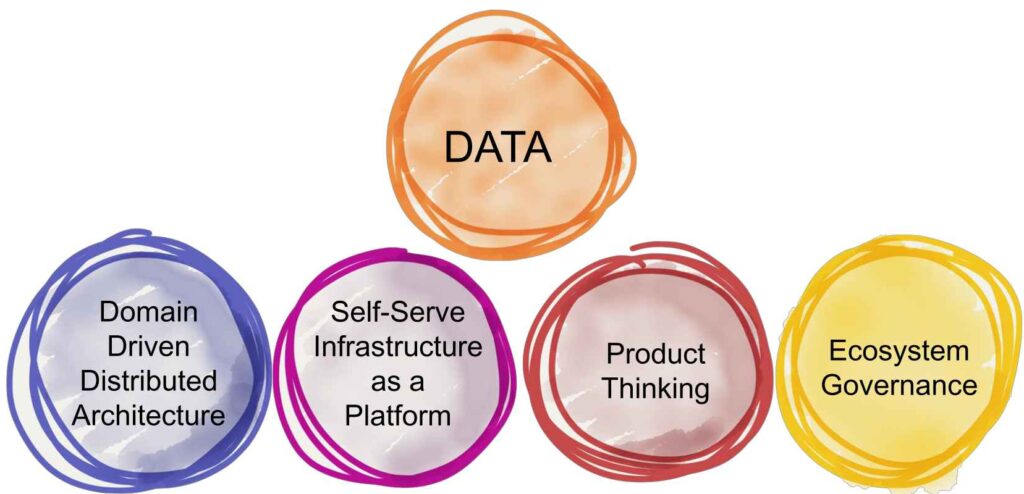
One paradigm that mitigates the problem of proper scaling within a data-driven company and becomes more and more popular, is the Data Mesh concept.
Data Mesh is not simply a technological solution but more a socio-technical approach with a wider vision. It puts data as the key asset into service to be produced and consumed as a product. This requires a complete restructuring and fundamental changes to the organization’s structure.
The fundamental Data Mesh principles are:
- Principle of Domain Ownership
- Principle of Data as a Product
- Principle of the Self-Serve Data Platform
- Principle of Federated Computational Governance
The central point is decentralization and distribution of responsibility closer to the product teams, which need to grow independently into cross-functional data product teams. We will not delve into the basics and principles of the Data Mesh concept further here, as there are numerous well-written blog posts and whitepapers available that cover this in detail. If you are interested in the fundamentals of the Data Mesh, its principles, and concepts, we can highly recommend reading ‘Data Mesh’ by Zhamak Dehghani or this blog by Martin Fowler.
Organizational structure
As stated many times in various sources, the implementation of a Data Mesh is an organizational challenge in particular. To overcome this challenge, it is necessary to have a team setup within the organization that fits with the principle of a Data Mesh.
After almost a year of having the Data Mesh established and some reorganizations, the team setup is looking as follows:
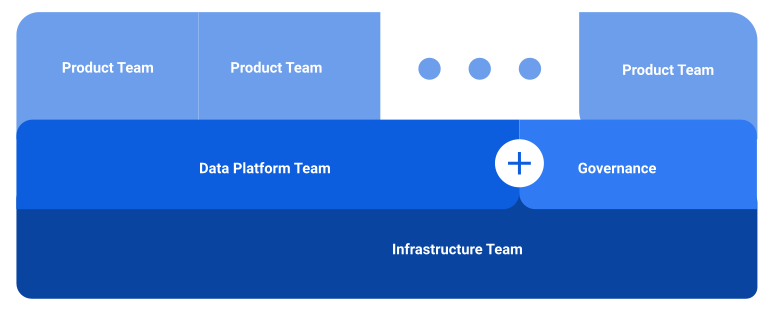
Infrastructure is key
All product teams are supported by a central infrastructure team which provides all core infrastructure components that a product team needs. That contains a set of GCP projects (development, staging, prod), Gitlab repositories for terraform deployments, and Argo CD configs.
Teams can optionally order GKE clusters, Airflow (on GKE), Cloud SQL instances, and other infrastructure parts. What is important to mention here is that by this setup product teams already have a separate place where they can store data and develop and run their productive workflows. As a result, product teams are kept separate, providing flexibility and serving the purposes of security and the principle of least privilege.
The data platform team is putting it all together
The engine of the Data Mesh is the data platform team. This team provides the tools and services that enable the company to actually make use of the Data Mesh. An example could be a central service of making data accessible across teams or a GDPR service, which serves as the central place where GDPR requests are distributed across the company and handled. It also maintains and offers the company-wide data catalog, which is essential in the context of a Data Mesh (more on that later). The team collaborates closely with the governance team as the technical point of contact for governance-related matters.
Together with the infrastructure team, the platform team is responsible for bringing the “self-serve data platform“ principle to life. In addition, it should try to establish and preserve common concepts. Due to the fact that many teams work independently in their domains, it is important that knowledge is shared, and the wheel does not get reinvented by each team every time. The team should keep an overview of the tools and services used in the company and give advice across all the teams trying to guide them in the best way possible.
Product teams: the reason for existence
The product teams are the reason why the Data Mesh exists. They create data products and therefore onboard and own data that they need to accomplish their work. These teams are responsible for fulfilling the “data as a product“ principle by considering their data not only to be something that is needed for their individual data products but also that a well-maintained and documented dataset itself can bring high value to the rest of the company, too.
Governance keeps an eye on the data
With the product teams creating and owning datasets and the data platform and infrastructure team providing everything needed from a technical perspective, the governance team is the team that looks from a business side on the data. They are the business owner of the data catalog, have an overview (and also business insights) of all the data within the company, and can make decisions about which team is allowed to consume which data.
Implementing the Data Mesh
After the team structure is clear, we are now going to sketch the implementation of our Data Mesh approach on GCP with the mentioned conditions. It will not include all details but will instead focus on the main points to establish the foundation of the implementation.
Since all teams and processes use native GCP tooling like BigQuery for relational data, Google Cloud SQL, Google Cloud Storage, Google Kubernetes Engine, BigTable and PubSub, we had no need of reconsidering this whole setup and could directly start the evolution to a Data Mesh architecture.

Making data accessible
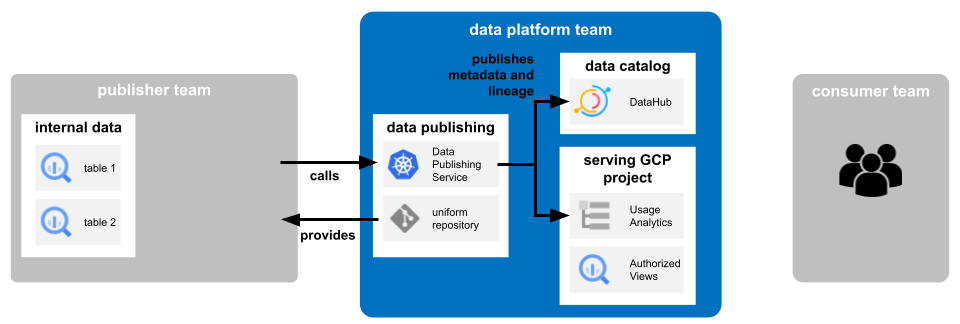
As core technology, we are using Google’s flagship database BigQuery. In order to fulfill the principle of domain ownership, it is important that the data that a product team owns reside in their space. Only the owners have access to the tables containing the data and are able to modify it. But that alone would result in data silos. To get real value out of the domain-ownership and data-as-a-product principle, we need to find a concept, to share data across teams without duplicating it so that the actual owner of the data stays the same all the time. We achieved this by using authorized views to enable other teams to access data. The process of sharing data across teams and domains is called data publishing according to Google.
The benefit of authorized views is that you can manage the access only in the GCP project of the data publisher, without the need to have extensive IAM permissions on source projects. Through these views, owners can gain access to new consumers but do not have to duplicate data, which reduces storage costs and does not violate any governance subjects. It is also possible to define a view, only showing a subset of a dataset which might become relevant if sensitive columns, like PII, exist in this data and thus can be hidden as not all product teams are usually allowed to see such information.
For the computational governance principle, we wanted to create a central place where all shared data is visible, searchable, and consumable. This was done in two parts:
For the users, this place is the DataHub data catalog. For technical access, we established one GCP project to serve all the authorized BigQuery views but without any project-wide IAM permissions for the product teams. That means all access and usage of data across teams and domains run through this single GCP project. To prevent Big Query usage costs from being mapped to this single project, we do not grant the teams
bigquery.jobs.create permissions there. As a consequence, the teams are pushed to create the Big Query jobs in their respective projects and therefore all costs are automatically assigned correctly to them.
Data publishing made easy
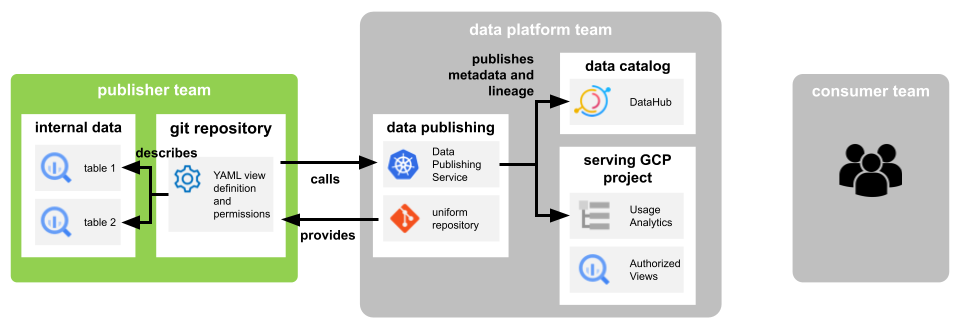
To make it as comfortable as possible for the product teams to publish data we built components and services around the publishing process every team gets provided with. In the center of this process stands a REST service, taking care of the creation of authorized Big Query views and managing access to those. To simplify and unify the communication between the teams and the service, we created a library that takes care of all necessary steps during the publishing process. This library is offered as a Python package. The only effort that a “publishing team“ has, is the definition of their views which are created through SQL queries, and the specification of entities that can access those views (single users, groups, or service accounts).
To have a common way of doing this, we provide a single git repository for each product team, where they can define the views and access in a simple YAML structure. The Gitlab CI pipeline of this repo runs a container where the above-mentioned library is installed. It calculates a “diff“ between the state that is defined in the repo and the views currently existing in the serving GCP project. After that, it makes the API calls to the publishing service to create, update, and delete entire views or to modify the access permissions accordingly.
As already mentioned, the creation and modification of the shared views in the serving project is done by the publishing service. Each publishing team has a dedicated service account that is allowed to update the datasets owned by the publishing team in the serving project. However, the authorization of these shared views needs to happen on the source datasets that still reside in the GCP projects of the respective data-owning team. What we definitely wanted to avoid is a god-like service account that has access to all data across the company to be able to create authorizations in every team’s projects as this would be a major security breach. We solved this challenge by the following steps:
- The service account that is running the CI pipeline of the config repo grants temporary Big Query read permissions on the internal source tables to the dedicated publishing service account of the respective team.
- The service account running the publishing service is allowed to impersonate the publishing service account of the team. That means, during the impersonation, the publishing service account has the right to read data from the source tables in the team’s projects and to modify the respective datasets in the serving project.
- Perform CRUD operations or modify access.
- Remove temporarily granted read permissions in the source data.
All this happens automatically inside the CI pipeline during deployment. The data publishing team does not need to be concerned about any of this. The only effort they have is to write some YAML files.
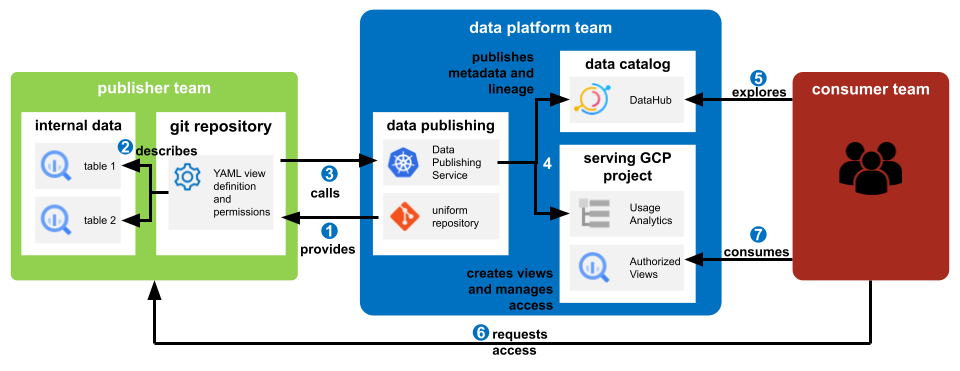
Data Catalog
The central and mandatory part for discoverability and lineage tracking and the first stop point for analysts and management is the data catalog. We decided to use DataHub instead of the data catalog provided by Google. DataHub is an open-source project offering a lot of source connectors already and is easily extendable and adaptable to our needs. Its clean interface and powerful functionality promise to be future-proof. If you are interested in learning more about DataHub and especially how it performs in comparison to its competitors, we recommend checking out this blog post.
Metadata of all shared tables gets automatically ingested into the catalog by a regularly scheduled Airflow DAG. To be able to do so, the service account running the DAG, has read permissions for the metadata of the authorized views in the central serving GCP project. The entities in the catalog are labeled with the producing team, consumers, and other relevant properties by custom transformers we built especially for the present use cases. And additionally, the lineage to the source table is ingested by analyzing the query, the view is created with. If teams want to publish more tables, which they have in their space and could probably be consumed by other teams, they can use the same config repositories mentioned above to create DataHub recipes which get picked up by the DAG as well and therefore enrich the catalog with more information.
With the help of the data catalog, the consuming team is able to explore the metadata like schema, description, and labels of all data across the company. When they identify a dataset that could help to achieve their goal they can request access from the publishing team. If the governance team has no complaint, the publishing team can give access via the process outlined above.
What we learned in more than one year with a Data Mesh
During the process of rolling out the Data Mesh approach in the company, we collected some learnings we want to share with you:
- Time is everything
As stated above it is not just the technical implementation of a Data Mesh but more a cultural shift and these processes naturally need time. So plan a rollout over months including more and more teams and meanwhile improve the technical requirements to speed up getting on board and make contributions easy. - It is an organizational shift
Building a common understanding of the concepts and benefits raises acceptance and is key to success. - Onboard the teams
In a data product team, the tasks and responsibilities slightly increase, therefore it’s important to stay in touch with the teams and help them to get into this process. They need to take over the complete ownership of the data they onboard and publish. Especially if other teams consume that data and build data products on top of it they need to have a look at the availability and reliability of the data. Changes in the structure do not only affect themselves but also other teams, so they need to be planned and communicated earlier. All in all, there is a bit more work to be done, even if the team itself is just in a kind of maintenance mode of their product. This needs to be considered. - Visibility of the process
Another learning we had is the importance of a structured process on how data gets published and how to gain access to it for consumers.
To prevent doing it on just a technical level and maybe overlook some usage restrictions not only the producing and consuming team but as well a dedicated governance team should be involved. For us, introducing a new JIRA board which includes all steps, was a good solution as it helped us visualize the steps, assign the tasks to the responsible people, and unify the procedure.
Having a dedicated, possibly small, governance team was a great benefit to have contact persons to decide on naming and legal aspects, … and support the data owners in questions they could not answer on their own. - Product team staffing
A point to not underestimate is the staffing of an independent product team. As there is no central data team anymore, each team would need at least one engineer to set up all the infrastructure and data pipelines.
Possible next steps in the journey
Even if the approaches are already in production use for months, the journey did not end, and we can think of future improvements and enhancements that could increase the value and allow new use cases. To just name a few of the thoughts we had:
- Increase data catalog integration and enrichment with metadata from different systems.
- More data sources, e.g. dbt, Power BI, …
- More metadata, in particular the quality level by integrating Great Expectations results in the data catalog and adding evaluations.
- Add automated usage analytics of shared tables to find abandoned sources and use this information for cost and maintenance reduction.
- Add a kind of impact analysis and notification of downstream consumers if schemas change, views get deprecated, and new data sources are published.
- Get the governance process more automated, e.g. having a service looking up if a data source can be consumed by a specific team without the need for someone from the governance team looking into that because the data source is not PII relevant.
With this outlook, we will close this article about our journey and look forward to the new things we will learn and discover about the Data Mesh in the upcoming time. If you are also working on similar topics, we would like to hear about your learnings and discuss new approaches. Feel free to contact us for an exchange.


