
Hinweis:
Dieser Blogartikel ist älter als 5 Jahre – die genannten Inhalte sind eventuell überholt.
COVID-19 – dieses Jahr ist alles anders – und dennoch soll die Ausbildung von Schüler:innen nicht auf der Strecke bleiben. Am 22.6. haben wir den – ursprünglich in unserem Hamburger Office geplanten – Techday zum Thema „Was ist Künstliche Intelligenz (KI)“ im Rahmen des Begabtenförderungprogramms mint:pro der Initiative NAT als Webinar stattfinden lassen.
„KI“: Was steckt hinter dem Begriff?
KI ist in aller Munde. Aber was ist eigentlich KI? Auch wenn häufig der bekannte Turing-Test zu Rate gezogen wird – eine eindeutige Definition von KI gibt es nicht. Nicht zuletzt, weil es bereits an einer exakten Definition von „Intelligenz“ mangelt. Ob also schon das Erkennen der Ampelfarbe als intelligent eingestuft wird oder erst das selbstfahrende Auto im Gesamten, liegt ganz im Auge des Betrachters.
Das Themengebiet KI ist breit, das Interesse der Schüler:innen groß. In einem Lean Coffee sammeln wir nach einer kurzen Webinar-Einführung ihre brennendsten Fragen: Wie lernt die KI? Wie funktionieren Algorithmen, die unser Online-Verhalten tracken? Kann KI auch Emotionen erkennen und darauf reagieren? Was sind die Gefahren einer KI?
All diese Gedanken waren Thema des Webinars. Wenn auch nicht in der Tiefe beantwortet, war unser Ziel, den Schüler:innen eine grobe Vorstellung davon zu vermitteln, wie KI funktioniert.
KI-Modelle mit Zümi 

Wir können Farben sehen und zwischen ihnen unterscheiden, aber wie können wir diese Fähigkeit einem Computer beibringen, der noch nie etwas von Farben gehört hat? In einer Live Demo haben wir unserer kleinen Zümi das Erkennen verschiedener Farben beigebracht. Hierbei handelt es sich um ein sehr grundlegendes Beispiel für maschinelles Lernen, einer Klasse von Algorithmen zur Umsetzung von KI. Das Vorgehen lässt sich in drei Schritten zusammenfassen: Erstens, die Sammlung und Vorverarbeitung von Trainingsdaten, zweitens, die Auswahl eines geeigneten Modells und dessen Lern- oder Trainingsphase und drittens das Anwenden des trainierten Modells – der sogenannten Vorhersage-Phase.
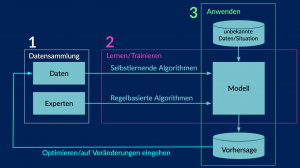
1. Datensammlung und -vorverarbeitung: Über Zümis Kamera haben wir jeweils 50 Bilder von verschiedenen Farbkarten in Grün und Rot gemacht. Der kleine Computer in Zümi, ein Raspberry Pi Zero, verarbeitet die Bilddaten, indem er für jedes Bild drei Zahlen aus dem HSV-Farbraum speichert. HSV steht für Hue (Farbton), Saturation (Sättigung) und Value (Wert). Der Farbton liegt normalerweise im Bereich zwischen 0 und 360 und repräsentiert die Farbe. Die Sättigung steht für die Farbintensität und der Wert gibt an, wie hell oder dunkel die Farbe ist. Da Zümi bisher noch keine Farben kennt, müssen wir beim Generieren der Beispieldaten jedem Foto eine entsprechende Farbinformation zur Beschriftung (Labeling) zuordnen. Diese „historischen“, beobachteten Daten, der Trainingsdatensatz, können dann für das Training eines Modells verwendet werden.

By loading the video, you agree to YouTube's privacy policy.
Learn more
2. Modellauswahl und Training: Wir entscheiden uns für ein sehr einfaches Modell: der \(k\)-Nächste-Nachbarn-Algorithmus. Dabei handelt es sich um einen Algorithmus zur Klassifizierung. Das Modell klassifiziert jedes Bild durch eine Farbklasse (hier Rot und Grün).
3. Anwenden: Damit Zümi die Farbe (Klasse) einer neuen Beobachtung auf Basis der von uns erstellten Trainingsdaten erkennen/vorhersagen kann, werden die \(k\)-ähnlichsten Nachbarn aus dem Trainingsdatensatz ermittelt, d.h. der Euklidische Abstand zwischen der neuen Beobachtung und allen Beobachtungen aus dem Trainingsdatensatz wird berechnet und die kleinsten \(k\)-Abstände werden ausgewählt. Die Farbe, die unter den \(k\)-nächsten Nachbarn am häufigsten vertreten ist, wird dann auch bei der unbekannten Beobachtung angenommen. Eigentlich ganz einfach. 🙂
Künstliche Neuronale Netze und Grenzen von KI
Mit der Anforderung der Aufgabe steigt in der Regel auch die Komplexität eines KI-Modells. Möchte man zwischen mehr als nur Grün und Rot unterscheiden und spielen zusätzlich noch Faktoren wie Licht und Schatten, Unreinheiten auf Bildern und Videos eine Rolle, reicht ein \(k\)-Nächste-Nachbarn-Algorithmus ganz schnell nicht mehr aus. Sogenannte Künstliche Neuronale Netze können zum Einsatz kommen.
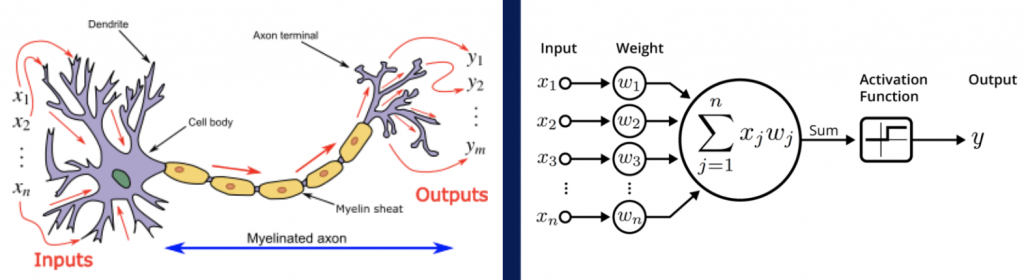
Die Anzahl der Neuronen sowie der Neuronenschichten und der damit einhergehenden Verbindungsmöglichkeiten der Neuronen verschiedener Schichten, bestimmt die Komplexität des Künstlichen Neuronalen Netzes und die Fähigkeit, Aufgaben zu lösen. Je komplexer das Modell ist, desto schwieriger ist es aber, den Output einer Vorhersage durch das Netz zu erklären. Die Erklärbarkeit, wieso sich ein Künstliches Neuronales Netz für einen bestimmten Output entscheidet, ist ein großes Problem (hier könnt ihr mehr dazu lesen). Deshalb werden diese Modelle meistens auch als Blackbox bezeichnet.
Falsche Zuordnungen oder auch völlig falsche Vorschläge gibt es immer mal wieder: natürlich ist nicht jedes trainierte Modell perfekt! Beispielsweise sorgte ein verändertes Bildpixel am Vorderrad dafür, dass kein Auto, sondern ein Hund erkannt wurde [2]; ein Algorithmus von Google klassifizierte 2015 fälschlicherweise dunkelhäutige Menschen als Gorillas [3]; gezielte Angriffe mit ausgefallenen Brillen haben Gesichtserkennungssysteme geschlagen (hier könnt ihr mehr dazu lesen) [4]; und kommerzielle Gesichtserkennungssysteme bestimmen das Geschlecht jeder dritten nichtweißen Frau falsch [5]. Die Gründe dafür zu finden, ist nicht immer einfach. Fest steht, dass die Entscheidungsfindung durch ein KI-Modell maximal so gut sein kann wie die Informationen aus den Trainingsdaten, mit denen es „gefüttert“ wurde.
Wie geht es weiter?
Das Feedback zum Webinar der Schüler:innen war durchweg positiv: Sie haben den Aufwand des Trainings eines Modells live erlebt und so besser verstanden. Das Zümi-Beispiel hat verdeutlicht, dass zahlreiche Modelle für KI bereits in Funktionen programmiert sind und zum eigenen Training verwendet werden können. Die Gefahren und Chancen einer KI wurden ebenfalls besser verstanden.
Das Thema KI entwickelt sich extrem schnell – Ängste und Zweifel entstehen. „Künstliche Intelligenz“ ist ein Buzzword und viele Menschen wissen einfach nicht, was genau dahinter steckt. Letztendlich ist KI nur eine Vision. Oder wie Andrew Ng es ausdrückt:
„Fearing a rise of killer robots is like worrying about overpopulation on Mars“.
Die Gefahr einer starken KI wird übertrieben dargestellt, dennoch muss stärker anerkannt werden, dass schwache KI schnell dazu tendiert, einen Bias (engl. Verzerrung) zu verstärken, der in den Trainingsdaten steckt. Deshalb ist es unerlässlich, die zugrundeliegenden Daten und Modelle aktiv zu analysieren und gegebenenfalls gegenzusteuern. Dafür braucht es Expert:innen.
Wer KI produktiv im Alltag einsetzen möchte, weiß, dass KI ein Mannschaftssport ist. Nicht nur Data Scientists und Machine Learning Engineers sind gefragt, sondern auch Expert:innen für Softwareentwicklung, Datenbanken-Managementsysteme, rechnergestützte kognitive Wissenschaften und noch viele mehr. In den kommenden Monaten planen wir weitere kleine Remote-Workshops für die Schüler:innen, in denen wir einzelne Themen gezielt vertiefen. Wir möchten den Schüler:innen einfache Werkzeuge an die Hand geben, damit sie ein Verständnis für die Vision „Künstliche Intelligenz“ erlangen, Vertrauen aufbauen und eine Idee für ihre eigene Zukunft entwickeln können.
Read On
Möchtest du mehr über das Begabten-Förderungsprogramm mint:pro lesen und vielleicht im nächsten Jahr selbst teilnehmen? Dann schau gern auf der Website der Initiative NAT vorbei, oder stöbere durch die Erfahrungsberichte aus den letzten Jahren:
2020
Kickoff:
-
-
- Oberstufenschüler entwickeln Start-up-Ideen im KI-Bereich – Für den Nachwuchs: Hammerbrooklyn Youth Innovation Center und Initiative NAT kooperieren
- mint:pro 2020: Schüler:innen entwickeln KI-Geschäftsideen
-
2019
Kickoff:
-
-
- Im Inkubator der NAT: Begabtenprogramm mint:pro „Start-up und KI“
-
Programmtage:
-
-
- mint:pro 2019: Hamburger Schüler:innen entwickeln eigene KI-Anwendungen
- Ganz schön ambitioniert! mint:pro Gründerteams erkunden Planet AI in Rostock
- Access to Justice! Feedback für mint:pro Idee „Legal IT“ an der Bucerius Law School
-
Abschluss:
-
-
- Flagge gehisst: mint:pro Gründer präsentieren auf dem Hamburg Innovation Summit
-
2018
-
-
- Luft nach oben: Neues NAT-Programm verbindet KI und Start-ups
-
Literatur und Bildquellen
[1] „Biological neuron model,“ Wikipedia. Jun. 24, 2020, Accessed: Jun. 30, 2020. [Online]. Available: https://en.wikipedia.org/w/index.php?title=Biological_neuron_model&oldid=964313675.
[2] H. Fry, Hello World: Was Algorithmen können und wie sie unser Leben verändern, 2nd ed. München: C.H.Beck, 2019.
[3] D. SPIEGEL, „Google Fotos bezeichnet Schwarze als Gorillas – DER SPIEGEL – Netzwelt.“ https://www.spiegel.de/netzwelt/web/google-fotos-bezeichnet-schwarze-als-gorillas-a-1041693.html (accessed Jun. 30, 2020).
[4] M. Sharif, S. Bhagavatula, L. Bauer, and M. K. Reiter, „Accessorize to a Crime: Real and Stealthy Attacks on State-of-the-Art Face Recognition,“ in Proceedings of the 2016 ACM SIGSAC Conference on Computer and Communications Security, Vienna Austria, Oct. 2016, pp. 1528–1540, doi: 10.1145/2976749.2978392.
[5] J. Buolamwini, „Wie ich Vorurteile in Algorithmen bekämpfe.“ https://www.ted.com/talks/joy_buolamwini_how_i_m_fighting_bias_in_algorithms?language=de (accessed Jun. 30, 2020).
