
Der weit verbreitete Einsatz von Software kann nicht nur das alltägliche Leben der Menschen, sondern auch deren Umwelt beeinflussen. In Anbetracht der Klimakrise ist es umso wichtiger, ökologisch nachhaltige Software zu entwickeln. Doch gleichzeitig soll die Entwicklung und der Einsatz eines Softwareprodukts oft auch positive wirtschaftliche Effekte haben. Dieser Blogartikel behandelt die Frage, inwiefern Clean Code die Nachhaltigkeit der effizienten Softwareentwicklung beeinflusst und welche Folgen dabei entstehen. Um dies zu beantworten, werden sowohl die Kriterien zum Definieren und Entwickeln nachhaltiger Software herausgestellt als auch die ökologischen und ökonomischen Auswirkungen hinsichtlich der Ziele von Clean Code untersucht. Hierfür wurden entsprechende Messungen zu konkreten Implementierungen durchgeführt, ausgewertet und Handlungsempfehlungen vorgestellt. Dabei wurden Untersuchungen zu folgenden Szenarien gemacht: Ein Decorator Design Pattern vs. Decorator Anti Design Pattern, das Anwenden und nicht Anwenden von Caching, Inlining vs. Anti-Inlining, Rekursion vs. Iteration sowie Loop vs. Loop Unrolling.
Nachhaltige Software
Ökologisch Nachhaltige Software hat geringe Hardwareanforderungen und kann langfristig eingesetzt werden. Dabei sollte der Energieverbrauch von CPU-Zeit, Arbeitsspeicher, Festplatten- sowie Netzwerkzugriffen möglichst gering gehalten werden, ohne dabei die Funktion einer Software negativ zu beeinflussen (vgl. Umweltbundesamt (2015): 31). So hat die Ausführung einer Software auf unterschiedlicher Hardware verschiedene Effekte. Es gibt bereits einige Ansätze und Richtlinien zum Entwickeln nachhaltiger Software. So bietet der „Blaue Engel“ Vergabekriterien für ressourcen- und energieeffiziente Softwareprodukte (DE-UZ 215). Eine als solche ausgezeichnete Software gilt als besonders transparent, frei im Umgang durch deren Anwender:innen und energiesparend bei der Nutzung von Hardware-Ressourcen. Die Vergabekriterien werden in die Bereiche Ressourcen- und Energieeffizienz, potenzielle Hardware-Nutzungsdauer sowie Nutzungsautonomie aufgeteilt (siehe https://www.blauer-engel.de/de/produktwelt/ressourcen-und-energieeffiziente-softwareprodukte). Zudem bietet das Umweltbundesamt weitere Orientierung (siehe https://www.umweltbundesamt.de/themen/wie-software-gruener-werden-kann-ergebnisse-eines).
Von ökonomisch nachhaltiger Software ist die Rede, wenn die investierten Mittel in deren Entwicklung durch den Einsatz oder den Verkauf der Software die Maximierung oder den Erhalt des daraus entstehenden Ertrags gewährleistet.
Sozial nachhaltige Software kann z. B. durch freie Software erreicht werden, wenn dadurch der Zugang zu Wissen, Kultur oder Kunst von allen sozialen Gruppen gewährleistet wird. Dies fördert die Chancengleichheit. Je mehr soziale Aufgaben bzw. Probleme sie erfüllt, desto nachhaltiger ist sie in diesem Bereich.
Clean Code
Clean Code erleichtert das Ändern, Lesen, Erweitern und Warten von Softwarecode. Ein weiteres Ergebnis ist eine stabilere und effizienter wartbare Software, die weniger investierte Entwicklungszeit bei Funktionserweiterungen und Fehlerbehebungen benötigt. Dies ist besonders deshalb relevant, da im Durchschnitt mindestens 80 Prozent der Entwicklungszeit auf Wartungen zurückzuführen sind. (Vgl. Robert C. Martin (2009): 16). Zudem unterstützt Clean Code die sichere und weniger fehleranfällige Entwicklung von Software, da die Entwicklung übersichtlicher, weniger komplex und weniger missverständlich wird (vgl. Uwe Post (2021): 14 f.). Es fördert die ökonomische Nachhaltigkeit durch Einsparung von Entwicklungszeit und Kosten und verhindert kostenintensive Katastrophen, die sonst die Folge sein können. Dabei muss beachtet werden, dass das Schreiben von sauberem Code ein Prozess ist. Je früher damit begonnen wird, desto weniger zeit- und kostenaufwändig werden Anpassungen im späteren Verlauf, auch wenn initial besonders bei komplexen Programmen der Zeitaufwand oft höher ist. (Vgl. Robert C. Martin (2009):110). Zusätzlich sorgt das Einsparen der Entwicklungszeit auch dafür, dass weniger Energie durch die Entwickler:innen selbst verbraucht wird, um das jeweilige Softwareprodukt fertigzustellen.
Effiziente Programmierung
Die Laufzeit eines Algorithmus hängt sowohl von den Eingabewerten und der jeweiligen Programmiersprache als auch von der Hardware ab, auf der er ausgeführt wird. Die Anzahl der Ausführungen sowie die Art und Weise der Implementierung von einem Algorithmus ist dementsprechend ebenso relevant. Deshalb müssen Messungen hierzu als Einzelfall-Untersuchungen betrachtet werden, die in Bezug auf einen konkreten Rechner bzw. der dementsprechenden Hardware sowie der jeweiligen Programmiersprache, Implementierung und Eingabewerte unterschiedliche Ergebnisse liefert. (Vgl. Wegener (2003): 20 f.). Die Formel für den Energieverbrauch ist Energy (J) = Power (W) x Time(s). Dies bedeutet, dass die Laufzeit den Energieverbrauch zwar beeinflusst, aber die dafür benötigte Leistung eines Computers nicht immer als Konstante betrachtet werden darf. Hierfür müssten weitere Untersuchungen erfolgen. (Vgl. Rui Alexandre Afonso Pereira et al. (2020) :11). Für die Effizienzbewertung von Algorithmen existieren auch von Implementierungs-, Hardware- und Eingabedaten unabhängige Kriterien (vgl. Wegener (2003): 21 f.). So kann neben dem Speicherplatzbedarf die benötigte Wachstumsgeschwindigkeit eines Algorithmus auch unabhängig von Zeiteinheiten mit der Anzahl durchgeführter Rechenschritte bzw. mit der Landau-Notation angegeben werden (vgl. Wegener (2003): 21, 295).
Im Folgenden werden einige praktische Beispiele für Code-Optimierungen und das Anwenden von Clean Code genannt. Diese werden durch die jeweiligen Messungen der Laufzeit auf die Auswirkungen ökologischer als auch ökonomischer Nachhaltigkeit untersucht. Hierbei muss beachtet werden, dass sich die Messungen auf ein konkretes Szenario mit einer individuellen Hardware und der Programmiersprache Java beziehen. Außerdem wird davon ausgegangen, dass die unabhängig von der Laufzeit verbrauchte Leistung für die unterschiedlichen implementierten Algorithmen konstant bleibt. Dies ist dadurch begründet, dass es sich um Algorithmen handelt, bei denen der Prozessor für die jeweilige Zeit der Ausführung vollständig ausgelastet werden kann und keine Netzwerkzugriffe stattfinden. Somit können alleine durch die Vergleiche der Laufzeitmessung Rückschlüsse auf den jeweiligen Energieverbrauch gezogen werden.
Decorator Design Pattern vs. Decorator Anti Design Pattern
Beispielhaft wurde ein Decorator Design Pattern im Sinne der Clean Code SOLID Prinzipien und dessen Anti Design Pattern implementiert. Dabei kann die Dekoration von konkreten Komponenten bei Anti Decorator Design Pattern mittels innerer Klassen oder als Unterklasse erfolgen.
Damit Laufzeitunterschiede deutlich zu erkennen sind wurde die Dekoration einer konkreten Komponente jeweils 10 Millionen-mal durch eine For-Schleife aufgerufen. Dies wurde 10 Mal hintereinander ausgeführt und die Laufzeit bei jedem Durchgang gemessen. Denn die Messergebnisse sind nicht gleichbleibend und hängen u.a. stark von anderen Aktivitäten ab, die derselbe Computer durchläuft. Die Ergebnisse in den dargestellten Grafiken zeigen, dass das Design Pattern bei jeder Ausführung deutlich mehr Laufzeit benötigt als die beiden Anti Design Pattern:

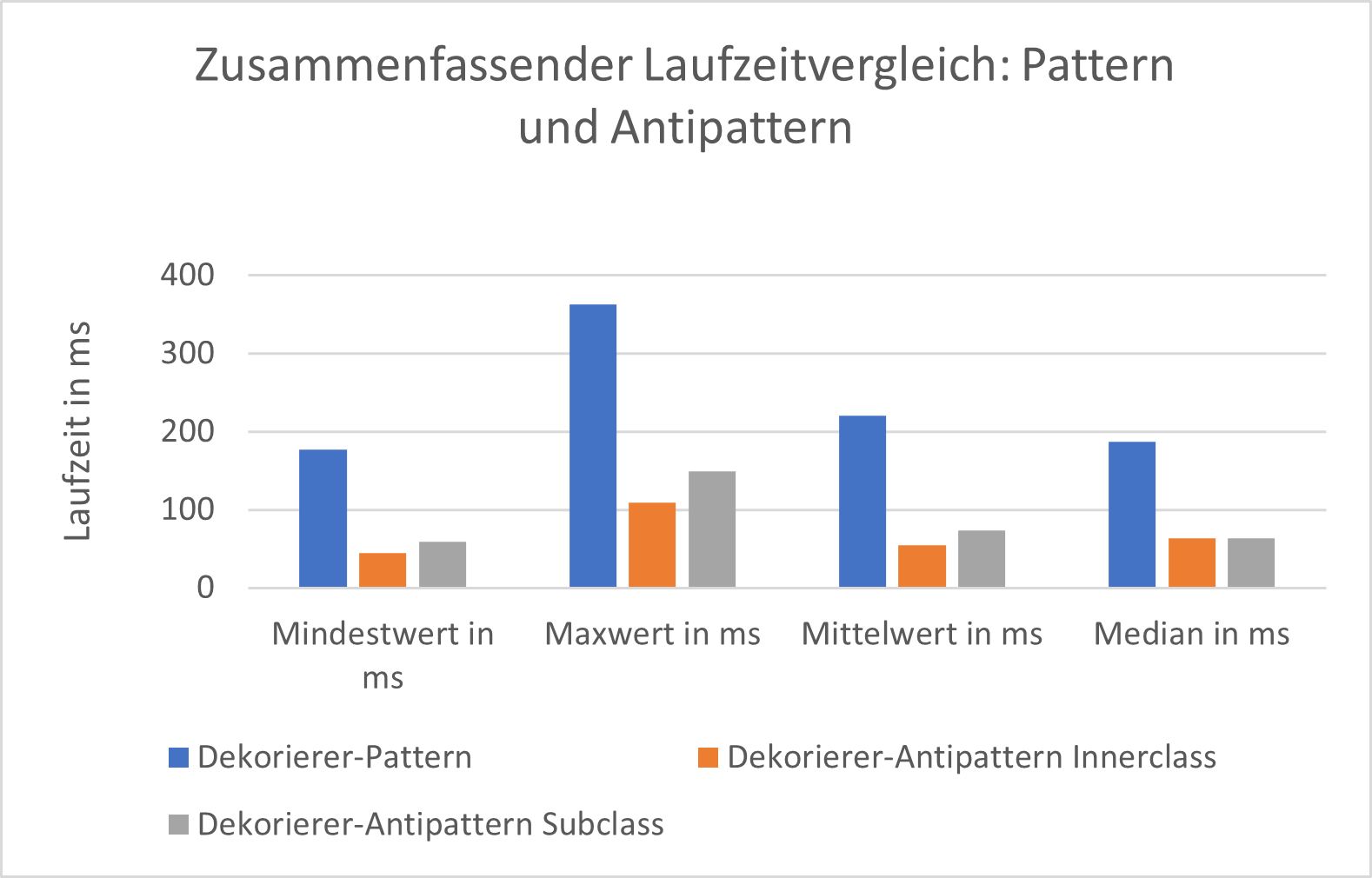
Zusätzlich wurden weitere Messungen mit konkreten Komponenten durchgeführt, die eine zusätzliche aufwändigere Berechnung haben. Diese führten die Fibonacci-Berechnung mit einem Eingabewert 10 aus:


Der relative Laufzeitunterschied vom Experiment (Dekorierer-Pattern) zum Gegenexperiment (Anti Pattern) ist geringer, wenn eine zusätzliche Berechnung im „inneren des Pattern“ durchgeführt wird. In absoluten Werten braucht das Dekorierer-Pattern jedoch trotzdem länger. Dieses sollte also dann vorgezogen werden, wenn viele dekorierte konkrete Komponenten mit komplexen Berechnungen erforderlich sind. Dadurch ist der Energieverbrauch nicht so viel höher, aber es bietet den Vorteil hinzukommende Entwicklungszeiten und Kosten zu vermeiden. Ein Anti Design Pattern ist dagegen dann vorzuziehen, wenn nur sehr wenige konkrete Komponenten dekoriert werden müssen. Dadurch kann im Verhältnis bei geringen hinzukommenden Entwicklungszeiten und Kosten sehr viel Energie eingespart werden.
Caching
Bei dem Einsatz von Caching handelt es sich um das Zwischenspeichern mit hohen Zugriffsgeschwindigkeiten (Vgl. Amazon Web Services (2022)). Dies kann mehr Speicherplatzbedarf erfordern, führt aber oft zu Energieeinsparungen bei CPU-Berechnungen oder Festplatten und Netzwerkaktivitäten. Hierzu wurde die Fibonacci-Funktion mit und ohne den Einsatz von Caching implementiert. Für den Eingabewert 47 der beiden Funktionen ergab sich folgender Laufzeitvergleich:

In diesem Fall ist Caching zu empfehlen, da dadurch das exponentielle Wachstumsverhalten in der Zeitkomplexität durch ein lineares ersetzt wird. Das sorgt sehr schnell für erhebliche Laufzeit bzw. Energieeinsparungen, während der dafür benötigte zusätzliche Implementierungsaufwand gering bleibt.
Iteration vs. Rekursion
Als weitere Optimierungsmethode wurde eine iterative mit einer rekursiven Fakultätsfunktion verglichen. Damit Laufzeitunterschiede deutlich zu erkennen sind, erfolgte der Funktionsaufruf mit dem Eingabewert 10 und wurde insgesamt 10 Millionen Mal aufgerufen. Anschließend kam es zu 10 hintereinander folgenden Durchführungen.
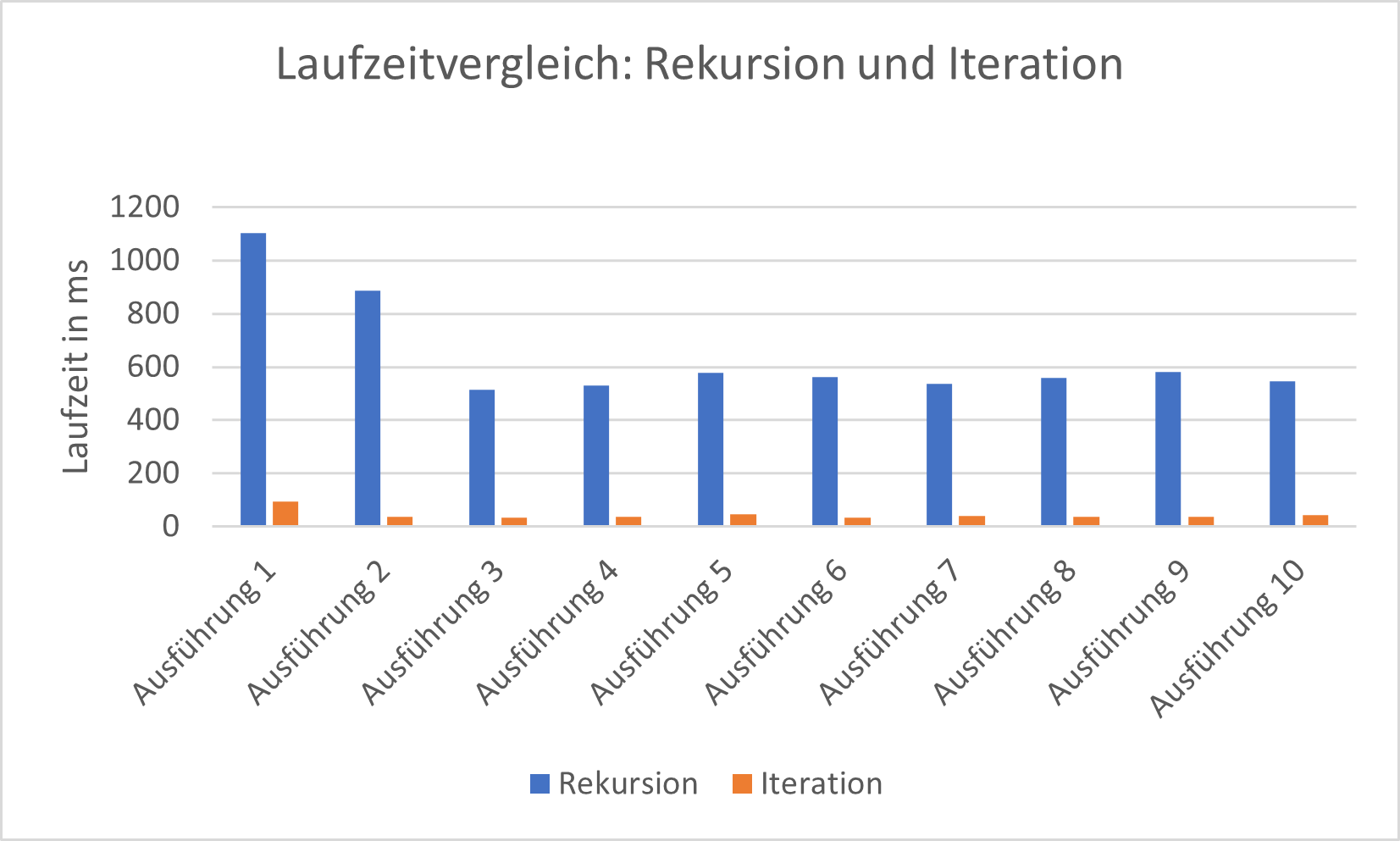

Die Ergebnisse zeigen, dass die Rekursion deutlich mehr Laufzeit benötigt, und weisen darauf hin, dass die Java Virtual Machine (JVM) zur Laufzeit automatisch Optimierungen vornimmt. Die für einen Menschen lesbarere und verständlichere Rekursion sollte der manuellen iterativen Variante dann vorgezogen werden, wenn automatische Compiler- oder Laufzeitoptimierungen den Unterschied des Energieverbrauchs dieser beiden Varianten ausgleichen. Die manuelle Iteration ist dagegen dann empfehlen, wenn keine oder kaum Compiler- oder Laufzeitoptimierungen stattfinden und es sich um Hotspots handelt –also dort, wo viel Energie verschwendet wird, die Zeitkomplexität sehr hoch ist und diese Algorithmen sehr oft ausgeführt werden.
Inlining vs. Anti-Inlining
Bei Inlining-Optimierungen wird der Code-Inhalt einer Funktion an Stelle der Aufrufe dieser Funktion ersetzt. Dies wurde durch eine einfache Funktion umgesetzt, die zwei verschiedene Zahlen zum Quadrat berechnet und diese dann addiert. Die dazugehörige Anti-Inline-Methode ruft dabei jeweils eine Quadrat-Funktion auf, die diesen Teil der Berechnung übernimmt. Die Messungen fanden nach demselben Verfahren wie bei Rekursion vs. Iteration statt. Hierbei ist kein eindeutiger Laufzeitunterschied zwischen dem Aufruf der Inline- mit der Anti-Inline-Funktion zu erkennen:


Zusätzlich wurde der Bytecode der Anti-Inlining-Methode untersucht, da Inline-Ersetzungen durch moderne Compiler auch automatisch stattfinden können. Im Bytecode ist für die Anti-Inline-Methode keine automatische Inline-Ersetzung zu sehen, da die Quadrat-Funktion aufgerufen wird. Deshalb handelt es sich dabei wahrscheinlich um eine Optimierung durch die JVM.
In diesem Fall oder bei automatischen Compiler-Optimierungen sollte auf manuelles Inlining verzichtet werden. Dadurch kann die eigentliche Funktionalität von dem jeweiligen Code bei gleichbleibendem Energieverbrauch manuell und lesbarer bzw. verständlicher zusammengefasst werden. Für die Bedingung, dass sicher keine automatischen Laufzeit- oder Compiler-Optimierungen stattfinden, müssten weitere Messungen durchgeführt werden, um die Laufzeit vergleichen zu können.
Loop vs. Loop Unrolling
Bei der Loop-Unrolling-Optimierung wird der Aufruf einer Schleife durch mehrere Kopien von dessen Inhalt ersetzt. Die Schleifenbedingung muss somit nicht wiederholt geprüft werden. Auch dies kann durch einige moderne Compiler automatisch angewandt werden.
Die Laufzeitmessungen fanden nach demselben Verfahren wie bei den Untersuchungen von Rekursion, Iteration sowie Inlining und Anti-Inlining statt. Die Ergebnisse zeigen, dass Loop Unrolling wesentlich schneller ist:
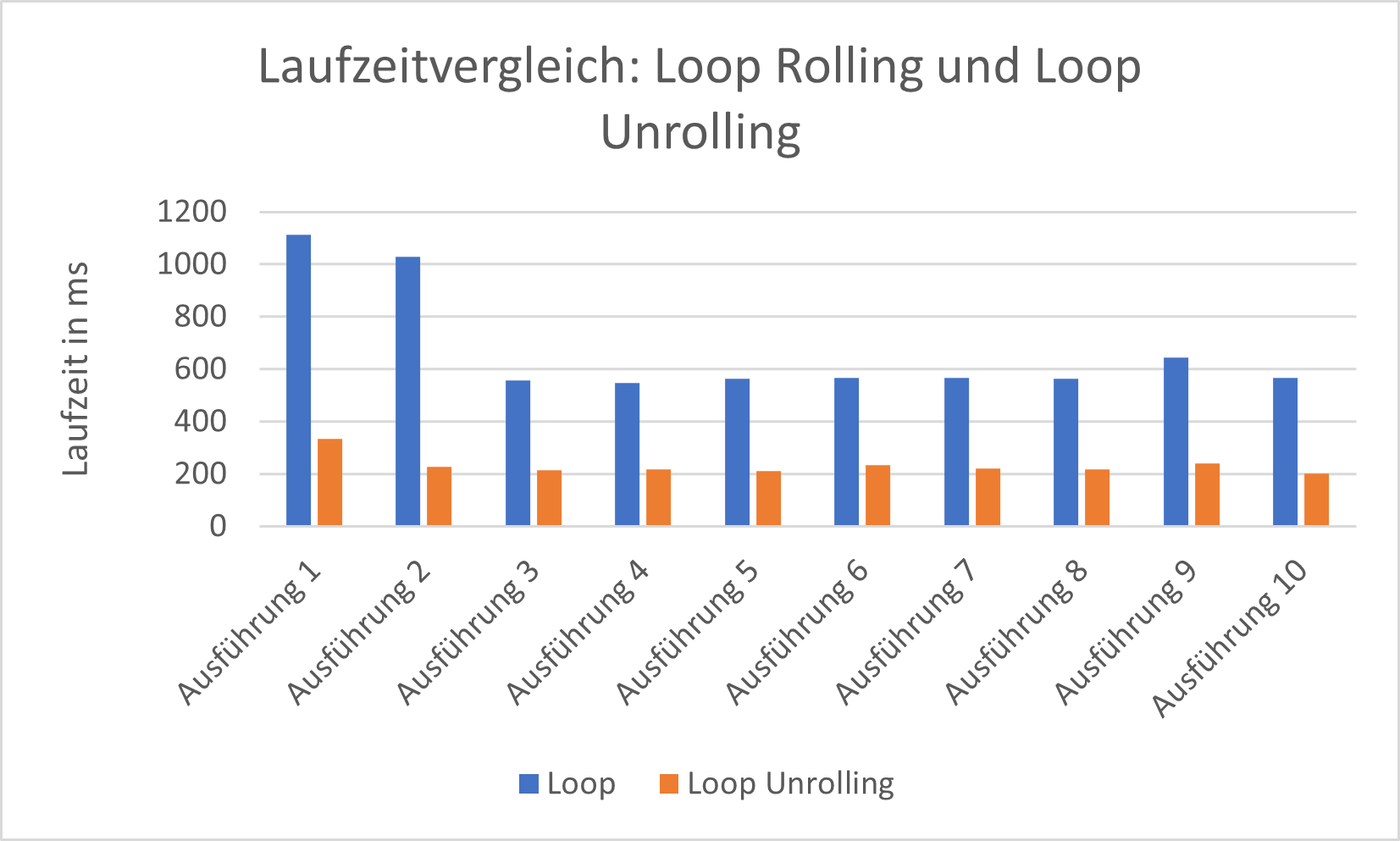
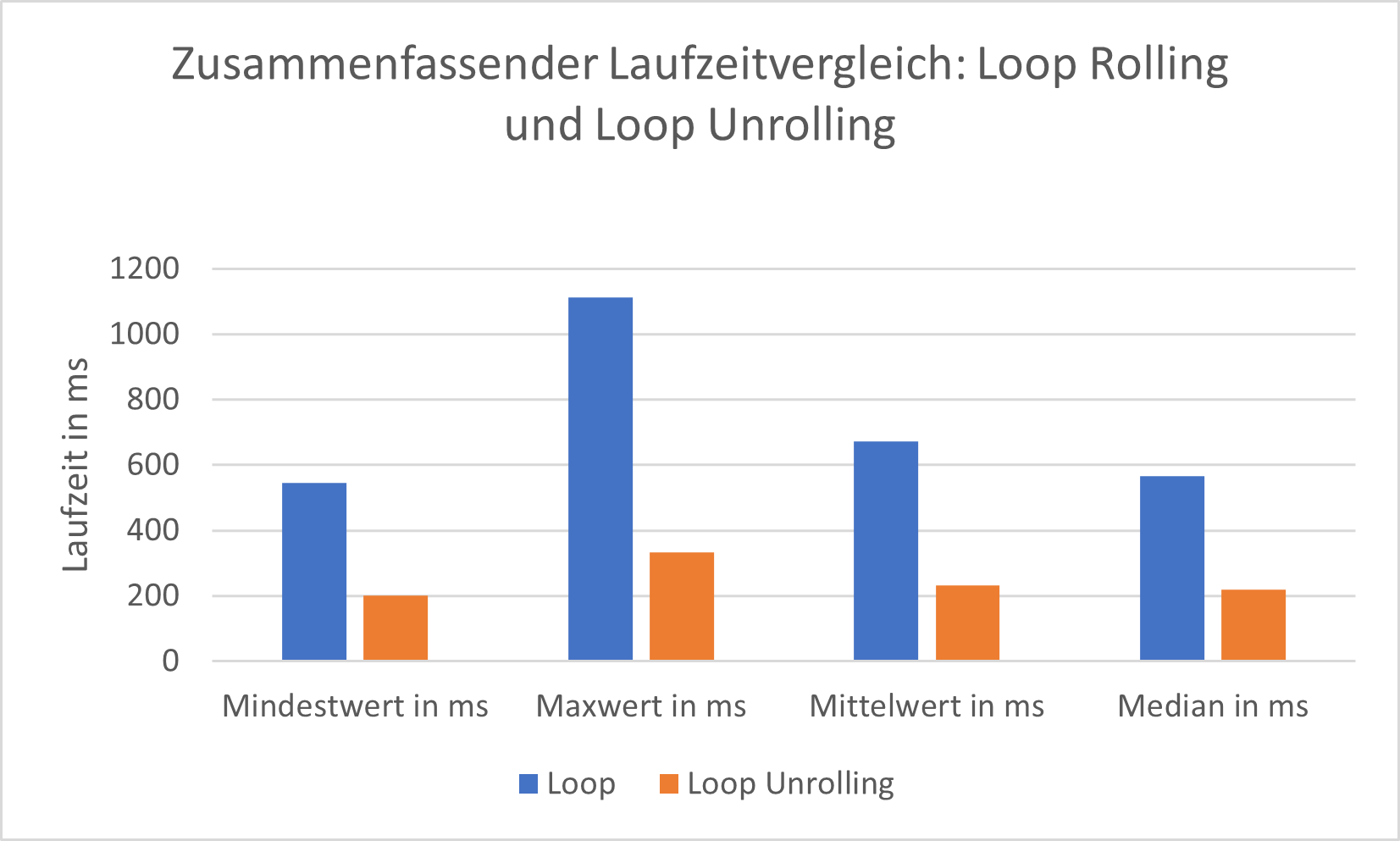
Auch hier deuten sich Laufzeitoptimierungen der JVM an. In diesem Fall sind die Ergebnisse des Loop Unrolling ökologisch effizienter. Ein manuelles Loop Unrolling bedeutet allerdings jede einzelne Zeile Code manuell schreiben und ggf. später refaktorieren zu müssen. Dabei kann eine hohe Anzahl an Schleifendurchläufe erhebliche Auswirkungen auf die langfristigen Entwicklungs- und Wartungszeiten haben. In der gezeigten konkreten Implementierung handelt es sich jedoch um wenige Schleifendurchläufe. Außerdem kam kein automatisches Loop Unrolling durch den Compiler zustande. Laufzeitoptimierungen wurden sowohl für die Loop- als auch die Loop-Unrolling-Funktion vorgenommen. Unter diesen Umständen ist ein manuelles Loop Unrolling zu empfehlen.
Fazit
Clean Code wirkt sich vor allem bei komplexen Softwareprojekten positiv auf die ökonomische Nachhaltigkeit aus. Ob es sich dabei auch um ökologische Nachhaltigkeit handelt, muss für jeden individuellen Fall und in dem jeweiligen Kontext einzeln betrachtet werden. Wenn unterschiedliche Algorithmen auf ihre ökologische Nachhaltigkeit hin untersucht werden und dementsprechende Messungen ausgeführt werden sollen, empfiehlt es sich, dessen reale Komplexität z. B. mit dem Einsatz von Schleifen zu simulieren, falls der Anwendungsfall dies erlaubt. Dadurch kann die für die Messung benötigte Entwicklungszeit eingespart werden. Gleichzeitig können Rückschlüsse gezogen werden, ob das Anwenden von Clean Code oder ökologisch effizienteren Code zu einer insgesamt höheren Nachhaltigkeit führt. Dabei sollte man auch überprüfen, ob automatische Optimierungen vorgenommen werden, um eine sinnvolle Entscheidung zu treffen – besonders bei Hotspots sollte optimiert werden. Diese sind z. B. identifizierbar mit Profiler Tools.
Repository zum Projekt
Für die beispielhaften Implementierungen zu den Methoden der effizienten Programmierung wurde ein Repository bereitgestellt: https://github.com/Marjuw/Methods-of-efficient-programming.
Literaturverzeichnis
[Amazon Web Services 2022] Amazon Web Services: Caching – Übersicht. https: //aws.amazon.com/de/caching/ Version: 2022. – Last accessed 24 February 2022
[Holzbaur 2020] Holzbaur, Ulrich: Nachhaltige Entwicklung-Der Weg in eine lebenswerte Zukunft. Springer, 2020 https://link.springer.com/book/10.1007/978-3-658-29991-0. – Last accessed 06 January 2022
[Blauer Engel 2020] Blauer Engel: Ressourcen- und energieeffiziente Softwareprodukte (DE-UZ 215). https://www.blauer-engel.de/de/produktwelt/ressourcen-undenergieeffiziente-softwareprodukte. Version: January 2020. – Last accessed 13 January 2022
[Robert C. Martin 2009] Robert C. Martin: Clean Code – Refactoring, Patterns, Testen und Techniken für sauberen Code. 1. Edition. mitp, 2009. – ISBN 978-3-8266-5548-7
[Rui Alexandre Afonso Pereira et al. 2020] Rui Alexandre Afonso Pereira and Marco Couto and Francisco José Torres Ribeiro and Rui António Ramada Rua and Jácome Cunha and João Paulo Sousa Ferreira Fernandes and João Saraiva: Ranking Programming Languages by Energy Efficiency. http://repositorium.sdum.uminho.pt/handle/1822/69044. Version: Dezember 2020. – Last accessed 28 February 2022
[Umweltbundesamt 2015] Umweltbundesamt: Nachhaltige Software-Dokumentation des Fachgesprächs „Nachhaltige Software“ am 28.11.2014. https://www.umweltbundesamt.de/themen/wie-software-gruener-werden-kann-ergebnisse-eines. Version: July 2015. – Last accessed 06 January 2022
[Uwe Post 2021] Uwe Post: Besser Coden – Best Practices für Clean Code. 2. Edition. Reihnwerk Computing, 2021. – ISBN 978-3-8362-8492-9
[Wegener 2003] Wegener, Prof. Dr. I.: Komplexitätstheorie: Grenzen der Effizienz von Algorithmen. 1. Edition. Springer-Verlag Berlin Heidelberg, 2003. – ISBN 9783642555480



Sehr interessante Ergebnisse! Meiner Meinung sind zwar die Effekte von Verbesserungen auf „low-level“ Code Ebene im Hinblick auf nachhaltige, energieeffiziente Software eher marginal – verglichen mit dem Entwicklungsprozess an sich oder aber dem Betrieb der Software (Stichwort „auto-scaling“, etc.) – aber dennoch nicht zu vernachlässigen. Einige der erwähnten Aspekte finden sich auch im openHPI MOOC über „Sustainable Software Engineering“ wieder – sehr empfehlenswert 😉 //Link von Redaktion entfernt
Danke dir! Wir freuen uns, dass dir der Artikel gefällt! 🙂
Ziemlich substanzloser Artikel, der realitätsfremde Beispiele verwendet und eher wie CEO-Optimierung für das Trendwort „Nachhaltigkeit“ aussieht – ein Wort das hier überhaupt nicht passt. Nachhaltig ist eine Ressource oder ein Prozess, der nicht auf endlichen Ressourcen basiert oder diese durch Recycling immer wieder verwendet. Was hier eher untersucht wird ist „Energieverbrauch“. Und dass rekursive Fibonacci-Berechnung ohne Caching sehr ineffizient ist, lernt man in der zweiten Woche des Informatikstudiums. Mit Clean-Code hat das ganze auch fast nichts zu tun.
Interessanter wäre eine Untersuchung von CPU-Architekturen und Transistordichte, die sich direkt in Energieverbrauch niederschlägt, nativ kompilierten und interpretierten Programmiersprachen, etc.
// Dieser Kommentar enthielt Inhalte, die nicht unseren Diskussionsstandards entsprechen, und wurde angepasst.
Hallo Peter,
um etwas Kontext zu geben – bei diesem Artikel von Marvin Juwig handelt es sich um die Zusammenfassung seiner Bachelor Thesis, die ich auf Seiten inovex in Kooperation mit der TH Köln betreut hatte.
Dementsprechend wurde hier etwas gekürzt auf Bloglänge. Wenn du Interesse an der vollständigen Thesis hast, kann ich dir die gerne zukommen lassen.
Deine Kritik ist durchaus berechtigt und ich würde gerne mit dir weiter über das Thema diskutieren 🙂 :
„Nachhaltig ist eine Ressource oder ein Prozess, der nicht auf endlichen Ressourcen basiert oder diese durch Recycling immer wieder verwendet.“
Das stimmt, aber ist meiner Ansicht nach etwas vereinfacht im Kontext der Informatik.
Software selber mag als kreatives Erzeugnis nicht endlich sein, aber die Plattformen auf denen sie läuft – also die konkrete Hardware + die verbrauchte Energie von ihnen – ist es durchaus nicht.
In der Thesis ging es darum einen ersten Einblick darin zu bekommen wie man „nachhaltiger“ Software entwickeln kann. Dazu gehört auf jeden Fall dazu die bestehenden Mittel die einem zur Verfügung stehen besser zu nutzen.
Mich würde aber sehr interessieren ob du zu dem Thema noch andere Definitionen kennst? Idealerweise bereits etablierter durch Standardisierungen oder Zertifizierungen. In unserer Recherche hat sich das Thema Nachhaltigkeit + Software noch sehr als Nischenthema herauskristallisiert, mit nur wenigen Institutionen die versuchen Nachhaltigkeit zu quantifizieren.
„Was hier eher untersucht wird ist „Energieverbrauch“. Und dass rekursive Fibonacci-Berechnung ohne Caching sehr ineffizient ist, lernt man in der zweiten Woche des Informatikstudiums.“
Da hast du natürlich Recht 😉 Im Benchmarking ging es eher darum die Grundprinzipien darzustellen, deswegen ist das Beispiel auch für den Kontext der Bachelor Thesis stark vereinfacht.
„Mit Clean-Code hat das ganze auch fast nichts zu tun.“
Hier stimme ich dir nicht zu. Vermutlich ist es im Kontext der gesamten Thesis ersichtlicher, aber es gibt durchaus einen Zusammenhang zwischen Clean Code practices und den verschiedenen Dimensionen der Nachhaltigkeit, insbesondere ökologische und ökonomische Nachhaltigkeit. Insbesondere haben wir versucht den negativen Effekt auf die ökologische Nachhaltigkeit zu beleuchten! Komplexer Code mit vielen Klasse und Abstraktionsebenen sorgt für mehr „Arbeit“ des Prozessors – aber ist natürlich einfacher zu warten. Ich finde das ist ein sehr interessanter tradeoff und durchaus eine Diskussion Wert. Clean Code Prinzipien durch Götterklassen zu ersetzen ohne jegliche Abstraktionen ist natürlich kein guter Ansatz, aber vielleicht ist auch krampfhaftes Refactoring nicht immer die richtige Lösung?
„Interessanter wäre eine Untersuchung von CPU-Architekturen und Transistordichte, die sich direkt in Energieverbrauch niederschlägt, nativ kompilierten und interpretierten Programmiersprachen, etc.“
Das sind super Vorschläge! Bei CPU-Themen bin ich leider kein Experte, aber die Idee mit dem Vergleich verschiedenen Programmiersprachen finde ich klasse. Hast du konkrete Vorschläge oder Ideen was dich da interessieren würde?