Notice:
This post is older than 5 years – the content might be outdated.
Neural networks are the basis of some pretty impressive recent advances in machine learning. From greatly improved translation to automatic transfer of painting styles and from expert-level Go to Super Smash Bros, neural networks seem to to conquer various fields previously dominated by human performance. The on-going progress in different algorithms and techniques allows the application of neural networks in more and more use cases. Combined with the continuous maturing of the web as an application platform (see progressive web apps) this begs the question whether neural network applications can be deployed as web apps with all the advantages that come along with them.
While various applications use neural networks in the data center and send the result of their calculations to the client, the execution on the client itself without direct internet access is less researched. The biggest problem with this approach is the limited access to hardware capabilities through the available browser APIs and a generally low execution efficiency due to secure sandboxing and compatibility with a wide variety of operating systems and CPU architectures.
In my master’s thesis I explore the different ways to execute neural networks in a browser environment while applying various types of optimization to achieve the best possible result. This includes fast execution as well as a small file size to minimize data usage and transmission times.
To create a JavaScript module which executes a neural network directly in the browser, it is important to understand what exactly has to be done to make it happen. From the perspective of an integration engineer, a neural network is a graph of operations passing around n-dimensional arrays of real numbers (so called tensors), altering them along the way. Such an operation could be a matrix multiplication which needs two two-dimensional tensors as input and emits a third two-dimensional tensor. There are static tensors (the so called parameters or weights of the network), which are learned by backpropagation using training data prior to deployment in the browser, and dynamic tensors which depend on the current input data.
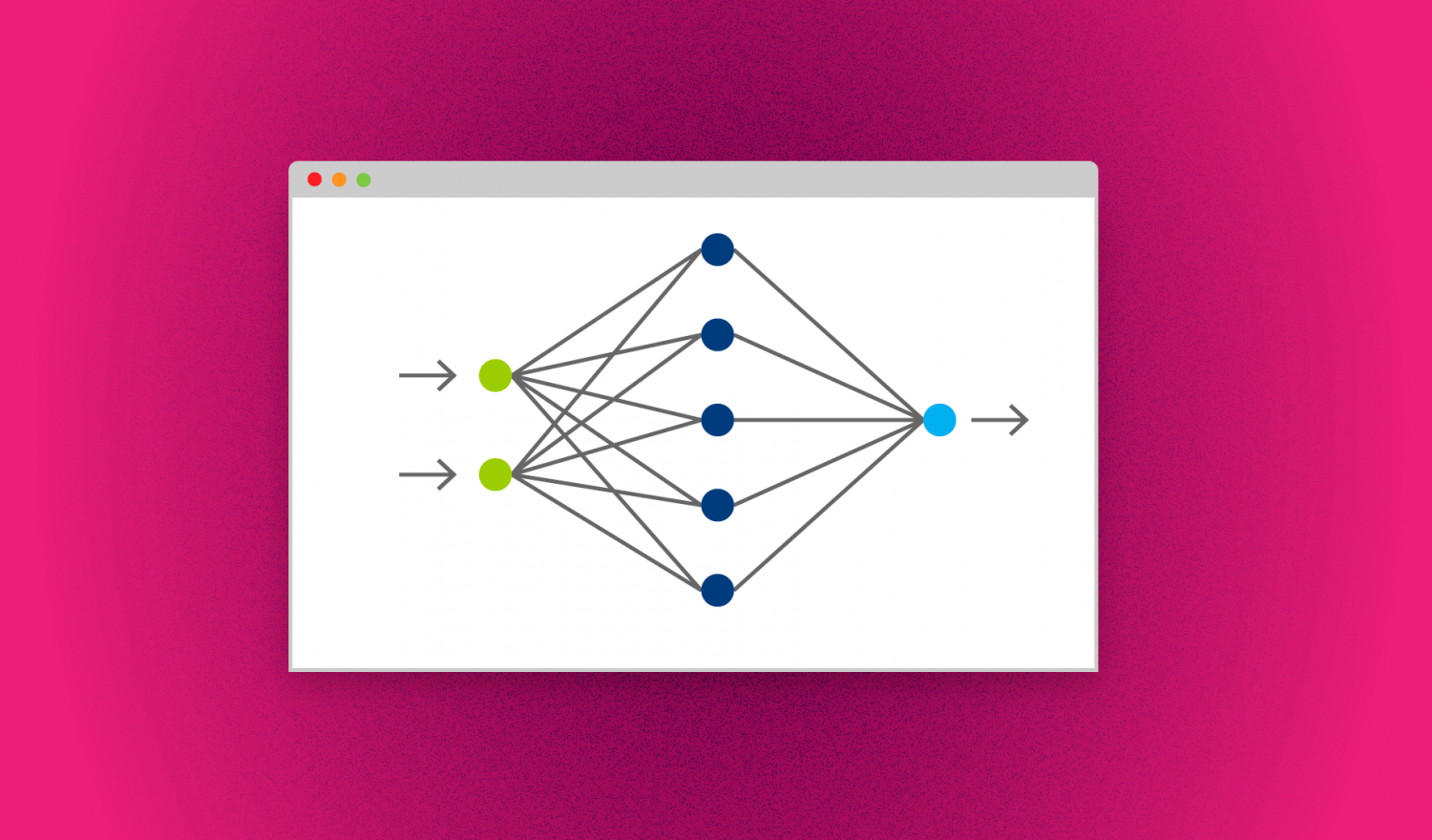
The following figure shows a fairly simple example of this model. Here the network can be used to classify handwritten digits in a small grayscale-image. In this case the input-tensor is a two-dimensional 30×30 tensor, the individual values represent the brightness value of the corresponding pixel in the image. This tensor is passed through multiple operations which sometimes need some additional static tensors to produce a one-dimensional output-tensor with 10 entries, each value representing the recognition confidence for the respective digit.
In practice the computational graph can be much bigger, requiring large numbers of static tensors and a lot of computational power to pass one input-tensor through the network.

Implementation
To generate the JavaScript module, the individual operations of the graph are concatenated in the correct order into a single function which accepts the input-tensor as a parameter and returns the output-tensor. Static parameter tensors are stored in a global variable. The function representing the neural network together with the global variable and some auxiliary functions are wrapped in a module definition to make the integration into other web apps possible.
In order to fully utilise the performance offered by modern JavaScript engines and thus minimizing the execution time, the generated JavaScript code should be as efficient as possible. The asm.js subset uses only a small portion of available language features but in many cases greatly improved runtime performance. The Emscripten compiler is able to compile C or C++ code directly into efficient asm.js code executable in the browser. In terms of the code generator implemented in this thesis this means C code is generated from the computational graph of the neural network which is compiled to asm.js and wrapped into an UMD module definition afterwards. An additional interface listening for the ‘message’ event allows moving the execution into a Webworker. This prevents long lasting calculations on the main thread and therefore a frozen UI.

The static tensors of the network are saved in a binary file which is downloaded and converted into a continuous array of floating-point numbers. The generated code references the required tensor for the individual operation by an offset. Code example 1 shows the generated code for a matrix multiply operation, analogous code snippets exist for other operations like convolutions or pooling. The static tensor of this layer starts at offset 14419755 of the complete parameter array. Interim-tensors produced by the operation are also saved in a single large array with individual tensors referenced by offset.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
for(int i = 0; i < 1008; i++) { float r = 0.0; for(int j = 0; j < 2048; j++) { int k = 21820000 + i * 2048 + j; int inputCoord = 14419755 + j; r = r + interimVar[inputCoord] * paramVar[k]; } int outputCoord = 14421803 + i; interimVar[outputCoord] = r; } |
The code generated by this method is very static (number of loop passes known beforehand, no dynamic memory allocation, …) and thus can be optimized automatically by the Emscripten compiler and the executing JavaScript engine.
There are various methods to further speed up the execution performed by the created module, for example fixed point arithmetic. The basic idea is to avoid potentially costly floating point operations and replace them by simpler integer operations which can be executed by the CPU in fewer instruction cycles, sacrificing precision of the calculation in favour of performance. Using these the code looks like this:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 |
for(int i = 0; i < 1008; i++) { int r = 0; for(int j = 0; j < 2048; j++) { int k = 21820000 + i * 2048 + j; int inputCoord = 14419755 + j; r = r + interimVar[inputCoord] * paramVar[k]; } r = (r >> 6); int outputCoord = 14421803 + i; interimVar[outputCoord] = r; } |
The only obvious difference is the bit-shift of the result variable after the mutliplications in the inner for-loop, but the arrays interimVar and paramVar holding the tensors are of type int instead of float.
Other methods like the usage of SIMD (Single Instruction, Multiple Data) can be applied in a similar manner. Using these it is possible to execute the same low-level operation (addition, multiplication) multiple times in parallel with different parameters. This is possible because most CPUs feature multiple parallel processing units. The SIMD.js API currently only available in the Nightly build of Firefox offers access to SIMD instructions which can perform four floating-point operations at once. If Emscripten is used, so called SSE instructions in the C code are replaced by the corresponding SIMD.js counterparts in the resulting asm.js code. The matrix-multiply example from above with SSE instructions looks like this:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 |
for(int i = 0; i < 1008; i++) { float r = 0.0; int baseParamOffset = 21820000 + i * 2048; __m128 tmpVec = _mm_setzero_ps(); for(int unrollCtr = 0; unrollCtr < 2048; unrollCtr = unrollCtr + 4) { __m128 interimVec = _mm_load_ps(interimVar + 14419755 + unrollCtr); __m128 paramVec = _mm_load_ps(paramVar + baseParamOffset + unrollCtr); tmpVec = _mm_add_ps(tmpVec, _mm_mul_ps(interimVec, paramVec)); } float tmpArray[4]; _mm_store_ps(tmpArray, tmpVec); for(int i = 0; i < 4; i++) { r = r + tmpArray[i]; } int outputCoord = 14421803 + i; interimVar[outputCoord] = r; } |
Unfortunately I couldn’t get a combination of SIMD and fixed point arithmetic to work—it seemed like the necessary instructions generated by the Emscripten build were not supported by the Firefox Nightly at the time of writing, which can quickly change due to the rapid development of Emscripten and Firefox.
A fundamentally different method of executing the calculations of a run of the neural network in a browser is leveraging of the GPU as a general purpose execution engine (known as GPGPU, General Purpose Computing on GPUs). The only widely available API for accessing the GPU is WebGL, a binding to OpenGL ES 2.0, which is optimized for 3D graphics. To make arbitrary calculations, some hacks are necessary. To transfer 32 bit floating-point numbers to the GPU memory, they have to be transformed into a bitmap texture. Unfortunately the support for color-depths larger than 8 bit is rather limited, especially on mobile devices. A possible solution to this is to split the 32 bit of the floating-point number into 8 bit pieces which fit into the four color channels (red, green, blue and alpha) of a single pixel. A tensor therefore becomes a two dimensional WebGL texture, each pixel representing a single floating-point value of the tensor. If the tensor has more than two dimensions, it has to be unrolled accordingly. Because of the limited maximum size of WebGL textures, it can be necessary to split large tensors into several textures. To perform actual calculations on the tensors, the original floating-point value has to be restored from the color channel of the pixel. To save the result of the calculation in a new tensor, the floating-point result has to be split into 8 bit pieces again. In the paradigm of WebGL, shaders (representing single operations like a matrix multiply) are executed to access textures (parameter-tensors and input-tensors) to render to another texture (an intermediary tensor). In the end, the last intermediary texture is transferred from GPU memory into main memory where the result of the run can be accessed by ordinary JavaScript methods. This progress is far from optimal but at least the GPU can be accessed in this way.
There exist several libraries which encapsulate this process. In my thesis I chose the pure JavaScript WebMonkeys library because it is easy to use and a good fit for a proof of concept application. For a real, productive environment it may make sense to develop your own library which is specifically tailored to neural networks to overcome some avoidable inefficiencies of WebMonkeys. The already familiar matrix multiply example looks like this in WebMonkeys:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
monkeys.work(1008, ` float r = 0.0; for(int j = 0; j < 2048; j++) { int k = 6083328 + 2048 + j; int inputCoord = 14419755 + 2048 + j; r = r + interimVar0(inputCoord) * paramVar1(k); } int outputCoord = 14421803 + i; interimVar0(outputCoord) := r; `); |
The outer loop is moved to the parameter of the work method of WebMonkeys—this is the number of result values which are computed in parallel on the multiple computing units of the GPU. The second parameter is a string containing the code of the operation which is compiled into a shader program executable over WebGL. The used language here is an extended form of GLSL, a language resembling C, the only method to program a GPU through WebGL.
The following code snippet transfers the result of the calculation back into the main memory:
|
1 2 3 4 5 6 7 8 9 10 11 |
monkeys.set('outputVar', 1008); monkeys.work(1008, ` int inputCoord = 14421803 + i; outputVar(i) := interimVar0(inputCoord); `); var result = monkeys.get('outputVar'); |
This is only done with the last result of the computational graph of the neural network because the data transfer between GPU and main memory is comparatively slow.
Integration
To embed the generated JavaScript respectively asm.js code into a bigger application, it is wrapped into an UMD module definition. This is a combination of AMD and CommonJS module specifications which makes it possible to import the file in other JavaScript modules. Additionally it defines the publicly available API of the generated code, in this case a method to set the parameters of the network and a method to execute a given input tensor:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 |
(function (root, factory) { if (typeof define === ’function’ && define.amd) { // AMD define([], factory); } else if (typeof exports === ’object’) { // Node, CommonJS-like module.exports = factory(); } else { // Browser globals (root is window) root.feon = factory(); } }(this, function () { // module code, generated from network definition // API return { setParameters: function(dataArray) { /*...*/ }, forward: function(inputTensor) { /*...*/ } }; })); |
In a JavaScript app which aims to use the functionality of the network, the integration could look like this:
|
1 2 3 4 5 6 7 |
import runtime from ’./runtime.js’; // .... runtime.setParameters(params); var result = runtime.forward(cameraData); |
By using a module-bundler like webpack the sources of the app can be bundled together with the generated neural network runtime into a single file which is distributed and included in a webpage as a regular single page application. The parameters are saved in a separate binary file which can be downloaded via AJAX and passed to the runtime module via the setParameters API.
Performance
The following chart shows the execution time achieved with the aforementioned methods for SqueezeNet, a comparatively small neural network trained to recognize one of 1000 different classes given a single small image (277×277 pixels) as input. The laptop is a MacBook Pro with a 2.6 Ghz i5 CPU and an on-chip Intel Iris GPU. The desktop computer has a 3.3 Ghz i5 CPU and a Nvidia Geforce GTX 660 GPU.

While techniques like fixed point arithmetic and SIMD calculations improve the execution speed, the advantage of powerful hardware is clearly shown by the results of the dedicated desktop graphics card. This isn’t very surprising though, given the theoretical 1,900 GFLOPS of the Nvidia Geforce compared to the 16 GFLOPS of the laptop i5 CPU. However, the more important question here is the efficiency of the runtime since the hardware of the used device isn’t controllable at all in the web. To do so, a neural network was executed using the implemented runtime as well as the CPU and GPU version of the popular Tensorflow library by Google. The following chart shows this comparison. All runs were performed on the desktop computer because Tensorflow can only be used with certain Nvidia GPUs. In this case, the larger Inception-v3 network was used, which lends itself more to parallelization than SqueezeNet.

The results show there is a large discrepancy between native and web-bound execution methods, even when using experimental features like SIMD instructions. The performance gap for GPU bound execution (in this case WebGL in comparison to CUDA) is even bigger than for CPU based methods. The differences can be explained by the access to more and more efficient APIs (e.g. access to multiple CPU cores through threading and shared memory and the highly optimized CUDA API especially for GPGPU) and the unoptimized implementation of the individual tensor operations over the course this work. Nevertheless it can be stated that execution performance is substantially worse than native implementations. However, new developments strive to close the gap between native and web performance, e.g. Long SIMD extensions and shared memory for WebAssembly and new GPU APIs for the browser (like WebGPU and WebGL2 Compute Shaders) so the situation is likely to improve in the future.
Parameter Compression
The second important metric to consider when executing neural networks in the web is the amount of data which needs to get transferred to the client device before the actual execution can take place. This includes the the code of the runtime itself and the static tensors (or parameters) of the network. The size of the code itself includes only the operations necessary for the network at hand leaving little opportunity to reduce it. Compressed with the gzip algorithm which is the established standard for static resources in the web, even the runtime for complex networks like Inception-v3 only takes up 30KB which is negligible in comparison to the network parameters. Even the small and optimized SqueezeNet network has approx. 1.2 million individual parameters. If each value is saved as a 32 bit floating point number which is the established standard in deep learning, this amounts to 4.8MB which can be a lot when transferred over a mobile connection. The bigger Inception-v3 network takes up approximately 90MB of disk space.
The naive approach of simply compressing the parameter file with a widely available lossless algorithm like gzip only saves approx. 7% of disk space. The “deep compression“ method by Song Han et. al promises much better results by using lossy compression schemes which are optimized for neural network parameters. The two most important steps are the pruning of unimportant parameters and the reduction of precision (the number of digits after the decimal point). Because the value of the parameters changes slightly by doing so, a trade-off between the size of the parameter file and the quality of the results of the network after compression has to be balanced. This “sweet spot“ of small parameter file size and high-quality results depends highly on the use case at hand and the targeted audience. The following figure shows the trade-off between recognition accuracy of the correct class in an image and the size of the parameter file for the SqueezeNet network.

The far right data point represents the uncompressed network. It can be seen that the file size can be reduced significantly (to less than 1MB) without sacrificing much of the accuracy and thus the quality of the results of the network. Because of this property much bigger networks become viable in terms of data transmission times.
Demo
As a working demo I took the style transfer network of the Google Magenta project (2), which is a convolutional neural network implemented in TensorFlow and generated the corresponding JavaScript runtime. This module was used in a single page application based on Inferno (a slim alternative to React) and Redux (a library for state management in applications) to create a web app which repaints your image in the style of famous paintings directly in the browser. Because the computational cost is pretty high and increases quadratic with the size of the image, the image is downscaled to a fixed size prior to the execution of the network. It can still take quite some time to style an image on low-end devices so please be patient. If available the SIMD extension of JavaScript is used (only available in Firefox Nightly at the moment). The output-tensor of the network is transformed into a canvas and displayed respectively downloaded to the computer of the user as an ordinary image file.
Each style that can be applied to the image is a separate parameter file which has to be downloaded separately. The computational graph is the same in all cases which means only one runtime module has to be used.
The network at hand has 1.6M parameters which can be compressed to appr. 1.6MB file size without sacrificing any visual quality of the end result.

Similar Approaches
There are multiple other projects using WebAssembly and WebGL for executing trained neural networks in the browser, for example the libraries TensorFire by MIT and WebDNN by the university of Tokyo. Google has just recently released deeplearn.js, an open source library to make WebGL-accelerated machine learning accessible for a broader audience. This shows the general interest in the web as a delivery platform for neural network models, although no real applications using these libraries exist yet.
Summary
As shown in experiment it is possible to execute neural networks trained with conventional libraries like Tensorflow directly in the browser. The feasibility of the approach depends on computation and storage requirements of the used network where the constraints of the web platform definitely limit possible use cases. However, since neural network algorithms and the web as application platform are still maturing, it is likely that the situation will improve in the near future. To unlock more potential of optimization it is important to consider choices early in the design process of the network to create neural networks as small and fast as possible.


