
Notice:
This post is older than 5 years – the content might be outdated.
Neuroevolution describes the evolution of Artificial Neural Networks for problems in the domain of supervised or reinforcement learning. This article is the result of evaluating Neuroevolution during my Master’s Thesis. The thesis was created in cooperation with inovex and Uppsala University. In the following, we will look at the history of Neuroevolution and present state-of-the-art work that was performed by Google, Uber and other companies.
Introduction
Throughout history, humans continuously researched the underlying concepts of nature and utilised them as a source for innovation. As a result, products were invented in a variety of domains such as air planes or even flippers. Natural computing describes the transfer of concepts from nature to computers. Machine Learning or Evolutionary Computation have their roots in the field of natural computing. We can utilise these concepts to perform simulations or solve (really difficult) problems. But in the end, not only humans can improve by observing the nature. We also have the ability to return the favour and use the information that we retrieved to support nature and our environment.
Evolutionary Computation
Evolutionary Computation (EC) according to Fogel et al. (1997) describes the concept of borrowing and transferring ideas from evolution which can be found in nature to computers. As mentioned before, this allows us to understand and simulate underlying processes of how evolution is performed in nature. Furthermore, these techniques allow us to solve tasks by finding (near-)optimal solutions. We will look into how the latter is done. As it represents a form of stochastic optimisation, randomisation is involved to find a (near-)optimal solution. However, this also means that it is non-deterministic. Exhaustive testing is a must to allow a robust evaluation of results.
The question is now: How do we transfer evolution to computers? To perform the evolution, EC borrows the following components from nature:
- Population: A population represents a set of individuals.
- Individual: Each individual represents a candidate solution. A candidate solution is a solution that might be good at solving the given problem.
- Fitness: To assess how good an individual is at solving the problem the individual hast to be evaluated. This is achieved assigning a fitness value. Typically, the higher the fitness value the better the individual is at solving the problem. Therefore, this can be seen as a maximisation problem.
- To iteratively evolve the population over so-called generations, reproduction and selection are used to produce offspring and select the “best“ individuals to transfer to the next generation.
Let’s take a look at the operators:
- Recombine parent individuals to create offspring. However, recombining individuals can be difficult since it involves domain knowledge to produce viable individuals.
- Mutate individuals to embrace innovation. To increase the diversity, individuals can be mutated to introduce new approaches/solutions to the population.
- Select individuals that will be part of the next generation. However, what are the „best“ individuals to retain in the population?
The following figure illustrates how the evolution can be performed.
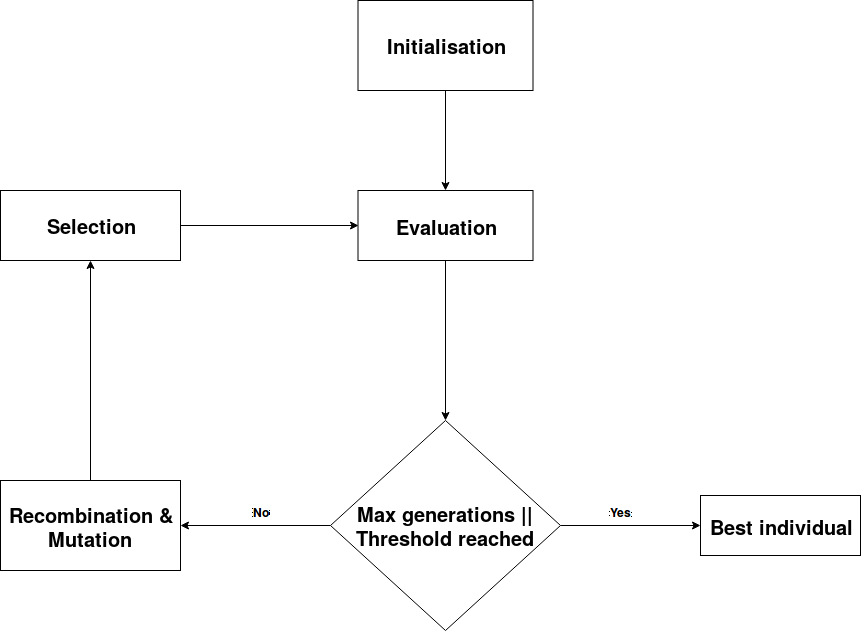
- Initialise population (Generation 0)
- Evaluate population of current generation by assigning fitness values to the individuals
- Check if the evolution can be stopped (go to step 7)
- Maximum number of generations is reached
- If the threshold of the fitness value is reached, one or more individuals are able to solve the problem/task sufficiently
- Recombine and mutate individuals
- Select individuals to take over to the next generation/individuals that are allowed to stay in the population
- Go to step 2
- Return best individual that was found throughout the evolution
One aspect that makes EC interesting is scalability. Operations can be performed in parallel and allow reduction of the overall runtime. Individuals can be evaluated separately. In addition, recombination and selection can be done in parallel as well. Using one of the several cloud environments, we are able to speed up the computation time for a task.
It is difficult to select the best individuals from a population. One might think that retaining the n best individuals would be the best solution. However, it is important to look at both short-term and long-term performance of the evolution:
Just imagine you would assess the ability of a robot to move forward. As a metric, you could measure the distance that the robot travelled with respect to the part of the body that is the furthest away from the origin. Now imagine two individuals A and B. A just falls on the ground. His head is the part of his body which is the furthest away from the origin. B just jumps upwards and does not move in any direction. Therefore, A covered more distance than B. B could possibly be removed from the population since he did not achieve any visible progress. However, B was able to figure out how to jump and may provide a valuable innovation that can help solving the task.
This thought experiment shows how difficult it is to retain the best individuals in a population. Overall, EC represents a powerful way of solving a variety problems. However, EC should not be forced on a problem. If it is too difficult to encode your problem for EC, it might not be the best solution. Moreover, as the no-free-lunch theorem states, it does not achieve the best performance on every problem. Exhaustive testing of (hyper-)parameters and used recombination, mutation, and selection algorithms is necessary.
What is Neuroevolution?
Neuroevolution describes the evolution of Artificial Neural Networks (ANNs) to solve a given problem or task. Each individual represents an ANN. Stanley and Miikkulainen (2002) describe the history of Neuroevolution in their paper called NeuroEvolution of Augmenting Topologies (NEAT). They talk about the history and different ways of evolving ANNs. Topology and Weight Evolving Artificial Neural Networks (TWEANNs) is a concept that refers to evolving both topology and weight of an ANN.
The algorithm that they describe in the NEAT paper also evolves both weights and topologies. They introduced interesting concepts that can accelerate the evolution. Let’s briefly look at them:
- Start from minimal solution and increase the complexity of ANNs over time.
- History in form of an innovation number. Every gene and therefore the the ANN are traceable. This does not only allow insight into the „heritage“ but also provide a more informed way of mating ANNs to create offspring.
- Introduce species. ANNs in the population are grouped into species. Using some distance function, the similarity of ANNs can be expressed. The main reason to introduce this feature, was to prevent premature convergence. This refers to the process of losing diversity in the population which can hinder the search for a (near-)optimal solution.
The following video by Seth Bling demonstrates the use of NEAT to play Super Mario World. I think the progress from not knowing anything about the environment to becoming a skilled player at the game illustrates the process in a „neat“ way. This represents a reinforcement learning task since we receive only sparse rewards. A run is only successful if Mario was able to reach the flag at the end of a level. We do not have a feedback for every state that the game is currently in unlike supervised learning where every input is labelled.

By loading the video, you agree to YouTube's privacy policy.
Learn more
The fitness represents the distance from the origin with respect to the time. Therefore, the further an individual proceeds to go right and the less time it uses to do so, the higher the resulting fitness value. As you can see, constructing a fitness function can be tricky and is highly problem depended.
Two other concepts that Stanley introduces are Novelty Search and Open-Ended Evolution. Novelty search refers to the idea of embracing innovation by rewarding new behaviour. Open-ended evolution is, as the name might suggest, an evolution that does not aim to reach an objective. I believe that it could be very interesting to see what evolution (and therefore computers) are able to achieve. Do they reach the human-level experience or even go beyond it and find interesting new ways of solving problems? I believe that these topics offer very interesting insight into „real“ natural evolution and might even offer some surprises for us humans.
Supervised Learning and Neuroevolution
Solving specific Artificial Intelligence (AI) related tasks is also referred to as narrow AI. I believe that the holy grail of general AI is very difficult to achieve. Instead, let’s try to divide it into subtasks. Deep Learning (DL) reached state-of-the-art results in various domains (e.g. image classification). However, constructing these complex ANNs within DL is a time-consuming task. Obviously, why not try to automate the task and use the time for more important things … like playing Super Mario World?
Recent research from Uber, Google Brain and some others goes towards combining supervised learning with Neuroevolution. This can be seen as an architecture search for ANNs. Instead of evolving the weights, they are rather trained in a supervised fashion (e.g. backpropagation). In addition, they try to overcome the problem of NEAT being too fine-grained for some tasks. Instead of evolving topologies by adding single neurons or connections, there are approaches that are layer-based or module-based. As one might suspect, layer-based approaches use layers to construct the topology of an ANN. Module-based approaches try to build modules that can be reused to build larger topologies by assembling several modules (e.g. just like assembling inception modules together). In the following, I will briefly describe some approaches which I find interesting. In addition, they were actually able to demonstrate the success of evolving ANNs for supervised learning tasks.
CoDeepNEAT by Miikkulainen et al. (2017) represents an approach that utilises features which can be found in NEAT (hence the similar name). They can be referred to as a module-based approach. They actually use two populations to evolve ANNs: a population for modules and a population for blueprints. A blueprint can be thought of as an abstract or higher-level description of an ANN. Instead of neurons, the blueprint contains nodes which each refer to a species of modules which are separately evolved in the module population. The demonstrated the performance of this approach on image classification and language modelling.
Google Brain published two papers Large-Scale Evolution of Image Classifiers (2017) and Regularized Evolution for Image Classifier Architecture Search (2018). They focused on the scalability of the used approaches. One integral part is the use of a tournament selection where individuals compete against each other. The winner(s) are part of the next generation of the population. The use of this selection strategy allows asynchronous execution of the evolution. The experiment took 7 days with 450 GPUs (K40) and 5 days with 900 TPUs. They achieved state-of-the-art results on CIFAR-10.
I think it is intriguing to see what researchers are coming up with. The approaches offer interesting views on the problem from different perspectives (e.g. module- vs layer-based).
Scaling Artificial Neural Networks
For my thesis project, I evaluated the evolution of ANNs in a cloud environment to provide scalability. Therefore, the following research questions came up:
- How well does it scale?
- How well does the performance of resulting ANNs evolve?
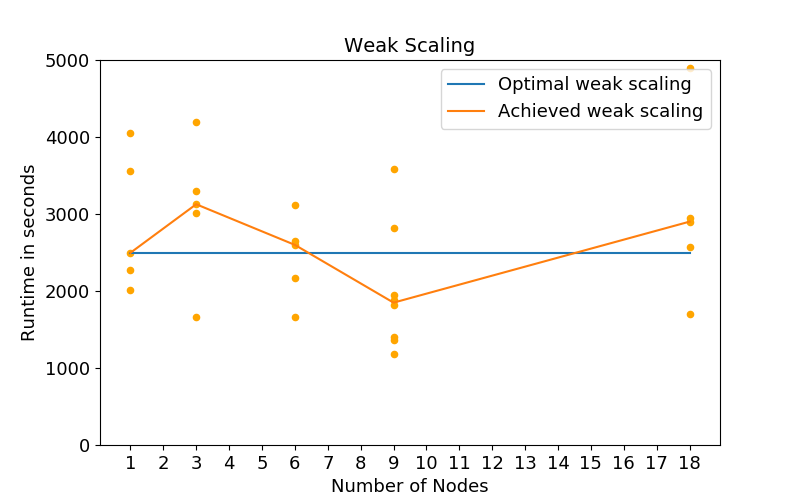
For the evaluation, I used Fashion-MNIST by Zalando. Fashion-MNIST contains images of clothes (shoes, shirts, etc.) and has the same dimensions as MNIST. To assess the scalability of the implemented prototype, I measured both strong and weak scaling. Strong scaling refers to scaling resources while the problem size is fixed. For weak scaling both problem size and resources are increased over time while the problem size per number of resources remains constant (e.g. here constant number of ANNs that are evaluated per node).
To assess the performance of the resulting ANNs, the accuracy on the validation and on the test set are being recorded. Only training and validation set are used for the evolution and training. Thus, overfitting is prevented. However, to evaluate the ability to generalise, the accuracy on the test set is recorded. The following figure displays the accuracy on validation (left) and test set (right). Each point in the figure represents the accuracy of an ANN with respect to the time its training started.
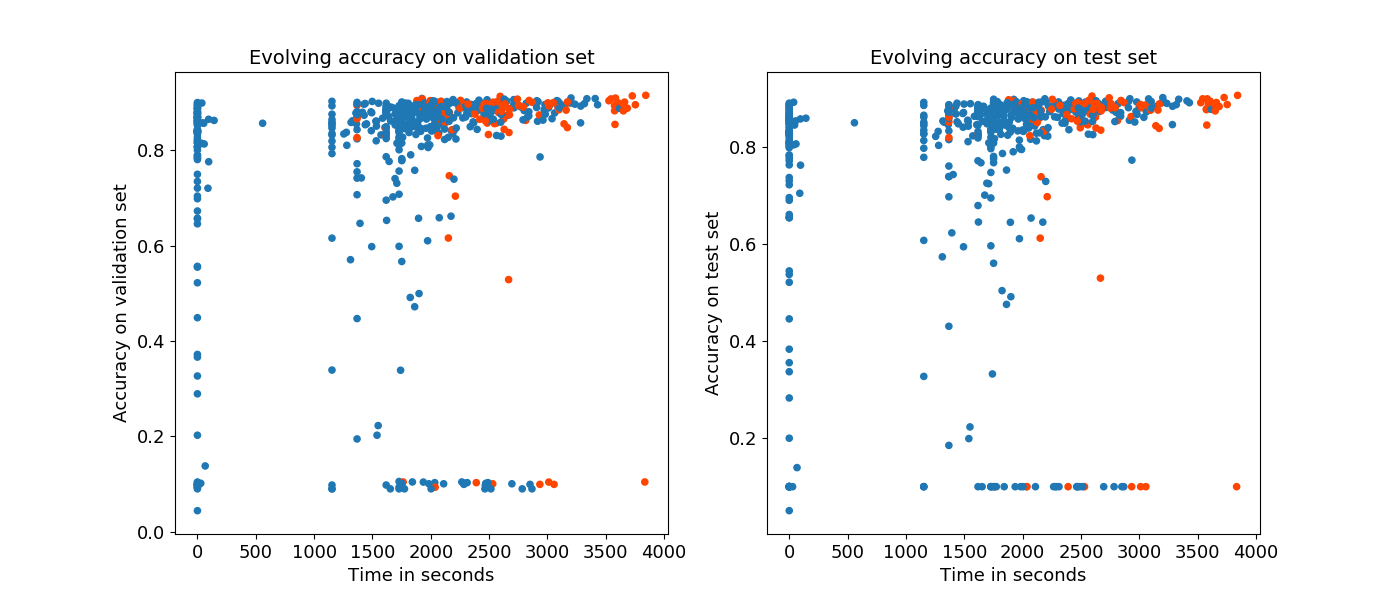
The ANNs are converging and overall the evolution is able to improve the average accuracy over all networks. In addition, there is no overfitting visible. Both accuracy on validation and test set have similar values. Therefore, we can reason that the approach is able to generalise.
Let’s look at the maximum accuracy achieved over time now. We would be happy if there is just one ANN that performs really well and that we could use in production. The following figure displays the highest accuracy seen so far on the validation (left) and test set (right).
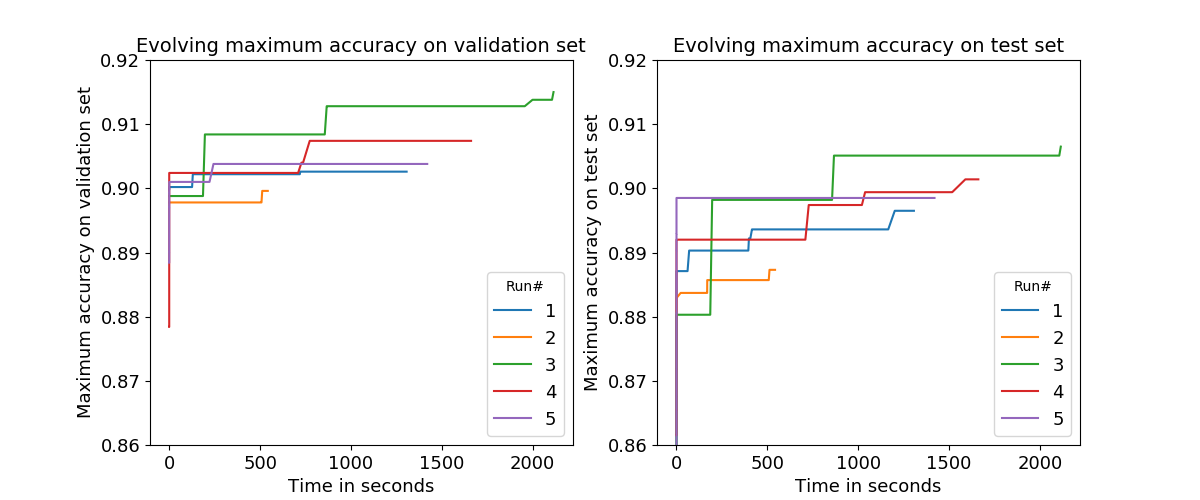
As we can see, the runs have different lengths (hint: non-deterministic). Moreover, they plateau at different points in time. However, overall we can see that every run is able to improve over time, and that both scalability of the prototype and performance of the resulting ANNs look promising.
Conclusion and Future Work
I hope I was able to provide an insight into the field of evolving Artificial Neural Networks within the domains of supervised and reinforcement learning. Neuroevolution represents one solution to architecture search for narrow AI problems. Using one of the several cloud environments, the process can be scaled-out to reduce the computation time. There are lots of possibilities for future research. The use of other data sets within image classification or even other domains (e.g. natural language processing) can be evaluated. Overall, there is a lack of implementations of algorithms/papers. Other hardware such as GPUs or TPUs can provide further insight into the power and scalability of Neuroevolution. In addition, the training of ANNs can be distributed to improve the task distribution among used resources.
Just keep this in mind: innovation and creativity can be the key to success. Thinking differently might just lead you to the solution for a problem.



test