
Hinweis:
Dieser Blogartikel ist älter als 5 Jahre – die genannten Inhalte sind eventuell überholt.
Assistenzroboter werden immer populärer und finden deshalb zunehmend Verwendung in den verschiedensten Einsatzszenarien. Staubsauger-Roboter oder Rasenmäher-Roboter helfen uns beispielsweise bereits seit einigen Jahren im Haushalt. Im kommerziellen Bereich werden Service-Roboter eingesetzt, um die unterschiedlichsten Aufgaben zu übernehmen. Sie dienen als interaktiver Produktberater oder als Wegweiser in Flughäfen und Einkaufszentren. [1]
Gestenerkennung & -Steuerung von Assistenzrobotern
Die möglichen Szenarien sind breit gefächert. Ein hohes Potenzial wird zukünftig etwa vom Pflegesektor ausgehen. Dies lässt sich auf den demographischen Wandel und dem damit einhergehenden ansteigenden Mangel an Pflegepersonal zurückführen. Assistenzroboter können hierbei die Rolle von sinnvollen Unterstützern im Alltag einnehmen. [2]
Ein möglicher Anwendungsfall fokussiert den Gesundheitssektor. Laut der Bundeszentrale für gesundheitliche Aktivität besitzen Menschen, die sich nicht regelmäßig aktiv bewegen, ein höheres Risiko von altersbedingten Krankheiten betroffen zu sein. [3] Geeignete Präventionsmaßnahmen können die Gesundheit der älter werdenden Bevölkerung fördern. Dieser Aufgabenkomplex lässt sich wunderbar durch eine assistive Technologie abdecken: Man stelle sich einen Roboter vor, der zusammen mit Senioren einfache Sportübungen durchführt und diese dabei interaktiv begleitet.
Im Rahmen meiner Masterthesis habe ich diese Idee in die Realität umgesetzt. Zum Einsatz kam hierbei der humanoide Roboter Pepper des Herstellers Softbank Robotics. Pepper begleitet den/die Nutzer:in durch ein interaktives Trainingsprogramm, führt ihm verschiedene Übungen vor und überprüft die Bewegungsausführung mittels seiner visuellen Sensoren. Zudem kann Pepper durch verschiedene Gesten gesteuert werden. In diesem Blog werden die Umsetzung der beschriebenen Szenarien sowie die Ergebnisse meiner Masterthesis beschrieben und zusammengefasst.
Thematischer Hintergrund
Assistenzroboter können mittels verschiedener Methoden gesteuert werden. Von besonderem Interesse sind natürliche und intuitive Wege, um mit diesen Systemen zu interagieren. Meist erfolgt die Bedienung mittels Sprachsteuerung oder Touch-Bildschirmen – sei es am Roboter selbst oder durch verknüpfte externe Geräte wie Smartphones.
Eine weitere Möglichkeit bietet die Gestensteuerung. Wir benutzen Gesten in alltäglich, während wir mit unseren Mitmenschen interagieren. Wir winken einer Person zu, um sie zu begrüßen oder ihr zu signalisieren wo wir uns befinden. Wir zeigen in eine bestimmte Richtung, um auf Objekte zu deuten oder um einen Weg zu erklären und wir verwenden Gesten, um unseren Kommunikationspartner die Größe von Gegenständen zu verdeutlichen. Weiterhin basiert die Gebärdensprache beinahe vollständig auf der Gestikulation. Gesten spielen in der zwischenmenschlichen Kommunikation also eine wichtige Rolle.
Eine Übertragung dieser Kommunikationsform auf den Kontext der Mensch-Roboter-Interaktion liegt daher nahe. Besonders für humanoide Roboter, die der menschlichen Gestalt nachempfunden sind und überwiegend für kommunikative und soziale Zwecke eingesetzt werden, können Gesten eine sinnvolle und nützliche Interaktionsform bieten – auch im Hinblick auf eine barrierefreie Benutzung dieser Technologien. Zentrales Thema meiner Masterthesis ist daher die Gestenerkennung und Gestensteuerung unter Verwendung eines Assistenzroboters. Doch was sind Gesten überhaupt?
Gesten
Allgemein sind Gesten Bewegungen des Körpers oder einzelner Körperteile, die bestimmte Informationen zu vermitteln oder zu verstärken versuchen. Sie zeichnen sich durch ihren nonverbalen kommunikativen Charakter aus und treten in unterschiedlichen Formen auf. In der Mensch-Computer-Interaktion werden Gesten genutzt, um einem System Anweisungen zu geben. [4]
Gesten können in ihrer Art und ihrem Zweck sehr unterschiedlich sein. Es existieren zunächst zwei grundlegende Arten: Statische und dynamische Gesten. Bei einer statischen Geste findet keine Bewegung während der Informationsübermittlung statt. In dieser Zeit verweilt die ausführende Person in einer festen Pose oder Haltung. Ein Beispiel hierfür ist die Daumen-hoch-Geste. Im Gegensatz dazu ist eine dynamische Geste durch Bewegung gekennzeichnet. Sie besitzt damit einen festen Anfangs- und Endpunkt. Ein und dieselbe Geste kann hierbei in ihrer Ausführungsform und -geschwindigkeit variieren. Diese Eigenschaft muss bei der Entwicklung eines Systems zur Gestenerkennung unbedingt berücksichtigt werden. [5]
Eine Geste soll weiterhin einen bestimmten Zweck erfüllen. In der Fachliteratur zur Gestenforschung wird häufig eine Unterteilung in manipulative, pantomimische, semaphorische, deiktische und abstrakte Gesten vorgenommen. Manipulative Gesten beabsichtigen die Beeinflussung eines Objektes. Pantomimische Gesten werden genutzt, um bestimmte Aktionen zu imitieren. Durch semaphorische Gesten können Signale vermittelt werden. Ein Beispiel hierfür ist die Gebärdensprache. Zeigen wir auf ein Objekt oder eine Richtung, dann benutzen wir deiktische Gesten. Diese Form wird auch als Zeige-Geste bezeichnet. Abstrakte Gesten dienen zur Verstärkung des gesprochenen Wortes und werden von uns meist unbewusst während der verbalen Kommunikation genutzt. Zudem besitzen Gesten auch physikalische Eigenschaften, beispielsweise die involvierten Körperteile, die Dauer und Geschwindigkeit der Ausführung, die räumliche Position oder die Dimensionalität (2D oder 3D). [5][6]
Aber was bringt uns das jetzt für die Gestenerkennung?
Verfahren der Gestenerkennung
Ganz einfach: Die Art einer Geste bestimmt signifikant die Anforderungen an das Verfahren zur Gestenerkennung. Dynamische Gesten sind weitaus komplexer als statische Posen. Ein Erkennungsverfahren muss die Nutzerbewegungen erfassen, analysieren und korrekt einem Befehl zuordnen. Es besteht deshalb aus mehreren Teilkomponenten, die diese einzelnen Sub-Aufgaben übernehmen: der Datenerhebung, der Merkmalsextraktion und der Gestenklassifikation. Zudem müssen wir den Anfangs- und Endpunkt einer Geste korrekt identifizieren, was im Fachjargon als Gesten-Segmentierung oder Gesten-Spotting bezeichnet wird. Dies ist nötig, um bewusst ausgeführte Gesten (mit Interaktionsabsicht) von unbewusst ausgeführten Bewegungen unterscheiden zu können.
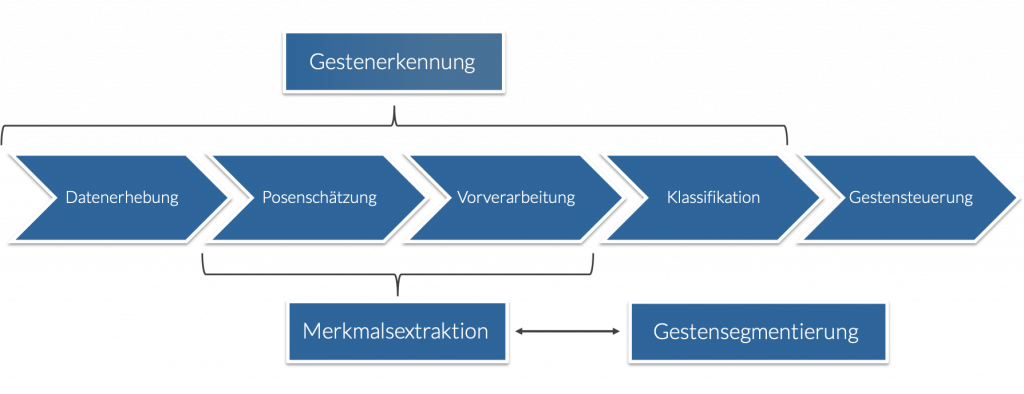
Datenerhebung
In diesem Prozess geht es um die Erfassung der Gestenbewegung durch die Sensorik des verwendeten Systems. Es existieren verschiedene Typen, die sich zunächst primär in der eingesetzten Technologie unterscheiden:
Zum einen gibt es gerätebasierte Verfahren. Hier ist das Tragen oder Halten externer Geräte oder Marker notwendig. Beispiele hierfür sind Datenhandschuhe oder Remote-Controller. Die Vorteile dieser Verfahren spiegeln sich in sehr guten Erkennungsraten und ein auf den Anwendungskontext zugeschnittenes Bedienkonzept wieder. Dies stellt jedoch zeitgleich eine Einschränkung dar, da sich diese Systeme in der Regel schlecht erweitern lassen. Weiterhin kann das Tragen dieser Geräte für Nutzer:innen einen Störfaktor darstellen.
Optische Verfahren hingegen besitzen diese Einschränkung nicht. Der/die Nutzer:in wird durch optische Sensoren erfasst und benötigt keine weiteren Geräte. Diese Form der Datenerhebung erfordert jedoch weitaus komplexere Verfahren, um gute Erkennungsraten erzielen zu können. Nachdem ein:e Nutzer:in durch die Sensoren erfasst wurde, muss in den erhobenen Daten nach Merkmalen gesucht werden, die eine Geste beschreiben. Dieser Vorgang nennt sich Merkmalextraktion.
Merkmalextraktion
Das Ziel der Merkmalextraktion ist die Erstellung eines Merkmalvektors, der alle für die Geste relevanten Informationen beinhaltet und damit als Grundlage für die darauffolgende Klassifikation genutzt werden kann. Es existieren unterschiedliche Ansätze, um Daten aus einem Kamerabild zu extrahieren. [6] Im Rahmen meiner Arbeit habe ich hierfür die sogenannte Posenschätzung verwendet.
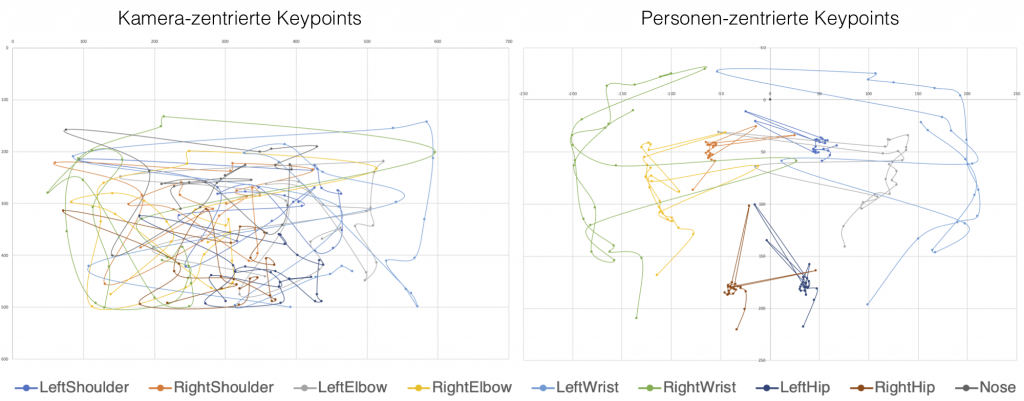
Die Posenschätzung ist ein Prozess, bei dem eine Schätzung der Konfiguration der Körperteile der Nutzer:innen aus dem Kamerabild erfolgt. Hierfür werden die Gelenke sowie die Nase, Augen und Ohren der Nutzer:innen im Kamerabild identifiziert und mit sogenannten Keypoints überlagert. Diese Keypoints besitzen räumliche Koordinaten und eine Zugehörigkeit zum jeweiligen Körperteil. Durch das Verbinden der Keypoints entsteht eine vereinfachte Skelettdarstellung, mit der die aktuelle Pose bestimmt werden kann. Führen wir diesen Prozess auf jedem Kamerabild unsere Gestensequenz aus sind wir in der Lage Bewegung festzustellen.

Die Kamerabilder werden in der entwickelten Anwendung durch die Kopfkamera Peppers erfasst. Der Roboter ist von Haus aus konfiguriert, Nutzer:innen mit seinem „Blick“ zu fokussieren und zu „verfolgen“. Dies bietet uns den Vorteil, dass der Benutzer stets durch die Kamera erfasst wird, selbst wenn er sich vor dem Roboter wenige Meter bewegt. Jedoch bietet diese Kamera lediglich eine Bildrate von 1 fps. Um Bewegung zu erfassen ist dies zu gering, weshalb ich zunächst das Verfahren zur Aufnahme analysiert und durch Einsatz des Android LruCache optimiert habe. Hierdurch konnte eine Verbesserung der Bildrate um 3 fps erreicht werden. Diese Bildrate genügt, um Bewegungen der Nutzer:innen zu erfassen. Sehr schnelle Bewegungen sind jedoch nach wie vor problematisch. Durch die Verwendung leistungsfähigerer Hardware kann an dieser Stelle ein erheblicher Mehrwert generiert werden. Zu beachten ist jedoch, dass der Rechenaufwand mit steigender Bildrate linear zunimmt.
Die Daten der Posenschätzung besitzen zunächst noch diverse Abhängigkeiten, die aufgelöst werden müssen; beispielsweise die Position der Nutzer:innen im Kamerabild oder die Körpergröße und Arm- und Beinlänge. Weiterhin kann die Posenschätzung für einzelne Keypoints fehlschlagen, weshalb ein geeignetes Korrekturverfahren benötigt wird. Diese Herausforderungen werden im Rahmen der entwickelten Vorverarbeitung übernommen.
Im ersten Schritt der Vorverarbeitung erfolgt eine Umwandlung des Koordinatensystems der Keypoints. Nach der Aufnahme liegen die Koordinaten in einer kamerazentrierten Form vor. Bei einer Kamerabewegung ändern sich demzufolge auch die räumlichen Parameter der Keypoints. Hierdurch wird im System eine Bewegung der Nutzer:innen registriert, selbst wenn dieser keine Körperbewegung ausführt. Durch die Umwandlung der kamerazentrierten Koordinaten in personenzentrierte Koordinaten wird diese Abhängigkeit aufgelöst. Als neuer Koordinatenursprung wird der im Durchschnitt am robustesten erkannte Keypoint verwendet – in unserem Fall die Nase der Benutzer:innen. Alle anderen Keypoints besitzen nach der Umwandlung eine relative Position zu diesem Punkt. Durch entsprechende Korrekturverfahren (siehe nächster Abschnitt) ist die Behandlung fehlerhaft detektierter Nasen-Keypoints möglich. Die folgende Grafik zeigt die Umwandlung der Koordinaten für eine Auf- und Abbewegung beider Arme.
Die Korrektur von fehlerhaft detektierten Keypoints erfolgt im zweiten Schritt der Vorverarbeitung. Fehlerhafte Keypoints werden auch als Ausreißer bezeichnet. Sie können durch Verdeckungen einzelner Körperteile, schnellen Bewegungen oder bei einer schlechten Trennung von Vorder- und Hintergrund auftreten. Die Detektion dieser Keypoints erfolgt durch die Einführung eines sogenannten z-Wertes. Der z-Wert ermöglicht es einen Messwert m aus einem Datensatz daraufhin zu prüfen, wie viele Standardabweichungen σ dieser über oder unter dem Mittelwert μ eines Datensatzes liegt. Dies geschieht durch Subtraktion des Mittelwerts μ vom Messwert m und anschließender Division des Ergebnisses durch die Standardabweichung σ der Grundgesamtheit. [8]
In unserem Fall besteht der Datensatz aus den Distanzen eines jeden Keypoints. Dieser legt über den Zeitraum der Gestenausführung hinweg eine gewisse Distanz zurück, welche für jeden Zeitpunkt t zu seinem Vorgänger zum Zeitpunkt t-1 bestimmt werden kann. Für jeden dieser Messwerte können wir den z-Wert bestimmen. Durch einen empirisch zu ermittelnden festen Schwellwert kann nun die Detektion eines Ausreißers erfolgen. Wird ein Keypoint als Ausreißer erkannt, muss dieser noch korrigiert werden. Hierfür gibt es unterschiedliche Herangehensweisen. Am geeignetsten im vorliegenden Kontext ist die Verwendung eines Annäherungsverfahrens. Hierfür bilden wir den Mittelwert der (x,y)-Koordinaten des Ausreißers zum Zeitpunkt t und dessen Vorgänger- und Nachfolger-Keypoints zu den Zeitpunkten t-1 sowie t+1. Stellen diese Keypoints ebenfalls Ausreißer da, wird der Zeitpunkt entsprechend bis zum nächsten korrekt erkannten Keypoint verschoben. In den nachfolgenden Diagrammen wird die Korrektur der Ausreißer beispielhaft für unsere Auf- und Abbewegung der Arme visualisiert.

Eine letzte Abhängigkeit betrifft die Körpergröße bzw. die Arm- und Beinlängen verschiedener Nutzer:innen. Um diese aufzulösen, berechnen wir die Orientierung benachbarter Keypoints zueinander. Hierbei hilft die Betrachtung der vereinfachten Skelettdarstellung. Aufgrund des relativ kleinen Gestenalphabets meiner Anwendung habe ich mich für die Einteilung in 20°-Bereiche entschieden.
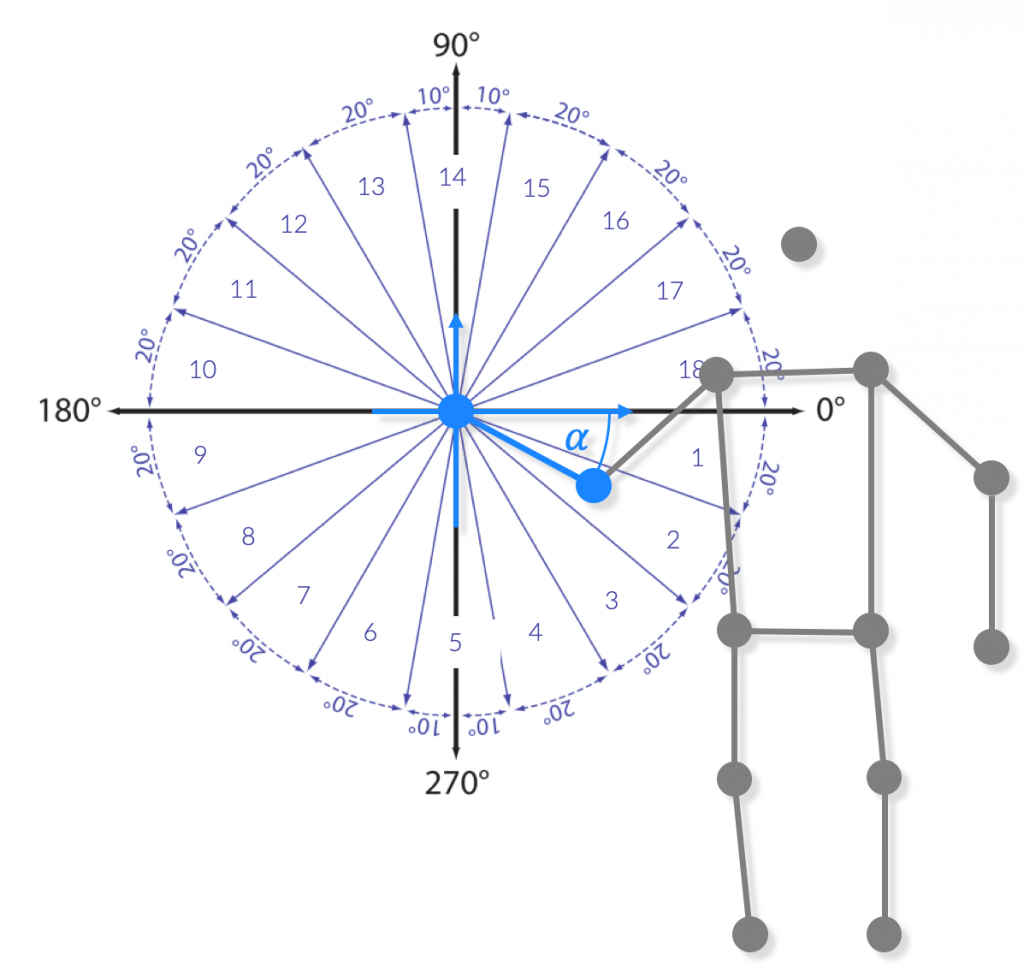
Über den Zeitraum der Gestenausführung hinweg entsteht somit für jeden Keypoint eine Symbolfolge. Der Merkmalsvektor M als Ergebnis der Merkmalsextraktion besteht somit aus einer Menge von Symbolfolgen, die eine dynamische Geste vollständig beschreiben und im nächsten Schritt als Datengrundlage für die Klassifikation dient.
Klassifikation
Als Klassifikation wird die Zuordnung von Objekten oder Prozessen zu einer Klasse von Instanzen bezeichnet. Im Kontext der Gestenerkennung wird in diesem Schritt einer ausgeführten Geste eine konkrete Bedeutung (Klasse) zugewiesen. Hierfür existiert eine große Bandbreite an Verfahren, die sich grundlegend in statistische Methoden, Distanzmetriken und Methoden des maschinellen Lernens unterscheiden. Die Wahl des Klassifikators hängt von der Beschaffenheit des Merkmalvektors ab. Für die Klassifikation dynamischer Gesten eignen sich beispielsweise Hidden-Markov-Modelle, Dynamic-Time Warping (DTW) oder der Random Forest. Ein Vergleich der unterschiedlichsten Klassifikatoren würde genug Stoff für eine eigene Thesis bieten, weshalb an dieser Stelle nicht weiter darauf eingegangen wird. Aufgrund der erfolgreichen Verwendung in verwandten Arbeiten habe ich mich für die Implementierung des Random Forest und des DTW entschieden, um diesbezüglich einen Vergleich anstellen zu können.
Der Random Forest bietet hohe Erkennungsraten bei einem ausreichend großen Trainingsdatensatz. Der DTW kommt hingegen auch schon mit wenig Beispieldaten zurecht, weshalb dieser in der finalen Anwendung zum Einsatz kommt. Steigt die Größe des Gestenalphabets oder ist eine Unterscheidung ähnlicher Gesten nötig, ist die Identifikation eines geeigneteren Verfahrens notwendig. Insgesamt habe ich für die prototypische Anwendung 8 Bewegungsübungen und 8 Gesten entwickelt. Für jede dieser dynamischen Gesten sind 10 Muster in einer SQLite-Datenbank hinterlegt. Diese dienen als Datengrundlage zur Ermittlung der DTW-Distanz eines Eingangssignals. Das Muster mit der niedrigsten Distanz zum Eingangssignal gewinnt den Prozess der Klassifikation und gibt seine zugehörige Klasse als Ergebnis aus. Die durchschnittliche Erkennungsrate für die Bewegungsübungen beträgt ca. 85%; für die Gesten zur Steuerung ca. 65%, was in Anbetracht der geringen Größe des Trainingsdatensatzes als relativ gut eingestuft werden kann.
Das entwickelte Verfahren zur Gestenerkennung wurde in einer prototypischen Anwendung implementiert, in der Pepper als Bewegungstrainer fungiert und mittels verschiedener dynamischer Gesten gesteuert werden kann.
Bewegungstrainer
Das Bewegungstraining mit Pepper ist primär auf die Zielgruppe von Senioren ausgerichtet – kann aber auch für Menschen sinnvoll sein, die ihren Arbeitsalltag am Schreibtisch verbringen. Insgesamt habe ich 8 Bewegungsübungen auf Pepper portiert. Diese basieren auf Empfehlungen der Bundeszentrale für gesundheitliche Aufklärung, die im Rahmen ihres Präventionsprogramms „Älter werden in Balance“ entwickelt wurden und die Beweglichkeit der menschlichen Gelenke fördern sollen:








Während des Bewegungstrainings gibt Pepper dem Benutzer fortlaufend Anweisungen und informiert ihn über die erforderlichen Schritte. Dies erfolgt überwiegend durch Sprachausgabe und Gestikulation. Das integrierte Tablet dient lediglich der Anzeige von Ladevorgängen und der Bereitschaft zur Gestenausführung.
Im ersten Schritt des Bewegungstrainings gibt Pepper dem/der Nutzer:in ein kleines Intro und informiert ihn über den Ablauf sowie die grundlegende Benutzung der Anwendung. Daraufhin führt Pepper die erste Bewegungsübung vor. Die Auswahl erfolgt zufällig aus dem Übungskatalog. Danach erfolgt eine Aufforderung, die gleiche Übung für 30 Sekunden auszuführen. Während dieser Zeit überprüft Pepper die Bewegung der Nutzer:innen mittels der entwickelten Gestenerkennung und motiviert die Nutzer:innen durch Sprachausgabe. Im Fall einer fehlerhaft ausgeführten Übung führt Pepper diese nochmals vor und bittet um eine Wiederholung. Eine korrekte Ausführung startet die nächste, noch offene Übung.
Motivierende Sprüche sollen den Trainierenden bei Laune halten. Zudem werden dem Benutzer in bestimmten Situationen Fragen gestellt; beispielsweise ob er die aktuell vorgeführte Bewegungsübung verstanden hat oder ob er das Bewegungstraining ein zweites Mal ausführen möchte. Die Beantwortung dieser Fragen erfolgt mittels der entwickelten Ja- und Nein-Geste, die Teil des zweiten Anwendungsfalls Gestensteuerung sind.
Gestensteuerung
Weiterhin ist eine Steuerung Peppers durch Gesten möglich. Eine wichtige Anforderung für gestische Benutzungsschnittstellen stellt die leichte Erlernbarkeit der Befehle dar. Komplexe Gesten sind – wenn möglich – zu vermeiden oder in mehrere einfach erlernbare Gesten aufzuteilen. Weiterhin darf die Händigkeit keine Rolle spielen, um Links- sowie Rechtshändern eine gute Benutzbarkeit zu ermöglichen. Ein primäres Ziel beim Entwurf der Gesten besteht darin, eine möglichst natürliche Interaktion mit dem System zu erzielen, die an die jeweilige Arbeitsaufgabe und den Kontext zugeschnitten ist.
Bekannte Gesten aus der realen Welt können hierbei helfen. Beispielsweise wissen Menschen, wie sie einen realen Gegenstand verschieben können. Dieses Wissen können wir ausnutzen, um die gleichen bekannten Bewegungsabläufe auf den virtuellen Raum zu übertragen und bezüglich des Beispiels einen Befehl zum Verschieben von virtuellen Objekten zu realisieren. [9][10] Besonders für die Zielgruppe von Senioren ist darauf zu achten, die Gesten möglichst einfach zu halten und komplizierte oder schwer ausführbare Bewegungen zu vermeiden. [11][12]
Im Rahmen der prototypischen Lösung habe ich 8 Gesten entwickelt. Diese können für das Bewegungstraining und die Steuerung von Pepper eingesetzt werden. Zur gestischen Beantwortung von Fragen kann ein Benutzer beispielsweise eine Ja- oder Nein-Geste ausführen. Mittels der Hallo-Geste kann der Anwender Pepper begrüßen. Hierdurch startet das Bewegungstraining. Einfache Navigationsanweisungen erfolgen durch das Zeigen nach Links oder Rechts, worauf Pepper genau einen Meter in die jeweilige Richtung fährt. Weiterhin folgt Pepper dem Benutzer nach Ausführung der entwickelten Folge-Mir-Geste. Zudem ist es möglich die Spracherkennung des Roboters zu aktivieren (Zuhören-Geste) oder mit Pepper zu Tanzen (Tanzen-Geste).

Ein zusätzlich implementiertes Tutorial erläutert neuen Anwendern die grundlegende Steuerung sowie Funktionalitäten der prototypischen Lösung. In diesem erklärt Pepper Nutzer:innen zunächst die Ja- und Nein-Geste, welche zur Entscheidungsfindung in unterschiedlichen Situationen des Bewegungstrainings nötig sind. Nutzer:innen werden dabei interaktiv einbezogen. Dies fördert die Erlernbarkeit der Anwendung und der Gesten. Danach erklärt Pepper dem Benutzer die restlichen Gesten zur Steuerung, woraufhin die Nutzer:innen das Bewegungstraining oder die Gestensteuerung starten kann.
Evaluation und Ergebnisse
Die prototypische Lösung wurde anschließend einer Evaluation unterzogen, in der ingesamt 10 Probanden (6 Frauen, 4 Männer) die Gestensteuerung testeten sowie das Bewegungstraining mit Pepper absolvierten. Die Durchführung bestand aus den drei Aufgaben Tutorial, Gestensteuerung und Bewegungstraining. Das Ziel war es, mögliche Probleme hinsichtlich der Gestenerkennung und -Steuerung sowie der Anwendung aufzudecken, um daraus zukünftige Optimierungen ableiten zu können.
Die Ergebnisse fielen hierbei überwiegend positiv aus. Die meisten Probanden hatten keine Probleme, sich die entwickelten Gesten zu merken und sprachen den Gesten eine leichte Ausführbarkeit zu. Lediglich bei der Nein-Geste kam es gelegentlich zu fehlerhaften Ausführungen seitens der Probanden. Weiterhin entsprachen die Gesten überwiegend den Vorstellungen der Teilnehmer. Drei Probanden äußerten den Wunsch einer zusätzlichen Sprachsteuerung für einzelne Gesten; vor allem für die Entscheidungsgesten. Dies spricht für einen multimodalen Ansatz in zukünftigen Entwicklungen auf diesem Gebiet. Als Vorbild kann hier die zwischenmenschliche Interaktion dienen, die von der Verwendung von Sprache und Gesten lebt. Jedoch sollte im Sinne der Barrierefreiheit auf alternative Bedienkonzepte zurückgegriffen werden können.
Alle Teilnehmer empfanden die Rolle eines humanoiden Roboters als Bewegungstrainer sinnvoll und hatten Spaß an der Benutzung. Die Interaktivität und die Rückmeldungen des Roboters wurden besonders positiv hervorgehoben. Die entwickelte Gestenerkennung prüft lediglich die Klasse der Übung. Einige Probanden äußerten den Wunsch, dass sie bei verschiedenen Übungen gern genaueres Feedback bezüglich der Ausführung erhalten hätten („Was hätte ich anders machen müssen?“). Hierfür sind komplexere Verfahren zur Bewegungsanalyse nötig, was als interessante Herausforderung für zukünftige Forschungsarbeiten auf diesem Gebiet dienen kann.
Die Erkennungsraten des Systems schwankten deutlich zwischen den Benutzern. Die Bewegungsübungen wurden in ca. 85% der Fälle korrekt erkannt. Bei den Gesten zur Steuerung des Roboters kam es häufiger zu Problemen (60% korrekt erkannt). Da die Kamera des Roboters lediglich Bewegungen mit einer Bildrate von 3fps erfasst, kam es bei einer zu schnellen Ausführung entsprechend zu Schwierigkeiten. Bei den Bewegungsübungen orientierten sich die Probanden an der Geschwindigkeit des Roboters, weshalb die Erkennungsraten hier besser ausfielen. Die Verwendung von Kameras mit höheren Bildraten kann dieses Problem lösen, bedarf jedoch weiterer Untersuchungen.
Zusammenfassung
Körpergesten bieten ein hohes Potenzial zur Steuerung von Assistenzrobotern. Vor allem für körperlich beeinträchtigte Menschen können sie eine sinnvolle Alternative zur Sprachsteuerung darstellen. Im Kontext humanoider Roboter können sie aufgrund der Parallelen zur zwischenmenschlichen Kommunikation einen sinnvollen Beitrag zur multimodalen Interaktion leisten und so eine natürliche Bedienung dieser Systeme fördern.
[1] Roboter im Einzelhandel: https://www.digitaltrends.com/cool-tech/pepper-robot-sells-smartphones-news/
[2] Demographischer Wandel in Deutschland: https://www.destatis.de/DE/Themen/Querschnitt/Demografischer-Wandel/_inhalt.html
[3] Älter werden in Balance (BZgA): https://www.aelter-werden-in-balance.de/bewegungfuer-aeltere/aelter-werden-in-balance/
[4] David McNeill. Hand and mind : what gestures reveal about thought. Bd. Chicago. 1992, S. 416
[5] Sushmita Mitra und Tinku Acharya. “Gesture recognition: A survey“. In: IEEE Transactions on Systems, Man, and Cybernetics 37.3 (2007), S. 311–324
[6] Fereydoon Vafaei. “Taxonomy of Gestures in Human Computer Interaction“. In: Au- gust (2013), S. 65
[7] Android LruCache: https://developer.android.com/reference/android/util/LruCache
[8] Natasha Sharma. Ways to Detect and Remove the Outliers. 2018
[9] Heba Aly, Carolin Arnold, Ananth Hari, Phil Nguyen und Snehesh Shrestha. Human Gesture Recognition for Drone Control. 2017
[10] Mahmoud Elmezain. “Hand Gesture Spotting and Recognition Using HMMs and CRFs in Color Image Sequences“. In: November (2010), S. 155
[11] Inga Schlömer, Barbara Klein und Holger Roßberg. “A Robotic Shower System – Evaluation of multimodal Human- Robot Interaction for the Elderly“. In: September (2017)
[12] Microsoft. “Interface Guidelines“. In: Human interface Guidelines v1.8 (2013), S. 1–142


