
This article will elaborate a method for generating abstractive perspective dialogue summarization. Unlike regular dialogue summarization, perspective summarizations aim to outline the point of view of each participant within a dialogue. This work provides an approach to fit datasets intended for regular dialogue summarization to the task of perspective summarizations. It furthermore presents an architecture that can be a solid foundation for this task.
Introduction
For centuries humans have been living in a society where conversations are the quintessence of information exchange. In today’s age, this form of communication has been evolving for generations and has become an essential part of what defines our current society. We can therefore assume that it will keep evolving and holding its role as human society continues to grow. While dialogues between humans are a core interaction in our daily life, they not only provide information, result in new insights for all participants and outsiders, but also fulfill our social needs. Hence, conversing between people has many different traits. These traits can define how getting information across makes the experience more enjoyable, which can hold its amount of valuable information.
Although relatively young, the research in dialogue summarization has been thriving over the past few years. Some literature has followed various approaches to building automated dialogue summarizers which returned promising results. Most of them are trained on the SAMSum corpus, a dataset containing chat messenger conversations, or corpora such as the AMI business meeting corpus, which includes spoken dialogues in a particular domain such as business meetings. However, both do not reflect the general tone of humans conversing daily. The SAMSum corpus comes closer to dialogues that would be held in our daily life, but they are still chat conversation nonetheless. Past works have generally trained on dialogues that do not reflect our everyday chitchat.
In summer 2021, the DialogSum corpus was released along with its challenge. The dialogues in this dataset are spoken, and about daily topics such as holiday travels, bachelor parties, and so on. At the time of this writing, this is the closest a corpus gets to spoken daily life dialogues and provides a novel challenge for the domain of dialogue summarization. This is crucial as it strongly resembles the dialogues we hold in everyday life and thus can be used more generally. That way, we have access to a large-scale dataset on which no previous work has trained a model. Although past architectures, trained with the SAMSum corpus, have prevailed quite well in general dialogues, there has been no research in summarizing the positions of each participant.
Defining summarization
Monologue summarization
Summarizing according to Merriam Webster, is the action of reducing a given text into a concise and shorter version of it, the summary. In particular, this summary must cover the main points succinctly and should be comprehensive. There is no strict rule about what the process of summarization must look like as it often depends on the original text, its length, and its messages. Therefore summarizing can be done arbitrarily as long as it meets the properties defined above. These properties generalize the task of summarization well enough for dialogue summarization to be not coherently different from general text summarization when it comes to the final results. Merely the process of creating such a summary is inherently more challenging. Translating this task into a problem would look like the following:
S = fM(D)
where S is the output summary, fM is the function for summarizing, and D is the input document to be summarized. While S is the target to be computed and D an input variable that cannot be controlled, fM remains to be optimized and properly engineered to generate good summaries. Constructing the function fM is the research of text summarization which has shown great results with the help of Deep Learning methods.
Dialogue summarization
Many guidelines and techniques exist for summarizing text in general. The conceptual process of creating dialogue summaries remains the same as its results. Therefore a formula similar to the one we defined for monologue summarization could be used. However, based on the source dialogues, this process cannot be as easily simplified as it has been barely the case for text summarization. Using therefore fM again would not make much sense here. The summarization function needs to be specialized in summarizing dialogues.
S = fD(D)
fD denotes the function for summarizing dialogues. When keeping the core differences between monologues and dialogues in focus, it becomes evident that monologue summaries align stylistically very well with their source text as both texts follow a narrative style or an observer-style of text. This is not the case for dialogue summarizations, as conversations are transcribed with direct speeches between at least two parties, which does not align with the outcoming abstractive summarizations in terms of linguistic style. Therefore, the input D has to be processed differently from fM as the style for output S will differ a lot from D. Aside from this high-level observation, dialogues are inherently much different from normal documents or monologues as already covered. These differences make it more difficult to reuse fM but do not have a large influence on the overall concept like above mentioned textual style. Finding and optimizing a function fD has been growing as a research field over the past years.
Perspective dialogue summarization
We consider perspective dialogue summarization to be a derivative of dialogue summarization related to it. The premise is similar to dialogue summarization as it deals with the same input type. In this case, it is the output that is different. In perspective dialogue summarization, we receive more than one output, i.e., one summary for each dialogue speaker. Assume we have such function fP that accomplishes that, we can say that this problem follows this equation:
SP = fP(D)
SP = (s1, s2, …, sk)
Where SP is the collection of all generated summaries. si, where i ∈ (1, …, k), denotes a separate summarized view of the i-th person in dialogue D. D is a history of utterances from k person. In this article, we describe our approach for finding a function fP
Established dialogue summarization methods
Thanks to the strong foundation the literature on document summarization has delivered, researchers could leverage these results as a foundation for potential architecture summarizing dialogues. Hence, research in automated dialogue summarization has shown promising results over the past years. All the works we have analyzed in this thesis deliver single outputs and abstractive summaries. We have not found any research on automated dialogue summarizers delivering multiple outputs or abstractive summaries of each speaker’s view and position. Nonetheless, the existing work on dialogue summarization we have found still shows great potential. It thus can be further utilized as a starting point for our goal of achieving automated abstractive perspective dialogue summarization.
We investigated three architectures that have shown promising results for dialogue summarization and also claimed state-of-the-art performance at the time of their writing.
Controllable Abstractive Dialogue Summarization with Sketch Supervision
We refer to this literature as CODS. It generates summarization by constructing so call sketch summarizations before. The authors put lots of emphasis on controllability, as this approach allows the user to define how many sentences the model should generate for summaries. The work can be found on Github.
Coreference-Aware Dialogue Summarization
This works leveraged the information coreferences can yield. Given the sentence
Bill is going home. He just came from work.
we immediately know that the pronoun ‚He‘ refers to the person named ‚Bill‘. The authors describe these occurrences as co-references and they provide connection to previous sentences and subjects which can benefit the performance for the model. Their work can be found here.
Multi-View Sequence-to-Sequence Models with Conversational Structure
Each participant in a conversation may have an intent. These intents can be detected in the utterances the participant gives. Moreover, dialogues can reach different stages where the topic but also the dynamic between the utterances can change. The authors of this work analyzed dialogues and defined different views from which the stages of each dialogue can be seen. With these multiple views, the architecture is capable of extracting more relevant information from the dialogue. You can find the published work here.
Data pre-processing
DialogSum dataset
With the growing interest and success in the research of dialogue summarization, there were already dialogue datasets. Most existing research used the AMI meeting corpus, which is considered to be small-scale, or the SAMSum dataset, which contains written dialogues. These characteristics bring relevant differences to monologues. With the motivation to provide a corpus that contains spoken dialogue with general topics for them to be closer to our daily life conversations, the authors proposed the DialogSum corpus in May 2021.
The dialogues originated from Dailydialog, MuTual, and DREAM. Dailydialog contains over 13 thousand conversations. Those dialogues were extracted from websites for practicing the English language. MuTual and DREAM are 6,000 and 9,000 transcripted spoken dialogues originating from English listening exam material. The authors complemented the dataset with additional exchanges from speaking practice websites for English learners. Given the origins of these samples, the DialogSum consists mainly of conversations about topics that are present in real life, for instance, business meetings, restaurant reservations, or banking services. However, their origins stem from different sources. Since these conversations are intended to help English learners to practice the language, they have clear communication patterns and intents while being of reasonable length.
It was necessary to clean and pre-process the data as they all have a different origin. Non-English characters were omitted, typos and grammatical errors were corrected, and, based on text similarity, duplicates were removed as well. Continuous utterances had to be merged into one longer statement for each conversation. Furthermore, definite names of the speakers were dropped and substituted with tags, i.e., #Person1# and #Person2#. Accumulating the samples and pre-processing them resulted in a corpus of 13,460 dialogues. The authors decided to split the data into a training set with 12,460, a validation set with 500, and a test set with equally many samples as the validation set.
After that, the dialogues needed to be annotated. To ensure the high quality of the annotations, criteria must be met for each annotated summary. It should:
- convey the most salient information,
- be no longer than 20% of the original conversation length,
- preserve important named entities within the conversation,
- be phrased from an observer’s perspective, and
- be phrased in formal language.
At first glance, the third object might contradict the fact that the speaker’s identities are not annotated in the dialogue. However, named entities and co-reference might occur during the speech, thus revealing the identity of a speaker. This name should be considered in the annotation and might be an essential factor in the information or semantic comprehension in the summary. If no name is mentioned in the dialogue, the previously defined tags should be used instead in the label. Annotators with degrees in English Linguistics or Applied Linguistics were hired to write the summaries for the DialogSum corpus. We also refer to the annotated summaries as gold labels. On top of the criteria, those annotators were required to give heed to a set of aspects.
Tense Consistency: The summaries should observe the conversation as if they were held in present time and thus use proper tense for events before and after the dialogue.
Discourse Relation: Summarized events can hold relevant discourse and causal relations. The summary should preserve these relations when present.
Emotions: Compared to monologues with a neutral position, such as newspaper and academic articles, social conversations are often set with emotions. Important emotions related to the events of the conversation should also be explicitly described in the gold label.
Intent Identification: The summary should describe the outcomes of the dialogue and the speakers‘ intents when identifiable.
In addition to these quality criteria, the labels underwent extra quality control. By using cross-validation between different annotators twice, the annotations were checked until they met the requirements. In case of insufficient quality, the annotators were asked to re-annotate the respective dialogue. The authors paid extra attention to the test set and let it get annotated three times by three different annotators. Then they compared these summaries by calculating pair-wise ROUGE scores. As a result, the annotators might have used different linguistic styles but still overlapped largely in the logical order and primary content. An additional jury was hired to perform a human evaluation on the DialogSum data. They were faced with 50 randomly chosen dialogues and their respective summaries from the test set and had to give a rating from one to five, with five being the highest possible score.
Acquiring perspective summary annotations
In this section, we explain how we preprocess the data for further steps in particular how we prepare the labels so that they can be used for perspective dialogue summarization.
Since the dialogues and labels are all in English, English grammar can be leveraged to split the summaries. Most sentences usually have at least a subject in combination with a verb. There can be other segments as well, such as time, adverbs, locations, or sub-sentences which, again, follow the same rule. With the help of a part of speech (POS) tagger, we were able to classify each segment of every sentence in each summary.
We used the constituency parser with ELMo embeddings as it has shown good evaluation results. It was trained on the Penn Treebank corpus, which is also a guide to understanding the POS tagger’s output. The sentences were output in a tree-like structure, with the token S, denoting the part of speech ‚Sentence‘ as a root node. This structure helps us to split the sentences accordingly. We first start by extracting the sub-sentences. Often sentences can consist of multiple other nested sentences, which we refer to as sub-sentences. It is important to note that sub-sentences appear in many different forms and might be whole sentences. The constituency parser does a decent job of detecting those, yet it is not entirely accurate. Therefore extra heuristics were necessary. To find the sub-sentences, we took every part labeled as Sentence (S) except for the root, i.e., the complete sentence itself.
Additionally, we looked for Coordinating Conjunctions (CC) as their primary function is to connect two sentences. The POS that appears after the conjunction will be considered a sentence. This approach results in sub-sentences that seem to be evident as such. However, there are other indications of sub-sentences except for conjunctions. Due to some inconsistencies in the results of the constituency parser, it is still possible for some of the extracted sentences, to begin with ‚and‘ which is relatively uncommon in English speeches. We wanted the sentences to be independent as necessary and therefore omit ‚and‘ as a part of the sentence. Splitting these sentences results in a more extensive set of sentences that all follow the same rules of English grammar to be a complete sentence. We use these extracted sentences for further processing.
Grammatically, it is possible for subordinate clauses to be standalone sentences. Therefore we extract certain subordinate clauses from each subsentence we have got at this point. The POS parser is capable of detecting subordinate clauses and tags them with ‚SBAR‘. For clauses, it is also necessary to only extract all segments that make it possible for the clauses to be able to stand as single sentences. For example, the sentence
(S I can’t believe (SBAR that John went without me.))
contains the tags S and SBAR. It is evident that the whole sentence can be without a doubt classified with S. The segment covering the fact, that John went without the speaker is a subordinate clause that starts with ‚that‘. Extracting the clause as it is would result in
that John went without me.
which is not a sentence that can stand alone. Removing the relative pronoun would make it a real sentence and does not affect the meaning, even if it was still connected with the original sentence:
John went without me.
(S I can’t believe (SBAR John went without me.))
It was therefore necessary to define a set of what we call dependent prepositions. These prepositions are conjunctions such as the one in the previous example ‚that‘ which functioned as a relative pronoun. The dependent prepositions cannot be removed from the clause, unlike in the previous example, as this would alter the meaning of the clause. Moreover, these prepositions often refer to another segment of the same sentence which is also reflected in their meaning. We created a set of dependent prepositions based on the explored data:
if, though, before, although, beside, besides, despite, during, unless, until, via, upon, unlike, like, with, within, without, because
We are aware that there could be many more words that would fall in this category, however, this set should be large enough to cover most of the subordinal clauses and diving deeper into this problem is out of the scope of this thesis.
By now, all subordinate clauses that have been detected by the constituency parser have been gathered. However, there are still other cases where one could find such a clause. In general, every sentence has at least a subject combined with a verb. Therefore, it would suffice to find segments that fulfill this criterion. Subjects are usually referred to as either nouns (NN, NP, NNP) or personal pronouns (PP). Thus, we can easily detect potential clauses by finding children in the constituency tree that are either a noun or a pronoun. Those are the starting segments of the clause. Consider the following extract of a tagged summary:
(S
(NP (NNP Doctor) (NNP Hawkins))
(VP
(VP
(VBZ advises)
(NP (PRP him))
(S
(VP
(TO to)
(VP (VB have) (NP (CD one)) (NP (DT every) (NN year))))))
(. .)
…
The segment Doctor Hawkins is the subject labeled NP and marks the beginning of the candidate clause. After that, it is still necessary to determine how many subsequent segments need to be added to the potential clause. Whenever another conjunction like and or another clause gets classified as SBAR, one can consider that until this point, the clause in question can be used in a sentence and added to the previously extracted sentences. Analogously, when the next tagged segment right from the candidate clause is not labeled with SBAR it is not a new subordinate clause. This is also the case whenever adverbs (ADVP), adjectives (JJ, JJR, JJS), verbs (VP, VBP), and other pronouns are the next right segment as they were usually a grammatical object when the subject was found in a previous part.
In the extract above, we already detected a subject, Doctor Hawkins. Thus, the clause starts with „Doctor Hawkins …“. Sentences are read from left to right in the English language, and we can therefore flatten the constituency tree as follows:
(NP (NNP Doctor) (NNP Hawkins)) (VP (VP (VBZ advises) (NP (PRP him)) …
It is now evident that the next segment is not labeled with SBAR or S but with VP. That means the next segments are not a new clause and therefore belong to the previous segment, i.e., it is part of the clause we have built so far for this example. Therefore we concatenate the segment to our current clause:
Doctor Hawkins advises him to have one every year.
Consider another tagged extract of a summary:
(NP ($ #) (NN Person1) (NNS #))
(VP (VBZ ’s) (ADJP (JJ angry)))
(SBAR
(IN because)
(S
(NP ($ #) (NNP Person2) (NN #))
…
In this example, at the highest level of the parsed tree, we have got the labels NP, VP, SBAR. By following our approach, we get the subordinate clause
#Person1#’s angry.
The subsequent segments that appear after the one labeled VP are processed independently as separate clauses because the next segment is labeled SBAR.
These clauses are standalone sentences that will be used as summaries for every person after further data cleaning, preprocessing, and assignment.
Cleaning and correcting the labels
As mentioned earlier, the constituency parser does not work completely accurately and we also consider that our approach for splitting the labels has its flaws. During the process of creating the new annotations, we found several cases where we had to simply hardcode the proper summaries. There were cases where the sentence was cut off or not properly structured. It was also necessary to remove the whitespaces which were inserted by the POS tagger, as suffixes such as ‚ll or ’s or special characters like hyphens (-) or dots (.) were also classified separately. For the suffixes, we simply removed the whitespace in front of them. In the case of hyphens, whitespaces before and after them had to be omitted. Dots were completely erased as they are also often part of titles such as Dr or Ms, denote the end of a sentence, or act as the decimal point in numbers like in the following example:
She has a GPA 3.92.
For this particular sentence, our approach even split it into two separate sentences. This was caused by the POS model constructing the constituency tree as the following one:
(S she has a GPA 3. (S 92.))
This was one sample where we had to manually correct it to a proper summary, too. These dots can cause problems when getting treated like the regular end of sentence tokens since for those, it would make sense to keep whitespace after the dot, but not for decimal numbers. We manually inserted them at the end of each sentence again. There were also cases where single dots were classified as a sentence. We removed these entries from our annotation set thus resulting in a set of summaries that were split into single, shorter sentences.
Assigning the labels to the corresponding speaker
With the subordinate clauses extracted as independent sentences, the next step was to assign them to \textit{Person1} and \textit{Person2} accordingly.
As mentioned in the section for acquiring the labels, our sentences always contain a subject. These subjects can be either
- „#Person1#“ or „#Person2#“,
- a name,
- or a personal pronoun
In the former two cases, it is trivial how to assign the sentence properly. Personal pronouns are used as a coreference and there imply a reference to the previous sentence. Since the sentences are in chronological order, i.e., the order when they appear has not been altered in the previous process, we assign sentences with a pronoun to the person the previous sentence has been assigned to. Assigning sentences where the grammatical subject is a name is more complicated than in the earlier two cases.
Before assigning all extracted clauses to the speakers, we used a Named Entitiy Recognition (NER) model based on ELMo embeddings. We discovered that in our samples the token Person caused the model to output ambiguous, inconsistent classifications. Additionally, there are issues with occurrences of # as well. Therefore, before performing named entity recognition, it was necessary to substitute all occurrences of #Person1# and #Person2# to XYZ1 and XYZ2 respectively as this will guarantee that the NER model will not recognize these entities as Persons or Organization, i.e., label them with O. Afterwards, we executed NER on all sentences and converted all names that were found to only lower case characters and kept them in a set. Then we added xyz1 and xzy2 to the set as well. This set of all occurring names will be crucial for assigning the labels. Since all occurrences of #Person1# and #Person2# have been changed, we need to assign sentences with XYZ1 and XYZ2 to the speakers accordingly. It is quite common that names are mentioned in spoken conversations. We generalize the intention of this into three cases:
- Introducing oneself
- Directly speaking to a person, for example: Hey Daniel! Can you help me?
- Talking about another party that is not part of the dialogue, for instance: Have you seen Sara’s dog?
If a speaker introduces themselves, the most used clauses are
„I am“, „I’m“, „name is“, „name’s“
Finding the name in the summary sentence in combination with one of these clauses automatically assigns the summary sentence to the speaker who said the clause. If, however, the name is mentioned in an utterance without an introductory clause, then that means that the speaker does not introduce themselves and the sentence gets therefore assigned to the other person. This is a rather generalized approach to solving this problem as there are some exceptional cases. For example,
Have you seen Sara’s dog?
clearly does not imply any form of introduction or directly speaking to the other person. In these cases, the speaker is talking about another party that is not present in this conversation. Another challenge is that it is difficult to catch all forms of introductions. In our method, both
Her name is Jessica.
and
The name’s John.
imply that the speakers are introducing themselves although in the first example the speaker clearly introduces a third party. Introductions are often not clear in dialogues as it can be seen in the following example:
#Person1#: Who am I talking with?
#Person2#: This is Jane speaking.
Covering all forms of self-introduction is a major challenge and is out of scope for this article.
We mentioned earlier that sentences with a pronoun will be assigned to the person that the previous sentence got assigned. The main exception here are the pronouns they and their. Sentences with subjects that were referred to with these pronouns were assigned to both parties. All sentences that could not be assigned by our methods were assigned to both speakers. After all labels were assigned, we changed the tokens XYZ1 and XYZ2 back to #Person1# and #Person2#.
The previous sections covered the creation of our new DialogSum dataset which now contains summaries for each person in each dialogue. We simply add these new labels to the corresponding dialogue from which the sentences of the annotation originated. The following example gives an idea of what the labels look like:
summaries: {
„Person1“: „#Person1# thinks the rent is expensive. #Person1 disagrees.“,
„Person2“: „#Person2# lists the advantages of the house Person1 wants to rent. #Person2# suggests sharing it to decrease the total amount of the rent. #Person2# tells #Person1# it helps to save money on fares, and #Person1#’ll think about it.
}
Architecture
Multi-headed neural networks have an adequate backbone network that has learned the salient features of the input data. As the name suggests, multiple different output heads are attached at the end of this backbone. The salient information the backbone has been trained on is forwarded to each head while each head is trained on its task. The following figure shows an example from a multi-headed neural network with two heads.

Additionally, each head has its different task, either regression or classification. Thus, the neural network returns two different outputs.
We leveraged the fact that a multi-headed neural network returns two different results as this is congruent with our goal to generate two distinct summaries for a single input dialogue. Therefore, we will plug in two heads to a dialogue summarization model. However, unlike the example from the previously shown image we are not training two completely different tasks since both outputs are of the same type of task, i.e., both outputs are abstractive summaries. We aimed for heads specifically trained on one single speaker and therefore only generated a summary for a single speaker. We modified the encoder of our baseline architecture by adding two additional heads. These two heads then lead back to one common decoder that generates the summaries for each speaker. From the point where the encoder splits into two heads, we passed each encoding separately to the decoder and used our annotations for each person for calculating the loss respectively.
Multi-head encoder
As mentioned above, we only modified the encoder in order to use further encode the learned features within the context of the annotated summary of a single person. The following figure displays the architecture we have described.
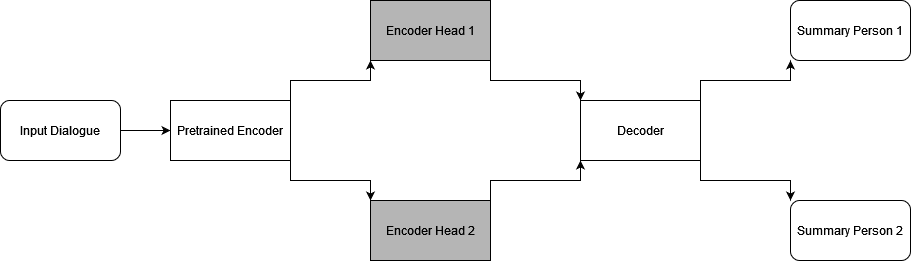
Each copy is a hard copy of the very last encoder layer and, therefore, initialized with identical weights. We used the BART encoder that was trained in the works of CODS as the backbone for our encoder. Since both additional encoder heads are copied from the last layer of the backbone, they also share the same internal architecture as BART Layers, as shown here

Furthermore, the encoding process can be then formulated as
H = EBART({x0, x1, …, xn})
Hk = Ek(H), k ∈ (1, 2)
where EBART describes the BART encoding of n tokens xi and Ek denotes the additional encoding process for the k-th head respectively as shown in the figure above. We only applied the idea of multi-headed neural networks in the encoder as we aimed to increase parameters as little as possible. We also do not want the model to learn anything different for the summary generation part as the style of outputs for regular dialogue summarization, and each summary of a single person should be similar. Thus, we left the decoder part as it is. Again, we used a BART decoder for fine-tuning from the works CODS which has been trained on the SAMSum datasets. The following equation completes the encoder-decoder process of our approach:
Yk = DBART(Hk)
Yk = (y0,k, …, ym,k), k ∈ (1, 2)
Ykis the sequence of tokens yi,k for person k acquired from the decoder DBART. The decoder processed the encodings Hk from each of the k heads separately. In our environment, H1 and H2 as well as Y1 and Y2 were not computed concurrently but sequentially.
Training
Loss function
Since we have two different outputs for the DialogSum dataset, conventional training and computation of the loss are not possible. The significant difference is that we receive two results from the neural network and have two labels for computing the loss. It is important to incorporate both outputs in the training process and to ensure that the outputs and the weights of both new encoder heads, given that the weight initialization is equal for all components, also differ from each other.
During training, we calculated the loss for each single encoder output and then used the maximum of both to punish the model for the worse performing head and thus making the learning process more challenging. We chose the Cross-Entropy loss function and obtained the following equations for the loss:
CE(Y, Ȳ) = –∑yi ·log ȳi
Lk = CE(Yk, Ȳk}), k ∈ (1, 2)
LE = max(L1, L2)
where CE(Y, Ȳ) is the Cross-Entropy loss function, Lk denotes the loss that the k-th encoder head causes. Note that Lk includes the output from the decoder instead of only the encoder head. We then acquire the loss LE as described above with the label Ȳk for person k. We compared the similarity between the encoded outputs and multiplied them with a penalizing parameter γ, which acts as a weight for considering the similarity in the loss function. We sum the product with LE to penalize the learning process accordingly if the outputs are too similar.
S = mean(SIM(H1, H2))
L = LE + γS
SIM is the similarity function from which we additionally calculate the mean for the score S to be a scalar still representative of similarity. For SIM we chose cosine similarity. This computes the total loss L from which it is now possible to acquire the training gradients.
Setup
For training, we used the weights from the pre-trained CODS architecture. We left most of the parameters to the default, which its authors have set; for instance, we used learning rate 5e-5. We trained the model with AdamW and set our penalizing parameter γ to 0.8. Early stopping was implemented, yet, we set the patience parameter to a higher number since the task itself is somewhat more abstract. We wanted to observe the learning behavior, particularly the behavior of the validation metrics, in a longer training process. Therefore, we set patience to 100 and trained the model for 107 epochs in total where we also saved the checkpoints. For validation, we used the ROUGE-1 F1-score to measure the model’s performance on the validation set over time. We utilized the similarity score as an additional parameter since, especially at the beginning, the pre-trained model tends to generate general dialogue summarizations for each person, resulting in two identical outputs for each person.
Results
We trained the architecture as described in the section above on our version of the DialogSum dataset. We kept track of the loss, validation metrics, and similarity scores during training. The model consistently minimized loss on both training and validation sets, resulting in converging loss curves that were approximating 0. However, the validation and similarity curves fluctuated as shown in the figure below.

It shows that the F1-score is not only fluctuating but also monotonically decreasing. This made it difficult to use conventional early stopping, which is why we looked for the optimal checkpoint in terms of F1 score and similarity. The similarity curve shows a behavior similar to the curve of the F1 score. In the early epochs, the validation metrics were relatively high, reaching an F1 score up to approximately 0.34. In contrast, the similarity was also very high, indicating that at this point, the summaries for Person1 and Person2 would be identical. After that, the similarity score and F1 score were constantly going down. Between epochs 40 and 60, the similarity of the outputs decreases even faster, and the F1-score is slightly increasing. We then chose the checkpoint that reached the highest F1 score and the checkpoint with the lowest similarity score, epoch 50. These three checkpoints were then tested on the test set of DialogSum. The following paragraphs show the generated summaries samples from each checkpoint.
Highest F1-Score (2 Epochs):
Person1: #Person2# cannot stand the noise in her room. She was woken up several times by the noise the baggage elevator made. They do not have any spare rooms today, but there will be some tomorrow.
Person2: #Person2# cannot stand the noise in her room. She was woken up several times by the noise the baggage elevator made. They do not have any spare rooms today, but there will be some tomorrow.
50 Epochs:
Person1: #Person1# will change #Person2#’s room for her as it is too noisy. #Person2# will wait till tomorrow as a tour company will be leaving tomorrow morning.
Person2: #Person2# cannot stand anymore the room for her because it is too noisy. #Person1# cannot change the room for her because a tour company will be leaving tomorrow morning. #Person2# will wait till tomorrow
Lowest similarity score (106 Epochs):
Person1: 0 what can i do for you 1 none 2 none 3 none 4 none 5 none 6 none 7 none 8 none 9 none 10 none
Person2: 0 none 1 none 2 none 3 none 4 none 5 none 6 none 7 none 8 none 9 none 10 none
The checkpoint reaching the highest F1 score has been trained for two epochs. Although it got a decent F1 score for ROUGE-1 it produced summaries for both persons, which were identical. This is also reflected in its similarity score. Its similarity score is close to 1, and in the produced summaries one can see that the generated summaries might be good candidates for a regular dialogue summarization but are not distinguishable from each other. The former aspect can be explained with the CODS backbone, which was trained for dialogue summarization.
The model trained for 50 epochs seems to be the most promising model for perspective dialogue summarization. Although not accurate, the summaries from Person1 and Person2 are different from each other, and they do seem like a usable summary. The summary sentence for Person1
#Person1# will change #Person2#’s room for her as it is too noisy.
and the summary sentence for Person2
#Person2# cannot stand any more the room for her because it is too noisy.
both represent the perspective or situation of each person, respectively. The next sentence for person1
#Person2# will wait till tomorrow as a tour company will be leaving tomorrow morning.
and the one for Person2
#Person1# can’t change the room for her because a tour company will be leaving tomorrow morning
take the position of the other speaker again. However, the last summary sentence of Person2 reflects that person’s position again. On a semantic level, the summaries for both persons do contain the dialogue’s content. There are some minor flaws in the generated output, such as „cannot stand any more the room for her“ which is not grammatically correct. The clause „cannot stand any more“ was existent in the dialogue, and having it next to „the room“ did preserve the original meaning. Note that this example happens to be a more ideal case where our model’s performance was not too bad. Given that the similarity score is still high (higher than 0.8), the generated summaries for each person in many other dialogue samples still tend to be identical or nearly identical. In most outputs, the perspective of the other speaker is also summarized.
The model with the lowest similarity score clearly generated the worst outputs. Since the backbone is based on CODS, the model overfit after training for 106 epochs and produced only the keyphrases and summary sketches, which are used in the underlying architecture.
The model that trained for 50 epochs came the closest to perspective summarization in our experiments. It reached an F1-Score of 0.2294 and a similarity score of 0.89 on the test set of our version of the DialogSum dataset. Nonetheless, during training, the loss converged towards 0. We assume that the architecture tried to learn embeddings that lie between the targets for Person1 and Person2, thus reducing the loss but increasing the F1 score. Individual results of this model, such as the one above, show that using a multi-head encoder attached to a single decoder might be a good foundation for perspective dialogue summarization. In our experiments, the results were not convincing enough to use our architecture for an accurate automated system for summarizing each speaker’s perspective. It instead provides a direction in which future work could achieve this. Many factors might have influenced the outcome of our work and approach. Solving them could provide great potential for our architecture to eventually generate precise and accurate summarizations for each person in a conversation that are distinctive from each other.
Discussion and future work
Challenges
No research exists for perspective dialogue summarization. This made it difficult to develop a viable architecture and required us to outline an approach from scratch. We stated that perspective dialogue summarization and regular dialogue summarization are related to each other. However, the equations we have defined are different from each other. Note that these equations are each very abstract definitions of each task. Due to the difference between these two equations, it is necessary to find a function fP, which is inherently different from function fD. This conceptual difference implies that the neural architecture for perspective dialogue summarization must differ from the one for regular dialogue summarization. Therefore, we had to accumulate the characteristics of such an architecture, for example, having multiple outputs, processing an input dialogue for summarization, or being a generative text model. We combined different concepts for each characteristic into one sequence-to-sequence architecture that generates distinct summaries for each person. Since this work is one of the first in perspective dialogue summarization, the combination of multi-headed neural networks in sequence-to-sequence architectures containing an encoder-decoder structure is a novelty we have not discovered in our literature research. Therefore, we could not define clear expectations regarding the performance of our model. We showed that overall the performance of our trained model is meager and between its ROUGE-1 F1 scores and the ones from previous work is a clear gap. Nonetheless, some predicted samples have shown potential, promising better results if further improvements are made.
Many possible factors might influence the performance of our approach. We assume that a multi-headed encoder is a decent starting point to building better architectures for generating summaries for each person. One reason why the performance of our model was not high could be that the architecture has not been able to distinguish between Person1 and Person2. Although both heads share the same common input dialogue, extracting the features for distinguishing between each speaker is still necessary. If this is not the case, the model might still try to summarize for all participants. The predictions from our best model have shown that some sentences which should be designated for the other speaker i are nevertheless part of the summary for speaker j, where i≠j.
One possible solution would build the architecture around additionally differentiating between the persons. This could be done in various ways, such as splitting the dialogue into k sets for k speakers where each set Ui contains the utterances for speaker i and then passing these sets to the architecture. That would require the architecture to accept multiple inputs and to recover the dynamic conversational information flow, i.e., utterance ui,t of person i at position index t relies on the information of a previous utterance uj,v of person j at position index v, where i≠j and t > v. Another idea is to add more encoding layers for each head to increase the complexity and therefore learn the necessary features to focus on the salient information important for one speaker. Inserting more encoding layers is not the only way to increase the model complexity. However, it is always important to keep in mind higher complexity comes with more parameters and a higher risk of overfitting. Another major problem in our model is the high similarity between the generated outputs. By incorporating the similarity score of the hidden states in training in a more sophisticated way, the model might produce more distinct summaries for each dialogue.
The high similarity could also be related to the training data our model trained on. It is essential to mention that the lack of research in perspective dialogue summarization also comes with a limited selection of datasets. There were no corpora that contained the necessary annotations at all for this specific task. We had to create our solution for automatically creating perspective summary annotations, which required us to dive deeper into the linguistic level. This area of our work likely left some improvements to be desired. Sentences can follow a nested and very complex structure, making it quite challenging to come up with all necessary heuristics that can precisely split all annotations and assign them correctly to each person. For instance, our set of dependent prepositions will not cover all sentence conjunctions that either make one clause dependent on the other or connect two stand-alone sentences. Another example is utterances that introduce a person, which can be very ambiguous. There, the person might be either introducing themselves or another third party not necessarily partaking in the conversation. We also relied on machine learning models, which were able to tag the part of speeches of each original annotation. Although they have shown excellent results, they are not working perfectly. We found sentences that followed a very similar structure on which the POS tagger could not consistently make similar inferences. These loopholes in our data pre-processing step might be the leading cause for a relatively high similarity score of around 0.778 which makes it difficult for our model to produce very distinctive summaries for each speaker. The gold labels we created are based on the references from DialogSum. Therefore, the quality of our gold labels is not as high as that of the DialogSum labels because the creation and evaluation process were not as polished. In addition, the annotations of DialogSum were written to summarize the whole dialogue. The semantic traits of this intention could still be found in our labels, which might also affect the quality of the model-generated summaries.
On a high level, improvements can be made in the architecture and data creation process. However, in each of them, multiple areas can be improved and turn out to be relatively tricky. Resolving all problem areas can lead to better results but would go beyond the scope of this thesis. We want to encourage future work for automated perspective summarization by listing these problem areas.
Future work
As we developed our methods, we identified problem areas and thus clarified the requirements for this task. Future work on perspective dialogue summarization can address these areas and needs to surpass the performance our model reached.
Improving the architecture: This does not necessarily mean increasing the model complexity. Since our architecture builds on the CODS model, which already has shown success and therefore has its degree of complexity, the depth of our architecture can consequently be considered deep. A high degree of complexity usually raises the number of parameters which slows down the training and requires more memory. Then again, as explained earlier, adding more encoding layers could help the model distinguish every speaker and produce better summaries. In addition, multi-headed neural networks do not have to be the only solution for this task. There are many different architectural styles for designing a neural network. Therefore, it is necessary to identify the crucial requirements where we think that the distinction between each speaker is one of them.
Extending the data creation: This addresses the problem of high similarity between the labels we have created. The low degree of variance between the made references is very likely to be linked to the negative correlation of F1 and dissimilarity measurements in our model’s performance, i.e., the higher the F1 score, the more similar the generated summary pairs. Our heuristics and approach only scratched the surface of this problem area, potentially posing a whole work on its own. When splitting the labels for perspective summaries, many linguistic and semantic features need to be considered. Extending and enhancing the proposed creation process would lead to fewer default steps, where a summary sentence is 1) well split and 2) assigned correctly to one person instead of being assigned to all persons.
Creating new data and annotations: Last but not least, we suggest that more data is always a beneficial resource for any deep learning task. Currently, there are no datasets available specifically for perspective dialogue summarization. While splitting the labels of regular summaries and assigning them to each speaker respectively, the semantic context is nonetheless different from summaries that are intended for a specific task. The labels of DialogSum are written in an observer style. However, this ‚observer‘ is to observe all parties in dialogue, so that the sentences are formed accordingly. These semantic and syntactic features will remain, even if the data pre-processing went smoothly, and still can influence the training process. Therefore, a dataset designated for this task with the same degree of quality assessment opens new promising paths for developing automated perspective dialogue summarizers.
We are aware that there could be many more factors that affect the performance of our model. During this thesis’s creation, the aspects we just mentioned were the most prevalent we faced. Thus, we strongly emphasize those due to the fact that we experienced most obstacles caused by them.
Conclusion
Our contribution is an approach to building a neural network capable of generating summaries for each speaker in a dialogue, a method for creating reference summaries for perspective dialogue summarization, and an augmented set of reference labels for the DialogSum corpus. These labels contain summaries for each speaker gained from the original reference summary and can be used for training. Furthermore, this task of per-person dialogue summarization is new and has no literature record. With this work, we further refined the requirements and problem areas that frequently occur when building such a neural network.


