
Transformer-based language models trained on massive datasets, such as Google’s BERT, have undeniably pushed the frontier of natural language processing (NLP) in recent years. Due to the heterogeneous nature of the training data, the models improve when shown supplementary knowledge during pretraining.
Pretraining algorithms often call for large datasets – the bigger the better. But what if only a limited amount of data is available for pretraining? Is it beneficial to focus on quality instead of quantity? In this article, we investigate whether it is possible to invest in small, high-quality datasets for pretraining language models instead of relying on large, more general corpora.
What is Domain Adaptation?
Humans are pretty good at using knowledge from previously learned tasks when learning new tasks. This is generally referred to as positive transfer. For instance, learning to drive a car could facilitate learning to drive a truck.
It would be nice if machine learning models could do the same. Traditionally, if we wanted to train models for different tasks, we would train each model separately (see Figure 1). This is where transfer learning comes into play. Instead of starting from scratch in every task, the goal of transfer learning is to transfer knowledge from previous tasks to a target task (see Figure 2).
Training a decent model requires an immense amount of data which we often source from publicly available datasets. The type of data published for anyone to use tends to be what is considered „standard“ or canonical – mostly Wikipedia and news articles. Due to the homogeneity of these texts, they are often a poor match to other domains. Studies show that models perform substantially better when shown (additional) domain-specific text during (pre-) training. The task of adapting models from a training distribution to a different target distribution is generally referred to as domain adaptation.

In domain adaptation, we deal with the scenario where we have a source domain and a target domain, which are different in some way, e.g. the source domain is reviews of computers and the target domain is movie reviews. More precisely, source and target domain have different marginal probability distributions. The goal of domain adaptation is to learn representations specifically for the target domain.
Since annotation of data is a costly enterprise and labeled data in the target domain is thus often scarce, most recent research focuses on studying unsupervised domain adaptation, where only unlabeled data for the target domain is assumed to be available.
Who is BERT?
BERT, or Bidirectional Encoder Representations for Transformers, is a language model that has been pretrained on a large amount of texts from Wikipedia and books. It has achieved state-of-the-art results on a wide variety of NLP tasks.
BERT makes use of transformers – an attention mechanism that learns relations between words (or sub-words) in a text. What differentiates BERT from other language models is that its transformer encoder is bidirectional, meaning that it can learn about a word based on its context from both left and right.
There are two training strategies for BERT: masked language modeling and next sentence prediction. In the former, 15% of words in each sequence that is fed to the model are replaced by a [MASK] token. The model learns by trying to predict the original value of the masked words based on the other words in the sequence. In the latter sentence prediction strategy, BERT is fed a pair of sentences and learns to predict whether the second sentence follows the first one in the original document. The cool thing about both of these strategies is that they enable the model to learn in a self-supervised manner: they are supervised in the sense that there is a gold standard against which the model can check its predictions, but no labeled data is required for this step!


In order to use BERT for classification tasks, such as sentiment analysis or topic detection, a classification layer is added. This layer can be trained in traditional machine learning fashion, i.e by feeding the model labeled data in a process called fine-tuning (see Figure 3).
To take things one step further, BERT models actually perform even better when shown additional relevant data prior to fine-tuning. Indeed, research shows that pretraining on data from the domain of a specific task improves results significantly. That is to say, BERT is not trained from scratch on different data but rather, the pretrained BERT model is pretrained again on data relevant for the task (see Figure 4). This practice is referred to as adaptive pretraining – pretraining followed by secondary stages of pretraining on additional data.
What is a Domain? How do we Measure it?
The term domain is used quite liberally in NLP literature. There is no consensus on what really constitutes a domain. The definition which is cited the most (to my knowledge) distinguishes domains based on their feature spaces and their marginal probability distributions. Not only are the boundaries between these two concepts blurry – at what point are differences in vocabulary large enough to justify the distinction of feature spaces? – they also leave questions about granularity unanswered. Is online reviews a domain, or Amazon reviews, or Amazon reviews of wireless headphones? We could continue this line of argument until each document is its own domain.
Despite the muddle of conflicting notions about the domain, there are quite a few studies attempting to measure domain similarity. It is pretty important to have some measure of domain similarity. You need similarity measures to be able to make claims about a model’s generalization and performance across domains, and they are also used directly in domain adaptation algorithms. Commonly used metrics are the Kullback-Leibler divergence and the Jensen-Shannon divergence which measure the difference between two probability distributions. For model evaluation purposes, vocabulary overlap, where you calculate the intersections between, say, the top 10k words of each domain, seems to be a popular measure.
Mission: QUANTITY
For Mission: QUANTITY, we want to find a baseline for adaptively pretraining BERT across different tasks and domains. As explained above, the notion of domain is pretty fuzzy. For now, let’s go with the intuitively defined „domains“ reviews, news, social media, and scientific papers (aka domains where we can find lots of publicly available datasets). Here is a list of the datasets and tasks:
Reviews
- E-Commerce (sentiment analysis)
- IMDB (sentiment analysis)
- Amazon (sentiment analysis and topic detection)
News
- AGNews (topic detection)
- BBC (topic detection)
- 20Newsgroups (topic detection)
Social media
- Sentiment140 (sentiment analysis)
- Tweet Eval (sentiment analysis)
- Emotion (sentiment analysis)
- HateXplain (hate speech detection)
- Ethos (hate speech detection)
Scientific papers
- PubMed (abstract analysis)
- Web of Science (topic detection)
First, we only fine-tune BERT on each dataset without any additional pretraining. To speed up training time, we use DistilBERT, which is smaller and faster than BERT but was pretrained on the same corpus (Wikipedia and BookCorpus). Table 1 shows the results.

As you can see, the model did pretty well on the IMDB and Amazon datasets, as well as the AGNews and PubMed ones. It struggled with many of the social media datasets. I wondered whether performance was in some way related to domain similarity between BERT’s original training domain (Wikipedia and BookCorpus) and the task’s domain. Testing different similarity measures like vocabulary overlap, I unfortunately could not find a correlation. As explained above, there is no real consensus on what constitutes a domain and how to quantify differences between domains. We need some more studies on the topic and maybe someone else can find a correlation in the future.
Moving on, we compare the baseline results (Table 1) to results after domain-adaptive pretraining (Table 2). Here, we pretrain the DistilBERT model on a large domain dataset in hopes of providing it with some useful additional knowledge. For reviews, we use the Amazon polarity dataset; for news, we use the SemEval 2019 news dataset; for social media, we use a Twitter scrape and a collection of Reddit comments; and for the science domain, we use an ArXiv dataset. All datasets are the same size (200 million tokens), so the we can compare results fairly.

Looking at the results, we can see that domain-adaptive pretraining does indeed improve performance across most datasets. There is some negative transfer for the BBC dataset, implying that it is not within the domain of the news articles we chose for pretraining.
Mission: QUALITY
Let’s get to the juicy part: Mission: QUALITY. Can we do adaptive pretraining using small, high-quality datasets?
In order to generate „high-quality“ datasets – aka datasets that are more closely tied to the target task – we employ a data selection algorithm. For each target task we:
- Generate embeddings for each document in the task dataset, as well as the documents in the corresponding domain dataset,
- Select candidates using Nearest Neighbors with cosine similarity as the matric, resulting in a task-specific dataset and
- Pretrain BERT on task-specific dataset.
For instance, when generating a high-quality dataset for IMDB, we take our domain dataset (Amazon polarity) and select candidates based on each IMDB movie review. The resulting task-specific dataset contained lots of reviews of movies, books and music (it ended up choosing around 50k reviews). Reviews of beauty products or gardening tools are irrelevant, so they did not end up in the task-specific dataset.

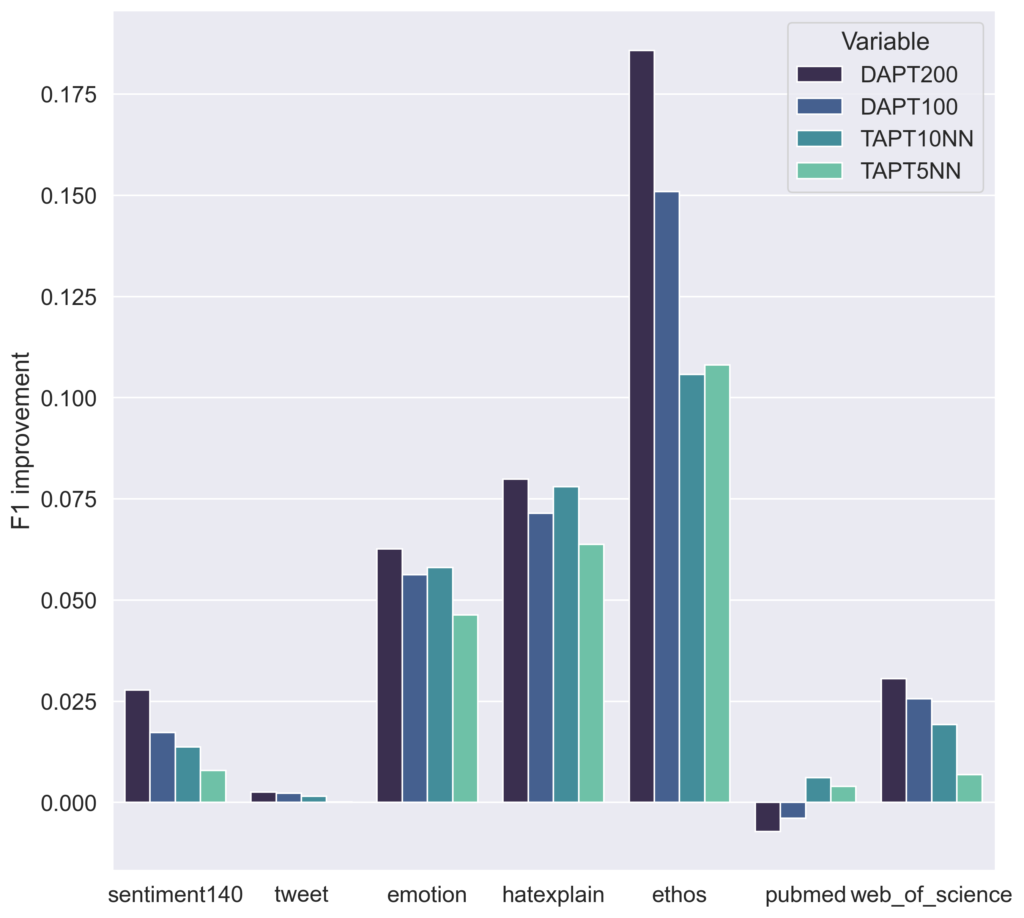
Looking at Figure 5 and 6, which compare how much the model’s performance improved after pretraining, we can see that even though task-adaptive pretraining uses much smaller datasets, the model still gets a nice performance boost! In those cases where we had negative transfer from domain-adaptive pretraining (see BBC), selecting „high-quality“ relevant candidates actually remedied the issue and resulted in positive transfer.
Conclusion and Takeaways: Pretraining Language Models
We saw that language models trained on massive, heterogeneous datasets can be adapted to a task’s domain to improve performance. Usually this type of domain adaptation asks for large datasets but we learned that it works (almost) equally well with small, high-quality datasets. You can extract task-specific datasets from large, more general ones with data selection algorithms (check out Data Selection Strategies for Multi-Domain Sentiment Analysis for more information).
A takeaway from this is that if you find yourself in a situation where you need to generate a new dataset, you might want to try focusing on quality instead of quantity! This idea goes hand in hand with a new line of thinking that is becoming more popular in machine learning: choosing a data-centric view over a model-centric one. When faced with a machine learning problem, a data-centric approach would be focusing on data quality to improve your model’s performance, while the more traditional model-centric approach is to try different state-of-the-art architectures or to optimize hyperparameters. If you are interested in learning more about data-centric AI, check out Andrew Ng’s talk on Youtube.


