
Notice:
This post is older than 5 years – the content might be outdated.
In the first part of our series we elaborated on the common use of Web Components and web frameworks taking Angular and Polymer as examples. We ended the article with the statement that both suffer from essential compatibility issues which aren’t fixed so far. So now we will illustrate solutions for these problems and thus enable applications with Angular and Polymer running side by side.
What do we know so far and which restrictions do we have?
If we take a look back at the first part, the majority of problems rests upon the fact that Angular doesn’t integrate Polymer elements in its internal processes. There’s no logic for Polymer elements within the application logic of Angular. Because of this, we will follow the strategy of upgrading the needed functionalities within Angular.
However, there are restrictions which complicate our plans. As we know from the first part, Angular uses an individual rendering architecture and pre-compiles it’s application code before the page renders. Because of this and to maintain the patterns of Angular, we have to add the logic before the compilation processes.
Also, each Polymer element has its individual functionality and needs to be treated separately, so we can listen to change events dispatched by each element. Whenever these events occur, we possibly have to check for differences in Angular and update the application. But since the events are named after the property’s name (f. e. “value-changed“ for the property “value“) and each element provides different properties, they can’t be treated generically.
Which way do we follow?
With the above restrictions in mind, the most efficient way seems to be the usage of directives. They can refer to a single DOM element and fulfill the conditions such as the registration of event listeners or the binding of properties. They also come up with the huge benefit that we don’t have to manipulate internal mechanisms like the change detection. Since directives are linked up with them, we can implement the features out-of-the-box.
The existing approach
Based on the directive based approach, there is a project called angular-polymer. In the following figure you can see its basic functionality (in April, 2017):
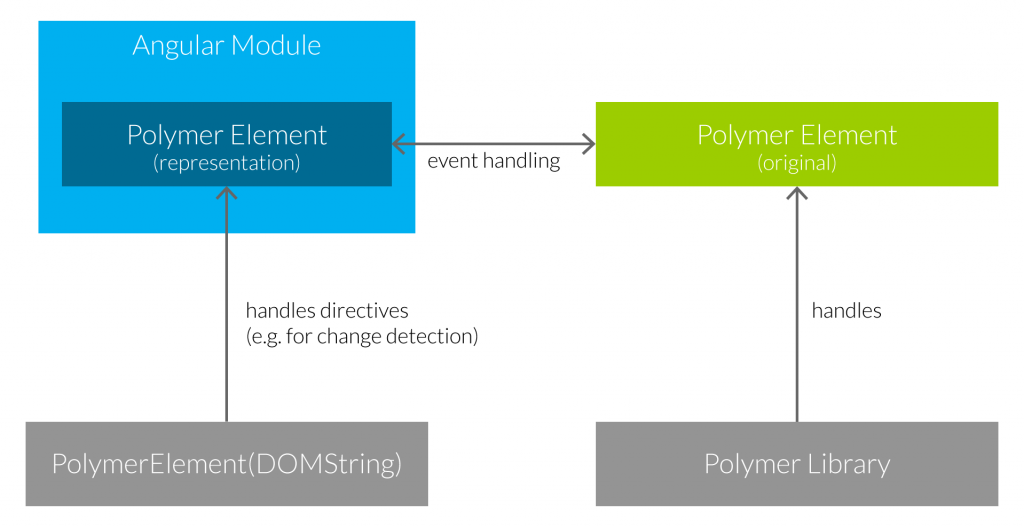
A global function “PolymerElement“ creates a representation for an element named after the passed DOMString (e. g. “paper-input“). The function internally generates several directives which provide needed functionalities and returns them finally. If we call the function in the declarations of an Angular module’s decorator, the dynamically generated directives will be integrated into the application. They are responsible for the synchronisation between the Polymer element and its representation in Angular. For more details, again see the Github repo.
However, using this function causes new problems:
- The function has to be called for each element separately. This results in redundant source code and can cause inconsistencies if we forget the function call for an element.
- The approach creates dynamic directives just-in-time before the Angular application renders. Since the function internally uses DOM operations, this results in a negative performance impact.
- The application can’t be compiled ahead-of-time since Angular prohibits calls of dynamic functions within decorators. Because of this, the solution isn’t compatible to angular-cli after version 2.2.
To summarize the studies: even though the directives themselves work fine, the usage of the approach within practical projects seems to be complicated. Therefore, we will try to optimize the approach.
Optimization strategies
We follow two strategies to optimize the above approach. First of all, the configuration overhead can be reduced if elements were integrated generically. Therefore, we read an element registry provided by Polymer: this registry contains the elements registered in the application’s document (global “Polymer.telemetry“ object). This approach seems to work in practice, since a plugin of Aurelia uses it to integrate Polymer elements.
The second approach is a static compilation of the dynamically generated directives. For this, we translate the directives to static templates and use a generator. The generator creates static directives from the templates and dynamic data retrieved from Polymer’s element registry. Now, the generated directives are available at development time and thus they can be included in the Angular processes natively. Since we don’t create directives at runtime anymore, the generator has a positive impact on performance, too. Last but not least, the ahead-of-time compilation works again.
The solution
Since we want to integrate Polymer elements generically, we have to register them in a DOM and query the Polymer element registry. However, we run the generator at development time server-side and thus we can’t access a DOM out-of-the-box. So we use a headless web browser to register Polymer elements and query the element registry. At this point, it makes perfect sense to choose a browser which uses Blink as rendering engine. They implement the Web Component specifications natively and thus prevent us from problems caused by Polyfills. For this reason, we choose NightmareJS. Additionally, we require a simple web server since the same-origin policy restricts HTML imports even on local files. We use Express for that purpose.
Finally, we need the generator itself. The web browser (Nightmare) and server (Express) are part of a Yeoman generator. The architecture of Yeoman, amongst others, allows us to use system operations. Also, we can start the generator via the command line as well as programmatically. The resulting architecture is described in the following figure:

The generator calls a webpage located on the Express server, reads the element registry within a browser context and returns the needed data to the generator. Afterwards, the dynamic data and the templates are combined to statically generated directives. These directives can be included in the application.
The full implementation of this solution can be found on Github. Also see the example project.
The generator’s cons
As you can imagine, using the generator implicates additional effort. For instance, we can’t use the index file of our Angular application as the main document of the generator. In fact, we have to use a separate file to avoid errors trigged by external dependencies (e.g. the Angular application itself). Because of this, we use the Yeoman configuration file to define which elements the directives should be created for.
In order to minimize this effort, there are some strategies to integrate the generator in your development process and to reduce the configuration overhead.
Conclusion
The code generator gives us the opportunity to use Polymer and Angular side by side. Even though the generator’s functionalities aren’t stable against updates to Polymer or Angular, they can easily be modified to prevent breaking changes or even for other frameworks. Additionally, new functions and exceptions can easily be added to the generator in the future.
However, there is an overhead of setting up the generator. It bundles a browser and a server and has to be included in the development process, too. This raises the question whether it’s worth the effort or not. In my humble opinion the synchronisation in small projects with simple Polymer elements can still be done manually. But if the project grows in complexity the generator could help to avoid inconsistencies and reduce redundancy.
Finally, let’s bridge the gap to the first part of this series: We found a way to use web frameworks with Web Components side by side in practice. However, the generator creates directives that aren’t complicated and already fit well to the architecture of Angular. Because of this, I look into the future with confidence that Angular or other frameworks upgrade their architecture for native Polymer or Web Components support.


