
Notice:
This post is older than 5 years – the content might be outdated.
The visions created by the Internet of Things, which encompass the seamless embedding of the virtual world into daily human life have become reality by now. In that context, the ongoing miniaturization of wearables, the ubiquitous availability of capable and mobile computation devices, and the fast progress within the domain of machine learning accelerated the recognition and analysis of human activity on basis of motion sensor information. Typical use cases are, e.g. controlling devices with gestures, supporting and monitoring of patients in a medical context or the tracking and estimation of physical exercises.
Related to that, the following article focuses on the analysis of human motion in sports in order to not only detect and identify different physical activities, but also to analyze them regarding their quality and correctness. Therefore, a distributed sensor system called SensX which is capable of capturing and analyzing human motion is presented. Moreover, an overview across a sequential process chain for analyzing multi-dimensional time-series with algorithms of supervised machine learning is provided. Afterwards, the application of this concept is evaluated by automatically recognizing and assessing the quality of conduction of different physical exercises. Finally the performance of two different approaches for segmenting recurrent motion events is examined.
Tracking Human Motion
In general, methods to capture human motion can be divided into two separate categories, which here are referenced as indirect and as direct capturing.
Indirect capturing is realized by tracking probands with non-contact sensors, such as cameras or depth sensors [1][2][3]. Advantages of such a setup are the holistic tracking of the human body (if more than one sensor is used), the possibility to determine exact distances and angles of extremities, and a potential for real time computation due to the scalability of computational power in a stationary sensor setup. In contrast, such a complex and stationary setup leads to a lack of mobility and is only applicable in laboratory conditions, which makes it inappropriate for a profound analysis of a variety of physical and sportive outdoor activities. This disadvantage becomes even more serious when multiple sensors must be added to avoid masking effects and to track all extremities of the human body.
In contrast to that, direct capturing is conducted by using wearable sensors, which are directly placed on the body of a proband for motion tracking. Examples for this approach are xsens, EnFlux as well as SensX, the latter of which is presented in the scope of this article [4][5][6][10]. Advantages of such body-worn sensor systems are the freedom of movement during physical activity as well as tracking body motion without masking effects. A disadvantage can be the a more coarse-grained motion capturing, as every limb which is about to be tracked needs to be monitored by an individual sensor module.
A Concept for Analyzing and Assessing Human Motion
The basis for the following remarks is the SensX sensor system [6][10]. It implements the tracking of human motion as well as its analysis and assessment in real-time within mobile scenarions by utilizing body-worn inertial sensors. Therefore, it loosely leans on ideas of an activity recognition chain as proposed by Bulling et al. [8]. The SensX concept consists of two main layers as depicted in Figure 1: The hardware layer and the software layer, which are wrapped around a process chain implementing mechanisms of supervised machine learning.

The hardware layer is responsible for organizing the 1) Tracking of raw sensor information and consists of four external sensor units and one central computation unit. The software layer encompasses all logical steps to create knowledge from raw sensor data, namely the 2) Preprocessing, the 3) Segementation, the 4) Feature-Engineering and finally the 5) Classification. Figure 2 depicts the underlying steps of the implemented activity recognition chain with all technical details, which will be referenced in the following sections.
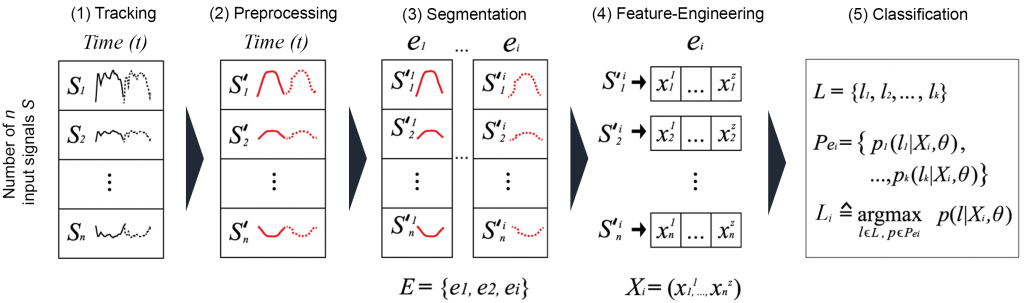
(1) Tracking
Within the SensX architecture, the tracking of human motion is completely organized in the hardware layer. Therefore, four external, wearable CPRO sensor units by mbientlab with an actual sampling rate of 40Hz and one Android smartphone functioning as a central computation and sensing unit with a sensor sampling rate of 100Hz are used [7].

The tracked sensor data encompasses acceleration and rotation information for the dimensions X, Y, and Z. This data resembles the incoming time-series depicted in Figure 2, (1) Tracking and consists of n=30 individual signals S used as input for the next step (2) Preprocessing within the proposed process chain. The potential sampling rate of the external sensor units is much higher, but due to the fact they are all communicating with the central computation unit through only one Bluetooth channel, it is necessary to split the available bandwidth for data transfer. This leads to a smaller actual data rate achieved by the external sensor units.
Figure 3 shows the SensX sensor system worn by a study participant: The four external units are applied to the body’s extremities, while the central computation unit is fastened on the chest with a flexible harness.
(2) Preprocessing
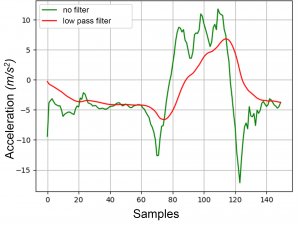
Commonly, there are various well-known issues with time-series acquired by sensors, which complicate their analysis significantly. Examples are the occurence of ambient noise, environmental influences such as dependence on temperature or moisture, or even the breakdown of sensor devices. In order to address such noise within signals or short time measurement failures as well as to simplify the shape of a signal, filters can be applied.
In step (2) Preprocessing of the process chain implemented by SensX, which is also depicted in Figure 2, the most important task to implement is the filtering of the n=30 signals S with a Butterworth low pass filter [9]. Its transfer function allows low frequencies to pass the filter, while high frequencies, such as sensor noise are reduced. Hence, depending on the order and the intensity of the filter, it is possible to smoothen the input signals. Figure 4 visualizes the smoothing of an acceleration signal by applying a Butterworth low pass filter onto it. The advantage of this procedure is the simplification and the reduction of noise within the signals. But as a disadvantage, possibly valuable information for further analysis may get lost during the filtering process. This emphasizes the need to chose the configuration parameters for the filter intensity carefully.
According to Figure 2, the outcome of step (2) Preprocessing are n smoothed signals S', which are handed over as input information to the next step (3) Segmentation.
(3) Segmentation
In general, there are several different core concepts of segmenting recurrent motion events from continuous time-series. Algorithms using static window sizes are often triggered by a signal-based threshold and offer a comparably simple solution for segmentation of individual motion events within an activity sequence. But in the current scenario, human motion events who are unsteady and whose appearance is often changing, are the subject of examination. This especially applies for the execution of physical exercises. Their duration and the exactness of their execution always relies on the skill of an athlete as well as on their current level of strength and endurance.
This leads to the assumption that a static segmentation algorithm is not sufficient to capture the actual segment borders of motion events of varying lengths, for a static window size inevitably leads to overlapping or cropping. In the following, two different segmentation approaches are presented to address these issues: One using static and another one using adaptive window sizes. Moreover, both of them will also become evaluated and compared below.
But before applying one of the segmentation algorithms to the incoming n signals S', the most meaningful signal SMMS becomes identified by calculating the standard deviation σ for each of them. One reason for this is that segmenting each of the n signals sequentially is creating much more computation load than segmenting only the SMMS to identify the borders of an encompassed motion event. After identifying a segment’s start time tstart and end time tend in SMMS, all corresponding segments of a motion event can be cut out of the remaining n signals according to these timestamps. The other reason is that not all captured signals describing an activity sequence are suitable for segmentation, i.e., due to the absence of significant motion of individual extremities when carrying out certain activities. In case of SensX this means that a segmented motion event consists of n=30 signal segments of length Δt=tend–tstart.
Peak-based Segmentation with Static Window Sizes
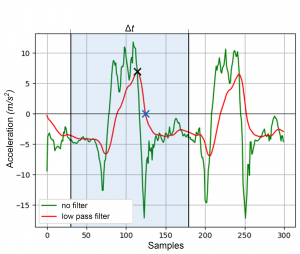
Figure 5 illustrates the implementation of a peak-based segmentation algorithm based on a sliding window with a static window size and applied to an acceleration signal captured with the SensX system. Therefore, the incoming signal is scanned sequentially for a local peak, which is marked with a black cross. As soon as one is found, the algorithm proceeds to the next zero crossing to identify the seed point of segmentation, which is marked with a blue cross. From this seed point on, the event segment now becomes cut out of the activity sequence by using a static window size Δt, which is distributed back and forth along the original signal. The the distribution ratio into both directions is dependent on the individual shape of the underlying event class. After cutting a segment out of the continuous sequence, the algorithm proceeds with scanning for the peaks of following events.
Segmentation with Extrema Fingerprints and an Adaptive Window Size
The individual steps of a second approach focusing on segmentation by utilizing adaptive window sizes is depicted in Figure 6. First, the SMMS becomes selected in (1) and is heavily filtered with a Butterworth low pass in (2). Thereby, the signal becomes transformed significantly and lots of potentially valuable information is lost. Here, the strength of the filter needs to be chosen carefully, for it also modifies the position of the signal’s zero crossings. But despite these side-effects, the signal’s shape is simplified greatly and allows for the identification of so-called extrema fingerprints.
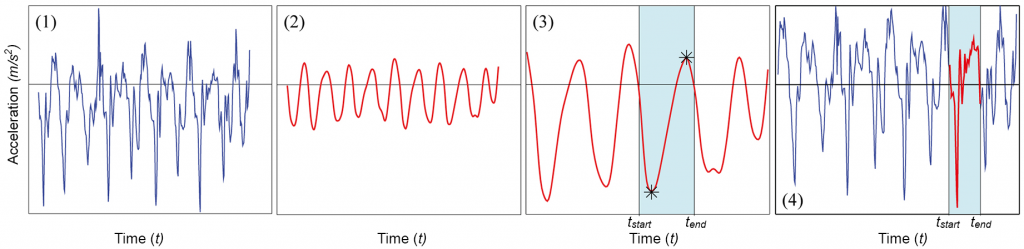
These fingerprints consist of a variable number of local extrema, defining exactly one type of motion event within an activity sequence. Figure 6 (3) depicts a basic fingerprint consisting of only one local minimum followed by a local maximum. Now, the segmentation algorithm again proceeds sequentially through the SMMS with an initially fixed window size and searches for the given fingerprint. The size is determined with the help of the auto-correlation of the SMMS, providing information about the initial duration of the encompassed signal frequencies. As soon as a corresponding pattern is found, the algorithm rewinds to the preceding zero crossing of the first extremum which marks the segment’s starting time tstart. At the last extremum it fast-forwards to the next zero crossing which marks the segments end time at tend. These timestamps are now used to cut the segments of the corresponding motion event out of all n=30 input signals (4), the segmentation proceeds at the last end time tend.
In an offline case (e.g., for model training), the outcome of (3) Segmentation is a set of motion events E={e1,...,ei}, in the targeted online scenario (real-time analysis of physical exercises) it is one motion event ei , which becomes handed over to the next step (4) Feature-Engineering. Thereby, each element ei consists of n=30 signal segments S'z. All elements ei may vary in their individual length, while the temporal length of all S'z within one element ei is equal.
(4) Feature-Engineering
In the following, the feature-engineering process for the current use-case, the analysis of physical exercises relying on the SensX sensor system, is described. There are many other automated or manual concepts to address that issue as well as the possibility to leap this step due to the benefits of supervised approaches based on Deep Learning. But because of the fact that in the current use case ad-hoc training of models for new motion events as well as classification and assessment in realtreime is mandatory, a resource-efficient as well as robust classification architecture is needed. To account for these preconditions, an analysis approach based on a compact, hand-crafted feature set and classification algorithms for supervised learning is proposed.
Inspecting and Labeling the Dataset
Prior to the actual feature engineering the dataset used for model training and testing is inspected and labeled to get an understanding of the underlying data. The dataset was compiled during a comprehensive study encompassing 26 athletes conducting 6 different body weight exercises, namely Crunches (CR), Lunges (LU), Jumping Jacks (JJ), Bicycle Crunches (BC), Knee Bends (KB), and Mountain Climbers (MC). Each exercise was executed by each athlete for 3 sets, each set with 20 repetitions. All athletes were instructed with coaching videos showing the exact execution of the exercises in prior, moreover they were recorded on video during the workout. This way 7,534 individual exercise events have been tracked.
In order to label the dataset not only in terms of the conducted exercises, but also concerning the quality class with which the exercise was executed, the following approach was used. Each event ei symbolizing one individual repetition of an exercise class was rated by two experts concerning their quality of conduction on basis of the tracked video information. The discretization of subjective perception is a challenging task and addressed within this work as follows:
\(L_{i} = p_{s} + \sum_{n=1}^i p_{a_{n}}, \; \textrm{when} \; L_{i} > 5: L_{i} = 5 \)
Here, each repetition is initially rated with a quality score of ps=1 which corresponds to the best quality rating on a scale from 1 to 5. Subsequently, penalty scores pa are added for each fault in conduction according to the fault’s severeness: 0.25 for slight, 0.5 for medium, and 1 for severe faults. These penalty scores are summed up and define the final quality label Li for each individual ei. If a specific repetition’s score is bigger than 5, it is set to 5 which resembles the worst conduction quality.
Building compact feature vectors
The basis for the following construction of compact feature vectors are pairs of an individual motion event ei and the corresponding label Li, where the label is defined by the quality score as determined in the previous section. Concerning the construction, Figure 7 provides insights on how an expressive feature set for describing motion events is chosen.
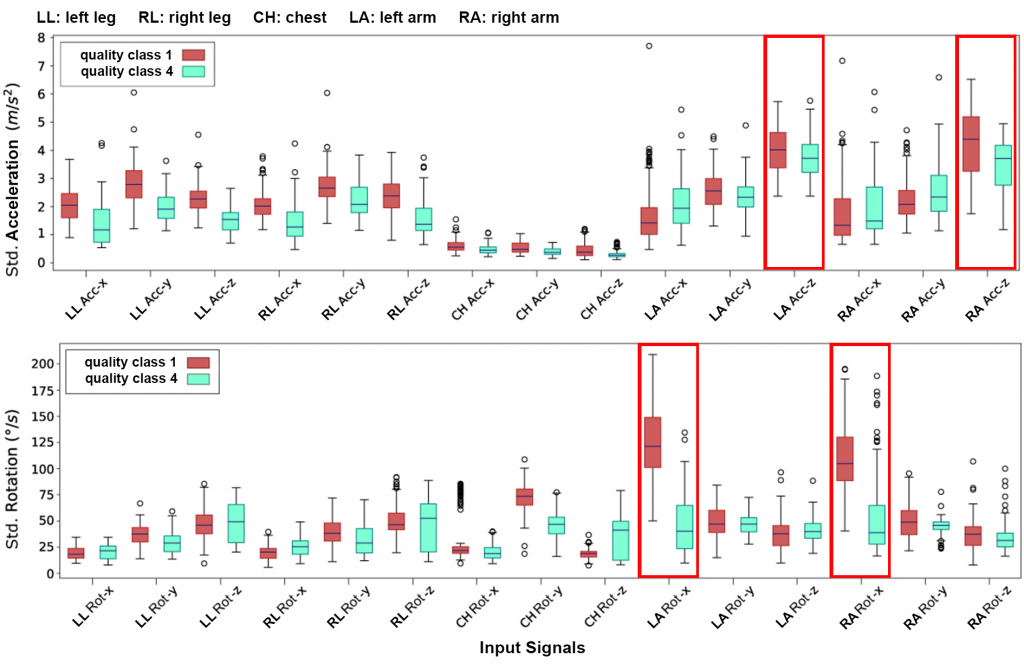
Depicted are the standard deviations of all n=30 input signals for 100 randomly chosen motion events of the exercise Bicycle Crunch with the quality classes 1 and 4, respectively. The red boxes mark the signals with the highest standard deviation, which are the acceleration of the athletes‘ arms into Z-dimension and their rotation into X-dimension. These visualize one of the singularities of Bicycle Crunches, where an athlete lies on the back and brings their arms to their knees alternately. The plot shows that clean executions labeled with quality class 1 as well as with class 4 both show a nearly comparable acceleration of the arms into the Z–direction, the acceleration for class 1 is only slightly higher. In contrast to that, the rotation in X–direction is much higher for class 1 events compared to those of class 4. Similar findings can be made for the other signals. These observations lead to the assumption, that only the standard deviations of the n signals of an event ei are already sufficient to describe its quality and to distinguish it from events of other activity classes.

Based on this assumption, Figure 8 shows the shape of the final 31 digits feature vector Xi. The first 30 digits contain the standard deviation σS'z of each of the n=30 signal segments S'z of an event ei. Additionally, the duration Δt=tend-tstart of ei is added. Subsequently, by assigning the corresponding label Li to Xi the final event instance Ii={Xi|Li} is created for each ei. These instances Ii are now functioning as the input for the model training as well as for the next step, (5) Classification.
(5) Classification
Prior to performing classification, a supervised learning classifier must be trained. Different classifiers and their individual performances are presented in the next section during evaluation. Within this section, we assume that a pre-trained classifier already exists. Input for the classification is a feature vector Xi as described in (4) Feature-Engineering, which is now processed as depicted in Figure 3, (5) Classification. The pre-trained model holds a set of possible event labels L={l1,...,lk}, which in terms of the following evaluation correspond to either an activity class or a quality class, depending on the targeted use case. For each incoming feature vector Xi, which is assigned to a corresponding event ei, a set containing the probabilities Pei={p1,...,pk} which describe the chance that Xi belongs to each label l, respectively, is calculated. The additional parameter θ depicted in Figure 3 illustrates additional hyper-parameters, which are necessary for some types of classifiers and can have an impact on the final classification output. Subsequently, the final label Li is derived from the max argument p(l|Xi,θ) within Pei, and thereby defines the class of the corresponding event ei.
Evaluation
In this section the capabilities of SensX built on the concepts described above are evaluated in terms of classification performance and potential real-time analysis. Moreover, the efficiency of adaptive segmentation in comparison to a static segmentation approach is explored.
Qualitative Assessment of Human Activities
Within the classification for qualitative assessment, four different supervised machine learning classfiers were trained and evaluated: a Random Forest (RF) and a C4.5 decision tree classifier, a Support Vector Machine (SVM), and a Naive Bayes (NB) classifier. Table 1 shows the results of qualitative assessment by using the above described, discretized quality classes for labeling. The best results for all exercises are achieved by using the RF classifier with an average mean of 89.7% accuracy within a 10-fold cross validation. Thereby, 7,413 exercise events 0ut of all 7,534 recoded events were used for evaluation, while 121 could not be extraced during the adaptive segmentation process.
Table1: Results for the qualitative assessment of physical exercises sorted by classifier| Classifier | CR (%) | LU (%) | JJ (%) | BC (%) | KB (%) | MC (%) | Ø (%) |
|---|---|---|---|---|---|---|---|
| RF | 88,00 | 90,00 | 92,10 | 92,10 | 93,40 | 82,50 | 89,70 |
| C4.5 | 79,10 | 80,50 | 83,60 | 82,10 | 84,60 | 67,90 | 79,60 |
| SVM | 73,20 | 80,80 | 85,00 | 85,70 | 80,20 | 60,20 | 77,50 |
| NB | 54,30 | 70,30 | 72,50 | 76,30 | 58,50 | 54,60 | 64,40 |
The C4.5 tree classifier and the SVM show results mostly comparable to each other, while the NB performs worst. In exchange, the NB provides the best runtime results by far due to its simplicity. These results prove that even a compact feature vector containing only the standard deviations of acceleration and motion information tracked from a proband’s extremities and their chest is sufficient for a fine-grained quality assessment.
Static vs. Adaptive Segmentation
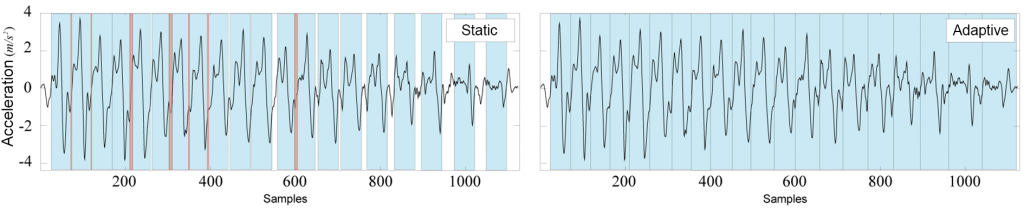
Besides the classification capabilities within qualitative analysis, the accuracy, runtime, and impact on classification performance by using static or adaptive segmentation algorithms was evaluated. Therefore, the exercises Knee Bend and Lunges were chosen, which are representative for the whole dataset. Figure 9 visualizes the segmentation of the SMMS of an exercise sequence containing 20 recurrent exercise events. On the left, several gaps and overlaps between the segmented events are visible, while the adaptive segmentation algorithm produces seamless segments as depicted on the right.
An interesting question is if the seamless adaptive segmentation really has an impact on the final classification results. Table 2 compares the accuracies within supervised learning, again by utilizing the RF, the C4.5, the NB, and a SVM classifier. Additionally, an automatically configured Hyper Parameter Optimized (HPO) classifier is used. Here, a defined time span of Δt=15 minutes is given to identify an optimized classifier and the corresponding hyper-parameters automatically.
| Classifier | KN, adaptive (%) | KN, static (%) | LU, adaptive (%) | LU, static (%) |
|---|---|---|---|---|
| RF | 93,40 | 90,55 | 90,00 | 87,45 |
| C4.5 | 84,60 | 77,46 | 80,50 | 73,94 |
| NB | 58,50 | 52,54 | 70,30 | 65,55 |
| SVM | 80,20 | 69,20 | 80,80 | 77,61 |
| HPO | 100,0 | 99,60 | 100,0 | 93,76 |
Again, for all experiments a 10-fold cross validation is implemented. The results show that training and classification while using adaptive segmentation always leads to a better accuracy with a mean average of 5.06%. But the better classification performance also comes with some limitations. On the one hand, the adaptive algorithm needs 221ms for the segmentation of one event in average, while the static approach needs 119ms. Moreover, the static algorithm proved to be more effective by segmenting 99.19% (7,473) events out of all 7,534 tracked, while the adaptive algorithm could only extract 98.39% (7,413) items.
Runtime During Training and Classification
One of the initial requirements to the SensX sensor system is the possibility to learn new activity classes ad-hoc as well as to classify given events in real-time, virtually. For the classification with adaptive segmentation, the architecture needs 1.791s in average: 1.5s until an exercise event was conducted by the athlete, 221ms for its segmentation and 70ms for the actual classification.
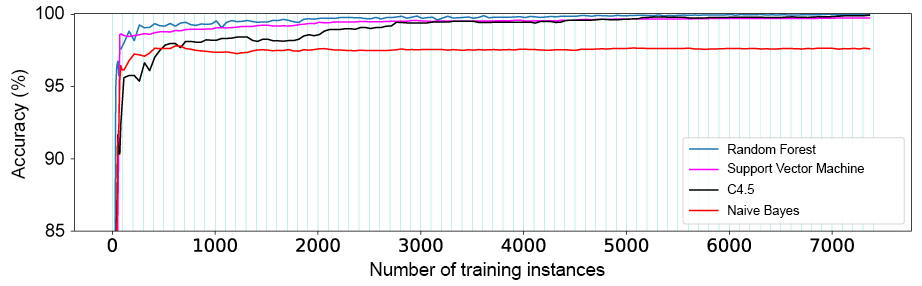
Figure 10 shows the results for model training with the 4 different classifiers and their accuracy during validation with a decreasing number of training instances. In this experiment, the former quality labels Li for each ei are substituted with their activity class names (CR, LU, etc.). The classifiers are trained with all 7,413 exercise event instances at first, subsequently the training set was reduced by steps of 150 randomly picked instances and a new model is trained, respectively. The validation is done with all 7,413 instances for each model. When only less than 150 instances are left, the reducing steps are decreased to 10 for each training in order to increase the resolution of results. Figure 10 shows that training of a model with roughly 200 instances of exercise events is already sufficient for all utilized classifiers, to achieve an accuracy of more than 95% for sheer activity recognition.
Summary and Outlook
This article presents a distributed sensor system for tracking and analysis of human motion called SensX. Therefore, a process chain of supervised machine learning consisting of 5 crucial steps is introduced and implemented. Additionally, a static and an adaptive segmentation algorithm for multi-dimensional timeseries are compared regarding their advantages and disadvantages. SensX is capable of tracking and analyzing human motion in virtually real-time and also includes a concept for qualitative assessment of individual motion events. These capabilities are verified in the evaluation together with further investigations concerning ad-hoc training of new models and the duration of event classification.
None the less, there are many open issues which are not covered by this article, such as the identification of specific malpositions during exercise as well as the inspection of non-recurrent motion events, which are not extractable by using the proposed segmentation algorithms. These and other open tasks are subject of ongoing investigations and experiments within this field of research.
[1] C. Marouane. Visuelle Verfahren für ortsbezogene Dienste. PhD thesis, LMU, 2017.
[2] A. Pfister, A. M. West, S. Bronner, and J. A. Noah. Comparative Abilities of Microsoft Kinect and Vicon 3D motion Capture for Gait Analysis. Journal of Medical Engineering & Technology, 38:274–280, 2014.
[3] T. Komura, B. Lam, R. W. Lau, and H. Leung. e-Learning Martial Arts. In International Conference on Web-Based Learning, pages 239–248. Springer, 2006.
[4] https://www.xsens.com/, last visit October 7th, 2019
[5] https://www.getenflux.com/ , last visit October 7th, 2019
[6] A. Ebert, M. Kiermeier, C. Marouane, and C. Linnhoff-Popien. SensX: About Sensing and Assessment of Complex Human Motion. In 14th IEEE International Conference on Networking, Sensing and Control (ICNSC), Calabria, IEEE Xplore, 2017
[7] https://mbientlab.com/metamotionc/ mbientlab Metawear wearable sensors, last visited November 26th, 2019
[8] A. Bulling, U. Blanke, and B. Schiele. A tutorial on human activity recognition using body-worn inertial sensors. In ACM Computing Surveys (CSUR), 2014
[9] S. Ivan W., and C. Sidney Burrus. Generalized digital Butterworth filter design. IEEE Transactions on signal processing, 46.6: 1688-1694, 1998
[10] A. Ebert. Erfassung, Erkennung und qualitative Analyse von menschlicher Bewegung. Dissertation, LMU München: Fakultät für Mathematik, Informatik und Statistik, 2019


