
Notice:
This post is older than 5 years – the content might be outdated.
I would like to start this series about reinforcement learning by giving an overview of what reinforcement learning is, what it is used for and what terminology is needed to better understand my upcoming articles. So here we go!
Let’s start with a question: Have you ever thought about how a living being learns something? I would like to present an example that reflects the learning behaviour. If you imagine a child, you know that they want to explore everything and challenge their limits. If they try to learn to ride a bicycle (= they want to stay on it as long as possible), the child sits down on the bicycle and tries to pedal. Sooner or later they will fall off the bike … Now for the interesting part of this example: The child has performed an action in a certain environment, causing themselves to fall to the ground. On the basis of these experiences they learn that they can ride a bicycle longer by avoiding failure. A Reinforcement Learning agent also learns from these experiences. Each action is evaluated to see if it was good or bad and finally to find out which action is best suited to reach its goal.
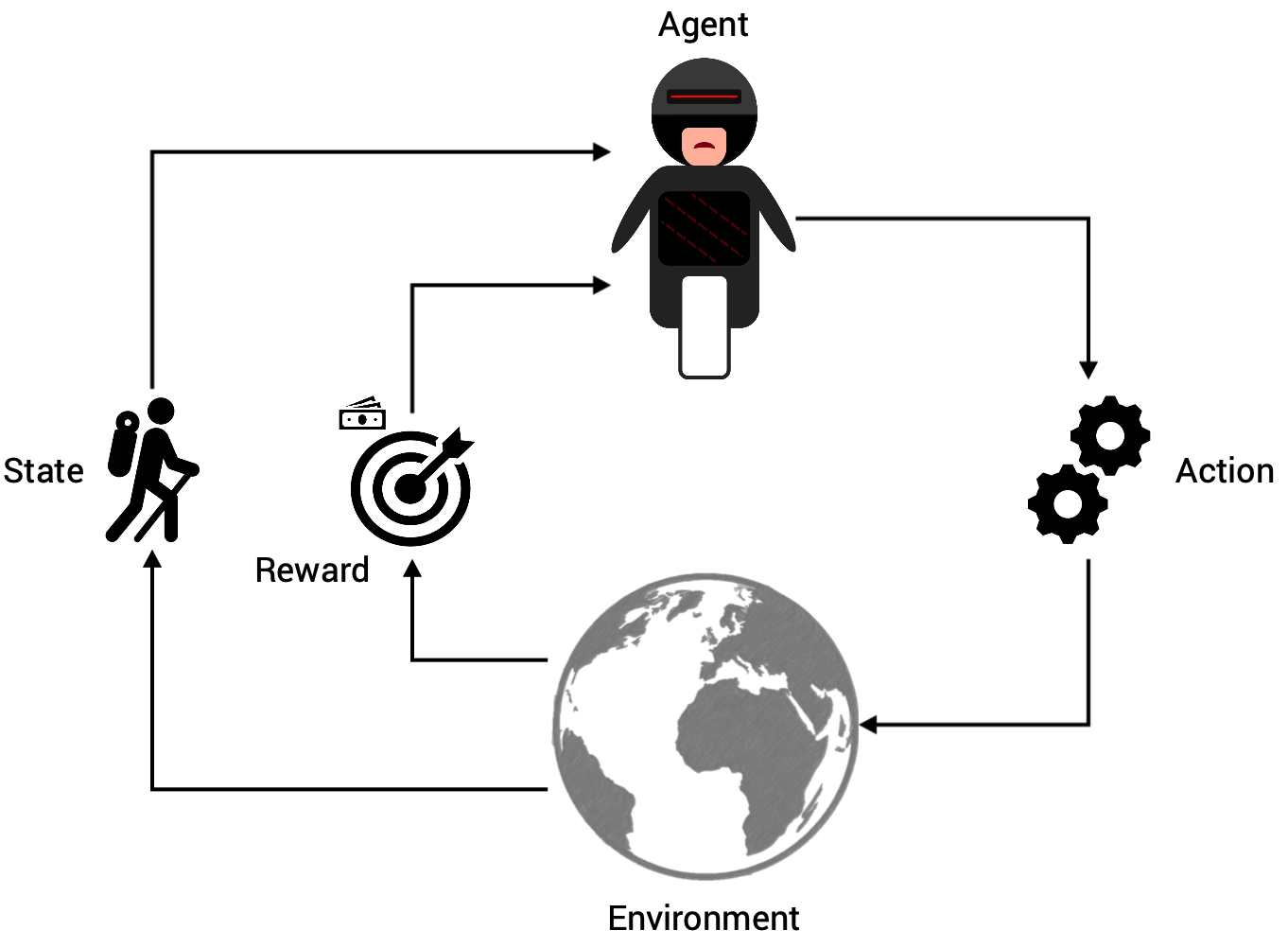
Below you can see the entire process in a diagram. An agent (e.g. the child or robot) is in a certain environment. Here it can perform actions, whereby each action moves the environment to a new state. By evaluating the performance of the transition from the old state to the new state, a reward will be granted.
 So why is reinforcement learning such a hot topic at the moment? Google’s AlphaZero/AlphaGo has made huge headlines in recent years when it beat the world champion in Go and various other chess/shogi engines [1]. Reinforcement learning is so effective for problems where it is not known which action is best in each state and in most of the problem definitions it is hard to untangle the information and trace back which sequence of actions contributed to the cumulative reward.
So why is reinforcement learning such a hot topic at the moment? Google’s AlphaZero/AlphaGo has made huge headlines in recent years when it beat the world champion in Go and various other chess/shogi engines [1]. Reinforcement learning is so effective for problems where it is not known which action is best in each state and in most of the problem definitions it is hard to untangle the information and trace back which sequence of actions contributed to the cumulative reward.
Good to know: The comparison between Stockfish and AlphaZero illustrates the power of Reinforcement Learning. Stockfish is an open chess engine and has been under development by a large community of developers for over 10 years now. In contrast, AlphaZero only needed nine hours to learn and practice chess (and Shogi and Go…) by playing against itself. And here is the really amazing part: in 100 games against each other AlphaZero never lost—with 28 wins and 72 draws!
Terminology of Reinforcement Learning
In order to get a better understanding of the following examples, I would first like to deal with the terminology. The point here is to get a feeling for what each term can be and what it should not be. If you want to dive deep into this amazing field, you have to get your basics right.
Agent
 An agent is the protagonist in reinforcement learning. The agent must be able to perform actions in the environment and thus actively participate. It needs to be able to influence and maximize its reward. An agent is often associated with a robot or physical hardware, but the agent can also act in the background and give recommendations, eg. in the form of a recommender system. The state of an agent is determined by the observation within the environment and that state can take any form. For example in Go, Chess or Shogi the state is the position of the pieces on the playing board, in a robot it is the positions and velocities of the joints or in a computer game it can be an image of the pixel input. Ideally, the state must provide all relevant information in order to provide a solution to the problem. Here again, this can be illustrated by the „learn to ride a bicycle“ problem—would you manage to ride a bicycle without being able to see anything? Try it out! (don’t actually try it, please).
An agent is the protagonist in reinforcement learning. The agent must be able to perform actions in the environment and thus actively participate. It needs to be able to influence and maximize its reward. An agent is often associated with a robot or physical hardware, but the agent can also act in the background and give recommendations, eg. in the form of a recommender system. The state of an agent is determined by the observation within the environment and that state can take any form. For example in Go, Chess or Shogi the state is the position of the pieces on the playing board, in a robot it is the positions and velocities of the joints or in a computer game it can be an image of the pixel input. Ideally, the state must provide all relevant information in order to provide a solution to the problem. Here again, this can be illustrated by the „learn to ride a bicycle“ problem—would you manage to ride a bicycle without being able to see anything? Try it out! (don’t actually try it, please).
Actions
 Actions are performed by the agent and have an impact on the environment in which the agent is operating. The action space describes the set of actions an agent can choose from; it can be either discrete or continuous. In a discrete action space, the agent can only perform a limited set of actions—eg. he can only make one step forward, backward, left, or right per iteration. In continuous action spaces the agent has much more freedom, as it is no longer restricted to a finite set, e.g. specific movements, but can also vary the radius or length of movements at its own discretion. In both action spaces, however, it is important to make sure that the boundaries of the environment and the agent are respected. When playing chess, for example, a pawn can at most perform one double step forward—so it would be cheating if he took five steps forward and three steps to the right, wouldn’t it?
Actions are performed by the agent and have an impact on the environment in which the agent is operating. The action space describes the set of actions an agent can choose from; it can be either discrete or continuous. In a discrete action space, the agent can only perform a limited set of actions—eg. he can only make one step forward, backward, left, or right per iteration. In continuous action spaces the agent has much more freedom, as it is no longer restricted to a finite set, e.g. specific movements, but can also vary the radius or length of movements at its own discretion. In both action spaces, however, it is important to make sure that the boundaries of the environment and the agent are respected. When playing chess, for example, a pawn can at most perform one double step forward—so it would be cheating if he took five steps forward and three steps to the right, wouldn’t it?
Environment
 The world in which the agent performs the actions is called environment. Each action influences the environment to a higher or lesser extent and thus yields a state transition of the environment. There are usually rules that govern the environment’s dynamics, such as the laws of physics or the rules of a society, which in turn can determine a consequence of the actions. The entire current state of the environment is monitored by an interpreter that is able to decide whether the performed actions were good or bad.
The world in which the agent performs the actions is called environment. Each action influences the environment to a higher or lesser extent and thus yields a state transition of the environment. There are usually rules that govern the environment’s dynamics, such as the laws of physics or the rules of a society, which in turn can determine a consequence of the actions. The entire current state of the environment is monitored by an interpreter that is able to decide whether the performed actions were good or bad.
Reward
 The statements about how „good“ or „bad“ actions are defined by a reward function. There are different models and ways how this function can be constructed. If, for example, you consider chess again, not every move can be evaluated per se, because in the end only winning counts. In this respect there is no general rule what a reward function has to look like or how it is defined, but it depends on the necessary criteria. Examples of criteria can be energy or time consumption until the goal is reached, or that the ultimate goal is reached at all. Looking at the video game Super Mario illustrates the point of a reward function. It maps states and actions to rewards using a simple set of rules:
The statements about how „good“ or „bad“ actions are defined by a reward function. There are different models and ways how this function can be constructed. If, for example, you consider chess again, not every move can be evaluated per se, because in the end only winning counts. In this respect there is no general rule what a reward function has to look like or how it is defined, but it depends on the necessary criteria. Examples of criteria can be energy or time consumption until the goal is reached, or that the ultimate goal is reached at all. Looking at the video game Super Mario illustrates the point of a reward function. It maps states and actions to rewards using a simple set of rules:
- When you reach the goal, you get a big reward.
- For every coin you collect, you get a little reward.
- The longer you need, the lower your reward will be.
- If you fail, you get no reward at all.
Policy
 So what is the ultimate goal of Reinforcement Learning? It can be put as simply as this: Reinforcement Learning wants to find a strategy that has the best answer to the given circumstances. That’s what you call an optimal policy. The policy is in general a mapping from state to action. Therefore, an optimal policy specifies what actions must be taken on the current state to achieve the highest reward. The biggest difficulty is learning an optimal policy where the agent has explored the environment sufficiently to perform appropriate actions even in unlikely states.
So what is the ultimate goal of Reinforcement Learning? It can be put as simply as this: Reinforcement Learning wants to find a strategy that has the best answer to the given circumstances. That’s what you call an optimal policy. The policy is in general a mapping from state to action. Therefore, an optimal policy specifies what actions must be taken on the current state to achieve the highest reward. The biggest difficulty is learning an optimal policy where the agent has explored the environment sufficiently to perform appropriate actions even in unlikely states.
Back to Topic
To get back to the topic of how living beings learn, it is important to understand why which decisions were made. There are many influencing factors and concepts that are also pursued in reinforcement learning, most of which overlap with the following.
Exploration vs. Exploitation
Why is it so hard for us to listen to our parents? Normally they have much more life experience than we do and know better what to do and when to do it. Nevertheless, we want to see if there is another way that leads to even better results than those they experienced. The competition of exploring new (even better or worse) actions versus exploiting existing knowledge is coined exploration vs. exploitation. Usually, the older we get, the more we rely on our experience and the less we look left and right. The same principle applies to reinforcement learning agents. You want to give them the freedom to explore everything, observe everything and gain experience—but the older the agents are, the longer they learn—the more they should exploit their experience and rely on it. Still, never stop exploring in a dynamically changing environment.
- Exploration: Look for new possible action-state combinations
- Exploitation: Use the best known action-state combination
Reward & Return
As mentioned above using the Mario example, an agent can be reinforced in its operating environment with the help of the rewards. But it is not expedient if the agent is always receiving small rewards (by collecting coins) while not reaching the ultimate goal (the destination flag). So, the return is the cumulative (discounted) reward of all actions the agent has received traversing the states and the ultimate goal is to maximize it. In this respect, the value function indicates the expected return of each state, whereby neither the return nor the value function must be explicitly defined, since the reward already covers this at every action-state point in time.
- Return: Expected cumulative (discounted) reward
- Reward: Transition (state-action) reward
Episodic vs. Continuing
Basically, the tasks in reinforcement learning are divided into two time-dependent categories: Episodic and Continuing. Episodic contains a maximum, finite number of actions that can be performed by the agent, but also terminal states that can be reached by the actions of the agent before the initial state of the environment is restored in both cases (e.g. computer games). Continuing, on the other hand, starts once in the original state and the agent can act endlessly, whereby the target can never be completely reached. In theory, however, there can only be continuing tasks, since even with episodic tasks it can be assumed that if the environment is in the terminal state, it remains there for an infinite period of time.
- Episodic: Finite number of steps before resetting the environment
- Continuing: Infinite number of steps (no resetting)
Value-based & Policy-based
Reinforcement learning methods are driven by a construct of a Markov Decision Process. This process allows to create a mathematical framework for modeling of decisions, which are made partly randomly and partly under the control of the decision maker. The goal is to find an optimal policy (i.e. state-action correspondence). However, the way to achieve this goal can vary. The value-based methods use a performance criterion to decide which action leads to the highest reward, whereas the policy-based methods provide a direct mapping from state to action. Policy-based methods can enable stochastic policies (e.g. probability of winning in the case of Stone/Paper/Scissors), but also a large and continuous action space. The strengths of value-based methods are in particular in the simplicity of the solution, but also in the speed of learning.
- Value-based: Choosing the action with the highest performance criterion
- Policy-based: Direct mapping from state to action
Competition vs. Cooperation
In many tasks, more than one agent is needed to solve a problem. If you look at tennis, for example, an agent would not be able to pursue a real goal (who plays tennis alone?). In this respect, it is also necessary to place several agents in the environment in reinforcement learning algorithms. This increases the complexity of the interactions within the environment, since the actions of each agent can be completely, partially or incompletely perceived by every other agent. The problem definition determines whether a common or an individual goal is pursued. Tennis is normally regarded as a competitive sport. Each player tries to score as many points as possible—the player with the most points wins. However, the problem can also be modified accordingly so that the common goal is to play the ball back and forth as long as possible without a final winner. In multi-agent scenarios, accomplishment of the task and achievement of a goal is also called ‚competition‘ (against each other) or ‚cooperation‘ (with each other).
- Competition: Beat the opponent
- Cooperation: Increase the total (shared) overall reward
Curiosity & Sacrifice
Curiosity and sacrifice are two forms of intrinsic motivation and concepts that deal with long-term success. Usually exploration is conducted on the basis of a stochastic policy by weighing actions against likelihood distributions—this is valid from a human but also reinforcement learning point of view. However, this stochastic process can be modified through intrinsic motivation by being attracted to rare or novel circumstances. This is where curiosity and sacrifice come into the equation. Curiosity tries to push you for so long that such unlikely conditions are always found, whereas sacrifice accepts short-term losses to be successful in the long run. It becomes clearer when the life of a human being is considered. If one lets a child drive by their own curiosity, then tasks can be confronted later, without having learned these explicitly before. And as good as anyone who has completed a vacational training or studied has accepted a short-term sacrifice to potentially get a better job later on.
- Curiosity: Explore without following a specific goal
- Sacrifice: Ignore short-term losses for higher returns
Take away …
In this blog the basic concept of Reinforcement Learning was shown. The main goal was to build an understanding of the closed loop system, in which an agent uses actions to change the state of the environment and thus receives rewards, with the goal of maximizing the return. Furthermore, this first part of the series serves as a reference book for all necessary terms of reinforcement learning.
Need more background knowledge?
- Never used deep learning and want to learn the fundamentals? Sebastian Blank did a great work in Deep Learning Fundamentals
- You want to understand the basic concepts and link them to real applications? In my previous work Concepts & Methods of Artificial Neural Networks you can find what you need
- Marisa Mohr shows in her blog post a mathematically but very descriptive representation of Entropy, which can be used to measure unpredictability in machine learning models
- You think machine learning or deep learning is a black box and you can not know what your model is doing – Marcel Spitzer will show you the opposite in Machine Learning Interpretability
References
- [1] Google’s AlphaGo https://deepmind.com/research/alphago/
- [2] Exploration vs. Exploitation http://home.deib.polimi.it/restelli/MyWebSite/pdf/rl5.pdf
- [3] Curiosity-driven learning approach http://www.pyoudeyer.com/oudeyerGottliebLopesPBR_R0.pdf
- [4] Curiosity in Reinforcement Learning https://ai.googleblog.com/2018/10/curiosity-and-procrastination-in.html


