
Notice:
This post is older than 5 years – the content might be outdated.
In order to build data services or advanced machine learning models, organizations must integrate large amounts of information from diverse sources. As a central place to consolidate as many data sources as possible we often find what is fashionably called a data lake. Building a data lake usually starts by collecting as much data in raw form as possible. The idea is to give data scientists simple access to all available data so that they can combine information in ways not yet anticipated. Hadoop is the preferred choice for such a system because it is able to store vast amounts of data in a cost-efficient manner and is largely agnostic to structure.
Beyond the Data Lake: Creating Value from Data
In practice, however, users of a data lake won’t want to clean, validate, and interpret raw data again and again whenever they need to analyze it. Given the possibly complicated nature of raw data sources (e.g. weakly structured clickstream data), this can also lead to conflicting or just plain wrong interpretation of data between different applications or even different users.
As a consequence, raw data within a data lake is typically cleaned, enriched, and pre-aggregated into a warehouse of common, reusable, and interdependent entities. If, for example, a data lake contains raw clickstream data, derived tables will contain session data. Sessions could be joined with product data to create a base table for recommendations, and so on.
Such a platform is sometimes referred to as a data hub with different layers for raw, pre-processed, and aggregated data. This of course is nothing new—every classical data warehouse is built in a similar way. The difference is the magnitude of data, the growth of a big data system and the more agile and experimental way one works with such a system.

Experiences with Standard Hadoop Tooling
Large organizations quickly end up with hundreds of interdependent tables in a Hadoop data hub. Loading of data in such an environment by means of conventional workflow-based ETL schedulers such as Oozie, Talend, or Azkaban quickly becomes tedious.
This is the experience that Otto Group BI made when building a Hadoop data lake for web analytics, product, and CRM data from 120 online shops. They started out with Oozie for orchestrating their workflows. After 3 months, they had integrated dozens of data sources and computed hundreds of derived tables using HiveQL queries, Pig scripts, plain MapReduce jobs and Spark jobs.
Following an agile, iterative development process, refinements and refactorings on a weekly basis were quite common in the early stages of development.
As the data hub grew with each iteration, however, the process of adding and changing tables was increasingly slowed down by the toolchain to the point where they needed to look at a different approach.
As a consequence, Otto Group BI designed and implemented Schedoscope – a goal-driven scheduling framework that automates many migration-related tasks arising from change thereby facilitating an agile development process.
In the following, we outline major obstacles one faces when choreographing a large Hadoop data hub with Oozie and show how Schedoscope alleviates these issues. While some of these obstacles are specific to Oozie, similar problems can be found with any workflow-based scheduler.
Schedoscope makes ETL fast and agile
When a table changes—say its structure is modified or the computation logic by which it is derived from other tables changes—all tables depending on it directly or indirectly need to be potentially recalculated.
As a consequence, considerable development resources are not only consumed by actually implementing the table change but also by writing migration scripts that propagate the change through the layers of the data hub.
The latter is particularly bothersome as migration scripts are applied only once and never used again. Also, migration scripts are difficult to test.
Schedoscope improves on that by enforcing a DRY principle—don’t repeat yourself. You define your table, its dependencies, and the computation logic to fill the table in a single place: the Schedoscope view.
Schedoscope compares views with the current state of data hub and automatically applies necessary changes. In case the structure of a table changes it is dropped and recreated; in case table computation logic changes, affected partitions are automatically recomputed with the new logic as well as all affected partitions of directly or indirectly dependent tables. No manual effort is required to roll out such a change.
Robustness and easy configuration
Oozie requires you to create and maintain a myriad of script and configuration files for each job:

- Schema definitions in Hive DDL for the table structure,
- the actual SQL queries, MapReduce jobs, or Spark jobs that compute a table,
- an Oozie workflow.xml definition file choreographing these jobs,
- an Oozie datasets.xml definition file plus,
- a coordinator.xml file to trigger workflows when data has become available,
- a bundle.xml file containing packaging information for bundling Oozie workflows for deployment.
There is no reasonable IDE support to speak of that helps keeping the references between these files consistent.
Schedoscope encourages you to think in terms of data, views on that data, and dependencies between your views. This makes it much easier to understand the semantics of your tables. Because you define what your view is supposed to contain, testing becomes quite straightforward.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 |
case class Nodes( year: Parameter[String], month: Parameter[String]) extends View { val version = fieldOf[Int] val user_id = fieldOf[Int] val longitude = fieldOf[Double] val latitude = fieldOf[Double] val geohash = fieldOf[String] val tags = fieldOf[Maps[String,String]] comment("View of nodes partitioned by year and month with tags and geohash") storedAs(Parquet()) } |
Schedoscope is based on a concise, statically typed Scala DSL, so views can be defined within an IDE. This has several advantages: the IDE will spot errors in your view definition while you type. You specify all of your view in one place. By following the DRY-Principle Schedoscope avoids inconsistencies and mismatches between different views. It also allows you to define common parts of your table as templates (or traits in Scala terminology). If you, for example, use a timestamp column in every table, you may define this as a template.
Lack of dependency management and packaging
Most workflows need additional resources such as jars for user-defined functions (UDFs) or Spark jobs, configuration files, or static data such as user-agent strings.
You need to version and manage these dependencies and make sure that they get deployed together with your workflow.
Partial reload of data
In practice, you will have to partially reload tables on a regular basis. Reasons for this might be:
- One of your data sources delivered incomplete or defective data.
- You had a bug in one of your workflows.
- Your analysts need a new metric which needs to be extracted from unstructured data.
Oozie requires you to manage the state of your data partitions manually. Also, the Oozie API does not offer efficient support for instantiating and re-instantiating a potentially large number of coordinators for time intervals.
Otto Group BI actually ended up writing a custom tool for this purpose. However, this tool required knowledge about the dependencies between tables, resulting in an additional JSON table dependency definition file to be managed along with the myriad of other Oozie configuration files.
It is difficult to change partition granularities with Oozie
Partitioning is an important factor in Hadoop data design. You want your table partitions to be fine-grained to allow for efficient data preselection; at the same time, you want your partitions to be coarse-grained to better utilize HDFS block size and warrant the significant overhead incurred by Hadoop job launches.
Oozie, however, does not offer workflow operators that allow you to easily go from a fine-grained to a less fine-grained partitioning such as, for instance, from a daily to a monthly partitioning scheme. In such a case you would want your monthly table to be computed once when all data from all days of that month has become available. With the means offered by Oozie datasets and coordinators, the monthly table would be computed every time data for a new day has become available.
Powerful scheduling
Schedoscope tracks the version of your data and your view definitions. The scheduler will automatically detect changes to your data or your transformation and will initiate a recalculation of that data and all views that depend on it. This way, all data is kept up-to-date automatically.
Automated testing
It is difficult to test Oozie workflows and data transformations during development. At first, Otto Group BI ended up setting up a Fitnesse-based (http://fitnesse.org) test environment on a development cluster.
With this approach, test definition was rather cumbersome, and test execution times were rather long. Even simple tests took at least 10 minutes to execute. As a consequence, developers were executing tests sparingly, cramming too many test cases into single tests, and not using tests to actually detect bugs in their code. Tests also fell out-of-sync with the code quite often.
Integrated Testing Framework
So, testing transformations in a Hadoop environment is hard. With Schedoscope, you can test your Hive, Pig or Spark-based transformations using Scala-based unit tests.

The main design principles of Schedoscope’s test framework are:
- Integration with Scalatest: Test specification and result checking is based on Scalatest, with its expressive library of assertions.
- Local transformation execution: In order to decouple testing from the availability of a Hadoop cluster environment and to achieve fast test execution times, the framework embeds various cluster components required for executing the different transformation types and configures most of them to run in local mode.
- Typesafe test data specification: Because the specification of input and output data of tests „lives“ within Scala, we can completely eliminate errors stemming from wrong types, column names, etc. with compile time checks. Another beneficial side effect of this approach is that one can use autocompletion in IDEs like Eclipse while writing tests.
- Default data generation: The framework encourages you to write separate tests for different aspects of a view transformation by generating reasonable default values for non-specified columns of input data. It is thus possible to focus on some specific columns, reducing the effort of specifying test data to a minimal amount. This is in stark contrast to other approaches where the test data definition overhead encourages you to create one huge input data set covering all test cases.

Metadata Management
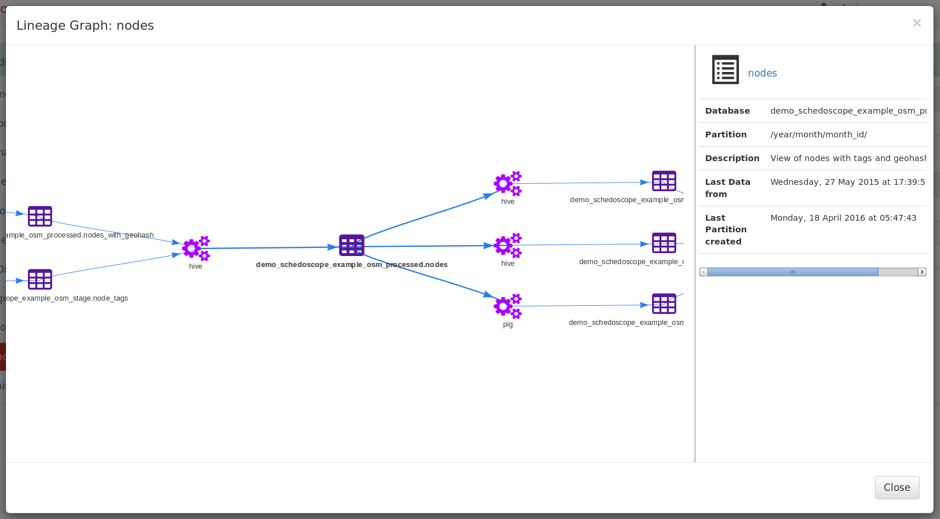
To be successful with data, analysts will need to navigate through available data. Discovering data sources, Thankfully, through the declarative nature of Schedoscope, there already is plenty of metadata available! Tables, Columns can be annotated and commented, data lineage is already in the model. All you need is a way to access it.
Metascope is an add-on to Schedoscope that makes this metadata accessible. Views and Columns are searchable using a full text search index. Analysts can annotate and comment on them. Metascope also extracts summary statistics and sample from tables, so that analysts can learn about data in one place.
It is also possible to link columns and table to business entities and thus generating a semantic view on the data in the datahub.

Read on
To find out more about Metascope, have a look at the Metascope Primer on github. To find out more about our offers in BI, Big Data Platforms, Data Science & Deep Learning or Search & Text Analysis, visit inovex.de.
We thank Utz Westermann for his valuable feedback and his contributions to this blog.


