
Machine Learning was long considered a difficult field where you had to employ a team of specialists to build good and useful models. In recent times, new services want to break this paradigm and make Machine Learning accessible for everyone by deciding on implementation details automatically. Of course, among others, the three largest cloud providers – Microsoft, Amazon, and Google – offer such AutoML services. They claim that one can train and deploy a Machine Learning service without being an expert in the field. In addition, this is supposed to be possible in a low- or no-code environment, that is, making Machine Learning available for users without great programming experience.
In this article, I want to test this claim and provide an overview of the capabilities of different cloud providers. While I know a fair bit about Machine Learning I want to test the three services acting like I had no relevant experience in the field. I want to find out if AutoML services can actually lead to a democratization of Machine Learning. And will ML specialists then become obsolete? Let’s find out!
Comparison of the AutoML Services
All three service providers offer a similar set of features. They all have an AutoML service for the most common ML problems and a way to run model training and inference within their systems in a no-code environment. The data types they support are also almost the same: All three support classification and regression tasks on tabular data as well as predictions on time series, image classification, and natural language problems such as text classification and entity extraction. Vertex AI and SageMaker also support tasks on videos such as action recognition and object tracking.
Still, there are some differences in the actual implementation of the features and how the services are integrated into the rest of the cloud environment. Also, how much work can actually be done in the GUI before you have to dive into the code? Before I describe how these differences affect using the service, let’s take a look at a higher-level comparison of the providers.
A tabular comparison of the three large AutoML services
| Dimension | AWS SageMaker | Azure AutoML | GCP Vertex AI |
|---|---|---|---|
| Support for Data Sources | Files on S3, Athena, Redshift, Snowflake, Databricks, EMR and many third-party providers | Azure Blob Storage, Azure File Share, Azure Data Lake | Cloud Storage, BigQuery |
| Data Import | Data Upload/Preparation needs to be done manually in respective service, explicit exporting to S3 | Upload within GUI when not using existing data | Upload within GUI when not using existing data |
| Complexity of AutoML Model Training | Basic settings & sensible defaults available in GUI, a few advanced settings possible.
Auto-generated Notebook available for very detailed manual tweaking |
Basic settings available, GUI provides more possibilities for advanced configuration than the other two services. Only service with the ability to select cluster/compute type for training | Simple AutoML GUI only has basic settings.
Vertex AI Pipelines provide more configuration but more complexity. |
| Model Deployment | Real-Time/Batch Deployment with configurable instance type, configurable sampling of inputs/outputs. Traffic split possible via Code. | Real-Time/Batch Deployment with configurable instance type. Multiple models per endpoint with traffic split possible in GUI. | Real-Time/Batch Deployment with configurable instance type, configurable feature attribution, and model monitoring jobs. Multiple models per endpoint with traffic split possible in GUI. |
| Model Monitoring | Monitoring job needs to be written and scheduled via notebooks (low-code solution) | Public Preview for Data drift, Prediction drift, Data quality and Feature attribution drift monitoring. | Model monitoring can be enabled via GUI to include data drift and prediction drift. Automatic retraining based on alerts can be enabled as well. |
| Integration in own application (Endpoint/local model) | REST calls to endpoint with Sagemaker library.
Model available for download in a respective format of the algorithm, no common download format |
Sample code for REST does not require additional libraries.
Model download contains sample code to run the model locally or as custom code on Azure |
RPC call to Google’s endpoint in their library.
Model download contains TensorFlow Package |
| Versioning | Model registry available, via GUI or API | Model registry available | Model registry available, access via GUI or BigQuery |
| CI/CD | Possible with Pipelines | Possible with Pipelines | Possible with Pipelines |
| Availability of pre-trained models | Foundation models for CV and NLP, also pre-trained models and LLM prompts for specific tasks | NLP models for various applications, partly from Huggingface. Also OpenAI Whisper for speech recognition | Large selection of ML models for all kinds of problems. Huggingface models, Stable Diffusion, ImageNet, GluonCV |
| Data Quality | Many possibilities for manual analysis and fixing data quality problems | Automatic analysis and fixing of simple problems, notifications and warnings if the data quality seems to be too bad | No explicit checks for data quality, no explicit null handling for classification. Null values in prediction tasks are imputed from surrounding values |
| Cost structure & transparency | Hourly prices for everything depending on compute instance | Hourly prices for everything depending on compute instance | Some AutoML prices fixed, everything else depends on the selected compute instance |
In Practice
Now let’s see how this theoretical capability measures up in practice. I want to run an actual ML task on each of the services to compare my experience with them. For this I have decided to use the well-known Titanic Dataset which offers several advantages for this task:
- It is rather small, allowing for quick training and evaluation times.
- There is no 1:1 relationship between the features and the prediction target. This means that we do not have to expect a rather boring result where all services return 100% accuracy.
- Many people already published their results with this dataset. From them, we can still infer a reasonable baseline for our expectations of the services.
With this dataset as a proxy for a real ML problem, I could see the different services in action. Now I can describe my experience of how well they actually work instead of only working with the providers’ documentation. So let’s go through an AutoML workflow with the three providers.
The Interface
From the start, the user interface reflects the respective philosophy of the three AutoML services.
AWS SageMaker’s tabbed user interface is based on JupyterLab with a seamless transition between GUI-based tools and Jupyter Notebooks. SageMaker appears to be the most code-oriented provider of the three: While there is reasonable capability to run basic functions without having to write any code, even slightly advanced configuration needs to be done in code such as Jupyter Notebooks. Fortunately, SageMaker also provides most of the required boilerplate code in Notebook templates.
On the contrary, Google’s Vertex AI provides a very simple GUI with friendly illustrations for their AutoML product. For the most part, everything that can be configured is available upfront, there are a few hidden submenus. The possibilities to switch from GUI to code are limited, you seem to be supposed to stay in the GUI.
Microsoft’s Machine Learning Studio offers a compromise between the two. The GUI offers more possibilities for configuration in submenus or already during the regular workflows. The interface is unobtrusive and mostly designed for a low-code workflow. Still, VS Code is available as an IDE for running Jupyter Notebooks.
Importing and Preparing the Data for the AutoML Service
At Vertex AI, the import is very easy using the provided GUI, either by uploading data directly which will be stored in Google Cloud Storage, providing an index file of the training data, or pointing to a BigQuery view or table. There is no workflow for further modifications of the data such as imputing missing values or balancing classes. Despite of this, I assume that some of this is automatically done in the background of the AutoML flow. Simple statistics on the distribution of each feature are available in the GUI which suffice for superficial manual checks. Vertex AI hides further processing of the data from the user if that happens.
In the Azure ML Studio, you can import data from the Azure Blob Storage or from Azure Delta Lake. After the import, Azure offers detailed introspections on the data with graphical representations, missing values, and some calculated statistics such as the standard deviation or quantiles for numeric values. Azure ML Studio has a feature named “Data Guardrails“ in the model training workflow where typical issues with the data are addressed during the training process. These include imputing null values, and checking for high cardinality features and unbalanced classes.
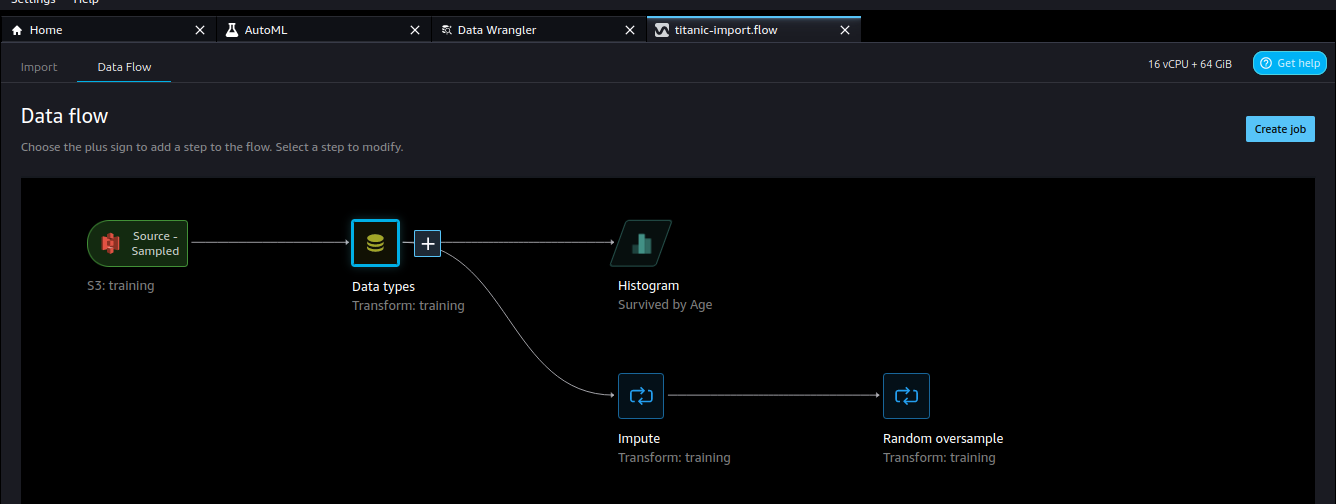
The data import in AWS SageMaker has a slightly higher complexity than with the other providers because it is not designed for one-off imports but for reusability. Still, it works quite well as a no-code solution, using a graph-like interface to describe the data flows. One great advantage is that SageMaker offers the largest variety of data sources. They range from Amazon products such as S3, Athena, or Redshift to Databricks and Snowflake. Even a large variety of third-party import tools such as Google Ads, DataDog, or Salesforce is offered.
While there is no automatic check for potential issues with the data such as checking for null values or a warning for unbalanced class distributions, it is possible to add such steps manually. Other data transformations such as grouping and outlier detection can also be included. Additionally, one can add data analyses to the import flow. All this allows for creating complex data imports within a simple GUI. The disadvantage is that you have to know how to work with (messy) data, so you have to have some ML experience to get a useful result out of it.
One advantage of Vertex AI and Azure ML is that data sources are refreshed automatically when the underlying data changes. While the data import flows at AWS SageMaker offer the greatest flexibility, they export the data again in a specific location and the flow needs to be rerun when the data changes. This also means that the data sets are not as well integrated with the rest of the process. Instead during the training, you point the data towards the export location on S3 instead of the dataset.
Model Training and Evaluation
All three services again have the same basic feature set. This includes selecting the data and some basic parameters such as the target metric and a training time limit. After the training you get at least one model together with some of its performance metrics: The F1 score, a confusion matrix, or a diagram with the ROC, to name a few. But again there are differences, especially regarding the extent to which the user can customize the process.
The training of a new model in SageMaker ML Studio is easier than the import: With the data made available by the data flow, SageMaker is able to automatically infer the problem type, train model candidates and optimize hyperparameters. For the trained models some basic metrics such as accuracy, the ROC or the F1 score are available. While I would have hoped for more details on the model performance it should be enough to assess whether the model is suitable for the job. One bonus for experienced developers is that notebooks with boilerplate code for data exploration and model candidate generation are automatically made available. They still need to be adapted but appear to be a good starting point for further research.
The AutoML in Azure process is comfortable to use and makes a more detailed configuration possible than the other two services while still keeping the process straightforward. For example, you can limit the training to certain model categories and configure for each feature how missing values should be imputed. It is possible to manually define how the training/validation/test split is done and even add a second dataset purely as test data which may be very useful.
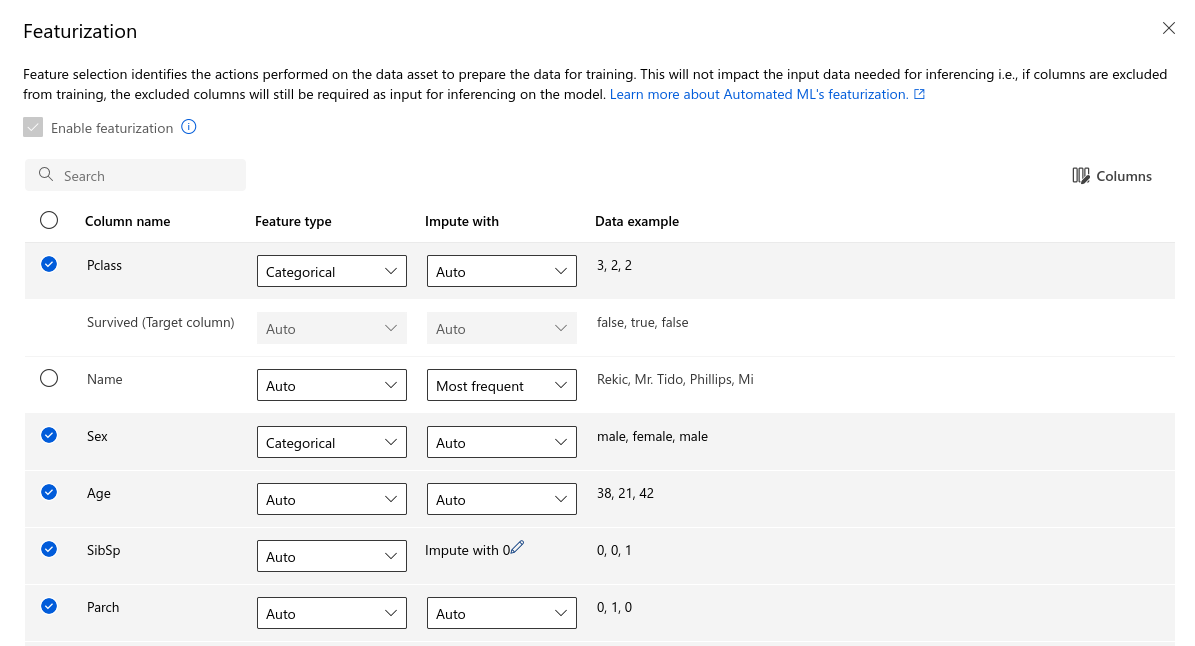
As mentioned before, after the training Azure shows some information about the decisions that were made to prepare the input data: How the validation split was performed, whether the classes were balanced, missing features had to be imputed and how, features with a too high cardinality were discovered. This section named “Data Guardrails“ helped a lot to increase my trust in the result of the training.
For the best resulting model, Azure also creates a dashboard with model metrics and charts such as the ROC. In contrast to the other providers, this dashboard can be freely modified, charts can be added or removed as needed. There are also detailed explanations for the feature importance within the model. Most of these features are probably not relevant for someone without ML experience but they also help experienced ML practitioners to ascertain the training quality.
Training a model with the Vertex AutoML interface is also very simple. Again, it is well structured and provides all the information needed to quickly start the training. There are some configuration possibilities such as modifying the data split between training, validation, and test data. Despite this are only very few possibilities to influence the process. One notable distinction between the other two services is that Google’s AutoML service does not let you decide on the compute instance the training runs on. Instead, there is a fee that is only dependent on the duration of the training, again configurable in the GUI.

When the training has finished, only the best model remains visible to the user, and the model evaluation again only has a few statistics and graphs such as the ROC. Since this service is intended for developers with little ML experience this may be sufficient.
Regarding the resulting prediction accuracy, I could not find a significant difference between the providers. The result from Azure AutoML, a large model ensemble, showed the best performance. Still, this may also be caused by random factors such as the training/test data split. In my opinion, the differences were not large enough to imply fundamental performance differences between the services. A detailed comparison of the performance of the services with multiple ML problems may lead to a finer differentiation. Still, I believe that the differences will not be that significant.
Deployment and Querying the Model
With the resulting model there are two ways we can make predictions with it: Deploy it directly with the respective provider’s tools or download and run it on our own. Of course, the providers want us to use their services but all three offer a model download with varying difficulty. One possibility to deploy a model yourself would be by using BentoML as your MLOps tool.
Vertex AI’s trained model can either be downloaded as a TensorFlow package or deployed to an endpoint. Deploying to an endpoint is mostly very simple, although the current example code is inconsistent with the library and you have to make some fixes for the example to work. With the fixed code it is rather easy to make a request. The endpoint uses a gRPC call with a payload encoded in Protobuf format, so you are dependent on Google’s libraries if you want to include this service in your own code. This may induce unnecessary bloat in smaller Python applications.
An advantage of Vertex AI is that it is very simple to deploy multiple models to the same endpoint with a customizable traffic split. This makes A/B testing or staggered updates very comfortable. Contrary to the training the endpoint can be configured to run on a certain compute instance so that it can be scaled according to your needs. It is also possible to enable model monitoring during endpoint creation. This allows you to catch data drift or prediction drift which may occur over time. By default the monitoring sends a warning mail but it is possible to include additional warning channels to enable automated reactions such as model retraining.
The deployment in AWS SageMaker itself is quite simple as well. The important decision again is which compute instance should be used, depending on the model size and expected load on the endpoint. There are two types of endpoints: A real-time endpoint is a REST interface which expects and returns CSV data. On the other hand, a batch endpoint is configured with an input and output directory in S3. The provided sample code allowed me to query the endpoint with minimal effort although I consider it less than ideal that I have to use the Sagemaker Python library even for a simple request.
Azure ML Studio offers the best way for both use cases, whether you want to run it locally or use an endpoint: Azure provides a model download which includes a Python file intended to be run on their servers if you want to run a custom inference script. While the script can be run locally it requires Python 3.8 and is not compatible with current Python versions. The example code for calling the endpoint is simpler. Azure also provides a REST endpoint, and the example code calls it without requiring packages outside of the Python standard library. Within the example code the data structures also make multiple predictions per request very comfortable to implement.
Monitoring and Retraining
Since input data may change over time it is important to ensure that predictions remain accurate. We have multiple points where we can check a drift over time, such as distributions of the input data, feature attribution for the prediction, or the distribution of the predictions. Often these changes can be alleviated by retraining the model. All three platforms put this firmly outside of their no-code interface with only the monitoring being configurable in the GUI. Reacting to potential alerts and automatically triggering a retraining pipeline needs to be done in code. All three providers offer example code in their knowledge bases which is helpful here.
One notable mention goes to Vertex AI, the only service with a GUI for data drift or model drift detection. This step also needs to be configured in code for the other two services. Automatic reactions to the alert channels still need to be coded but we have at least e-mail monitoring and the other available channels from the Google Cloud Monitoring service built-in.
Conclusion
Google’s Vertex AI, Amazon’s AWS SageMaker, and Microsoft’s Azure ML Studio all provide a solid platform for AutoML applications. Still, there are some differences between the services. I believe they are mostly only interesting for organizations that do not yet have an established ML infrastructure. For those who are already customers of a certain provider, it probably makes the most sense to just stay with their respective provider, migration costs overshadow the possible benefits of using a different service.
Of course, the availability of AutoML services is not limited to the three major cloud providers. Many other companies offer AutoML services. There are also toolkits such as auto-sklearn to run an AutoML pipeline on your own. Still, with many companies already using the cloud it makes sense for them to also use the toolset available there.
Vertex AI provides a very comfortable starting point for new AutoML applications. The interface is friendly and easy to use, although the set of advanced features is rather limited. The service works well for initial evaluations of which predictions may be possible on given data.
AWS SageMaker has a steeper learning curve in the beginning but with it more features are available. Especially for data analysis and preparation, there are more tools available but they add complexity. So if you have a good understanding of data preparation, arguably the most important part of Machine Learning, SageMaker can take away some of the work for you. Beginners may have difficulties navigating what SageMaker needs to produce good results.
Azure ML Studio offers a compromise: It has a lot of built-in features and takes away some work but still explains what it does. It also offers most possibilities to tweak some of the neuralgic settings. You are encouraged to write code yourself and the available analysis tools require some understanding of ML. Still, even without it, you can work with the service just fine.
So, do these three services live up to their promise of the democratization of Machine Learning? In my opinion, they can help with it but bring their own liabilities. Especially in critical applications we need to understand how and why a system acts like it does. Although some of the services make attempts at explainability, experts are still needed. Their knowledge makes it possible to assess how an ML system actually makes its predictions. The better a service hides how it works and how its decisions are made, the easier it is for non-experts but also the less trust a company can put into their AutoML system.
For experts, AutoML services may be very helpful to run one-off predictions that do not need to be integrated into a larger system. Additionally, one important use case may be to create a baseline against which to measure future development. In the MLOps Lifecycle, they can therefore serve as a starting point for the development of a more sustainable model. But still, these systems provide no support channels and explanations that laypersons can understand. Therefore businesses that want to rely on Machine Learning systems will still rely on human experts to design them.


