
Notice:
This post is older than 5 years – the content might be outdated.
Despite all advances in machine learning due to the advent of deep learning, the latter has one major shortcoming: It requires a lot of data during the learning process. Since the current global datasphere is estimated to be approximately 20 Zettabytes (ZB) and is predicted to grow up to 160 ZB by the end of 2025 [1], it is not a challenge to get more data in order to let machines learn. However, most models are only able to train in a plain supervised way with labeled data. The label of a data object provides explicit information about the object and it mostly needs to be provided by humans. Therefore, the labeling process of data is often time-consuming, leading to situations where the labeling of data might be too costly and hence, deep learning can not be applied to certain use cases. For this reason, it is necessary to find more efficient learning techniques. Another training type called semi-supervised learning is not only able to use labeled data but it can also extract information from unlabeled data and improve in that way the model’s performance. Therefore, semi-supervised learning is well suited for problems where labeled data is very limited, such as text spotting on scarce documents.
At inovex we are constantly looking for new research opportunities in which we can try out new frameworks and models in order to broaden our horizon and enrich our skillset. We identified a use case at Germany’s biggest vehicle marketplace online in which we were able to compare a supervised and a novel semi-supervised approach regarding their classification performances in my Master’s Thesis. Since the use case is about spotting characters in images, we used the character detection and recognition part of a self-developed text spotting pipeline for model comparison.
Use Case
The use case generally regards the advertisement of cars on the platform: When selling a car, a customer of the vehicle marketplace needs to provide a description of his car including information like manufacturer, type of car, color and engine power. For a few years, the platform has been using the vehicle identification number (VIN) of a car to request a lot of the necessary information directly from a database. This service simplified the process of advertising cars as only one single number needs to be provided by the customer in order to receive almost every required information about a car. In addition, the customer still needs to provide information about accidents or customizations of the car. To further facilitate this error-prone process of manually copying the 17 character long VIN into some web form, inovex wanted to build an image recognition tool which is able to automatically extract the VIN from images of the vehicle registration document (VRD).

As letters need to be detected and recognized, the task at hand is text spotting, better known as Optical Character Recognition (OCR). OCR has been well studied in the past and many open source and commercial solutions already exist on the market. Since we wanted to build a highly customized image processing pipeline, we decided to first evaluate flexible open source solutions. We began by evaluating Tesseract, an OCR tool from Google. As it turned out, Tesseract was not able to achieve a satisfying accuracy (<90%). Furthermore, we evaluated commercial end-to-end solutions which did not provide good results either as we will show at the end of this article, comparing a commercial tool with our approach. This is especially due to the fact that VINs are often not printed exactly within the provided field of the VRD. That leads to a case in which the boundary lines of the corresponding field cross the characters, resulting in a far more difficult task. The following image depicts a VIN suffering from that kind of distortion. Therefore, we needed to come up with our own text spotting pipeline which is able to detect and recognize the VIN in images of VRDs despite these shortcomings.

Text spotting pipeline
While state of the art object spotting models already highly integrate their detection and recognition steps in one model, text spotting systems still separate these two classification parts in different models. This architecture of separated modules allows us to create clear interfaces between the required modules of the pipeline and hence we are able to easily exchange classifiers without any modifications of other components of the pipeline. The figure below illustrates the complete processing pipeline receiving an edge detected image of the relevant VRD page as input:
- The region of interest extractor (RoIE) extracts the part depicting the VIN and passes it to the sliding window module which divides the image into many little windows of the same size.
- The character detector subsequently decides for each window whether or not the window depicts a character.
- The positive candidates are then passed to a non-maximum suppression module, which rejects redundant windows of a certain region and only allows one window per character.
- As a final step of the pipeline, the character recognizer classifies each window into one of the 36 classes representing the capital letters A to Z and the digits 0 to 9.

Dataset
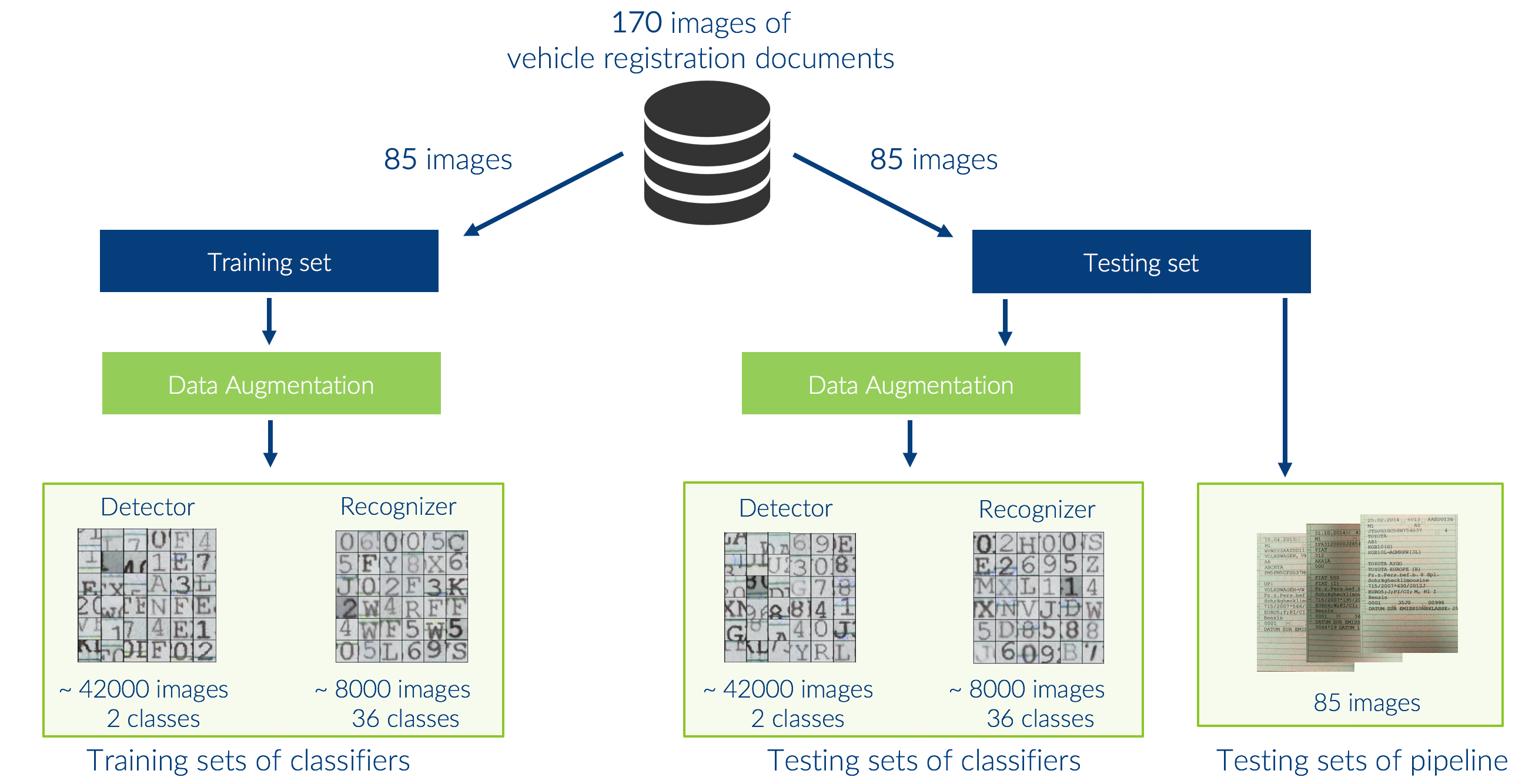
As mentioned above, we wanted to compare different deep learning models when solving the tasks of character detection and character recognition. However, when we started this work, we had only ten images of VRDs available, which is why we needed to find a way to collect more images. For this reason we developed an Android app allowing us to take pictures of VRDs and to save them on a server. The app displays a frame in which the relevant page of a VRD should be placed when taking the photo. After the photo is taken, the app crops the image so that only the page depicting the VIN is shown in the image. This procedure allowed us to collect standardized images of VRDs so that no further edge detection of the document was necessary. With this app and the help of many supporters, we were able to collect 170 photos of VRDs.

Since 170 images are not a lot when training deep neural networks and we still wanted to ensure that the models perform well on unseen data, we chose to split the dataset into two equal parts, each with 85 images. We then performed a data augmentation on the 85 training images in order to create one training set for the character detector and one for the character recognizer. Furthermore, we performed a data augmentation for the 85 test images since this allows us to evaluate the models in an isolated context. Additionally, we also kept complete images of VRDs to evaluate the performance of the end-to-end text spotting pipeline. This process of generating the datasets used for training and testing is illustrated in the following figure.
Using Generative Adversarial Networks for semi-supervised Learning
In general, supervised classifiers need as many labeled examples as possible to train well. Since we had to label all 170 VRD images on our own, we could not be sure that the amount of images we label was sufficient to let our supervised classifiers detect and recognize characters with satisfying results. Therefore, we also used a semi-supervised approach called Generative Adversarial Network (GAN) as a classifier, which is able to enrich its database by generating realistic images. In that way, a GAN can also learn well with a small amount of labeled data. GANs were introduced by Goodfellow et al. (2014) and due to their novel approach of training neural networks, they have raised a lot of attention in recent years. Yann LeCun, one of the deep learning fathers and Facebook’s AI research director said about GANs:
„There are many interesting recent developments in deep learning. The most important one, in my opinion, is adversarial training (also called GAN for Generative Adversarial Networks). This, and the variations that are now being proposed is the most interesting idea in the last 10 years in ML, in my opinion.“ LeCun (2016)
Generally, GANs consist of two neural networks competing against each other: Generator G and discriminator D. While G attempts to fool D by producing fake samples which imitate real samples as good as possible, D tries to distinguish between real samples and samples generated by G. As feedback during the training process, G uses the score of fake images assigned by D to improve its ability of creating realistic images, whereas D uses the origin of the images (real dataset or generator) to calculate its classification loss. In that way both neural networks improve their skills by interacting with each other.
While setting hyperparameters correctly is already a challenge in standard neural networks, it is remarkably more difficult to find good parameters when training GANs in order to create a fertile environment for G and D. Therefore, it is crucial to understand that the competition between both players must be balanced during training in order to ensure a stable learning process. If one player is much stronger than the other, the weak player will not be able to learn anything. In that case, also the stronger player stays relatively weak, as it is not challenged by its opponent. Soumith Chintala provides a great overview of techniques and tools to stabilize the training of GANs in his talk at the NIPS 2016.

When GANs are used for image processing tasks, a normal CNN can be used as discriminator while the generator consists of many convolution transpose layers assuring the creation of images from literally a vector of noise. If you want to learn more about convolution transpose layers, please visit this excellent blogpost. By making some small adaptations in the GAN’s discriminator loss and its output layer it is not only able to perform this binary classification between fake and real, but it can also perform a normal classification task classifying images into N classes. This allows us to train D as a semi-supervised classifier and to enable a GAN to simultaneously train D in two different tasks using three sources of information: real labeled images, real unlabeled images and fake images. In this way, semi-supervised GANs can learn highly efficiently with only a small amount of labeled data.

Performance evaluation
To compare the performances of the GAN with the CNN on different amounts of labeled training images, we created eleven sub training sets for both tasks. The detector´s sub training sets ranged from 20 to 42000 images while we used 36 to 8000 images in the recognizer`s sub training sets. However, the semi-supervised network also receives a varying amount of unlabeled images in addition to the labeled images. This amount depends on the size of labeled images used for training as we always feed the complementary part of the original training set into the network as unlabeled examples. For example, when training a discriminator in a semi-supervised GAN as a character detector with 200 labeled images, 41800 (42000-200) images are used as unlabeled examples. In that way, a semi-supervised GAN always uses the complete training set during training, while only a portion of it is labeled. Please note, the compared models have exactly the same architecture except for some minor modifications in the loss formulation allowing to train the GAN in a semi-supervised way.
As we can see in the graphs depicting the performances of the models, both models perform significantly better when trained on a larger training set. This is due to the fact that the models are able to analyze larger amounts of variations within the images as the training set increases. Furthermore, the semi-supervised GAN clearly outperforms the CNN when trained on small training set sizes. For example when detecting characters the GAN is able to classify 88.5% of the test set correctly, being trained with only 20 labeled images. However, the CNN only achieves an accuracy of 63.27% on the same training set. Also, when trained on the small sub training sets in the recognition task the semi-supervised GAN outperforms the CNN sets by far. When the full training sets with 8000 and 42000 images are used for training the two tasks, both models achieve a 99.8% accuracy in the detection task and in the task of character recognition they are even able to classify all test images correctly. These experiments show that the semi-supervised GAN is able to use the share of unlabeled images to improve its classification skills significantly, leading to a strong boost of the classification performance especially when trained with a small amount of labeled data.

After conducting these experiments, we inserted a trained detection and recognition model into our pipeline in order to evaluate its performance on complete images of VRDs. For the evaluation we used 85 images of the relevant VRD page illustrating the VIN. The pipeline misclassified only one single image depicting a “U“ as “0“, resulting in a total accuracy of 99.94% over all images. However, the misclassification is only due to a lack of training images as the class of “U“´s only contains 14 images and is by far the class with the least training examples.
Outperforming Google Cloud Vision
After we showed that the text spotting pipeline is able to achieve a 99.94% accuracy on the test set, we also tested the performance of the pipeline against a commercial OCR tool. There are multiple well performing commercial OCR tools on the market including ABBY, Microsoft Azure Machine Vision API and Google Cloud Vision API. We chose to use Google Cloud Vision API for an extensive comparison as it performed best on several trial examples and is easy to access on a larger scale. The Google Cloud Vision API is a commercial service allowing developers access to powerful recognition models via a restful interface. The API can solve several tasks like face recognition, object spotting, recognition of explicit content, recognition of touristic places and text spotting without any further preprocessing steps by the user.
The response of Google’s service did not always include 17 characters as it was not able to recognize every character in all images. Therefore, we used the Levenshtein distance for the comparison between our pipeline and Google Cloud Vision API. The Levenshtein distance is a string metric measuring the difference between two strings. It calculates the minimum amount of editing operations (deletion, replacement and insertion) needed to transform one string into another and hence it can be used to compare two strings of different lengths. As we are comparing a classification with the true label, a low Levenshtein distance is desired when measuring the performance of a classifier.
After receiving the classifications for all 85 test images, we calculated the average Levenshtein distance between the corresponding label of the image and the classification provided by Google Cloud Vision API. The average Levenshtein distance is 4.45, meaning that in average 4.45 operations like insertion, deletion or replacement are required to transform the provided classification into the corresponding label. Our pipeline on the other hand made only one misclassification in all test images, corresponding to an average Levenshtein distance per image of 0.011. This comparison shows that the recognition of text is not trivial for general OCR tools when the text is distorted by background structures and when lines are crossing the text. In this case, a customized text spotting pipeline is necessary which can be trained on these images and thus is able to ignore these particular distortions.

Conclusion
We have seen in this article that although OCR already has a long research history, it is still not at the end of its development. When required to find and recognize text in a regular image, the problem is significantly more challenging than reading text in plain scanned documents as the text appears at different positions, scales and lighting conditions. In many cases, commercial solutions already provide good results in these text spotting tasks. However, when the text is distorted as it was in our use case, an end-to-end text spotting pipeline trained on this specific task is able to outperform general commercial solutions by far.
Furthermore, we showed that GANs already deliver remarkable results in the area of semi-supervised learning as they are able to significantly outperform CNNs. This is especially useful in use cases suffering from a lack of labeled data since GANs are able to extract a lot of knowledge from unlabeled data. If you want to learn more about the architecture of semi-supervised GANs, please visit this recently published blogpost. The ability of learning in a semi-supervised way and the fact that a GAN’s generator is able to introduce creativity to machines, are the reason why GANs are one of the hottest topics in deep learning today.
[1] Reinsel, D., Gantz, J., and Rydning, J. (2017). Data Age 2025: The Evolution of Data to Life-Critical. In International Data Corporation (IDC)



Great Article! I am doing a project on same thing, please help me to understand it more by providing the code implementation of character detection using GAN.