
Notice:
This post is older than 5 years – the content might be outdated.
Ever since Amazon released AWS Lambda in 2014, the term Serverless Architecture has made its way to popularity amongst the tech community. The concept had already been around before and was mainly used to describe applications that made heavy use of or fully depended on the rich ecosystem of cloud services, specifically databases like Parse or Firebase. The promise of the new Serverless, also often referred to as Function-as-a-Service (FaaS), is to execute your code without the effort of managing and scaling servers while still paying less money.
In my Bachelor’s Thesis, I specifically looked at AWS Lambda, comparing it to the more traditional approach of hosting applications on Amazon’s EC2 service. I wanted to find out how common practices of software development, cost, performance and scalability are affected by moving from hosted virtual machines to Serverless.
How Serverless Architecture works
A common misconception about the term Serverless is that no servers are required anymore. This is not the case. Applications are still executed inside of virtual machines, in fact, AWS Lambda functions are hosted on the Amazon EC2 platform behind the scenes. Instead of constantly running servers, however, AWS Lambda starts virtual machines within milliseconds in response to pre-configured events. There is no document describing how AWS Lambda is really implemented but luckily there is a comparable open source implementation called Apache OpenWhisk. If you want to know how serverless platforms work in detail, you can read about it in this fantastic blog post.
Comparing AWS Lambda to Amazon EC2
As I said before, Serverless Architecture does not mean that there are no servers. What the term really means is outsourcing operational work to a third party, in this case of course—Amazon. This can be a good thing or a bad thing, depending on the individual case. In the best case, AWS Lambda can improve deployment speed and reduce costs for operational work. But giving up control also means relying on the third-party to work correctly, accepting less visibility, flexibility and giving up the ability to fix things yourself. Using Amazon EC2 is the opposite approach. The AWS ecosystem provides developers with all the necessary tools to build secure, scaling, high performance applications, but it requires knowledge and a time investment by development team. In return, developers gain the freedom of choosing the technology stack, visibility and control of the system and a Service Level Agreement (SLA) concerning the availability of the platform. In order to get a better idea of the differences, I looked at some of the key aspects of software development.
Development
AWS Lambda encourages a stateless and platform-agnostic programming style since there are no guarantees about resources being available beyond execution time and the underlying compute infrastructure. For the sake of simplicity and scalability, the service limits various things for the developer:
- The use of native libraries is complicated by the fact that AWS Lambda puts a limit of 50 MB on the maximum size of the deployment package.
- Code cannot be shared between different handlers.
- In-memory caching is only possible if the container is reused, which is unreliable.
- There is a five minute limit on the execution time.
- Maximum memory allocation is currently limited to 3008 MB.
- Programming languages are restricted to specific versions of Java, Python, JavaScript, C# and Go.
Deployment
Deploying a single AWS Lambda function requires packaging the application in a deployment package and uploading it to the service. The process of packaging applications differs slightly depending on the programming language used but is generally quick and easy. As opposed to Amazon EC2, AWS Lambda does not require choosing an instance type, deploying an AMI, writing provisioning scripts or defining security and autoscaling groups. But of course there are some limitations as well:
- It is not possible to run AWS Lambda on a dedicated instance.
- There is no way to deploy multiple functions atomically. This means that during an update of logically grouped functions, there might be a short period where one endpoint is ahead of the other.
- Deploying applications that make use of native libraries requires pre-compiling the library and packaging it with the deployment package.
Both AWS Lambda functions and Amazon EC2 instances can automatically be deployed using AWS CloudFormation or third-party tools like Terraform. For serverless applications, there is an extension to AWS CloudFormation called AWS SAM which can be used to describe resources for serverless applications more conveniently.
Testing Serverless Architectures
AWS Lambda functions can be unit tested like any other code. In order to do this effectively, writing code in a testable manner is key. The idea is not to test the handler function itself but to define functions in a vendor-independent manner so that they can be tested individually. AWS provides a tool for running AWS Lambda locally, called AWS SAM Local.
While ensuring that written code behaves the way it was intended to, most applications in a cloud environment rely on various other services, such as databases, message queues, etc. Ideally, it would be possible to launch an environment similar to the AWS cloud locally, with all services available for integration testing. There is a promising project called LocalStack which tries to achieve exactly this. In order to make sure the application behaves similarly to the real cloud environment, it would, however, be necessary that Amazon provides a tool like this of their own.
Logging, Monitoring & Debugging
Logs and metrics from AWS Lambda are gathered in Amazon CloudWatch. They can be accessed through the AWS console or by using the Amazon CloudWatch API. Contrary to Amazon EC2, it is not possible to access logs directly. The Amazon CloudWatch API can be used to make logs available elsewhere, e.g. ElasticSearch. This, however, leads to additional costs and is highly specific to the vendor.
AWS Lambda only exposes four metrics: Duration, Throttles, Errors and Invocations. Amazon EC2, on the other hand, offers a lot more insight into the system, providing metrics about CPU utilization, disk reads, writes and network traffic. Debugging AWS Lambda applications remotely is not possible. AWS intentionally blocks ptrace system calls to prevent debugging. For Node.js, however, there is a project that attempts to solve this issue.
Cost Analysis
The cost of running an AWS Lambda function depends on the configuration and execution time of the function. There are fixed prices per 100 ms depending on the chosen memory size. After a function has finished, its execution time is rounded up to the next 100 ms and billed accordingly. For example, if a function is assigned 256MB of RAM and executes for 3.12 seconds, the price is calculated like this: ceil(3120/100) ∗ $0, 000000313 = 0.00010016.
Since October 2nd, 2017 billing for Amazon EC2 instances is calculated per second, with a minimum of 60 seconds. Prices are still listed hourly, but bills are calculated down to the second. For example, an Amazon EC2 instance of type c4.large costs 0.114$ per hour or $0.114/3600 = $0.000031667 per second. Consequently, the price for an Amazon EC2 instance of type c4.large is calculated like this: ceil(3.12) ∗ $0.000031667 = $0.000126668.
The main disadvantage of Amazon EC2 is, however, that servers need to be running in order to be reachable. With AWS Lambda, billing only applies when the code is executed—this is one of its major advantages.
Performance & Scalability
AWS Lambda performance is measured similar to EC2 Compute Unit (ECU), in that doubling the memory size also doubles the CPU capacity. In contrast to Amazon EC2 there is no notion of vCPUs. While there are different instance types for individual use-cases on Amazon EC2, like memory or compute-intensive tasks, AWS Lambda does not offer this kind of flexibility. From this perspective, AWS Lambda is a one-size-fits-all solution.
Conceptually it is not possible to cache data in-memory with AWS Lambda. In reality, containers are frequently reused, enabling developers to cache variables or other valuable resources such as database connections. There is, however, no guarantee for this to happen.
Startup time is crucial when using AWS Lambda since conceptually the application is restarted on each request, similar to a Common Gateway Interface (CGI). Cold start is another concern that is often raised when it comes to performance. On AWS, this problem only occurs after 15 minutes without a request and only when the function is executed inside of a VPC. The problem can be circumvented by issuing keep alive requests periodically.
A major advantage of AWS Lambda is horizontal scaling out of the box. The stateless nature of AWS Lambda enables the service to easily launch hundreds of additional instances. To achieve horizontal scaling with Amazon EC2 instances, auto scaling groups need to be defined and the required capacity needs to be predicted in advance.
Practical Application
Experiment
Using the knowledge from my research, I wanted to see how AWS Lambda compares to Amazon EC2 in a real-world application. At inovex, we have a project that requires us to resize images to different resolutions. When an image is uploaded to an Amazon S3 bucket, a microservice downloads the image, resizes it to the configured resolutions and uploads the results to a different folder of the same S3 bucket. Previously, this was realized by an application running on Amazon EC2 that polled the S3 bucket periodically and processed the images in batches. The application was written with Java and the Spring Boot Framework. Further, the IM4Java library was used to resize the images. IM4Java is an interface to the native GraphicsMagick and ImageMagick library. In our specific case, GraphicsMagick was used.
In my experiment, I migrated the microservice to AWS Lambda to see how it compares with regards to the previously mentioned development practices as well as cost, performance and scalability. I asked myself three simple questions:
- Is it possible to achieve a similar or better performance using AWS Lambda instead of Amazon EC2?
- Can costs in terms of development time and billing be saved by using AWS Lambda instead of Amazon EC2?
- What advantages and disadvantages with regards to development, deployment, testing and monitoring exist?
To answer these questions, I defined various metrics that were captured during the execution of both versions. The essential metrics were: download duration, duration of resizing and uploading all images and the overall duration. For each execution, these metrics were stored in Amazon DynamoDB.
I compared three AWS Lambda functions configured with 512 MB, 1728 MB and 3008 MB memory size respectively and one Amazon EC2 instance of type c4.large.
Results
Development
Moving the microservice to AWS Lambda required some changes: I had to remove the Spring Boot Framework and replace built-in features, such as the instantiation, injection and configuration of Spring Beans by simple singleton classes to save time during startup. I also had to replace IM4Java with Thumbnailator, because AWS Lambda dropped the support for ImageMagick and packaging either of the native libraries inside of the deployment package was not possible due to the size restrictions.
Deployment
Building and uploading the AWS Lambda deployment package was very fast and accelerated the process of making changes. Some time went into configuring the minimum memory size requirement, by increasing it gradually and checking the logs for errors and execution time. I automated the deployment by using Terraform.
Performance and Cost
By copying all uploaded images from the Amazon S3 bucket of the application to my own S3 bucket for about one hour, 2529 uploads were captured. Replaying these events onto all four services produced 10070 entries in Amazon DynamoDB.

The figure shows a plot of the average overall execution time. As you can see, the lowest memory setting took about one second longer than the c4.large instance. Most notably, the AWS Lambda function configured with 1728 MB memory size was almost twice as fast as the Amazon EC2 instance on average. Increasing the AWS Lambda memory size to the maximum did not have a significant effect anymore.
The average cost of resizing an image can be calculated by using this formula: overallCost = ceil(timeInMs/100) ∗ costPer100ms and the AWS Lambda list price:
| Memory Size | Cost (per 100ms) |
|---|---|
| 512 MB | $0.000000834 |
| 1728 MB | $0.000002813 |
| 3008 MB | $0.000004897 |
In order to get a decent estimation of the average cost per day, I considered the number of uploads per day over the course of a week.
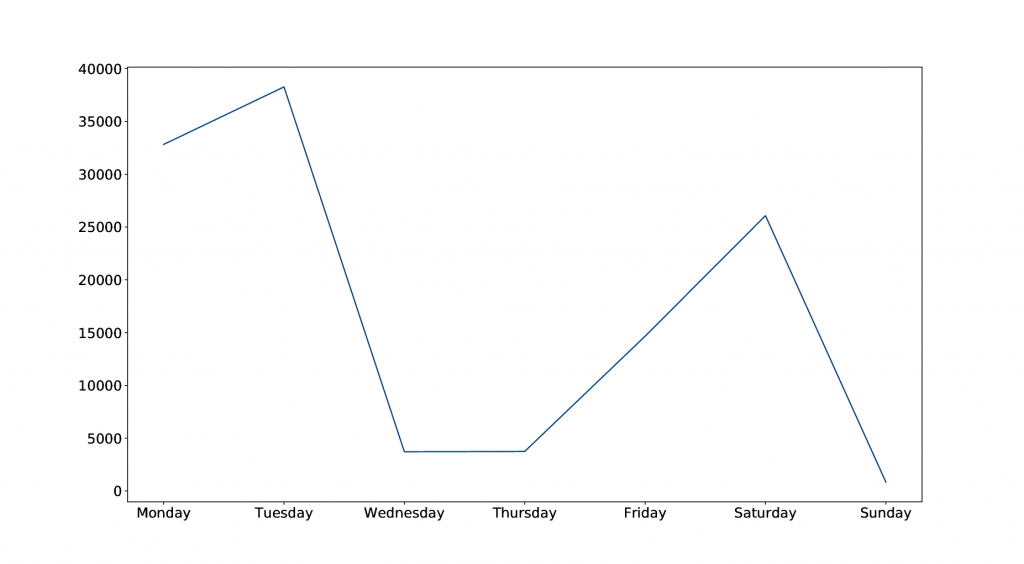
As the figure shows, the distribution of uploads was very uneven. Assuming that other weeks have similar upload numbers, the average can be used to calculate the average daily cost and estimate a yearly cost. The corresponding price for the Amazon EC2 service can be calculated by multiplying the hourly price by the number of hours the service would be running. It is worth mentioning that this price was calculated for one Amazon EC2 instance and in practice, the price could potentially be higher due to upscaling.
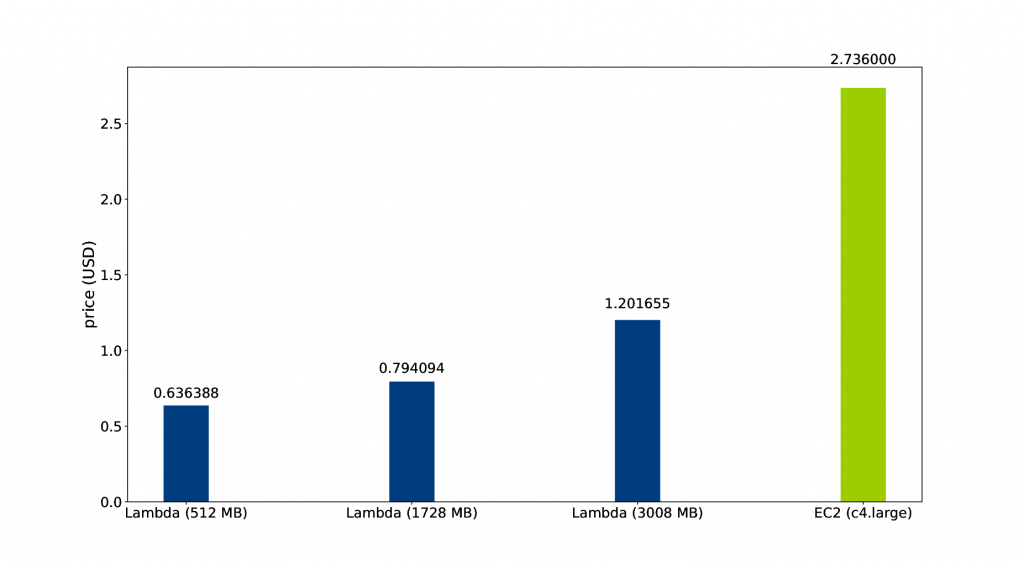

As shown, the price of running the image scaler service on Amazon EC2 was substantially higher than running any of the AWS Lambda functions. This is mainly caused by the inactivity of the Amazon EC2 service during the periods without any uploads.
In this specific case, approximately 708 USD could be saved per year by using AWS Lambda instead of Amazon EC2, when using a memory size of 1728 MB.
In terms of development time, the costs are highly dependent on the familiarity with the different technologies and the project in general. For a developer less experienced with operational tasks, such as defining security groups or provisioning a virtual machine, using AWS Lambda can save a lot of time during deployment. Even though some code changes had to be made, the time for adjustments was relatively low compared to the time it took to deploy the Amazon EC2 instance.
Conclusion
My comparison showed that using AWS Lambda is about outsourcing operational work to the cloud provider. This comes with the benefit of requiring less expertise about operations but comes at the cost of less visibility, flexibility and control. The experiment showed that developing AWS Lambda functions is easy when the task fits the AWS Lambda programming model. This programming model provides that functions are executed in response to events, stateless, platform agnostic and short running. Trying to go beyond these boundaries, for example by using certain native libraries or having complex dependencies between several handlers, can easily mitigate the advantages of the service by increasing time that needs to be spent on working around the services limitations.
The future use of AWS Lambda highly depends on Amazon’s efforts to provide additional capabilities for the service: Remote debugging, local integration testing and less memory limitations are a few examples.


