
Notice:
This post is older than 5 years – the content might be outdated.
Web sources such as social networks, internet forums, and user reviews, provide large amounts of unstructured text data. Due to the steady development of new platforms and the increasing number of internet users, the interest in methods that automatically extract discussed topics in text data has increased in recent years. Organizations and scholars from different fields can utilize such methods to identify patterns and generate new insights. Examples are opinion researchers investigating current opinions on political and societal issues, consumer researchers interested in consumer beliefs about the consumption and production of goods, and marketing managers curious about the public perception of their products and services.
Existing unsupervised methods to detect topics such as clustering and topic modeling represent topics as clusters or word lists (e.g., Blei et al., 2003; Chen et al., 2014). This information is often insufficient to get a comprehensible topic overview because words can be used in different contexts. Moreover, resulting word lists are often incoherent and consist of loosely related words. Additional information, like representative sentences, initial topic labels, and topic correlations, is necessary to gain a deeper understanding. Therefore, I developed a new user-friendly visualization and labeling toolkit called SocialVisTUM as part of my master’s thesis. SocialVisTUM enables users to get a quick and comprehensible visual overview of topics and topic relations for any English text corpus and can be accessed online. Moreover, a variety of features can be used to customize the visualization and change initial topic labels. To exemplify the usage and show one possible use case, let’s test it on a new data set that consists of user comments about organic food. We will use a total of 83.938 sentences from the comment sections of articles about organic food from news websites like The Washington Post and the New York Times.
Extracting Topics
We use an existing neural network model (ABAE by He et al, 2017) to extract topics from unlabeled text data. Embeddings (vectors) are used to represent topics and words because the numerical representation allows neural networks to deal with them. Moreover, we can use different notions of similarity, like the dot product and the cosine similarity to compare embeddings and identify possible relations. ABAE uses an attention mechanism (Bahdanau et al., 2014) that learns to focus on the most important words in a sentence. Every sentence \(s \) is represented by a vector \(\textbf{z}_s\) that is defined as the weighted average of all the word embeddings of that sentence. The weights are attentions calculated based on the contribution of the respective words to the meaning of the sentence and the relevance to the topics. The number of topics \(\textit{K}\) must be specified before training. Accordingly, the topic embeddings are initialized as the resulting centroids of k-means clustering on the word embeddings of the corpus vocabulary and then stacked as topic embedding matrix \(\textbf{T} \). During training, ABAE calculates sentence reconstructions \(\textbf{r}_s\) for every sentence. These are linear combinations of the topic embeddings from \(\textbf{T} \) and defined as
The SocialVisTUM Toolkit
Figure 1 shows a visualization for the organic food data set created by the SocialVisTUM toolkit. Topics are represented as nodes and automatically labeled. The node size increases based on the number of topic occurrences (shown in brackets next to the label). The edges between topics are labeled with the corresponding topic correlation and the link thickness increases with a higher positive correlation. A graph layout based on repelling forces between nodes helps to avoid overlaps, which is especially helpful when many nodes and links are displayed while a second force keeps the graph centered. Moreover, users can move nodes around to get a comprehensible overview.

Topics as Nodes
After training the ABAE model, we receive the probability matrix \(\textbf{P}_t\), which contains the probability vectors of every sentence. Each vector entry corresponds to the probability that the input sentence belongs to the associated topic (an example is shown in Table 1). We assign every sentence to its most likely topic based on \(\textbf{P}_t\) and then iterate over all sentences in the data set to count the number of topic occurrences. The number of topic occurrences is helpful to give an estimation of the topic importance because frequently discussed themes are usually more important as well.
| Sentence | GMO | Diseases | Organic |
| „GMO food is bad“ | 0.7 | 0.2 | 0.1 |
| „GMO food causes chronic diseases“ | 0.45 | 0.45 | 0.1 |
| „Organic food is healthy“ | 0.1 | 0.1 | 0.8 |
Topic Correlations as Edges
To calculate topic correlations, we iterate over all sentences in \(\textbf{P}_t\) and calculate the Pearson correlation between the probability values of each topic. Thereby, we receive a value in the range of [-1; 1] for every topic combination that specifies the relation between topics. Table 1 shows a small example of \(\textbf{P}_t\) with the associated correlations in Table 2. GMO and Diseases co-occur and are positively correlated indicating that people often discuss diseases in the context of GMO. Because the topic Organic is unlikely to occur when either GMO or Diseases is discussed, it is dissimilar to both.
| GMO | Diseases | Organic | |
| GMO | 1 | 0.37 | -0.91 |
| Diseases | 0.37 | 1 | -0.72 |
| Organic | -0.91 | -0.72 | 1 |
Hiding Insignificant Topics
In our tool, an occurrence threshold slider defines the percentage of sentences that must be about a topic in order to display the associated node. Another slider can be used to set the correlation threshold to define the required positive and/or negative correlation to display the associated connections. These sliders (see Figure 2) are especially helpful to maintain a clear visualization by limiting the number of shown topics and connections when many of them are available.
Topic Inspection
Users can double-click a node to receive additional information about one topic. Afterwards, only nodes that are connected to the clicked node and the associated links are displayed. Moreover, the most similar words (see Figure 2 on the left) and sentences (see Figure 2 on the right) to the topic are shown. Since topic and word embeddings in ABAE share the same dimensionality, we can calculate the cosine similarity between each topic and every word embedding in our vocabulary. Then, we can use the 10 most similar words to represent each topic, similar to the way traditional topic models like LDA (Blei et al., 2003) represent topics as word distributions. As representative sentences, we select the sentences with the highest probability for each topic based on \(\textbf{P}_t\). Representative sentences are helpful because they put representative words into a context, which helps to understand the underlying theme. To see all nodes and links again, the user can either double-click the same node again or double-click any other node to focus on it instead.

Automatic Topic Labels
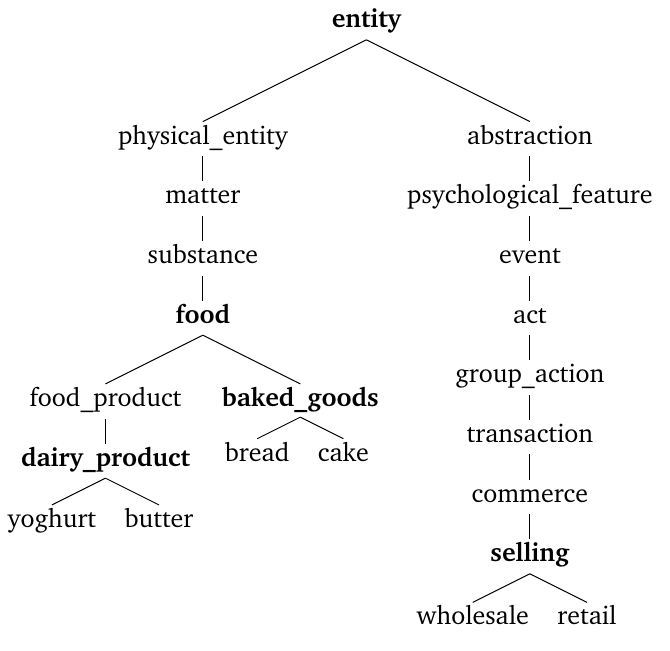
We use a new approach to label topic nodes automatically because the most similar word rarely serves as a suitable topic label. Initial topic labels are useful because they give users an immediate impression of each topic and eliminate the need to manually inspect representative words and sentences to come up with suitable labels. The labeling approach is based on shared hypernyms, which we identify using representative words and the lexical database WordNet (Miller, 1995). Hypernyms are words whose meaning includes the meaning of other words (hyponyms). For example, the word dairy product is a hypernym of the hyponyms yoghurt and butter because they are both dairy products.
First, we retrieve the hypernym hierarchy for every representative word (see Figure 3) and compare the representative word with every other representative word of the same topic. Next, at each comparison, we save the shared hypernym with the lowest distance to the compared words in the hypernym hierarchy. We only consider hypernyms if their distance to both words is smaller than half the distance of the word to the root hypernym to avoid unspecific labels like entity and abstraction. Then, we use the hypernym that occurs most often as topic label. If no hypernym can be identified, we use the most representative word instead. In the example shown in Figure 3, we identify dairy product as lowest shared hypernym of yoghurt and butter and food as lowest shared hypernym of yoghurt and bread. Although the root hypernym entity is a shared hypernym of the words yoghurt and wholesale, we do not save it because we only consider hypernyms with a distance smaller than 3.5 (half the distance to the root hypernym) for yoghurt and 4.5 for wholesale.
The quality of the shared hypernym chosen as topic label can be approximated by inspecting the number of its hypernym occurrences (shown in Table 3). Topic labels that occur frequently as shared hypernym are usually suitable (e.g., animal (102) and compound (91)) in contrast to topic labels that occur rarely (e.g., group action (9) or smuckers (0)). Thus, we can use the number of hypernym occurrences of each topic to estimate the topic coherence for hyperparameter optimization.
| Topic Label | Representative Words | Number of Hypernyms |
| animal (102) | insect, ant, habitat, rodent, herbivore | 218 |
| compound (91) | amino, enzyme, metabolism, pottasium, molecule | 158 |
| chemical (74) | fungicide, insecticide, weedkiller, preservative, bpa | 131 |
| systematically (0) | systematically, adequately, cleaned, properly, milked | 0 |
| smuckers (0) | smuckers, afterall, plz, assoc, fearmonering, 100x | 0 |
Changing Labels
To change the label of a topic, the user can click on the associated label of a node. Thereby, a prompt is opened and the user can insert a new topic label. The user can download a JSON file with the updated labels by clicking on the Create file button on the sidebar (Not shown in the screenshot for lack of space).
Hyperparameter Estimation
ABAE has multiple hyperparameters, such as the number of topics and the vocabulary size, which are crucial for the performance. Our objective is to receive topics that are as meaningful (coherent) as possible. The average coherence score (ACS) is usually used to estimate the topic quality. It compares the number of times two representative words co-occur with the number of times each word occurs overall.
One problem of the coherence score is that coherent topics are not necessarily represented by words that frequently co-occur. As an example consider a topic that has a set of synonyms (e.g., food, meal, dinner) as most representative words. This topic is very coherent because it describes one specific theme but produces a low coherence score because synonyms rarely co-occur in the same sentence. Moreover, the coherence score usually increases based on the vocabulary size (see Table 4) because a large vocabulary tends to result in very specific representative words. Although this sounds like the desired outcome, most representative word lists consist of words with multiple spelling mistakes or rare abbreviations. Therefore, topics can not be interpreted adequately and no good labels can be identified because no words with misspellings are defined in WordNet. The ACS also increases based on the number of topics (see Table 4) although a larger number of topics leads to disproportionately many incoherent topics for our data set.
To solve these issues we define and use a new metric, the average number of shared hypernyms (ANH), to identify suitable model parameters. To calculate the ANH, we first derive all shared hypernyms and their respective occurrences for each topic as done during the automatic topic labeling. Then, we define the ANH as the sum of hypernym occurrences over all topics divided by the number of topics. In contrast to the ACS, the ANH works well for synonyms because synonyms usually share hypernyms and thus result in a high ANH. Moreover, the ANH does not necessarily increase with higher vocabulary size. Using the ANH we found out that a medium-sized vocabulary (about 10.000 words) produces the most coherent topics, which is in line with the manual topic inspection by domain experts. As opposed to ACS, an increasing number of topics does also not necessarily increase the ANH. Table 4 shows an excerpt of the results for varying parameters.
| Number of Topics | Vocabulary Size | Average Coherence Score (ACS) | Average Number of Hypernyms (ANH) |
| 5 | 1.000 | -1104 | 28.6 |
| 10.000 | -765 | 68.0 | |
| 18.000 | -403 | 5.2 | |
| 15 | 1.000 | -366 | 33.3 |
| 10.000 | -270 | 40.0 | |
| 18.000 | -197 | 33.8 | |
| 50 | 1.000 | -110 | 30.4 |
| 10.000 | -70 | 51.8 | |
| 18.000 | -54 | 49.7 |
Conclusion
We implemented the SocialVisTUM toolkit to give organizations and scholars a quick and comprehensible visual overview of discussed topics in text data. SocialVisTUM can be used for any unlabeled English text corpus and displays relevant topic information in a force-directed graph. To give a detailed topic overview, we extended an existing method to extract topics (ABAE) and generated additional topic information in the form of representative sentences, topic labels, topic occurrences, and topic correlations. Moreover, users can dynamically adjust relevant parameters like the required number of topic occurrences and topic correlation to customize the visualization created by SocialVisTUM. Users can also show or hide topic information by double-clicking on topic nodes and change initial topic labels. To detect coherent topics, we introduced a new metric, the average number of shared hypernyms (ANH), that can be used to identify suitable hyperparameters and measure the quality of topics and topic models.
Sources
- Blei et al., 2003: Latent Dirichlet Allocation
- Chen et al., 2014: Aspect Extraction with Automated Prior Knowledge Learning
- He et al., 2017: An Unsupervised Neural Attention Model for Aspect Extraction
- Bahdanau et al., 2014: Neural Machine Translation by Jointly Learning to Align and Translate
- Miller, 1995: WordNet: A Lexical Database for English


