
Are you familiar with the problem of long and complex privacy policies that nobody has the time or energy to read? And are you interested in the latest deep learning models from the field of Natural Language Processing (NLP)? Then this is the right article for you.
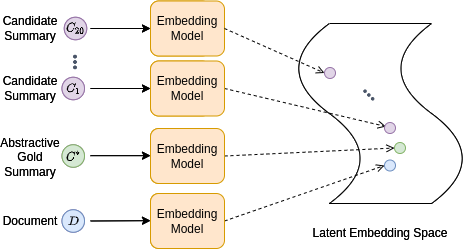
To shorten privacy policies, we develop an automatic summarization system by leveraging the state-of-the-art extractive text summarization approach MatchSum [1]. In extractive summarization – in contrast to abstractive summarization – the sentences of the source document are not changed, so the content is not altered, which is desirable for the privacy domain. Thus, we apply the MatchSum approach to this domain by combining it with PrivBERT [2], a domain-specific pre-trained version of the RoBERTa transformer model [3] which itself is an optimized version of BERT [4]. Furthermore, as there are currently no dedicated summarization datasets for the privacy domain, we filter out those articles from the CNN/DailyMail corpus that are related to the privacy domain and use over-sampling techniques for text data to increase the number of training samples. As a pre-processing step, we classify privacy policy texts into privacy practices, again leveraging the PrivBERT model. This limits the input length of our extractive summarization system and allows users to skip categories they are not interested in. The figure below illustrates our approach:

The ROUGE Score
Before we detail our approach, we have to shortly describe how the quality of summaries can be assessed automatically. Here, the ROUGE-N score is the standard metric used in the literature. It measures the overlap of N-grams between the source document and a summary. For example, in the figure below, one can see how the ROUGE-1 score measures how many 1-grams, i.e. word tokens, are present in the model output and the reference text:

To grasp different overlap levels, we use the mean of the ROUGE-1, ROUGE-2 and ROUGE-L scores where the ROUGE-L score measures the longest common subsequence of the source document and the summary. This score is easy to implement and useful if abstractive gold summaries (i.e. human-made summaries whose sentences differ from the original document) are available in the dataset.
Text Summarization with Metric Learning
The guiding idea of most summarization approaches in recent years has been to classify sentences in a source document into binary categories to decide whether or not to include them in the summary. This paradigm leads to systems that optimize at the sentence level rather than comparing whole summaries as such. This is why MatchSum is moving towards transforming texts into an embedding space where it is possible to measure their similarity with geometric measures, such as the cosine similarity.
As the output embeddings of transformer models are not suitable to calculate such measures by default, MatchSum uses metric learning, more specifically a triplet loss, to fine-tune RoBERTa embeddings for this task. In general, a triplet loss consists of an anchor, a positive and a negative sample, where the distance between the anchor and the positive should be smaller than the distance between the anchor and the negative. In the case of text summarization, for example, the anchor consists of the source document embedding, the positive of an embedded human-made abstractive gold summary, and the negative is the embedding of any less appropriate summary.
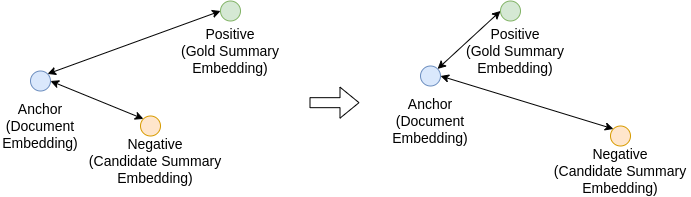
This triplet loss is combined with a Siamese network structure which means that the same network is used for calculating the different embeddings [5]. Thus, during inference different summaries can be compared by calculating the cosine similarity between their embeddings and the embedding of the source document. The summary with the highest cosine similarity can then be considered the best.
One difficulty that remains, is the high number of candidate summaries that we can derive from a source document. From \(n\) sentences and a given summary length of \(k\) sentences, one could build \(n\) over \(k\) potential summaries. For long documents, it would take too much time to embed all these texts. Therefore, during training, the number of possible summaries is limited by our text summarization dataset itself to 20 summaries. During inference, we use text classification as a pre-processing step to decrease the number of input sentences and thus the number of candidate summaries.
Privacy Policy Classification
To classify text segments of privacy policies into privacy practice categories, we use the OPP-115 corpus. This dataset contains 115 privacy policies split into 3,792 text segments which are labeled with one or more of the following categories:
| Categories of OPP-115 |
|---|
| First Party Collection/Use |
| Third Party Sharing/Collection |
| User Choice/Control |
| User Access/Edit/Deletion |
| Data Retention |
| Data Security |
| Policy Change |
| Do Not Track |
| International/Specific Audiences |
| Introductory/Generic |
| Privacy Contact Information |
| Practice Not Covered |
We train the PrivBERT model together with two linear top layers (which we will call PrivBERTClass) on this dataset using the Binary Cross Entropy loss for multi-label classification [6] which measures the entropy between the true label and the predicted class probabilities. PrivBERT itself is an in-domain language model which is based on the RoBERTa transformer model. Similar to BERT and RoBERTa, it is pre-trained with a masked-language modeling task on a large unlabeled set of over a million privacy policies making it a promising model for our task.
As the model complexity of PrivBERT is very high, it overfits the training data with its default parameter settings. To reduce the model complexity, we prune half of its top layers and “freeze“ the remaining weights, i.e. we exclude them from training [7]. Thus, we only train the two linear top layers, the last of which has 12 output neurons to produce the multi-label output. In the following table we compare our results with several baselines, including a Support Vector Machine with TF-IDF and Word2Vec features, and an XLNet-based model [8] which sets the current benchmark for this task:
| Precision Micro | Precision Macro | Recall Micro | Recall Macro | F1 Micro | F1 Macro | |
|---|---|---|---|---|---|---|
| SVM+TFIDF | 0.804 | 0.795 | 0.747 | 0.661 | 0.775 | 0.710 |
| SVM+Word2Vec | 0.750 | 0.741 | 0.623 | 0.552 | 0.680 | 0.622 |
| XLNet | nr | nr | nr | nr | 0.86 | 0.81 |
| PrivBERTClass | 0.891 | 0.871 | 0.812 | 0.730 | 0.850 | 0.787 |
As one can see, the PrivBERTClass model outperforms the baselines and achieves comparable results to the benchmark. However, since XLNet has a similar model complexity as RoBERTa, overfitting is likely here. After classifying each text segment of a privacy policy, we order these segments based on their classes and compile them into class-specific texts which we use as input for our summarization system.
Privacy Policy Summarization
Given a privacy policy text with \(n\) sentences (e.g. the class-specific snippets from the classification step), we calculate the summary length \(k\) as \(k = r \cdot n\) where we call \(r\) “compression ratio“. We combine all possible ordered tuples of \(k\) sentences from the original \(n\) sentences into potential summaries. As described above, we then embed the original texts and all summaries with a custom model, that we call PrivBERTSumm, and calculate cosine similarities between the summary embeddings and the original text embedding. Finally, our output summary is the one where this cosine similarity is maximal:
\(\hat{C}=\underset{C_i}{argmax}\big(cosine\_sim(h_{C_i},h_{D})\big)\)
where \(C_i\) denote candidate summaries, \(\hat{C}\) the best summary and \(D\) the original policy. We now describe how exactly we train our summarization model PrivBERTSumm, starting with the description of the dataset we use.
Dataset Compilation
There are several general extractive summarization datasets, all of which are not suitable for the privacy domain (e.g. medical data or Reddit posts). This is also true for the CNN/DailyMail corpus which contains over 300,000 articles from CNN and Daily Mail collected from the years 2007 to 2015. However, in general, the level of formality of the language used in the articles is comparable to our domain. Thus, by searching for articles whose topic is related to the privacy domain, we find useful samples for training our model. For this, we extract the most frequent word lemmas and bigrams used in the privacy policies of the OPP-115 corpus by applying the following NLP techniques to the texts:
- Stop-word-removal: removal of words like “and/or“, “he/she/it“, etc. which do not contribute to the content
- Lemmatization: cropping of words to base forms
- Part-of-speech tagging: assigning lexical categories (like “noun“, or “verb“) to words for filtering out names of particular persons or organizations
Then, we intersect the resulting lemma and bigram sets with the lemmas and bigrams of the CNN/DailyMail articles obtained with the same methods and examine how related they are to privacy topics. After determining an appropriate threshold of lemma and bigram overlap, we keep only those articles that have overlaps above the thresholds, which results in a pruned dataset with 2384 samples (0.8 %) of the original corpus. An example is shown below:
“Group claims Google bypassed security to track their online browsing. Action taken over the way Google tracked users of Apple Safari’s internet browser. Appeal court ruling means Google users have the right to sue internet giant. The ruling was a victory for Safari users against Google’s secret tracking.“
As this dataset is rather small for training a deep neural network, we use over-sampling techniques to get more training samples.
Text Over-Sampling
In general, over-sampling refers to synthetically generating new samples by changing existing ones. In the case of text data, this can be done, for example, with random operations like word insertion, swapping, or deletion. Since this results in syntactically incorrect or semantically incoherent texts, we instead search for synonyms of words in the texts and replace the words for which we find synonyms. Therefore, we leverage NLTK’s WordNet which provides a word hierarchy and enables us to derive direct synonym candidates as well as hypernyms, i.e. words belonging to superordinate concepts (for example, “animal“ is a hypernym for “dog“), which we also consider in our search [9].

Based on the paths between the words (the red line in the figure), we can also calculate a path similarity between the different words with WordNet. As this similarity is high for specialized words (e.g. “link“ and “linkage“), we combine this with another similarity value calculated with Word2Vec. Together, these measures provide a viable way to find useful synonyms.
Another over-sampling technique that produces syntactically and semantically correct sentences is back-translation. The idea here is to translate sentences from a source language to another language and re-translate them back to the original one. Depending on the interim language, this produces slightly different output sentences. Therefore, we use 10 languages with many worldwide speakers and, after replacing synonyms, apply back-translation with each of the 10 languages to each text sample. Thus we get a 10-fold increase in the number of training samples, resulting in a dataset with over 20,000 articles.
Summarization Training
With our new, over-sampled dataset we are now able to train our base model which, similar to classification, is PrivBERT. Like MatchSum, we use the triplet loss mentioned above in two ways: for a training sample consisting of an original article, a human-made abstractive summary, and 20 extractive candidate summaries, we calculate the first triplet loss as
\(\mathcal{L}_1(D,C^*,C_i) = \text{max}(0 , f(D,C_i) – f(D,C^*) + \mu_1)\)
for each candidate summary, where the function \(f\) denotes the cosine similarity and \(\mu_1\) denotes a constant margin. Next, we sort the candidate summaries in descending order based on their ROUGE score with respect to the abstractive gold summary. Then, for every pair of summaries \(i\), \(j\) with \(j < i\) we calculate the loss
\(\mathcal{L}_2(D,C_j,C_i) = \text{max}(0 , f(D,C_i) – f(D,C_j) + (i-j)\cdot \mu_2)\)
and, after summing up all the losses, perform gradient descent. Taking into account the triplet loss theory above, this means that we train the model to produce embeddings such that the gold summary embedding is closest to the document embedding, and that each candidate summary embedding is closer to the gold summary embedding the higher its ROUGE score with it.
As in the case of classification, PrivBERT’s default architecture overfits the training data because of its high parameter number. Therefore, we construct the summarization model, PrivBERTSumm, by pruning half of the transformer top layers and freezing the remaining layers. To train the model, we append two linear layers which have 5 times the weights of the last transformer hidden state to decompress the embeddings produced by this encoder.
We compare PrivBERTSumm on 24 privacy policies from the OPP-115 corpus with two KMeans-based baselines which use default BERT embeddings (BERT+KMeans) and default PrivBERT embeddings (PrivBERT+KMeans) as feature vectors, measuring the ROUGE scores between the original privacy documents and the produced summaries:
| PrivBERTSumm | BERT+KMeans | PrivBERT+KMeans | |
|---|---|---|---|
| Mean ROUGE Score | 0.532 | 0.450 | 0.404 |
PrivBERTSumm outperforms the baselines in terms of the ROUGE score. This score, however, is problematic without abstractive reference summaries, i.e. summaries whose sentences differ from the source document: if we think of the definition of the ROUGE score at the beginning of the article, it becomes clear that the longer a summary is, the higher the n-gram overlap with the source document (and thus the ROUGE score). Therefore, we also consider explicit user feedback.
User Evaluation
We let 12 users read two privacy policies each, together with the 3 summaries produced by the different approaches, and ask them to evaluate them on a Likert scale concerning the three most important aspects of the summaries: completeness of information, comprehensibility, and text length. The results show, that, while the users are satisfied with the reduced reading time of the summaries, they are still concerned about too much loss of important information which is shown in the following figure where we compare it with the baselines introduced above:

Here the orange box represents the results achieved with PrivBERTSumm (pb), the blue box the results of BERT+KMeans (bk), and the green box the results of PrivBERT+KMeans (pk). The y-axis represents the average user ratings on the Likert scale for the statement shown in the title of the figure. One can see that PrivBERT+KMeans achieves better results than BERT+KMeans, indicating that the use of a pre-trained in-domain language model improves the text embeddings.
Regarding the fact that PrivBERTSumm does not outperform the baselines here, one has to again take into account how the model is trained. It is optimized in terms of rather short abstractive summaries, which in turn lose a certain amount of details of the training articles. From this, we conclude that such an objective is not suitable for a domain with critical data where it could be essential to retain most of the information in certain parts of the text (e.g. in the category of first-party data collection).
Conclusion: Text Summarization for Privacy Policies
Our article shows that, in terms of standard summarization metrics, we successfully applied a new approach combining metric learning and multi-label classification with the in-domain PrivBERT model to privacy policy summarization. However, there is still room for improvement in our automatic privacy policy summarization system. One adjustment could be to consider user input for example for a variable summary length depending on the privacy practice category or to cut specific categories completely.
From a technical perspective, one could implement different training metrics to avoid information loss. For example, the Pyramid score [10] considers information units rather than n-gram overlap and is a promising alternative to the ROUGE score, but it requires additional effort in the creation of the summarization dataset. One could also try to further optimize the baseline approaches, e.g., by fine-tuning PrivBERT embeddings using a triplet loss on privacy policy data.
Overall, our successful training results show that metric learning with transformer models is a promising approach for text summarization for privacy policies, and provide valuable insights for further research on privacy policy and general text summarization.
References
- Extractive Summarization as Text Matching, Zhong et al., 2020
- Privacy at Scale: Introducing the PrivaSeer Corpus of Web Privacy Policies, Srinath et al., ACL 2021
- RoBERTa: A Robustly Optimized BERT Pretraining Approach, Liu et al., 2019
- BERT Tutorial
- Siamese Network Tutorial
- Classification with Cross Entropy Tutorial
- On the Effect of Dropping Layers of Pre-trained Transformer Models, Sajjad et al., 2021
- Privacy Policy Classification with XLNet, Mustapha et al., 2020
- NLTK Tutorial
- Evaluating Content Selection in Summarization: The Pyramid Method, Nenkova & Passonneau, NAACL 2004


