
This article will dive into the topic of autonomous robot grasping and the qualifications it entails. I want to share my experiences of dealing with deep multi-modal reinforcement learning algorithms in real simulation environments to help future work overcome the initial struggles with ease. This work provides good know-how on how to create a realistic framework to train in these environments and also some results of trained reinforcement learning agents.
Introduction
What would you do if someone approached you and asked you to decide whether you would prefer to go to the store around the corner and buy a can of peeled tomatoes or weld thousands of brackets with a precision of less than a millimeter to a car? It appears to be obvious that 99.999% of the population would choose to go to the store and buy whatever is needed because it is much easier for them. If robots could decide, I suppose that they would choose the second option. Tasks that are seemingly simple for every human can be impossible for a robot, but complex, repetitive tasks can be solved effortlessly by it. This is called Moravec’s paradox. Easy tasks require cognitive abilities, such as perception, attention, memory, and many more, which are not very straightforward to implement in a machine. For that reason, one purpose of artificial intelligence is to give robots the ability to act as cognitive systems.
This article concentrates on autonomous robot grasping and the qualifications it entails. At first glance, the robot requires the capability of recognizing certain objects, predicting their spatial location and orientation, the ability to reach the object, and the main ability to grasp it. These problems can be approached in a few different ways, but we will approach them with multi-modal reinforcement learning algorithms in this article. I want to share my experiences of dealing with deep reinforcement learning algorithms in real simulation environments to help future work overcome the initial struggles with ease. This work provides good know-how on how to create a realistic framework to train in these environments and also some results of trained reinforcement learning agents.
(Deep) reinforcement learning
Similar to the human learning process, reinforcement learning is all about positive or negative rewards after the execution of one or more actions. If the action is beneficial to the final goal, the agent receives positive feedback; but if the action is harmful, bad times await the agent: it gets punished.
Mathematically, reinforcement learning algorithms are based on Markov decision processes, but I would not like to enter into a long mathematical explanation. There are a lot of books that provide a much better explanation than the one I can give. One of my favorite books on this topic is written by R.Sutton [Sut-2018]. Let’s try to explain the concept of reinforcement learning with a simplified example of our use case. We have a robot arm, a shelf, a room, and some objects that lie on the shelf. The robot arm is called the “agent“, and all other elements are part of the environment. These are the only two elements that are needed to train a reinforcement learning agent.
The robot executes an action which is a movement. Accordingly, the state of the environment changes (this is not always the case, but for now, let’s assume that it touches an object and it moves). The success of the action is evaluated, and if it was a good action, it receives a positive reward; if it was a bad action, it receives punishment in the form of a negative reward. Hence, if it was a good action, it should learn it; if it was a bad action, it should better avoid it in the future. The ultimate goal is to learn the optimal policy, which is the means by which the agent chooses the most successful action. A good idea is to have a table that contains each state and the corresponding optimal action in it, right? How would you describe the state of the environment? Maybe get the position of each object, the shelf, the position of the robot arm, the illumination, and many more? What if we take a picture of the environment and every pixel value represents one part of the state? This seems to be not feasible at all since the number of “states“ is enormous. Here is when the famous “deep“ word comes into the scene. The concept of using a deep reinforcement learning algorithm is based on the idea that a neural network replaces the table of state-action pairs. Neural networks can handle big images and ideally predict the optimal action based on only images.
There is a very famous deep reinforcement learning algorithm that is able to win board games against the best players in the world. Nowadays, it is also used to experiment in the field of robotics. The network is called Deep Q-network (DQN). We will try to experiment with a multimodal version of it.
Problem formulation
Deep reinforcement learning algorithms are very complex to train and especially to transfer to real-life applications. They are computationally expensive and require a lot of time to train. It is very common, especially in the field of robotics, to train these algorithms in simulation, and later fine-tune them on the real robot. One important aspect when training these algorithms in this way is to have a low reality gap. Closing the reality gap is a complex problem in itself, but a good way to start approaching this issue is by creating a simulation similar to the setup in the real world. Creating this simulation in a framework that allows training different reinforcement learning without having to change the whole code whenever a new network is to be trained, is the first step of this work. Later, once it is possible to train every kind of algorithm with ease, the effect of multimodality on the training will be observed. Humans use more than one sensory input, especially visual input, to perform actions and react to occurrences. Hence, we will check if having different types of inputs is favorable for good training.
Implementation
Simulation
Our simulation is based on the work provided by robo-gym. The framework used is Gazebo, a 3D dynamic simulator that allows the integration of robots, environments, sensors, and many more as desired. To lower the reality gap, we integrated hardware with the same properties as in real life: a UR10e robot from Universal Robots, an Intel RealSense camera, the Robotiq85 gripper, and objects with textures such that they look similar to the ones in reality. The figure below shows a screenshot of the created environment containing the above-mentioned elements. The objects lay on the shelf to mimic the real-life use case.
-
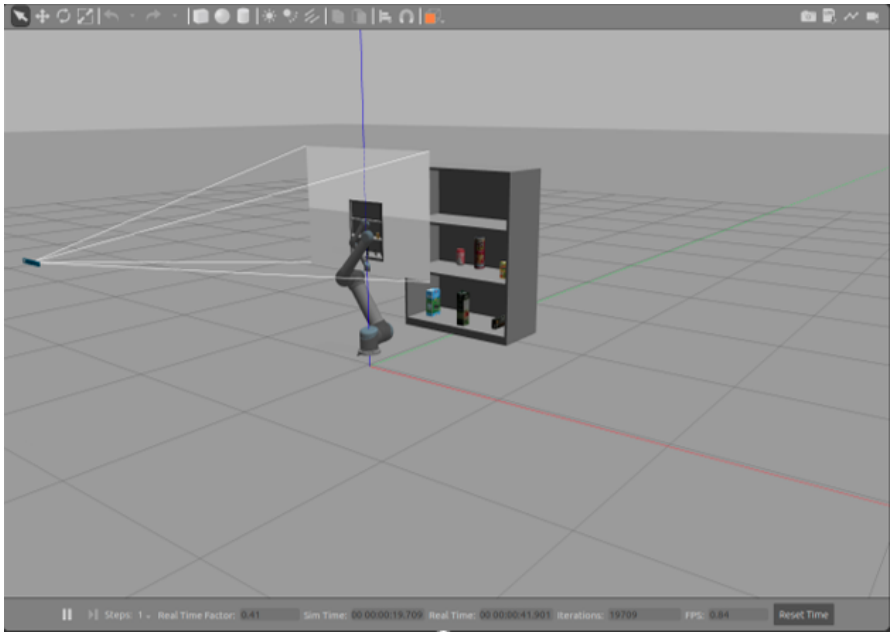
Screenshot of the Gazebo GUI. The simulation contains a robotic arm, a gripper, a camera, and a shelf with six texturized grocery objects.
Following the implementation of robo-gym, everything was integrated into Python using wrappers, which allowed us to create environments that can be integrated into the openAI gym toolkit. This toolkit allows for a simplified training of a lot of agents using reinforcement learning algorithms. We want to try different architectures for our agents, which leads to the need to train multiple times. To avoid having to constantly change the code for each experiment, we implemented a pipeline that is built out of modular blocks. Hence, it simplifies the process of changing the code every time a new experiment needs to be trained. There are two kinds of blocks: the input blocks and the network blocks. The input blocks are the ones that define which inputs are used to train the network. We experimented with three (four at the beginning, but our object detector was not stable enough to ensure smooth training) different inputs and their combinations. The inputs were an RGB image, a depth image, and a state vector containing parameters about the environment and the agent. On the other hand, the network blocks define which type of network is to be trained; either Deep Deterministic Policy Gradients (DDPG) or DQN. This blog article will focus on the latter one since the results achieved were significantly better. The following figure depicts the architecture of the pipeline we used to fulfill our experiments.
-

Graphical description of the pipeline used for training. - For easier comprehension, the figures pasted below demonstrate the typical inputs provided by the RGB image input and depth image input, respectively. These are passed without further preprocessing to the algorithm.
-

RGB image input
-

Depth image input
Training
The training procedure was completely performed in the simulation. For this purpose, as mentioned earlier, we tried an architecture that first passes the inputs through some layers before they are concatenated into a state vector, which is then again passed to further layers. If the input is image-shaped, it is passed through convolutional layers, but if the input is vector-shaped, it is directly concatenated to the state vector. This is shown in the multi-modal architecture figure.
-

Multi-modal architecture of the Deep Q-Network
Throughout the experiments, we maintained every hyperparameter constant except for the distance threshold to validate a successful touching event. Another exceptional hyperparameter is the buffer size, which was different for the cases that included images as input and the cases that did not use images as input. The learning rate, batch size, and network parameters were held constant. A detailed description of the values used is shown later in a table.
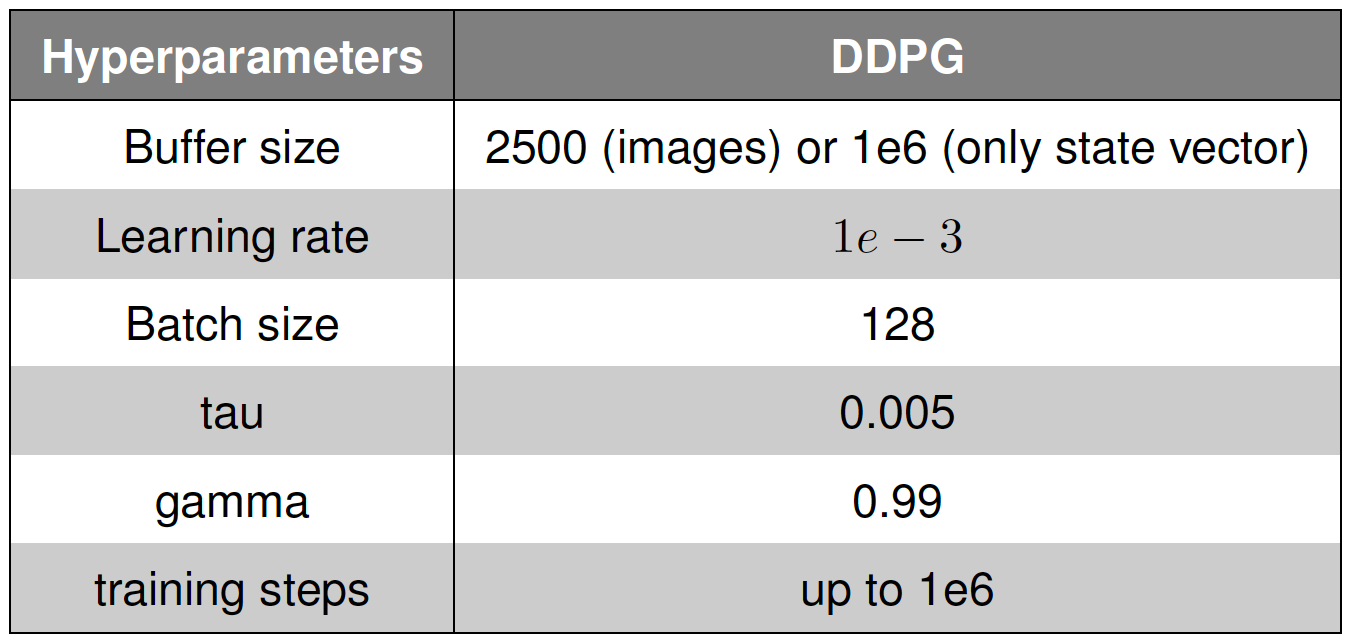
In this article, we will compare two training attempts: the first one contains only a state vector as the input, and the second attempt consists of an RGB image, a depth image, and a state vector. The encoding architectures are set to be the same to ensure an easier evaluation of the differences during training time. The images are first encoded using the network architecture shown in the following table.

Results and discussion
This section will present some results of the experiments. Training these deep reinforcement learning algorithms took up to 20 days each and we trained using an NVIDIA GeForce RTX 2060 SUPER GPU and four AMD Ryzen 3 2300X Quad-Core Processor CPUs. Even though the training was performed in a simulation, it took a lot of time to converge.

This figure shows the reward curve during 1.4M timesteps for the experiment with the multi-modal network. The set of inputs of this network is comprised of an image, a depth image, and a state vector. Each blue dot represents the accumulated reward during one episode. If it is close to zero, the episode was not successful, while if the reward gets close to two, the episode achieved the goal that was set. The blue line in between represents the mean reward of the last 50 episodes. Hence, the curve approaching the upper dots signifies that the algorithm is learning something. After some steps, we reduced the distance that sets the threshold for which an episode is seen as successful a few times. This is marked by the red bars in the graph. The number above the bars indicates the new distance threshold in distance units.
The result of the experiment with a uni-modal input is shown in the figures below. It is split into two graphs because the first one was interrupted unintentionally. The second was then started with the pre-trained weights from the first experiment.


It is clear that both algorithms exhibit some sort of learning since the curves move towards the upper line of points. This explains that it is possible to observe the environment with a combination of different inputs and with only a state vector. On the other hand, it is also remarkable that the second experiment is able to learn the representation of the observed environment with fewer difficulties. Having only one state vector as the input provides much faster and more accurate training than when the input consists of a combination of an image, a depth image, and a state vector. It is also able to achieve a much higher mean reward which leads to more accurate precision in the reaching task. We reached a very high mean episode reward for a discretization factor of 0.02 distance units, while we were not able to achieve this performance with the multi-modal network.
In our understanding, this is caused by one main problem, which is called hyperparameter tuning. Deep learning models require very precise training procedures, where the parameters of each one depend largely on the networks and the data used for good convergence. Networks that train with images and networks that use state vectors as inputs use very different parameters, especially when we talk about learning rate, training time, and network size. Each modality, trained in a separate way, needs its own hyperparameter finetuning. In a multi-modal network, everything is optimized with the same strategy. Training everything with the same strategy is not optimal for this reinforcement learning network. W. Wang et al. [Wan-2019] discovered a similar finding when comparing multi-modal inputs with uni-modal inputs. The same paper mentions that multi-modal networks are very prone to overfitting. This is also something that was discovered in our results. It is observable in the multi-modal network results that the average reward curve forms some sort of hill. These hills can be explained by this statement. Hence, for our experiments, it is not beneficial to have a multi-modal input. A bad training procedure makes it hard for the networks to extract or encode the important information from the inputs in a state vector. If this is the case, the agent receives a concatenated vector as the input, which does not describe the observed space in an accurate way.
Conclusion and Outlook
Experiments in which agents were trained using reinforcement learning revealed that incorporating inputs from several modalities is not useful. At least, that’s how we addressed the subject, where they were transmitted without any kind of preprocessing. In reality, they harmed the training process because we could not achieve positive results with anything other than a single state vector including information about the item and the robot. Our ideas on this, as discussed in the discussion section, are that neural networks are incapable of extracting the image’s key features into a state vector that is expressive enough.
Future phases would include a greater emphasis on raw input preprocessing. Our results suggest that training a multi-modal network does not allow us to encode the correct information, but we believe that pretraining some encoder architectures that can encode the correct information in a state vector could be advantageous. This would necessitate even more training steps and pipeline components. As a result, it must be a meticulous job requiring a thorough understanding of the encoder’s latent spaces.
[Sut-2018] Sutton, Richard S.; Barto, Andrew G.: Reinforcement Learning: An Introduction. Second. The MIT Press, 2018. Url: http://incompleteideas.net/book/thebook-2nd.html.
[Wan-2019] Wang, Weiyao; Tran, Du; Feiszli, Matt: What Makes Training Multi-Modal Networks Hard? In: CoRR abs/1905.12681 (2019). arXiv: 1905.12681 . Url: http://arxiv.org/abs/1905.12681.


