
This article discusses the challenges of building data products with an emphasis on Business Intelligence. With data products, there is often a need to build many of them in parallel with a short feedback cycle. This means that developers often have a strong coordinative role and need to be flexible. The article introduces Fluid Data Product Scrum Teams, an idea developed by Willem-Jan Ageling that allows teams to set focal points in Sprints and create low-adhesive groups to work on Backlog Items. Furthermore, the article explains how we use Fluid Scrum Teams to manage multiple data products over multiple Sprints.
Typical challenges for data products
When inovex is working with data products, two types primarily come up. The first one is a service-based calculation within a workflow or workstream which has been automated, for example with a microservice. The second one is a more hands-on approach where stakeholders coming from a Business Intelligence / reporting perspective need immediate feedback to validate data and outcomes, for example replacing manually created Excel files with an automated version – or creating an automated report in contrast to a manual one beforehand. There are many more distinctions for data products and they might not necessarily be available only in those two types, but for the sake of simplicity, we will focus on the Business Intelligence / reporting type in this article.
Data products usually have a bit of a different lifecycle in contrast to other software products. We see data products for example as anything that replaces a good ol’ Excel file with an automated workflow. It could also be a specific report which beforehand was loaded manually. With data products in this Business Intelligence-focused area, we face the challenge that usually we have to build many of them in parallel over the course of many Sprints. To build data products we use Scrum in a wide array of projects.
The results of a data product will usually be checked and verified already within a running Sprint, not necessarily waiting for the Sprint Review. This is one of the crucial elements of the difference in workflow for solutions that are being built for individuals. New data products sometimes do not start with a big vision in mind, but with small steps first to gather experience and create immediate value. This, by the way, usually is targeting the internal processes of a company, optimizing and automating existing workflows to enhance data quality, master data structures, and use new, agile ways of working.
Because of the first small steps with individuals and immediate feedback within the Sprint, this also means that feedback for a data product will be available already in the Sprint for a Product Backlog Item – or that there might be a delay of feedback due to unavailability of the stakeholders. With so much feedback and interaction with the stakeholders, the developers usually tend to have a stronger coordinative role than in other setups. The team needs to have a big amount of flexibility in those situations because stakeholders can also be quite demanding to get the solution quickly when providing an answer. We have learned that transparency and a good Scrum Master are very helpful here, to educate and show why Sprints exist and why feedback usually goes into the next Sprint unless something else was aligned upon.
What plays a role as well is the fact that those smaller initiatives, especially in the ramp-up phase of a data project, will fill up the Product Backlog quite quickly anyways – since quite a few people will learn about the new solutions being built and would like to try it themselves.
This can lead to the challenge that one team has to handle multiple data products over multiple Sprints, possibly leading to lone fighter syndrome through fragmented working areas. From our experience, it is not possible to focus on one data product only, since there is always a bit of feedback missing or another stakeholder has something more valuable available. Those priorities can change from Sprint to Sprint and are always something that will be aligned with the Product Owner, the stakeholders, and the developers in the Planning and within Sprint. To make this as flexible as possible, we adapted Fluid Scrum Teams.
What are Fluid Scrum Teams
Fluid Scrum Teams are an idea of Willem-Jan Ageling, which he published in September 2021.
Essentially, Fluid Scrum Teams allow the team to set focal points in Sprints and create low-adhesive groups to create value and work on Backlog Items. Say you have a pool of a dozen developers. They will create a specific Scrum Team for a Sprint, based on the current requirements. Then, in the next Sprint, the Scrum Team might be set up by a different constellation of people. We used the idea behind this approach within one team.
For example, in one Sprint a specific technology might be needed for a data product. One of the developers knows very much about this technology and would focus with others specifically on this Product Backlog Item. In the next Sprint, the expertise would no longer be needed and the team would create other focus groups.
Because of the complexity of work, this allows enough flexibility to work as a team on the Sprint Backlog but also to create enough cohesion on specific topics. Sure enough, this could also just be seen for the developers to set up within the Sprint for themselves – but especially with several data products it proved helpful for us to align beforehand in the Sprint Planning.
The article Stable Scrum Teams limited us to create value — Enter Fluid Scrum Teams of Willem-Jan goes into much more detail about Fluid Scrum Teams.
Fluid Scrum Teams in data products
For us, one of the main benefits is not only the dynamic association with topics but a visual overview of the upcoming Sprint, aside from a Sprint Backlog.
The Product Backlog in our case is set up very modular and focused on individual data products as well, whereas every data product has its own product goals. In this, every story always has information about its parent epic / its data product. For more details on this, please refer to our article about Managing Stakeholders in a Multi-Product environment.
Generally, our preparation workflow looks like this:
- Initially, a general layout was formed – here we also added pictures of the team members
- The Scrum Master copies the headlines from the Sprint Backlog in refinements into digital stickies (this is in accordance with a general idea about the Sprint from the Product Owner)
- Adding the data product in brackets at the start of the Sticky (to have a good overview)
- Manually adding Story Points and Timeboxes (for Spikes)
- And then, together with the Product Owner, we group those stickies – or Sprint Backlog items to be discussed – into focus areas. One team member should only be in one focus area, but there exists the possibility that a team member joins different focus areas for different tasks
- Other, additional duties (like a “firefighter“ role) can be assigned with this workflow as well
This workflow can be automated a bit with exporting functionality of workflow systems. Also, Miro creates stickies for every row in a spreadsheet, making the whole process easy enough.
An example can be seen in the picture below. In the example only a couple of fictional team members are available.
-
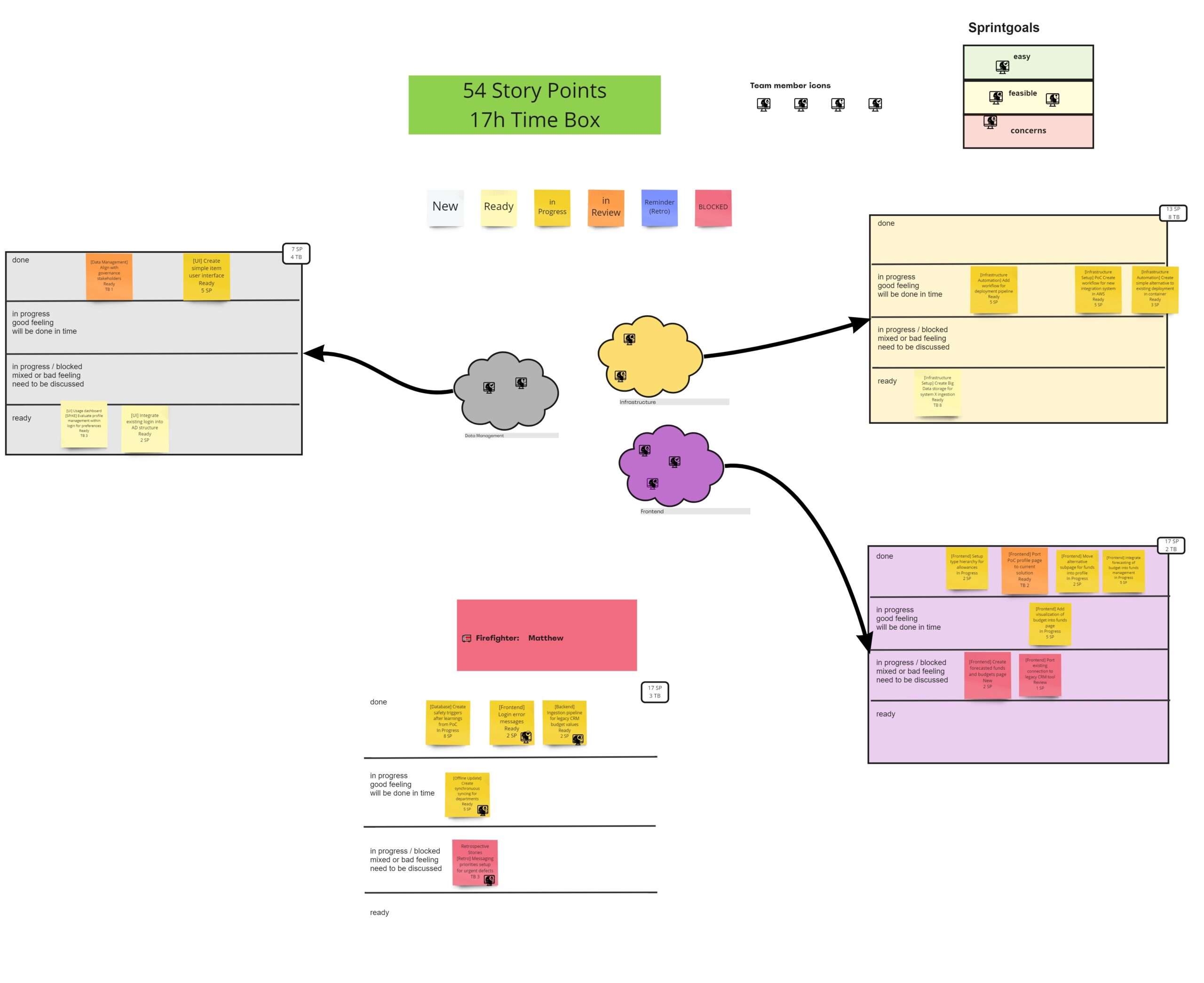
Simple Miro Layout for Sprint Planning with Fluid Data Product Scrum Teams
After the preparation, in the planning, we use this overview then to work together as a team on the Sprint Backlog. Is it feasible? Do we have too many or too few focus areas? Are there other items missing that some stakeholders might expect or need in the upcoming Sprint? This is usually brought to our attention by a developer.
With the pictures added, the team members then can use those icons to assign themselves to a focus area.
When all this has been laid out, we usually have an easy time identifying different perceptions and mental models – and will discuss them shortly to align priorities, focus areas, and assignments for this Sprint.
Then Sprint Planning closes up with the general estimation, if all things considered, we are convinced we can deliver. Sometimes if the Sprint Backlog is not estimable yet, we do a short Magic Estimation session to prepare everything with and for the team.
This “Fluid Planning“ – because of the complex nature of this workflow – takes a few iterations to get right. A solid team structure can help. New team members or people leaving will disrupt this (like Tucker mentioned in the Phases of Team Development) and it will take a little time to get things running again.
Advantages
The created board can also be used in the Daily to avoid individual story updates. Here the overview of the Sprint Goals and the focal areas help to always zoom out a little.
The Sprint Planning itself is more coherent and shows differences in perception quite fast. It opens up room for discussion in those focal areas and makes it easier to create tasks and think of missing items for the upcoming Sprint.
Also, there can always be a more general discussion about the Sprint Goals and their weighting. For us, the Sprint Goals go hand in hand with the focal areas – which is also why we do have two or three Sprint Goals in a Sprint. We used this with a team a little bigger than the usual Scrum Team size and it worked out fine. It would also be an interesting take for teams in Scaled Agile environments since this approach is individually available for every team.
Other important tasks, such as assigning a firefighter/operations contact point for this Sprint then also can become part of the workflow.
Disadvantages
This approach brings a few downsides:
The Planning needs a little more preparation time in advance to set up the Miro board. Because of the flexible way of using a digital whiteboard, no automated way exists yet to sync the Product Backlog and the board. From our perspective, it is well worth the invested time, though.
It could also be that the Miro board and the slightly different workflow will make people more skeptical in the beginning, making it harder to have effective Sprint Planning. It has helped us to have a couple of dry runs first. Once everyone gets used to the workflow it gets easier over time.
Conclusion
In specific data product contexts the Fluid Scrum team in data products approach can help to bring together all the different challenges.
It takes some time to get used to but if used correctly can help to provide the same mental picture to all involved.
And a nice side effect is: for stakeholder alignments, the Miro can be opened up quickly and be used as a foundation for a conversation.
TLDR:
Fluid Scrum Teams sets up Scrum Teams each Sprint anew from a pool of people, a bigger development team.
Fluid Scrum Teams for data products sets focal points with the same Spirit, but not necessarily focuses on a Scrum Team but on specific Data Product development, when a team is working on multiple products at the same time.


